异常检测 -- Kibana5.4时间序列分析
Posted bytebees
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了异常检测 -- Kibana5.4时间序列分析相关的知识,希望对你有一定的参考价值。
一个复杂的系统在许多方面都可能出现问题,这些问题可简单分为两类:一类是可以预料到的问题,比如磁盘失败,这种问题会重复发生并且可以被直接验证;另一类是无法预期的——本文主要是针对这类问题展开。
应对这种无法预期的问题,一个有效的工具就是统计学。用统计学的方法检测到异常点然后触发报警是我们的异常检测系统所做的工作。统计学的强大之处在于能够捕捉到新出现的问题;而不足之处是需要进一步跟踪和查询到问题根源。
建立一个有效的异常检测器最大的挑战是如何减少误报。如果一个报警系统存在很多误报,用户的通常做法就是将它关闭,或者将报警扔到垃圾箱,更常见的就是直接忽略这些报警,那这样的报警系统就没有太大的存在意义。

eBay所使用的方法就是基于统计学的异常检测。我们的查询系统中的监控信号是基于定时发布的参考查询结果得到的。系统需要先将这些监控信号进行编码得到一些数字集合——这项通过对查询结果进行指标的计算实现。对于每次查询,都可以计算50个左右相关的指标来对查询结果做归纳总结。比如某次查询结果集中物品的数量,查询结果集里所有物品价格的中位数,这就是2个不同的指标。我们有3000个参考查询,每个都可计算50个指标,所以就会产生150,000个指标;现在参考查询定时每4个小时发布一次,因此一天会产生900,000个指标。对于现在TB级别的数据库来说这个量是很小的,问题是如何从这么多数据中筛选出异常值,并且尽可能避免误报。
下图是一次发布的参考查询和每个多对应的指标图:
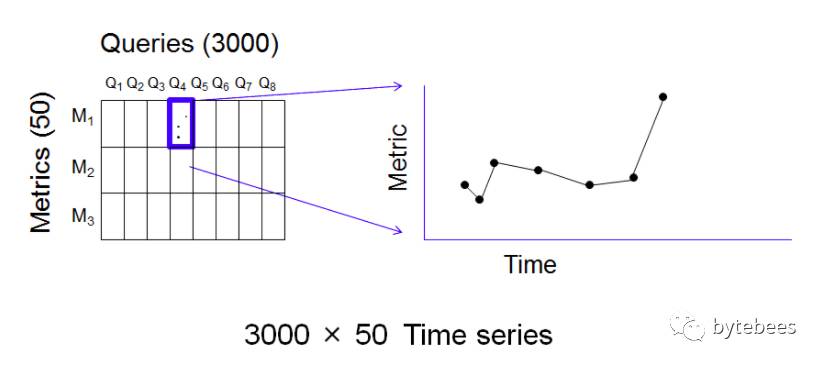
每一对(query,metric)都是一个随时间变化的数字,所以可以由查询q和指标m确定一个时间序列。因此每个时间窗(这里是4个小时)有150,000个时间序列生成。这么多的时间序列偶然出现一个异常报警是极有可能的,所以对每个时间序列分别进行监控报警是不现实的,将产生过多误报。
我们的解决方案就是聚合,想法很简单:检查每个时间序列并计算最近一个点的实际值和期望值(期望值是由历史值计算得到)之差——这个差值称为“意外”(surprise)。所以对每个查询q和指标m,在任意一个时间点t处就有一个意外值:
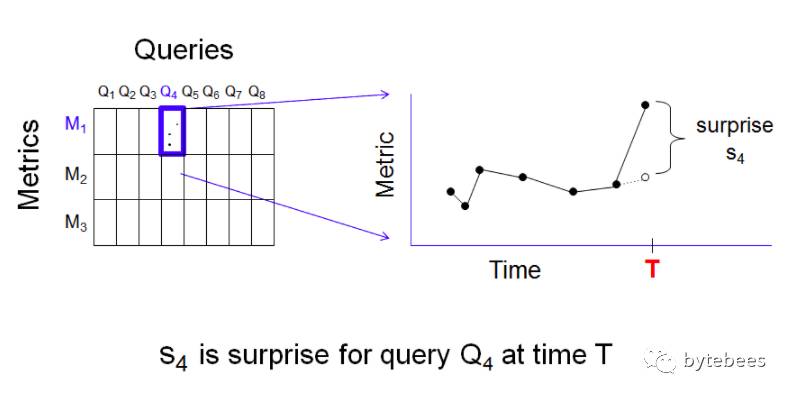
异常检测的思路是:固定一个时间点T,期望只有少数几个(q,m,T)存在较大的意外;假如出现了多个较大的意外值,就认为是异常需要进行报警。为了将这种方法量化,固定一个指标m,对所有3000个查询计算意外值,并算出这些意外值在时间T处的90百分位数S90(T):

由此每个指标所有查询的90百分位数构成了一个新的时间序列。假设两个指标的S90时间序列如下:
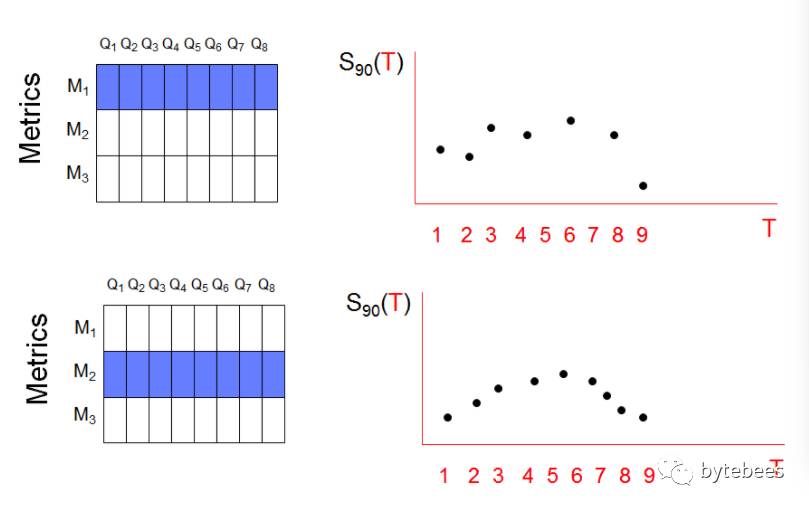
至此,我们将原先的150,000个时间序列减少到了50个。这种聚合手段对于异常检测是十分有效的。我们在这种时间序列的聚合方法基础上做简单的统计:计算最终得到的50个序列的均值avg和方差σ,如果一个序列值大于avg+3σ则认为是异常值。
以上是关于异常检测 -- Kibana5.4时间序列分析的主要内容,如果未能解决你的问题,请参考以下文章