专题6LogStash采集数据到kafka
Posted 择码记
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了专题6LogStash采集数据到kafka相关的知识,希望对你有一定的参考价值。
【背景】
当前大数据日志采集框架中,最火的莫过于 Flume 和 LogStash。
但 Flume 存在缺陷,
假如 Flume 如果宕机,重新启动后,
再次采集的数据可能存在数据丢失或者数据重复采集的问题。
如果要解决这个问题,需要自己去想办法维护偏移量。
有没有更简便的解决方案呢?
当然有,就是使用 LogStash。
【简介】
LogStash 是当前比较火的 ELK 技术栈成员之一,
它能够保证数据不重复消费,不丢失。
ELK:ElasticSearch,Logstash,Kibana
Logstash 有三个组件:
input:读取数据源,相当于 flume 的 source;
filter:可以过滤整理数据;
output:将数据写入到某种存储介质中。
【实战】
下载 Logstash
https://www.elastic.co/downloads/logstash
这里下载的是 2.3.1 版本:logstash-2.3.1.tar.gz
如今共有三个节点,其主机名和ip为:
mini5 192.168.87.155
mini6 192.168.87.156
mini7 192.168.87.157
将 Logstash 安装包上传到 mini5,解压:
[hadoop@mini5 ~]$ tar -zxvf logstash-2.3.1.tar.gz -C apps/
配置文件:
我们要采集文件日志写入到kafka。
[hadoop@mini5 ~]$ cd apps/logstash-2.3.1/
[hadoop@mini5 logstash-2.3.1]$ vi flow-kafka.conf
input {
file {
path => "/var/nginx_logs/*.log"
discover_interval => 5
start_position => "beginning"
}
}
output {
kafka {
topic_id => "accesslog"
codec => plain {
format => "%{message}"
charset => "UTF-8"
}
bootstrap_servers => "mini5:9092,mini6:9092,mini7:9092"
}
}
注1:
path => "/var/nginx_logs/*.log",
该采集文件路径为专题5埋点采集日志的文件,
具体可以参见专题5:
注2:
bootstrap_servers => "mini5:9092,mini6:9092,mini7:9092",
注3:
topic_id 为将要输入到 kafka 的 topic,此处设为 accesslog,
则在 kafka 集群中要先创建相应的 topic。
启动 ZooKeeper:
[hadoop@mini5 ~]$ startzk.sh
startzk.sh 脚本内容:
#/bin/sh
echo "start zkServer..."
for i in 5 6 7
do
ssh mini$i "source /etc/profile;/home/hadoop/apps/zookeeper-3.4.6/bin/zkServer.sh start"
done
启动 Kafka
[hadoop@mini5 ~]$ startKafkaServers.sh
startKafkaServers.sh 脚本内容:
#/bin/sh
KAFKA_HOME=/export/servers/kafka
KAFKA_LOG=/export/servers/log
echo "start kafkaServers..."
for i in 5 6 7
do
ssh mini$i "source /etc/profile;cd $KAFKA_HOME;bin/kafka-server-start.sh config/server.properties >> $KAFKA_LOG/kafka.log 2>&1 &"
echo "mini$i kafkaServer has started..."
done
创建主题
[hadoop@mini6 ~]$ cd /export/servers/kafka
[hadoop@mini6 kafka]$ bin/kafka-topics.sh --create --zookeeper mini5:2181,mini6:2181,mini7:2181 --replication-factor 3 --partitions 3 --topic accesslog
查看主题是否已创建
[hadoop@mini6 kafka]$ bin/kafka-topics.sh --list --zookeeper mini5

启动 Logstash
[hadoop@mini5 logstash-2.3.1]$ bin/logstash agent -f flow-kafka.conf

监视 mini5 收集到的日志
[hadoop@mini5 ~]$ cd /var/nginx_logs/
[hadoop@mini5 nginx_logs]$ tail -F track.log

打开 kafka 消费者客户端查看日志
[hadoop@mini6 kafka]$ bin/kafka-console-consumer.sh --bootstrap-server mini5:9092 --topic accesslog --from-beginning

浏览相关网页
http://mini6
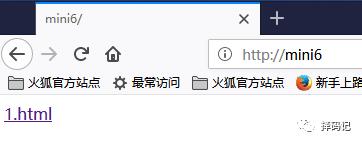
点击
1.html
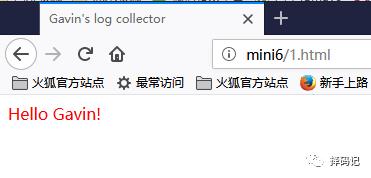
发现监视的文件 track.log 增加了新的记录
同时kafka 客户端也消费到新的数据了
说明 Logstash 采集数据到 kafka 成功!
———————————分割线———————————
阅后来撩啊:
未关注的,文章开头右上角,请亲戳"择码记"关注哦~
觉得文章不错,请亲点赞哦~
觉得可能对别人有帮助,请亲分享哦~
觉得为您共享了价值,请壕打赏哦~
版本所有:Gavin Hawk
择码记扣扣群:579522954,欢迎小伙伴们一起学习分享交流哦~
谢谢亲支持哟!
另:
感谢您的阅读~
择码记将持续发布高质量的文章,诚意满满,干货满满,以期对您有所帮助!
若您要查看章节,请直接输入“1”,即可跳转到第一章。以此类推。
有些章节分上下两篇,如第三章有“3_1”和"3_2",
则输入“3_1”即可出来上篇,以此类推。
若您需要查看某方面相关文章,可直接输入试试,比如“Spark部署”、“combineByKey”等。
包含:1, 2, 3_1, 3_2, 4_1, 4_2, 5_1, 5_2, 6, 7, 8 共 11 篇文章;
专题:专题1,专题2,专题3,专题4,专题5,专题6
官方翻译:3#1
Hadoop 生态圈:0#1, 0#2, 0#3, 0#4
认知:认知1,认知2
以上是关于专题6LogStash采集数据到kafka的主要内容,如果未能解决你的问题,请参考以下文章