Artery平台的Logstash日志
Posted Artery平台
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Artery平台的Logstash日志相关的知识,希望对你有一定的参考价值。
Artery平台即将发布的1.3版本,相比Artery 1.2版本,新增了很多功能。其中一个重要的功能升级,就是引入了ELK日志分析和采集机制,通过Elasticsearch+Logstash+Kibana日志采集工具,对日志进行采集和分析,实现对日志更有效的管理。
本文阐述ELK日志管理工具中Logstash收集日志的工作原理,以及收集Artery平台上工作日志的方法。
Artery平台采用ELK日志管理的优势
Artery 1.3之前版本的不足
Artery1.3之前的版本,对日志的管理和打印,基本采用log4j.properties机制。该机制存在的缺陷如下:
1. 缺乏有效的管理机制,无法系统管理日志记录。
2. 缺乏有效的分析机制,无法通过对日志的分析判断系统的运行状态。
3. 缺乏有效的展示机制,日志输出展示比较困难。
项目组也曾因为客户对某些交易特殊要求,在日志的分析处理以及输出展示上花费了不少精力。所以亟待更有效的日志管理机制。
Artery 1.3引入ELK日志管理系统的优点
新的Artery1.3版本,对日志采集及分析功能,采用了Elasticsearch+Logstash+Kibana的日志管理模式,即ELK机制。主要工作原理是通过将采集的日志建立关键字段索引后,可通过UI进行分散日志的统一管理,并可根据某个索引字段进行汇总统计分析。
ELK日志采集和分析,主要是通过Logstash进行日志采集,并推送至Elasticsearch进行分析,最后在Kibana中进行图形化展示。其中数据分析是Elasticsearch与Kibana的核心模块,Elasticsearch提供分析功能,kibana提供图形渲染功能。
通过ELK日志采集分析系统,建立起了简单高效的对Artery平台的日志管理机制,使整体流程变得更为实用便捷,提高了日志管理的效率。
Logstash收集日志的工作原理
Logstash的插件组成
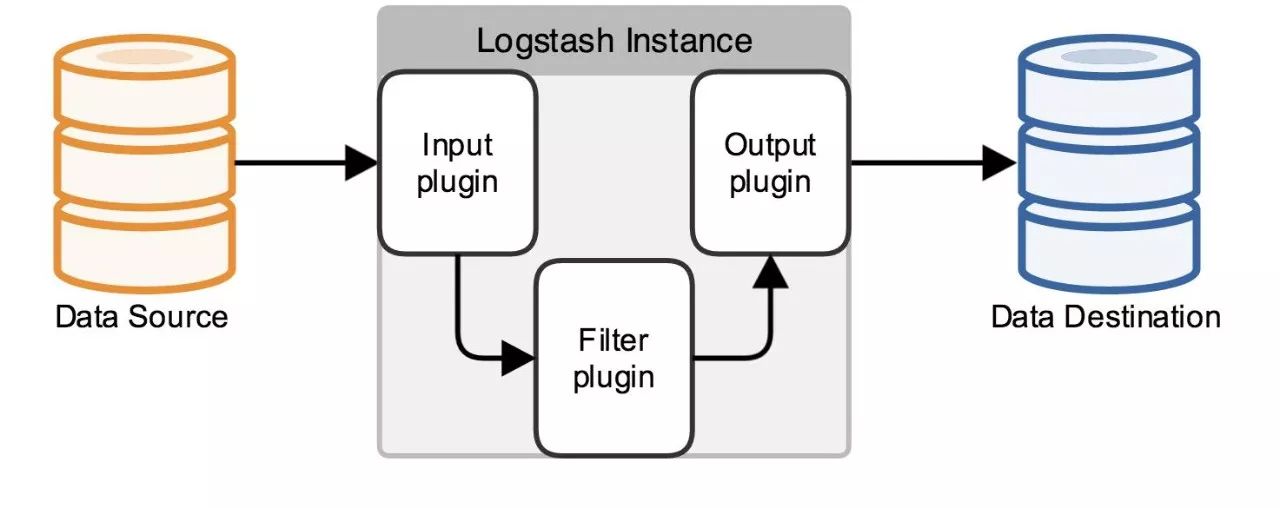
Logstash根据logstash.conf配置文件对数据源进行数据读取和清洗,并将清洗结果写入指定的目标文件,也可以在Elasticsearch上展示。其基本工作模式如下图所示。
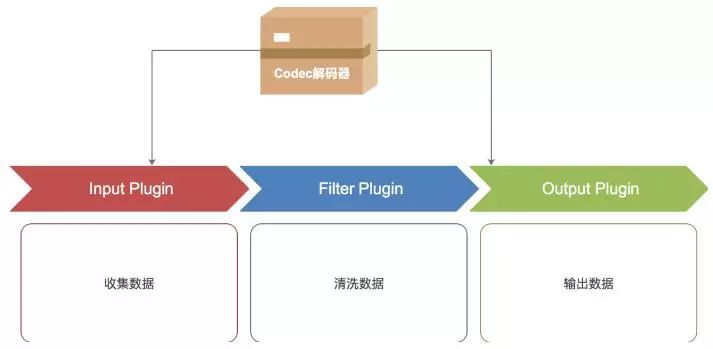
可以看出,Logstash由输入(Input)、清洗(Filter)和输出(Output)三部分插件构成,所以logstash的配置也分为Input、Filter和Output三部分。
1. Input插件
Input负责从logstash的数据来源中读取数据,并把读取到的数据传递给Filter插件进行过滤和解析。常用的Input插件主要有:
stdin——从标准输入中读取数据
file——从本地文件中读取数据
tcp——从网络中读取数据
log4j——从log4j发送过来的信息中数据。
2. Filter插件
Filter插件负责过滤和解析从Input中读取的数据,并将处理过后的数据传递给Output插件输出。常用的Filter插件主要有:
grok——通过正则解析任意文本,将非结构化日志数据弄成结构化和方便查询的结构。
date——从日志中解析时间,然后使用该时间作为logstash的事件时间戳。
mutate——提供了丰富的基础类型数据处理能力,包括类型转换,字符串处理和字段处理等。
json——在日志消息中提取和解析JSON 数据结构。
3. Output插件
Output插件负责将Filter处理过的数据输出,常用的Output插件主要有:
stdout——将数据输出到标准输出。
file——将数据输出到指定的文件中。
elasticsearch——将数据输出到Elasticsearch上展示。
4. Codecs插件
codecs 是基于数据流的过滤器,它可以作为input,output的一部分配置。Codecs可以帮助你轻松的分割发送过来已经被序列化的数据。流行的codecs包括json,msgpack,plain(text)。
json——使用json格式对数据进行编码/解码
multiline——将汇多个事件中数据汇总为一个单一的行。比如:java异常信息和堆栈信息
要获取更多的配置信息,可以参考Logstash文档中 "plugin configuration"部分。
Logstash命令
Logstash命令,即为将input中定义的输入数据经过Filter定义的规则清洗过后输出到output定义的区域中。
执行比较简单的命令时,可以用logstash-e命令,不写任何配置文件直接执行,如下面两个简单的例子:
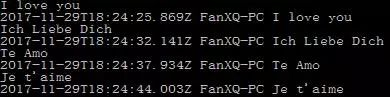
将标准输入的内容直接输出到控制台:
logstash -e 'input { stdin { } } output { stdout{} }'
输出效果如下:
输出内容到Elasticsearch:
logstash -e 'input { stdin { } } output {elasticsearch { host => localhost:9200 } }'
输入与上面的例子相同,输出效果如下:(Elasticsearch默认端口为9200)
但当配置参数较多时,则需要在bin目录下建立配置文件logstash.conf,在logstash.conf文件中配置Input、Filter和Output插件,并用logstash -f命令执行logstach.conf配置文件,便可按照logstash.conf中的配置收集数据。
Logstash收集Artery日志
要收集Artery平台上产生的日志,将Artery平台上产生的日志文件的路径写入logstash.conf配置文件中,Logstash便可自动手机该路径下的配置文件。示例如下:

配置完毕后,进入Logstash安装目录的bin目录下,输入命令:
logstash -f logstash.conf
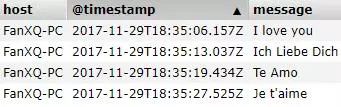
即可开始收集Artery的logs文件夹下产生的Artery工作日志,并传入Elasticsearch展示,如下图所示。
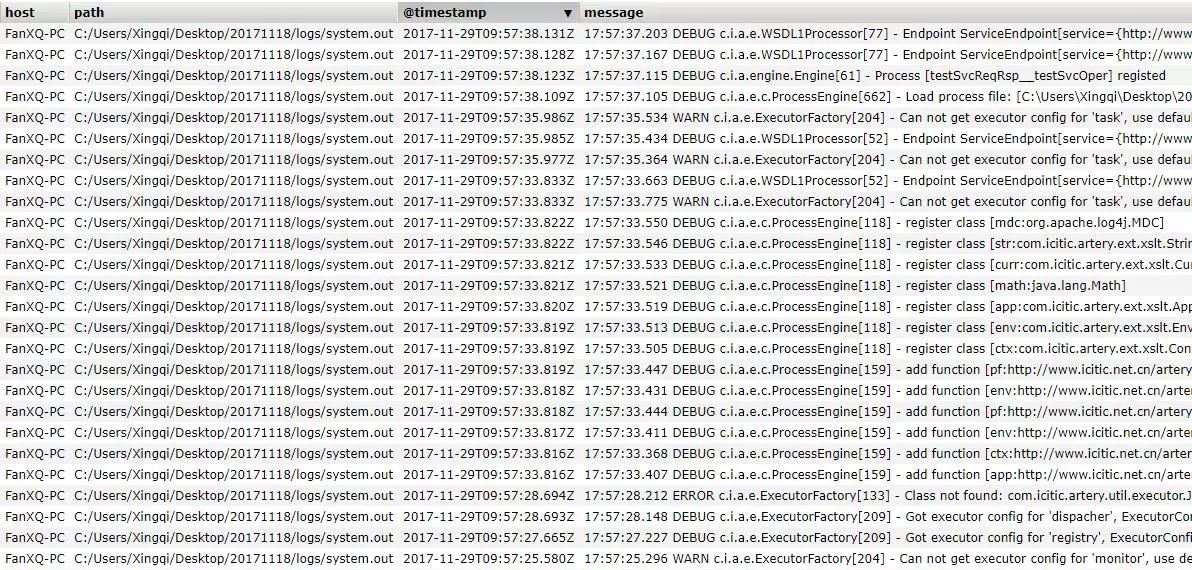
可以看出,Logstash成功地抓取了Artery平台的日志记录,并将其通过Elasticsearch直观展示。Artery1.3通过引用ELK机制,实现了日志的展示,达到了预期的日志定制化的目的。
本文介绍了ELK日志管理工具中Logstash的工作原理以及收集Artery平台上日志的方法,未来还会进一步介绍如何使用Elasticsearch和Kibana进行日志处理与展示,敬请期待。
Artery平台
以上是关于Artery平台的Logstash日志的主要内容,如果未能解决你的问题,请参考以下文章