使用容器的正确方式,Docker在雪球的技术实践
Posted 51CTO技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用容器的正确方式,Docker在雪球的技术实践相关的知识,希望对你有一定的参考价值。
雪球目前拥有一千多个容器,项目数量大概有一百多个,规模并不是很大。但是得益于容器技术,雪球部署的效率非常高,雪球的开发人员只有几十个,但是每个月的发布次数高达两千多次。
2018 年 5 月 18-19 日,由 51CTO 主办的全球软件与运维技术峰会在北京召开。在“开源与容器技术”分会场,雪球 SRE 工程师董明鑫带来了《容器技术在雪球的实践》的主题分享。
本文主要分为如下三个方面跟大家分享雪球在业务中引入和使用容器技术的心路历程:
为什么要引入 Docker
Docker 在雪球的技术实践
后续演进
雪球是一个投资者交流的社区,用户可以在上面买卖股票,代销基金等各种金融衍生业务,同时也可以通过雪盈证券来进行沪、深、港、美股的交易。
为什么要引入 Docker
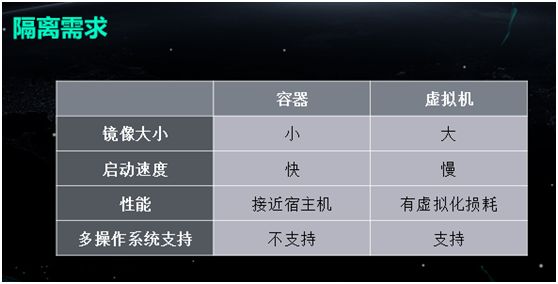
随着业务的发展,不同的社区业务之间所受到影响的概率正在逐渐升高,因此我们希望各个业务之间既能够不被打扰,又能在资源上、机器间、甚至网络上根据监管的要求予以不同层面的隔离。
早在 2014 年时,我们就发现容器技术具有本身镜像小、灵活、启动速度快等特点,而且在性能上比较适合于我们当时物理机不多的规模环境。
相比而言,传统的虚拟化技术不但实现成本高,而且性能损耗也超过 10%。因此,基于对镜像大小、启动速度、性能损耗、和隔离需求的综合考虑,我们选用了两种容器引擎:LXC 和 Docker。
我们把 mysql 之类有状态的服务放在 LXC 里;而将线上业务之类无状态的服务放在 Docker 中。

容器使用方法
众所周知,Docker 是以类似于单机的软件形态问世的,最初它的宣传口号是:Build/Ship/Run。
因此它早期的 Workflow(流程)是:
在一台 Host 主机上先运行 Docker Build。
然后运用 Docker Pull,从镜像仓库里把镜像拉下来。
最后使用 Docker Run,就有了一个运行的 Container。
需要解决的问题
上述的流程方案伴随着如下有待解决的问题:
网络连通性,由于是单机软件,Docker 最初默认使用的是 Bridge 模式,不同宿主机之间的网络并不相通。因此,早期大家交流最多的就是如何解决网络连通性的问题。
多节点的服务部署与更新,在上马该容器方案之后,我们发现由于本身性能损耗比较小,其节点的数量会出现爆炸式增长。
因此,往往会出现一台物理机上能够运行几十个节点的状况。容器节点的绝对数量会比物理节点的数量大一个数量级,甚至更多。那么这么多节点的服务部署与更新,直接导致了工作量的倍数增加。
监控,同时,我们需要为这么多节点的运行状态采用合适的监控方案。
Docker 在雪球的技术实践
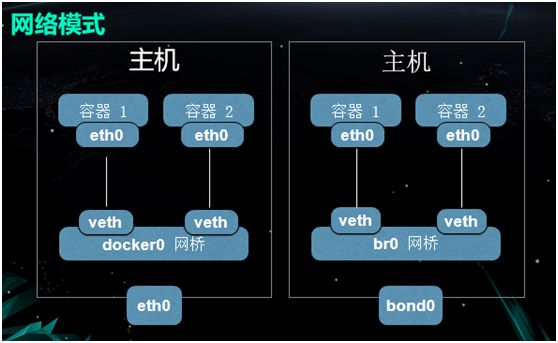
网络模式
首先给大家介绍一下我们早期的网络解决方案:在上图的左边,我们默认采用的是 Docker 的 Bridge 模式。
大家知道,默认情况下 Docker 会在物理机上创建一个名为 docker0 的网桥。
每当一个新的 Container 被创建时,它就会相应地创建出一个 veth,然后将其连到容器的 eth0 上。
由于在生产环境中不只一张网卡,因此我们对它进行了改造。我们产生了一个“网卡绑定”,即生成了 bond0 网卡。我们通过创建一个 br0 网桥,来替换原来的 docker0 网桥。

该网络模式具有优劣两面性:
优点:由于在网络二层上实现了连接互通,而且仅用到了内核转发,因此整体性能非常好,与物理机真实网卡的效率差距不大。
由于整体处于网络大二层,一旦系统达到了一定规模,网络中的 ARP 包会产生网络广播风暴,甚至会偶发出现 PPS(Package Per Second)过高,网络间歇性不通等奇怪的现象。
由于处于底层网络连接,在实现网络隔离时也较为复杂。
服务部署
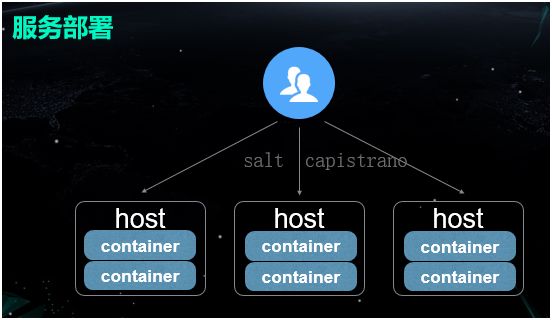
对于服务的部署而言,我们最初沿用虚拟机的做法,将容器启动起来后就不再停下了,因此:
如果节点需要新增,我们就通过 Salt 来管理机器的配置。
如果节点需要更新,我们就通过 Capistrano 进行服务的分发,和多个节点的部署操作,变更容器中的业务程序。

其中,优势为:
与原来的基础设施相比,迁移的成本非常低。由于我们通过复用原来的基础设施,直接将各种服务部署在原先的物理机上进行,因此我们很容易地迁移到了容器之中。
而对于开发人员来说,他们看不到容器这一层,也就如同在使用原来的物理机一样,毫无“违和感”。
与虚拟机相比,启动比较快,运行时没有虚拟化的损耗。
最重要的是一定程度上满足了我们对于隔离的需求。
而劣势则有:
迁移和扩容非常繁琐。例如:当某个服务需要扩容时,我们就需要有人登录到该物理机上,生成并启动一个空的容器,再把服务部署进去。此举较为低效。
缺少流程和权限的控制。我们基本上采用的是原始的管控方式。
自研容器管理平台
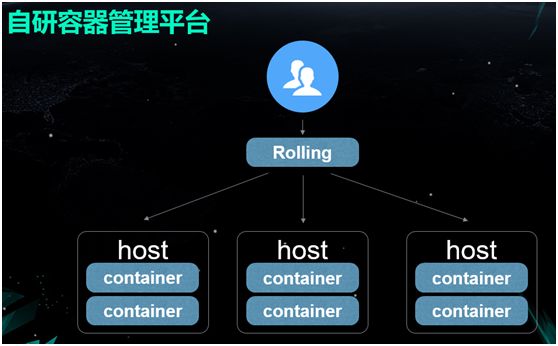
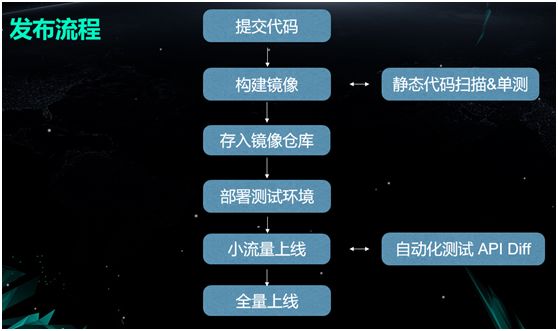
因此我们变更的整套发布流程为:
由开发人员将代码提交到代码仓库(如 Github)之中。
触发一个 Hook 去构建镜像,在构建的同时做一些 CI(持续集成),包括静态代码扫描和单测等。
将报告附加到镜像的信息里,并存入镜像仓库中。
部署测试环境。
小流量上线,上线之后,做一些自动化的 API Diff 测试,以判断是否可用。
继续全量上线。
镜像构建
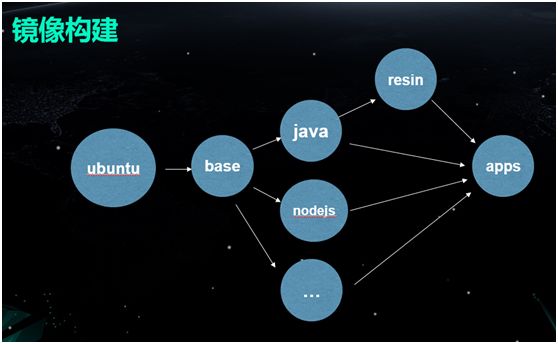
有了容器管理平台,就会涉及到镜像的自动构建。和业界其他公司的做法类似,我们也使用的是基于通用操作系统的镜像。
然后向镜像中添加那些我们公司内部会特别用到的包,得到一个通用的 base 镜像,再通过分别加入不同语言的依赖,得到不同的镜像。
每次业务版本发布,将代码放入相应语言的镜像即可得到一个业务的镜像。构建镜像的时候需要注意尽量避免无用的层级和内容,这有助于提升存储和传输效率。
系统依赖
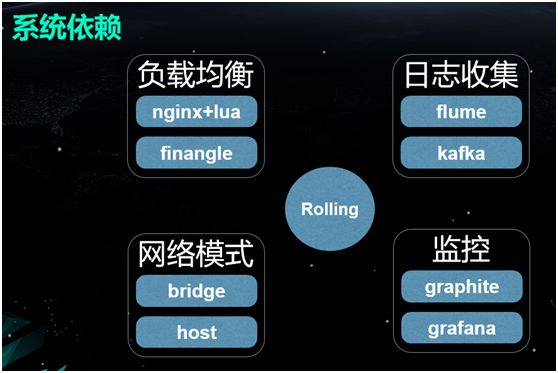
我们的这一整套解决方案涉及到了如下周边的开源项目与技术:
负载均衡
由于会频繁发生节点的增减,我们该如何通过流量的调度和服务的发现,来实现自动加入负载均衡呢?对于那些非 Http 协议的 RPC,又该如何自动安全地摘掉某个节点呢?
我们在此使用了 nginx+Lua(即 OpenResty),去实现逻辑并动态更改 Upstream。
当有节点启动时,我们就能够将它自动注册与加入;而当有节点被销毁时,也能及时将其摘掉。
同时,我们在内部使用了 Finagle 作为 RPC 的框架,并通过 ZooKeeper 实现了服务的发现。
日志收集
由于节点众多,我们需要进行各种日志的收集。在此,我们大致分为两类收集方式:
一类是 Nginx 这种不易侵入代码的,我们并没有设法去改变日志的流向,而是让它直接“打”到物理机的硬盘上,然后使用 Flume 进行收集,传输到 Kafka 中。
另一类是我们自己的业务。我们实现了一个 Log4 Appender,把日志直接写到 Kafka,再从 Kafka 转写到 ElasticSearch 里面。
网络模式
在该场景下,我们采用的是上述提到的改进后的 Bridge+Host 模式。
监控系统
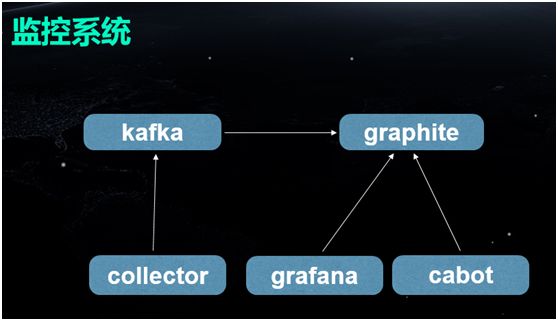
监控系统由上图所示的几个组件所构成。它将收集(Collector)到的不同监控指标数据,传输到 Graphite 上,而 Grafana 可读取 Graphite 的信息,并用图形予以展示。
同时,我们也根据内部业务的适配需要,对报警组件 Cabot 进行了改造和定制。

此时我们的平台已经与虚拟机的用法有了较大的区别。如上图所示,主要的不同之处体现在编译、环境、分发、节点变更,流程控制、以及权限控制之上。我们的用法更具自动化。

由于是自行研发的容器管理平台,这给我们带来的直接好处包括:
流程与权限的控制。
代码版本与环境的固化,多个版本的发布,镜像的管理。
部署与扩容效率的大幅提升。
但是其自身也有着一定的缺点,包括:
在流程控制逻辑,机器与网络管理,以及本身的耦合程度上都存在着缺陷。因此它并不算是一个非常好的架构,也没能真正实现“高内聚低耦合”。
引入 Swarm
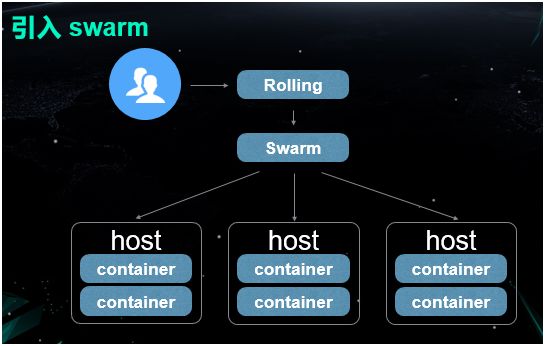
2015 年,我们开始着手改造该容器管理平台。由于该平台之前都是基于 DockerAPI 构建的。
而 Swarm 恰好能对 Docker 的原生 API 提供非常好的支持,因此我们觉得如果引入 Swarm 的话,对于以前代码的改造成本将会降到最低。

因此并不存在网络不通的情况。同时,我们的 Redis 是直接部署在物理机上的。
所以依据上图中各个列表的对比,我们觉得 Calico 方案更适合我们的业务场景。
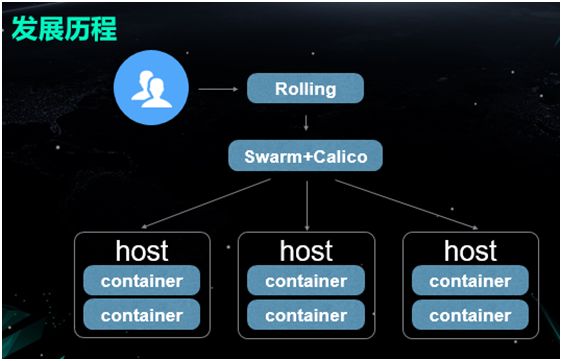
因此,我们在上层使用 Rolling 来进行各种流程的操作,中下层则用 Swarm+Calico 来予以容器和网络的管理。
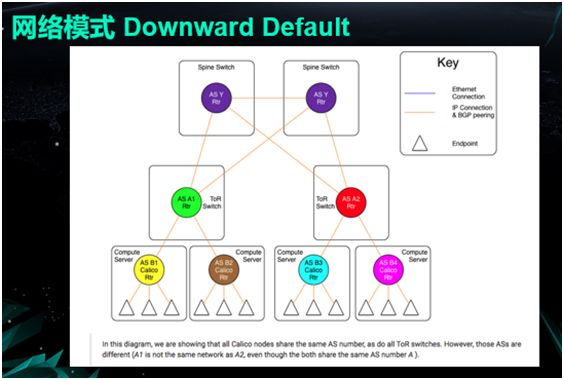
Calico 使用的是 DownwardDefault 模式,该模式通过运用 BGP 协议,来实现对于不同机器之间路由信息的分发。
在默认情况下,Calico 是 Node 与 Node 之间的 Mesh 方式,即:任意两个 Node 之间都有着 BGP 连接。
由于多台物理机同处一个 Mesh,那么每一台机器都会学习到该路由信息。而随着我们系统规模的逐渐增大,每一台物理机上的路由表也会相应地增多,这就会影响到网络的整体性能。
因此我们需要采用这种 Downward Default 部署模式,使得不必让每台物理机都拥有全量的路由表,而仅让交换机持有便可。
众所周知,BGP 会给每一台物理机分配一个 AS(自治域是 BGP 中的一个概念)号,那么我们就可以给各台物理机都分配相同的 AS 号。
而给它们的上联交换机分配另一个 AS 号,同时也给核心交换机再分配第三种 AS 号。
通过此法,每一台物理机只会和自己上联的交换机做路由分发,那么当有一个新的节点启动之后,我们便可以将这条路由信息插入到该节点自己的路由表中,然后再告知与其相连的上联交换机。
上联交换机在学习到了这条路由之后,再进一步推给核心交换机。
总结起来,该模式的特点是:
单个节点不必知道其他物理机的相关信息,它只需将数据包发往网关便可。因此单台物理机上的路由表也会大幅减少,其数量可保持在“单机上的容器数量 +一个常数(自行配置的路由)”的水平上。
每个上联交换机只需掌握自己机架上所有物理机的路由表信息。
核心交换机则需要持有所有的路由表。而这恰是其自身性能与功能的体现。
当然,该模式也带来了一些不便之处,即:对于每一个数据流量而言,即使目标 IP 在整个网络中并不存在,它们也需要一步一步地向上查询直到核心交换机处,最后再判断是否真的需要丢弃该数据包。
后续演进
在此之后,我们也将 DevOps 的思想和模式逐步引入了当前的平台。具体包括如下三个方面:
通过更加自助化的流程,来解放运维。让开发人员自助式地创建、添加、监控他们自己的项目,我们只需了解各个项目在平台中所占用的资源情况便可,从而能够使得自己的精力更加专注于平台的开发与完善。
如今,由于 Kubernetes 基本上已成为了业界的标准,因此我们逐步替换了之前所用到的 Swarm,并通过 Kubernetes 来实现更好的调度方案。
支持多机房和多云环境,以达到更高的容灾等级,满足业务的发展需求,并完善集群的管理。

上图展示了一种嵌套式的关系:在我们的每一个 Project 中,都可以有多个 IDC。
而每个 IDC 里又有着不同的 Kubernetes 集群。同时在每一个集群里,我们为每一个项目都分配了一个 Namespace。
根据不同的环境,这些项目的 Namespace 会拥有不同的 Deployment。例如想要做到部署与发布的分离,我们就相应地做了多个 Deployment,不同的 Deployment 标示不同的环境。
默认将流量引入第一个 Deployment,等到第二个 Deployment 被部署好以后,需要发布的时候,我们再直接把流量“切”过去。
同时,鉴于我们的平台上原来就已经具有了诸如日志、负载均衡、监控之类的解决方案。
而 Kubernetes 本身又是一个较为全面的解决方案,因此我们以降低成本为原则,谨慎地向 Kubernetes 进行过渡,尽量保持平台的兼容性,不至让开发人员产生“违和感”。
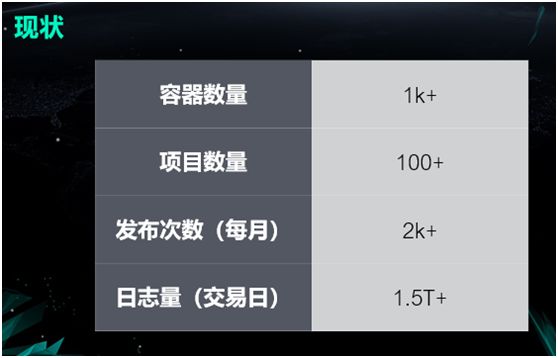
如今,我们的容器只有一千多个,项目数量大概有一百多个。但是我们在部署效率方面的提升还是非常显著的,我们的几十个开发人员每个月所发布的次数就能达到两千多次,每个交易日的日志量大概有 1.5T。
编辑:陈峻、陶家龙、孙淑娟
投稿:有投稿、寻求报道意向技术人请联络 editor@51cto.com
董明鑫,雪球网运维开发架构师,曾就职百度,2014 年加入雪球,目前主要负责保障雪球稳定性、提升资源利用率及提高开发效率等方面。关注容器生态圈的技术发展。
精彩文章推荐:
以上是关于使用容器的正确方式,Docker在雪球的技术实践的主要内容,如果未能解决你的问题,请参考以下文章