开源组件搭配DockerMESOSMARATHON,不要太配哦 | 又拍云企业容器私有云架构
Posted 又拍云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源组件搭配DockerMESOSMARATHON,不要太配哦 | 又拍云企业容器私有云架构相关的知识,希望对你有一定的参考价值。
分享 | 莫红波(又拍云系统工程师)
整理 | 半夏
2016年12月2日,InfoQ主办的全球架构师峰会2016在北京国际会议中心成功举办。本次活动以“云平台架构设计与容器落地实践”为主题,邀请架构私有云领域的技术大牛结合自身经验探讨容器技术中的技术难点以及如何解决这些问题。
又拍云也在受邀之列,又拍云系统工程师莫红波围绕「又拍云企业容器私有云架构」跟大家分享云架构中的几个组件,帮助大家了解如何快速搭建企业私有云等一些值得思考的问题。
由于文章比较长,小拍先在这里列了一下文章结构哦~
⊙服务器扩容的实际问题
⊙分解又拍私有云
镜像的持续交付
动态的服务路由
服务日志收集
服务监控告警
以下就是莫红波的分享啦~
服务器扩容的实际问题
大家好,我今天分享的是又拍云现在正在使用的企业容器私有云。在谈私有云架构前,我想先讲个故事,2015年又拍云遇到后端图片处理请求翻了好几倍的情况,而当时整个图片处理集群的冗余度在20%左右,是根本无法抵抗这么大的并发的,唯一的办法就是扩容,在整个扩容过程,我们发现了几个痛点:
第一,需要新机器
尽管数据中心有很多机器,但是当线上发生故障时不可能把服务器部署到完全新的环境中,而且在新环境中还跑了我们线上的业务,很可能会导致现在正在服务的业务出现故障,导致更大的事故发生,所以我们选择新的机器,但是大家都知道要新的机器周期非常长。
第二,系统环境问题
有了机器,部署好程序,开始跑项目的测试用例,结果发现有一部分jpeg图片测试用例没有跑过,然后我们开始排查问题,比对两台主机间的差异,最后发现是一个libjpeg版本差异导致的,虽然最后问题定位了,但是花了很长的时间。
从这个事件里,我们发现了这么几个问题是急需解决的:
如何快速扩容应对突发流量;
如何解决部署环境问题;
如何整合离散的计算资源。
分解又拍私有云
2015年的时候容器技术非常火,很多厂商都在做自己的私有云,也提供了很多方案。那时我们想又拍云也需要一个私有云。
一个理想的私有云需要具备哪些特点?我这里大概罗列了几点:
资源统一管理,把整个数据中心计算资源管理起来;
支持资源增删改,机器经常会上下架;
服务统一入口,需要什么服务,只需要访问最外层的Web服务器就可以,请求方无需知道内部的逻辑;
持续集成交付,容器技术的优势就是颠覆传统交付方式可以更加自动化;
部署迁移 App 要足够的方便,服务伸缩也是;
App 之间要环境隔离,这个容器技术已经帮我们搞定了;
通用的日志收集,不需要在代码里打点,尽可能小得改动之前的代码;
通用的监控告警机制,监控是私有云平台的重中之重,特别是借用容器这样的新技术,稳定性还有待考量。
在方案选型上,我们选择了Docker、MESOS、MARATHON。这套方案有很多厂商都在做,我们跟Google k8s做过一些比较,认为这套方案前期学习成本相对较低,可以快速上手,MESOS的架构更加清晰,也有很多丰富的API可以去调用。
接下来看一下MESOS的基础架构。
△ MESOS基础架构
首先Mesos是一个Master/Agent的架构方式,Master负责资源的统一管理跟任务的分发,Agent负责起停执行器,汇报主机资源、执行器状态等信息。一般情况下,会启动3个以上Master,以确保高可用,Master的状态由Zookeeper维护。Framework是Mesos上的调度框架,Marathon Hadoop Chonous都是比较常见的任务调度框架。整个架构给人的感受就是清晰明朗。
那MESOS内部机制是怎样?
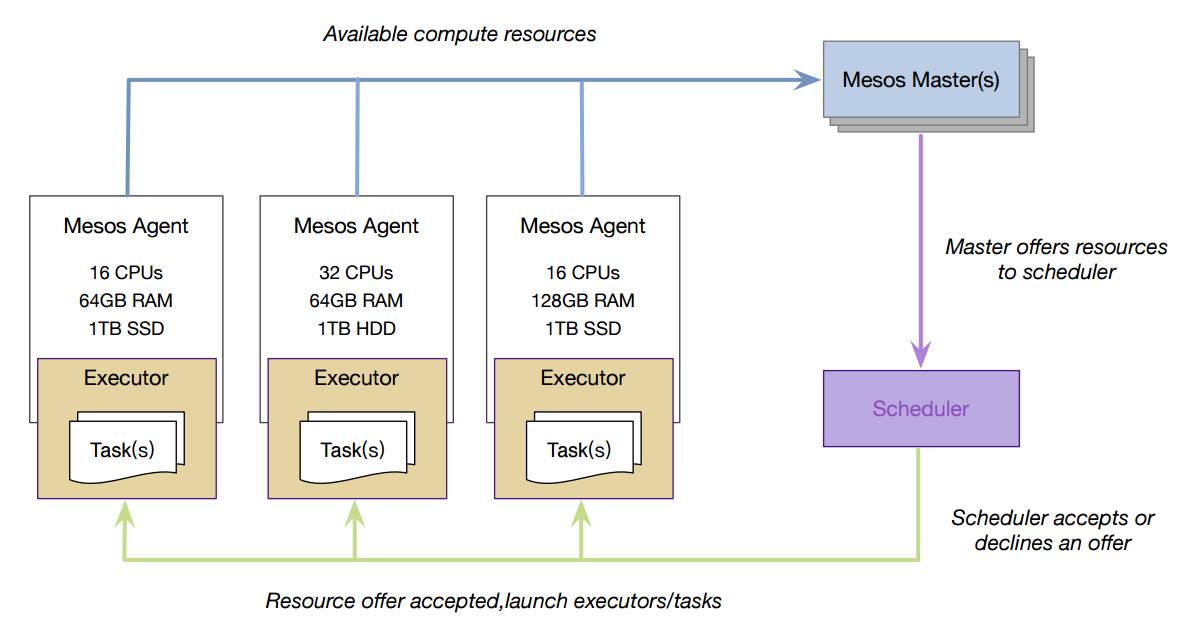
△ MESOS内部机制
首先每台机器上都会部署一个Mesos-Agent,Agent会把信息汇报给Master。调度器scheduler向Mesos-Master请求资源,Mesos-Master把所有可用的资源都反馈给Scheduler,Scheduler根据自己的规则决定该部署到哪一台。大致就是这样一个流程。
现在我们有了Docker做App的环境隔离,有了Mesos统一管理计算资源,有了 Marathon保证我们服务永不掉线,除此之外还需要做哪些东西呢?
第一是镜像的持续交付。在讲之前我先讲一下什么是持续集成。
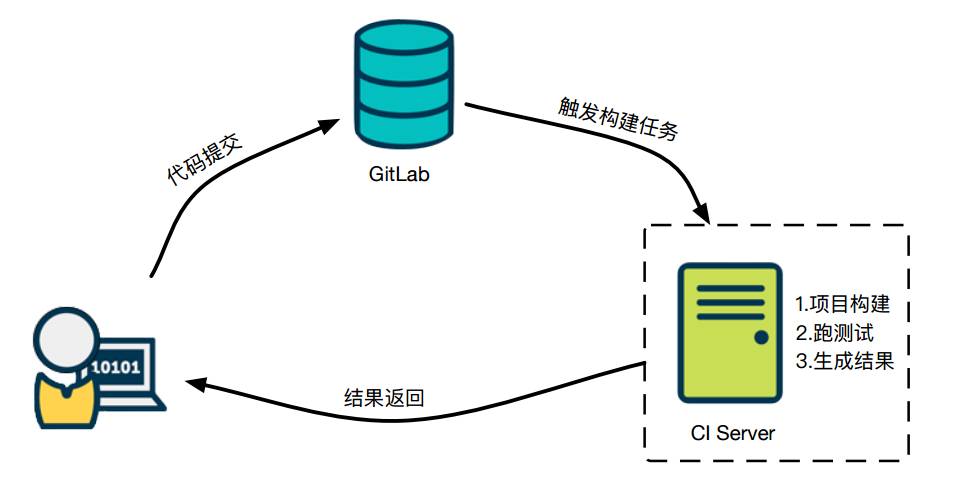
△ Docker持续交付
上面是我们使用的一套流程。我们把代码提交到代码仓库,我们用的是Gitlab,Gitlab触发构建任务给CI服务器,CI服务器进行项目构建、跑测试、生成结果,并把结果反馈出来,采用这种方式可以大大降低Master分支出现错误的可能性。
那么怎么来做Docker的持续交付?在这个模型上我们做了些许改动。
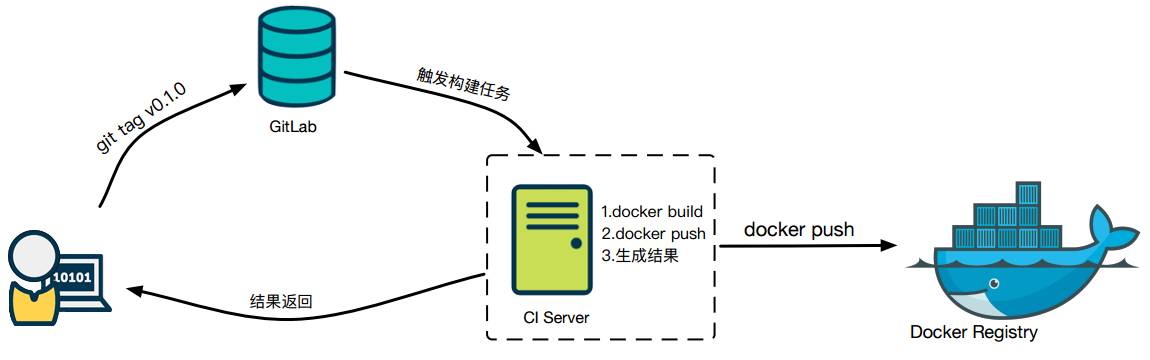
△ 又拍云Docker持续交付
当需要发布一个项目的时候,项目的负责人在项目的Master分支上打上一个tag,比如v0.1.0,GitLab触发构建任务,CI服务器根据触发方式判断出是Docker构建任务,便执行Docker build。
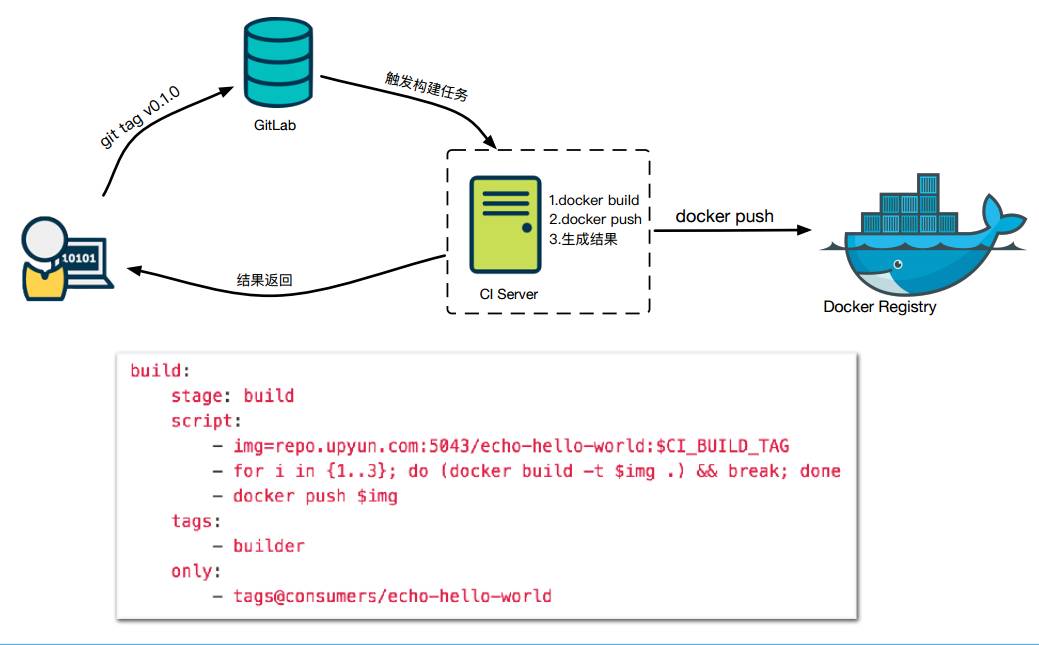
然后把Docker镜像推送到公司私有云仓库,最后生成一个结果。
又拍云用的是GitLab CI这套方案。
我们看一个简单的例子,基本含义就是当分支上有tag提交,就触发Docker 镜像构建任务,并把镜像推送到私有镜像仓库。
下面是又拍云一个早期版本的私有云。
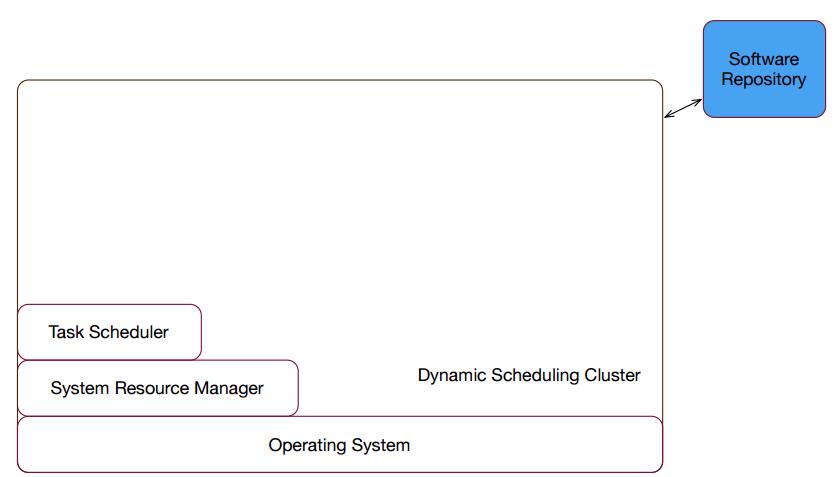
△ 早期版本的私有云
第二是动态的服务路由
解决方案有两种,一种是HAproxy,另一种是nginx。Mesosphere开源的Marathon-lb就是基于HAproxy做的。我们选择了NginX,NginX比HAproxy更加简单一些,我们实现了一个项目叫做Slardar,它是由NginX和Lua实现的,支持动态更新,不需要进行reload的操作。
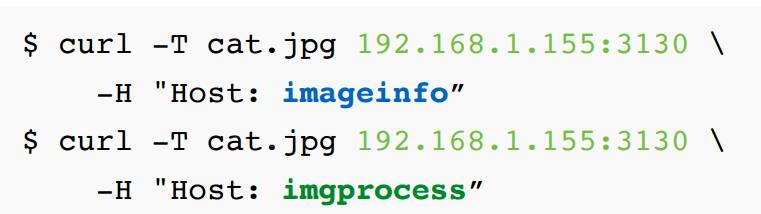
△ Host区分服务
上边是请求Slardar的例子,它是通过Host来区分服务的。比如上面一条请求,Host是imageinfo,这个请求会被路由到Info的集群。请求方收到结果就是这张图片的信息,而下面是路由到imgprocess。返回则是一张缩略图。
如何对Slardar进行动态更新upstream。

△ 动态更新upstream
这个例子需要增加一个服务upstream列表,把所有配置,包括host发送给Slardar。例子中是一台5.108的机器和5.109的机器,发送完之后可以通过Slardar状态页面看到它的状态,我们发现5.108的状态是OK,可以正常访问,5.109状态是err,这个状态页维护我们用的是lua-resty-checkups,它可以帮我们检查后端服务可用,这个模块我们也做了开源。
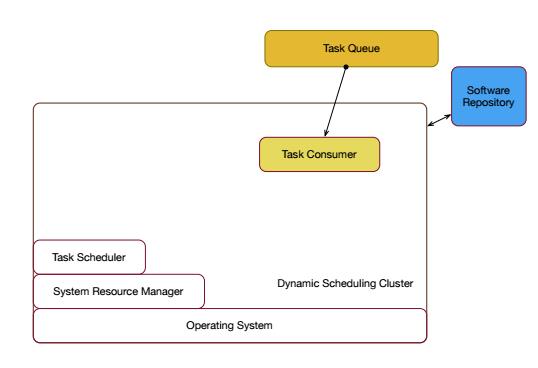
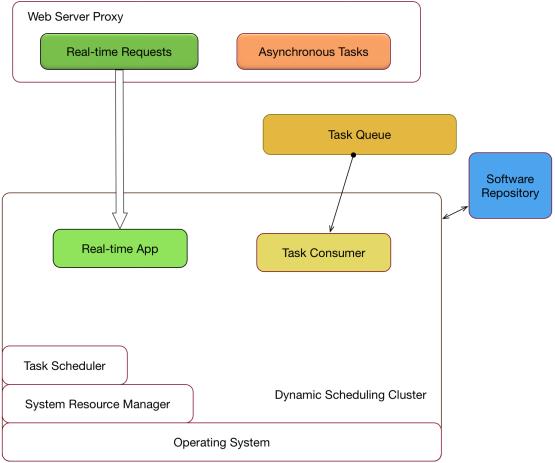
△ 统一的服务路由Slardar
有了这一层动态服务路由之后,就可以在私有云里面跑一些WebServer。
接下来讲一下服务日志收集
日志收集是件非常头疼的事情,但是日志在分析问题的时候是非常关键的。又拍私有云的日志收集遇到这样几个问题:
日志量大,频率高
分布在多个Docker容器里面
经常会迁移
按服务分割
多种用途
这里介绍一下私有云里用到的Heka。Heka,Mozilla的开源项目,又拍CDN节点的日志都是用Heka来收集的。Heka可以理解为一个管道,数据输入/数据输出,在管道内部会有一些逻辑,比如添加过滤规则(过滤掉不需要的日志),添加路由规则,把日志路由到不同的输出去。
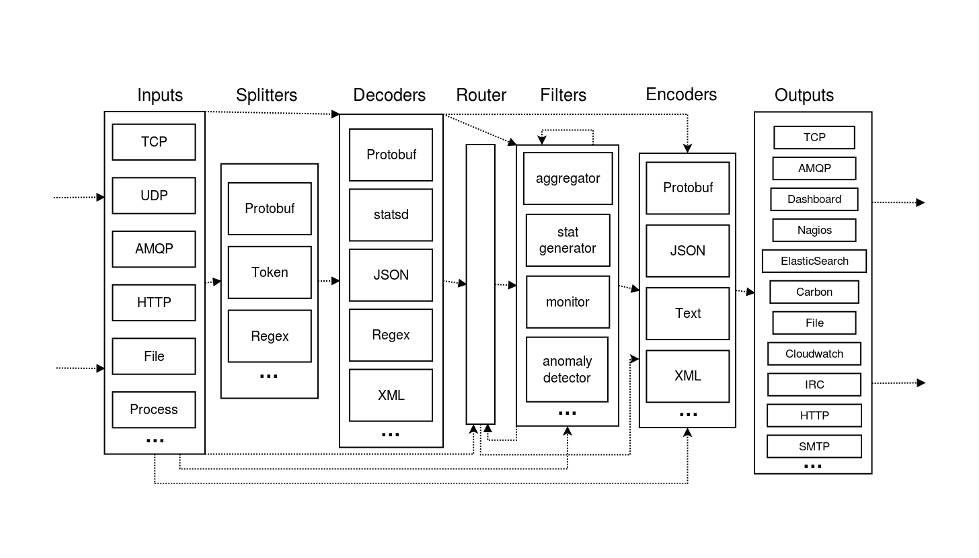
△ Heka

△ Heka的DockerLoglnput插件
采用Heka的DockerLoglnput插件这个方案有一点需要注意,日志需要输出到标准输出和标准错误中。我们先看一下Heka-Agent是怎样的东西,它的实现其实非常简单,它通过DockerAPI和Docker Deamon交互,取出日志发送到ES集群。日志消息格式大致包括这么几个字段:Uuid、Timestamp、Type、Hostname、Payload、Logger、Fields。Fields字段是可以自定义的,用过MARATHON的同学应该知道,MARATHON在启容器的时候会有一个MARATHON_APP_ID环境变量,我们在配置heka的时候把它映射出来,通过fields 字段来读取这个变量,这样就可以实现前面提到的按服务进行划分了。
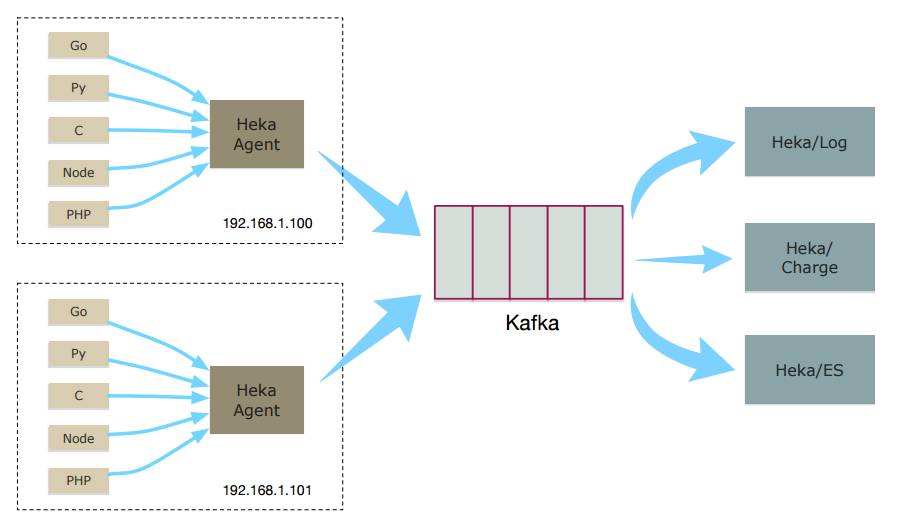
△ 日志收集的模型
这是日志收集简单的示意图,Mesos集群里的每台机器上都会部署一个 Heka-Agent,这个可以利用Mesos把App下发下。Heka-Agent采集到日志后,简单拼装下,就往Kafka发送。kafka这份日志数据可以提供给多方使用,对接到我们的日志平台、根据日志计费、对接elasticsearch,做数据分析。
在整个私有云里面就多了一个组件叫做日志收集,这个也是通过Marathon进行托管的。
现在讲一下服务监控告警。
△ Docker 监控告警平台
为什么要做服务监控告警?因为在早期搞容器私有云的时候,我们对Docker这个东西其实是不太放心的,我们担心我们的服务放到Docker里面跑会不会出问题,没有监控私有云是不可靠的。
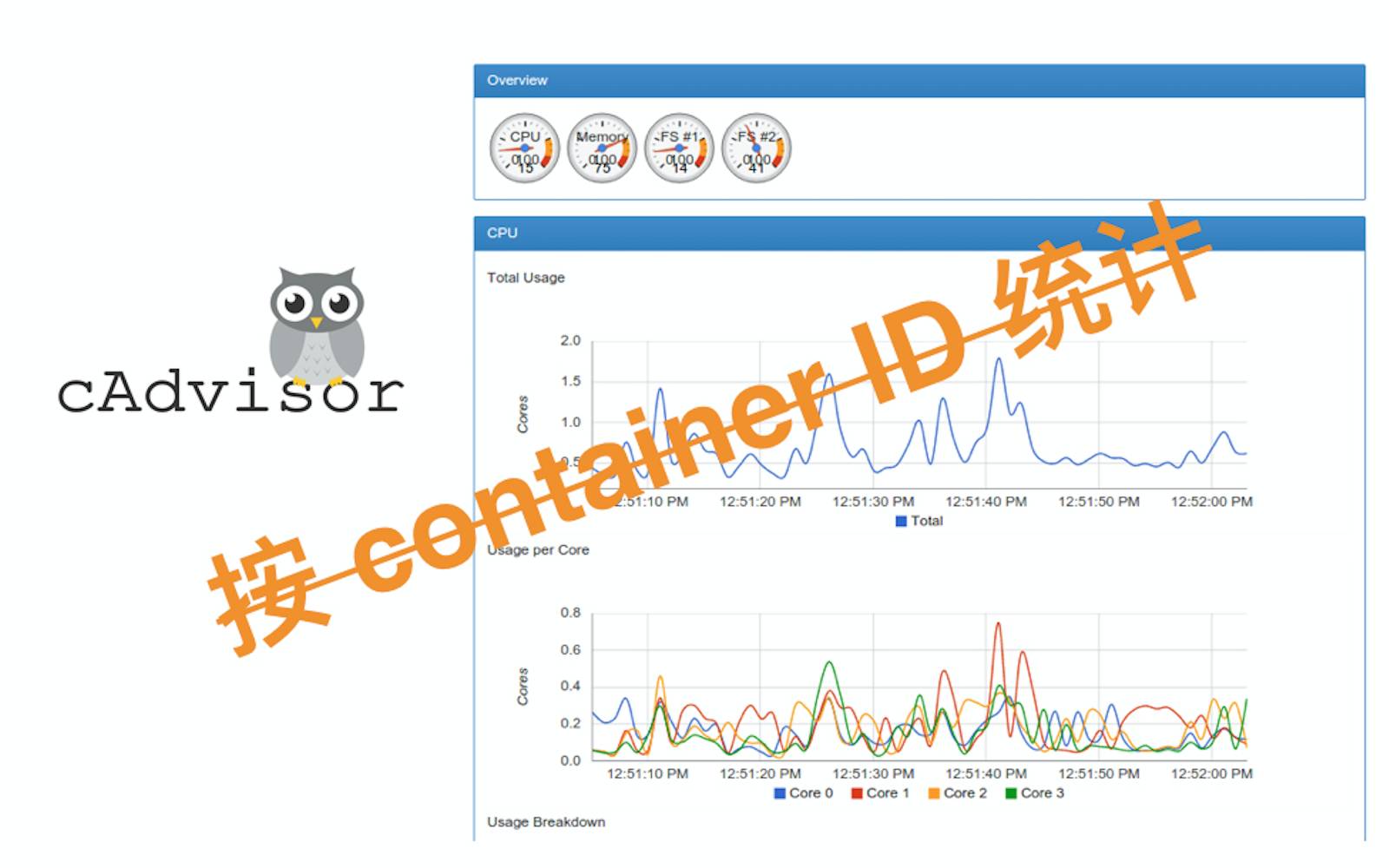
Docker容器监控的开源有很多方案,用的比较多的是Google的cAdvisor,安装也十分方便,页面也很炫酷。但是它汇总的信息是按照ContainerID的,这个监控力度太细小,并且不够直观,无法对应到具体服务,排查问题会比较麻烦,而且不太好设置告警阀值,CPU、内存的告警阀值都因服务而异,于是我们开始自己 DIY Docker监控告警平台。
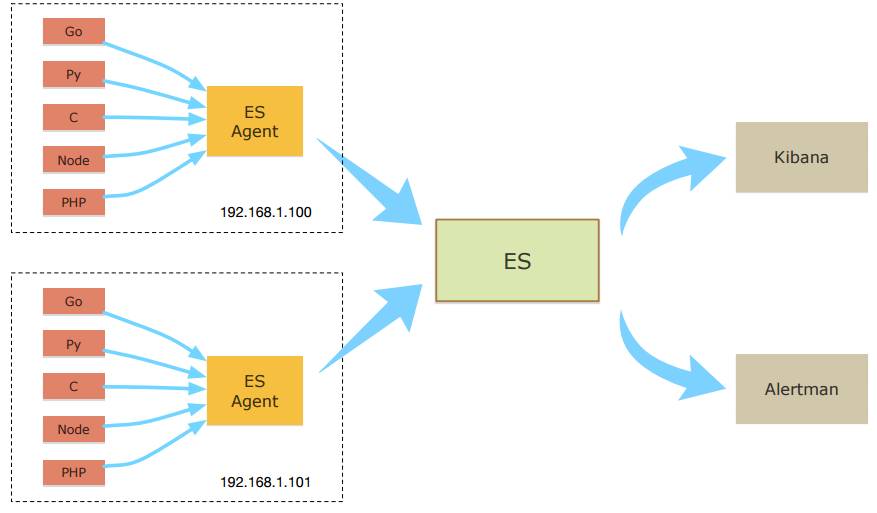
△ DIY Docker 监控告警平台模型
这是我们监控告警的一个模型,跟日志采集的很像,因为原理也很像,都是采集本地所有的Docker容器的数据。
它在每台机器上都部署了ES agent,获取跑着的容器监控数据,包括CPU、内存之类的,并把收集好的数据发送到ES。
我们可以看一下ES agent是怎么实现的。

△ 实现ES agent的代码片段
这个是我们数据采集插件里的一段代码,逻辑十分简单,构造了一个字典,里面包括了一些必要的监控数据,cpu、内存、磁盘IO、网络等。这里有一个字段 rssPercent,这个字段的含义是常驻内存在Docker容器总的内存里的占比。为什么不用memPercent这个字段,因为在实际使用过程中,我们发现Docker memoryStats.Usage包含了cache部分,是不准确的,会出现误报的情况。
倒数第二个字段,appID其实就是服务的名称,这个字段是用于数据合并的,因为同一个服务一般情况下不可能只需要起1个容器,当起了多个容器时,根据服务名合并就非常关键了,如果出现异常情况可以用来分析是该容器的特例还是所有都是一样的
再回到ES Agent这个模型。前端数据展现我们用的是kibana3。物理机是哪些,内存曲线呢?通过kibana可以方便的排查一些问题,比如某一个出了问题,我需要定位究竟是怎么回事儿,是服务机出了问题,还是这个服务本身有问题。据此我们自己写了个告警程序Alertman,会自动分析5分钟的数据。
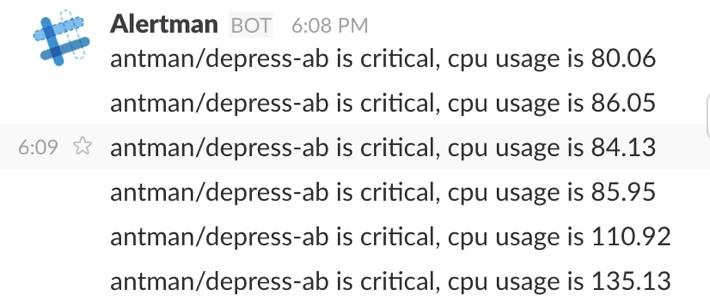
△ 告警程序Alertman
我们做了一个组件是监控告警,跟日志收集一样,也是托管在MARATHON之上的,由 Mesos进行下发。
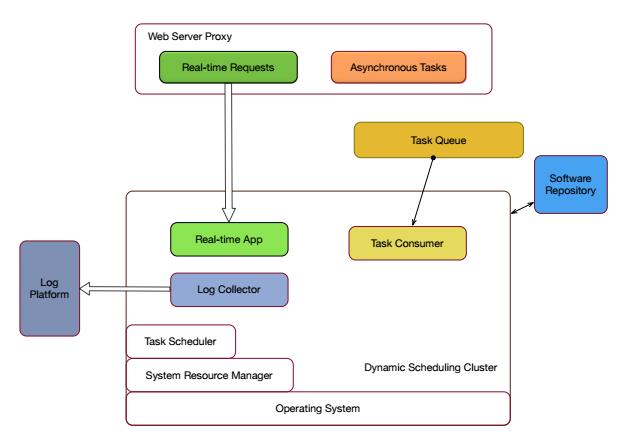
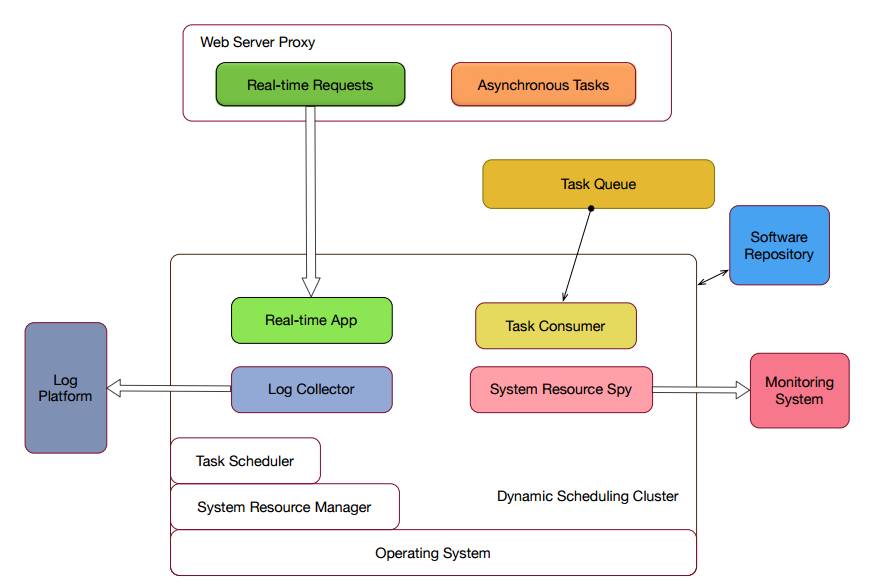
△ 监控告警组件
这个架构还缺点什么呢?我们发现整个架构是非常零散的:包括动态服务路由Slardar,MARATHON。
例如,需要对Web服务器进行扩容,首先需要去MARATHON那边把服务scale up到10,然后再把这份列表同步到Slardar,发送一个http请求,整个过程是非常麻烦的,还包括一些基本信息我们也无法察看到,所以搞了一个UPONE。UPONE是私有云平台的API层。
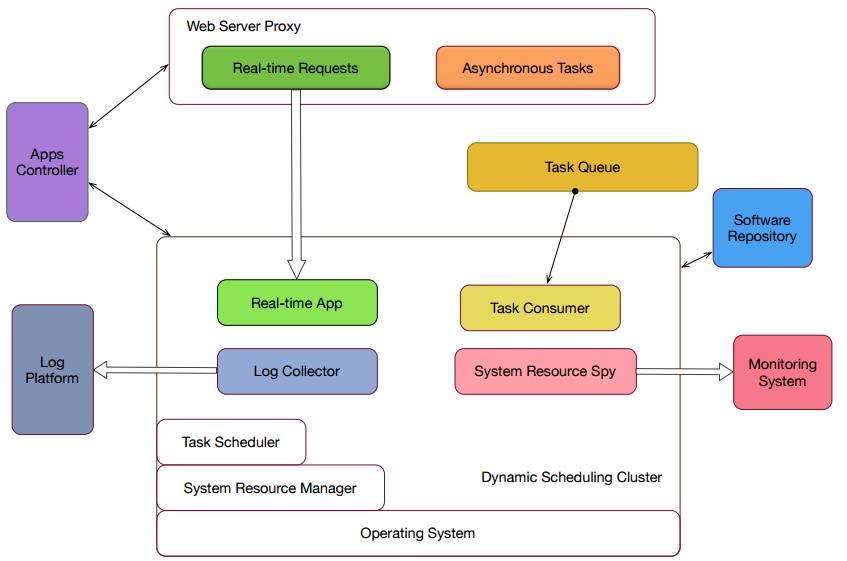
△ UPONE
这是UPONE的配置,主要参考MARATHON配置里面一些必要的属性,group是服务组,下面是名称,下面可以配置一些,ports这个字段是内部监听的断口,下面可以设置一些环境变量等等
我们在新建一个App的时候,首先upone init会生成一份默认的配置,你可以对这个配置进行修改,执行upone deploy。如果你是一个WebServer 还执行一下upone app NAME sync,把服务列表更新到Slardar上去。

△ 新建App
弹性扩容非常简单,只需要直接来一个命令 :
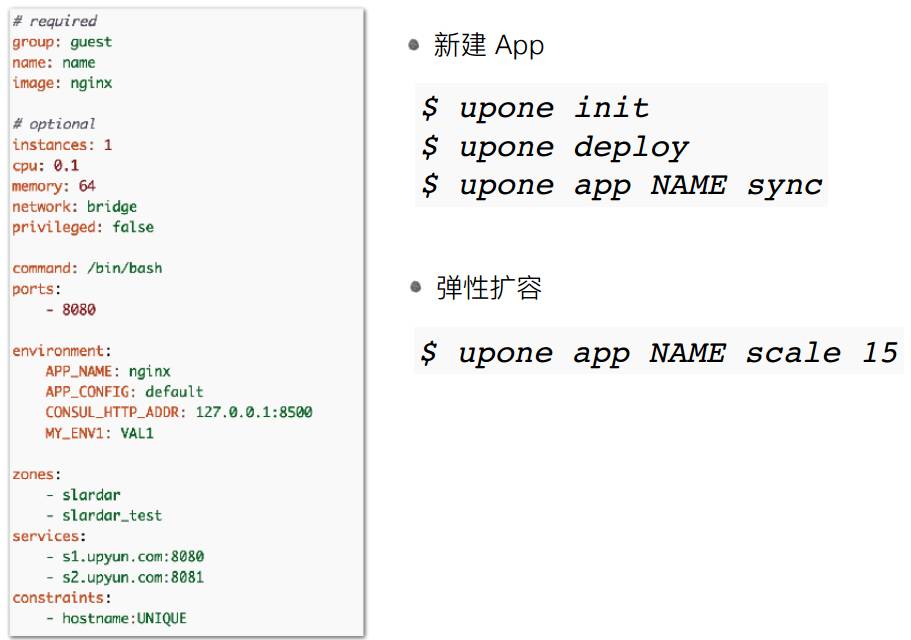
△ 弹性扩容
App更新,一般情况下除了 docker image其他不需要改变。

△ App更新
△ 私有云架构
上图就是整个私有云架构。但是我们可以做得更多,现在有很多数据可以进行分析,比如Nginx日志也就是Slardar日志,有ES数据、还有音视频处理的队列长度,可以通过数据分析做这么几件事情:
自动扩容
异常节点摘除
整合资源
最后总结一下,我们整个私有云平台用了很多开源的组件,Docker/Mesos/Marathon 是我们的基础框架,利用GitLab-CI做Docker镜像持续交付,Nginx+Lua实现了动态服务路由Slardar,使用Heka/Kafka做日志采集,ElaticSearch/Kibana做数据分析展现,用Python/Go/Slack做监控告警平台。充分的拥抱开源,在开源的基础上增加一些个性化的feature,这就是我们的私有云。
谢谢大家!
以下为QA环节
Q1:您好,听了您的演讲受益匪浅。又拍云现在网络模型是怎样的?跨主机是怎么沟通的?有互通的吗?
A1:用Docker原生的网络,没有做其他的改造。因为又拍云现在托管的服务以CPU密集型为主,IO这边还没做考虑,可能之后会采用Mesos提供的CNI这个组件。
Q2:您好,我有个问题想请教。关于你们自己开发的工具alertman,我想问一下你们为什么自己开发呢?据我了解ES的集成,提供的有一些第三方监控工具,为什么你们自己开发?你们自己开发这个东西,能介绍一些更多的细节么?它和ES是如何集成的?要监控我肯定要查询数据,这一块你们是如何做到很方便查询的呢?设计上的细节能简单介绍一下么?
A2:我们主要是拿它做告警的,查询是通过ElasticSearch查询的。做的是ES 5分钟的数据。为什么要做?因为我们有很多自己的需求,比如说5XX,后端服务会吐一些504、502这些状态码,我们会监控这些状态码,之后我们会做一个逻辑,现在还在测试阶段,我们会分析所有后端节点,如果发现这个节点502特别多,会把这个节点立刻摘掉。
Q3:你的监控是基于Slardar统计结果上。
A3:对,我们更加偏向在业务层面做异常节点摘除。
Q4:您好,我想问一下预收集的问题。程序员一般更关注通过日志定位问题,然后我们监控是通过耗时、CPU这些日志监控整个系统的健康和稳定,你们这个日志是统一打到一个里面然后统一抽出来之后再做分析再往不同的地方送,还是在原来打的时候就已经分散到各个不同的日志里面?
A4:日志这块我们是直接输出到标准输出里面,直接通过Docker API来看它的日志。会把日志汇总到kafka,像你这样的需求需要再写一些消费者来消费。我们这个架构现在是这样来做。
Q5:您好,我想问的是日志收集,如果你应用比较大的话,产生的日志文件会有很多,日志序列是怎么保证的?
A5:我们是按照hostname汇总日志的,同一容器内的日志可以保证日志的先后顺序。
以上是关于开源组件搭配DockerMESOSMARATHON,不要太配哦 | 又拍云企业容器私有云架构的主要内容,如果未能解决你的问题,请参考以下文章
You-Get开源在线下载神器,搭配python更加丝滑(文中案例演示)
You-Get开源在线下载神器,搭配python更加丝滑(文中案例演示)