Speedy:来自京东的Docker镜像存储系统
Posted InfoQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Speedy:来自京东的Docker镜像存储系统相关的知识,希望对你有一定的参考价值。
镜像是Docker项目最大的创新点之一,所有的Docker容器都源于镜像。不可否认镜像存储是Docker工作流中的重要一环,Docker Registry是官方提供的开源项目用以保存镜像,同时它也提供了后端存储系统来解决镜像的落地问题,比如Local Filesystem、S3、Swift。Speedy是由京东开源的一个分布式镜像后端存储系统,在架构设计上更好的解决了扩展性和可用性的问题。就Speedy项目的更多细节,InfoQ采访了其负责人田琪。另外,田琪也是也是全球架构师峰会北京站2015《云服务架构探索》专题的出品人。
田琪,京东资深架构师。10年互联网行业从业经验,分别就职于搜狐、新浪、腾讯、京东等公司,目前负责京东云主机及云数据库的架构及研发工作,曾在新浪微博负责新浪微博的底层平台研发工作,主导了Redis在新浪微博的大规模定制开发与应用。之后加入腾讯负责腾讯大规模分布式存储项目的研发与架构工作,为腾讯众多业务产品线提供高可靠的存储服务。
InfoQ:能否介绍下你们的Docker镜像存储系统Speedy?为什么要做Speedy?
田琪:我们通过Docker搭建了我们的弹性计算云平台,服务于公司内外各项业务。在搭建整个平台过程中遇到了很多问题,存储是其中一项待解决的问题。Docker官方提供了Docker Registry服务,但是最终的镜像文件落地存储并没有提供,目前支持的第三方存储服务主要是S3、Swift等。
我们也调研了一些开源分布式存储项目。发现主要存在几个问题:一是架构上倾向于无中心,或者一致性哈希等方式管理存储节点,运维方面我们比较担心可控性问题,另外增减机器都需要涉及文件数据的迁移,不利于线上系统稳定。二是大多开源方案都没有提供高性能的存储引擎,即只提供了数据分布的算法,但数据落地没有提供存储层的优化,这样产生大量文件时就会存在性能问题。三是针对大文件没有特别的优化措施。
认识到这些问题后,我们决定自己研发分布式存储系统,来解决和优化上述的问题。
InfoQ:能否介绍下Speedy整体的后端流程和逻辑?
田琪: Speedy架构如下图:
Speedy本身主要涉及模块:
Docker Registry Driver
ChunkMaster
ChunkServer
ImageServer
Docker Registry Driver是一个遵照Docker Registry 1.0协议实现的驱动,完成Docker Registry与后端存储系统的对接工作。ChunkServer与ChunkMaster组成了一个通用的对象存储服务,ChunkMaster是中心节点,缓存了所有ChunkServer的信息,ChunkServer本身是最终镜像数据落地的存储节点,多个ChunkServer会构成一个组,拥有唯一的组ID,上传这个组内的所有ChunkServer都成功才算成功,下载可以随机选择其中一个节点下载。
ImageServer本身是一个无状态的Proxy服务,它相当于是后面通用对象存储服务的一个接入层,Driver发起的镜像上传、下载操作会直接发给ImageServer,ImageServer中缓存了ChunkMaster中的存储节点信息,通过这些信息,ImageServer会进行ChunkServer节点的选择操作,找到一组合适的ChunkServer机器完成镜像的上传或下载操作。
上传流程
首先我们通过docker push命令发起上传镜像的操作,Docker本身会进行多次与后端存储系统的交互(这里我要简单吐个槽,合理的情况是这个结构化数据和非结构化数据分开存储,Docker本身用JSON表示结构化的描述信息,也是上传到后端存储系统的,个人觉得Docker的元数据管理方面很混乱),最后一次交互是上传镜像的layer数据到Docker Registry。
如果使用默认的本地存储,Docker Registry就直接把数据写到了磁盘上,我们这里通过自己实现的Driver完成与后端对象存储系统的上传工作。
我们的Driver首先会对源源不断上传过来的字节流进行切割,按照配置的固定大小并发上传到ImageServer中,并在上传的HTTP请求中携带了该分片的索引及位置信息。
ImageServer在收到该分片上传请求后,根据自己从ChunkMaster中同步过来的chunk信息来动态选择一组ChunkServer,并将分片上传到该组ChunkServer中的所有实例上,都成功才返回成功。并将分片索引位置信息及上传成功返回的文件ID提交给MetaServer保存Driver在收到所有分片的上传成功返回后,再返回给前端Docker,整个上传流程结束。
下载流程
首先Docker通过docker pull请求下载镜像,同样在真正下载数据开始前,Docker同Docker Registry以及后端的存储系统间也会产生多次的数据交互,这里省略,最后一步是下载对应的Image Layer数据。Docker Registry在收到下载请求后首先通过ImageServer从MetaServer里获取到该文件path对应的分片信息,主要是分片的个数,及每一片的索引,然后将这些分片下载请求并发的发送给ImageServer服务器。
ImageServer收到分片下载请求后,查询MetaServer获得对应的文件ID,该文件ID中包含有ChunkServer的位置信息,随后请求相应ChunkServer下载数据并返回给Driver。Driver收到分片下载的数据后,会根据分片的位置索引进行 排序,按文件分片顺序返回给Docker。
InfoQ:相比来说,Speedy有哪些优势?
田琪:我们系统设计主要考虑几点:
1.架构倾向于简单、可控、容易部署
2.提供Linux C编写的高效存储引擎,存储上将多个小文件合并成一个大文件存储,减少元数据 存储空间开销和性能开销,同时在原生文件系统上通过预分配空间方式,提供接近裸盘的读写性能,但兼具原 生文件系统的易用性。
3.针对大文件做优化,提供断点续传、失败重试等功能。
InfoQ:Speedy的官网提到目前已经支持Registry 1.0,接下来有没有计划支持2.0?
田琪: Registry 2.0主要是针对安全和性能方面做了一些改进,具体可以参考GitHub上的说明。目前已经可用。Speedy项目已经给官方提交了针对Speedy的Registry 2.0的驱动,正在等待官方合并。
InfoQ:Speedy的性能如何?
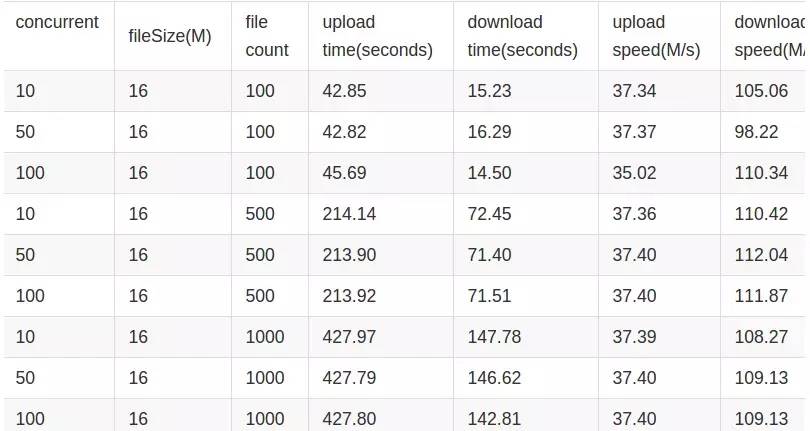
田琪: Speedy提供了高性能的存储引擎,整体系统的瓶颈在于网这一层,我们的测试数据如下,可以看到在千兆网络环境下,上传和下载都达到了网卡的性能瓶颈而不是存储本身,上传是下载性能的1/3,原因是由于上传是三副本的原因,后续我们考虑引入Erasure Code的方式,仍有性能提升空间。
InfoQ:Docker Registry的单点问题,你们有好的解决方案吗?
田琪:我们在线上部署是通过无状态部署多点的方式来解决Registry单点问题的,Docker Registry 1.0服务本身内部没有任何本地存储,所有元数据信息都是通过后端存储系统落地的,所以可以无状态多点部署来解决。
InfoQ:Docker Registry的权限控制,京东内部是如何处理的?
田琪:由于我们的Docker弹性计算云服务是服务于公司内部和生态用户,即实际是一个私有云服务,我们内部本身也不需要搭建类似 Docker Hub的服务,所以并没有严格的权限控制问题。
InfoQ:Docker Registry 1.0的并发性能并不好,从你的分析来看,主要的并发瓶颈在哪里?
田琪:这个问题可以从整体Docker上传镜像流程说起,这个流程本身有很多待改进的地方,从镜像生成的驱动到Docker Registry 1.0的设计都有提升空间,比如镜像生成驱动部分使用Device Mapper等方式都是需要通过比对本地文件系统文件来生成Diff Layer,之后与Docker Registry 1.0产生多次元数据的交互,最后才会发起Layer本身数据的上传下载请求,并且针对大文件也没有任何优化,不支持断点续传等功能。这些环节在 Docker Registry 2.0中有很多改善,相信后续也会持续发展。
作为全球架构师峰会北京站2015《云服务架构探索》专题的出品人,田琪将在为我们呈现哪些内容?
请关注ArchSummit官网二维码
或点击“阅读原文”
更多精彩内容持续更新中...
立即报名可享8折优惠,团购享受更多优惠;
以上是关于Speedy:来自京东的Docker镜像存储系统的主要内容,如果未能解决你的问题,请参考以下文章