从秒级查询提升到了毫秒级-财务平台logstash同步ES实战笔记
Posted 消费金融架构
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了从秒级查询提升到了毫秒级-财务平台logstash同步ES实战笔记相关的知识,希望对你有一定的参考价值。
编辑:阿兵
本篇是财务同学在解决大数据性能优化中整理的有价值笔记,是比较有好的总结干货;其实技术人就应该多做总结,知识不是做了就过去了,多总结才能有效变成经验,学会分享,传播所学,逐渐经营自己,感谢小冰同学的投稿,希望更多的人投稿给我。
1. 本文大纲
1、 财务系统使用logstash背景
2、 初识logstash
3、 logstash的安装及配置
4、 优化logstash同步elasticsearch效率优化
2. 背景
财务数据海量,字段较多,多表关联查询,mysql单表无法支持,前期我们通过sharding-jdbc(以下简称sj)进行过一次分库分表,但随着分库分表越来越多,sj基于内存结果归并,当关联表较多以或单表数据依然过大的表的相关查询效率出现瓶颈。在此背景下,财务技术组主要针对业务查询特点为查询频次高,查询纬度多变,查询组合较多,多表关联查询,及对于查询结果实时性无绝对要求(因同步会有一定的延时,本例为一分钟)的数据查询进行了查询优化,从秒级查询提升到了毫秒级,从而大幅度提高系统使用人员的体验性及日常工作效率。
3. 了解logstash
提到logstash,就需要说到ELK,ELK是Elasticsearch、Logstash、Kibana三个开源软件的组合。Logstash 主要是负责其中数据传输的工作,它可以统一过滤来自不同源的数据,并按照开发者的制定的规范输出到目的地,在财务的应用就是从mysql将数据同步到Elasticsearch。
【引】整一套软件可以当作一个MVC模型,logstash是controller层,Elasticsearch是一个model层,kibana是view层。首先将数据传给logstash,它将数据进行过滤和格式化(转成JSON格式),然后传给Elasticsearch进行存储、建搜索的索引,kibana提供前端的页面再进行搜索和图表可视化,它是调用Elasticsearch的接口返回的数据进行可视化。logstash和Elasticsearch是用Java写的,kibana使用node.js框架。
4. Logstash安装及配置
4.1. Linux下安装
Logstash 依赖JDK1.8 ,因此在安装之前请确保机器已经安装和配置好JDK1.8。
ELK版本:Kibana5.5.0,elasticsearch-5.5.0, logstash-5.5.0.
下载Logstash命令:wget https://download.elastic.co/logstash/logstash/logstash-5.5.0.tar.gz
安装命令:tar -zxvf logstash-5.5.0.tar.gz -C /usr
4.2. 组成结构
Logstash 通过管道进行运作,管道有两个必需的元素,输入和输出,还有一个可选的元素,过滤器。
Logstash 是一个input | decode | filter | encode | output 的数据流。
输入插件从数据源获取数据,过滤器插件根据用户指定的数据格式修改数据,输出插件则将数据写入到目的地。如下图:
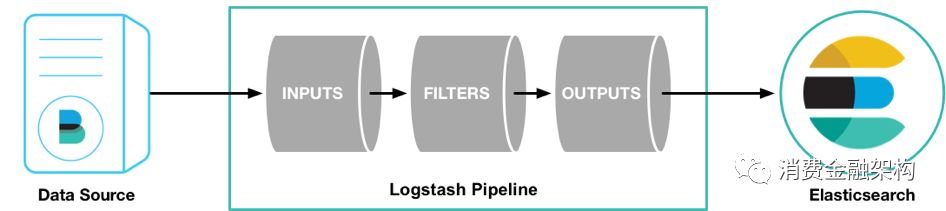
4.3. 启动示例
脚本直接启动:bin/logstash -e 'input { stdin { } } output { stdout {} }'
配置文件启动bin/logstash -f logstash.conf
目录方式启动:bin/logstash -f
财务因设计多库多表的同步,所以采用目录启动方式
4.3.1. 启动所需依赖
mysql-connector-java-5.1.32.jar
4.4. 重要参数说明
数据库设置(MYSQL)
如果要了解其它数据库,可以参考 http://www.cnblogs.com/licongyu/p/5535833.html
jdbc_driver_library => //各个数据库都有对应的驱动,需自己下载
jdbc_driver_class =>//不同数据库有不同的 class 配置
jdbc_connection_string =>//配置数据库连接 ip 和端口,以及数据库
jdbc_user =>//配置数据库用户名
jdbc_password =>//配置数据库密码
Schedule设置
# schedule => 分 时 天 月 年
# schedule => * 22 * * * 每天晚上10点执行一次
schedule => "* * * * *" 一分钟执行一次
财务采用一分钟一次
重要参数设置
财务采update_time作为增量更新标识
//是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run => true
//是否需要记录某个column 的值,如果 record_last_run 为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 timestamp 的值.
use_column_value => true
//如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是单调的.比如:ID.或时间
tracking_column => update_time
//指定文件,来记录上次执行到的 tracking_column 字段的值
//我们只需要在 SQL 语句中 WHERE update_time > :last_sql_value 即可. 其中 :last_sql_value 取得就是该文件中的值(时间戳).
last_run_metadata_path => "/home/soft/logstash-5.5.0/config/config-mysql/config_last_run/bookCapitalPlan/logstash_jdbc_last_run"
//是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录,或者将logstash_jdbc_last_run手动置空也可以从头开始
clean_run => false
//是否将 column 名称转小写
lowercase_column_names => false
//存放需要执行的 SQL 语句的文件位置
statement_filepath => "/home/soft/logstash-5.5.0/config/config-mysql/config_sql/book/bookCapitalPlan/bookCapitalPlan201708.sql"
input:接入数据源
filter:对数据源进行过滤
output: 输出的
配置范例:
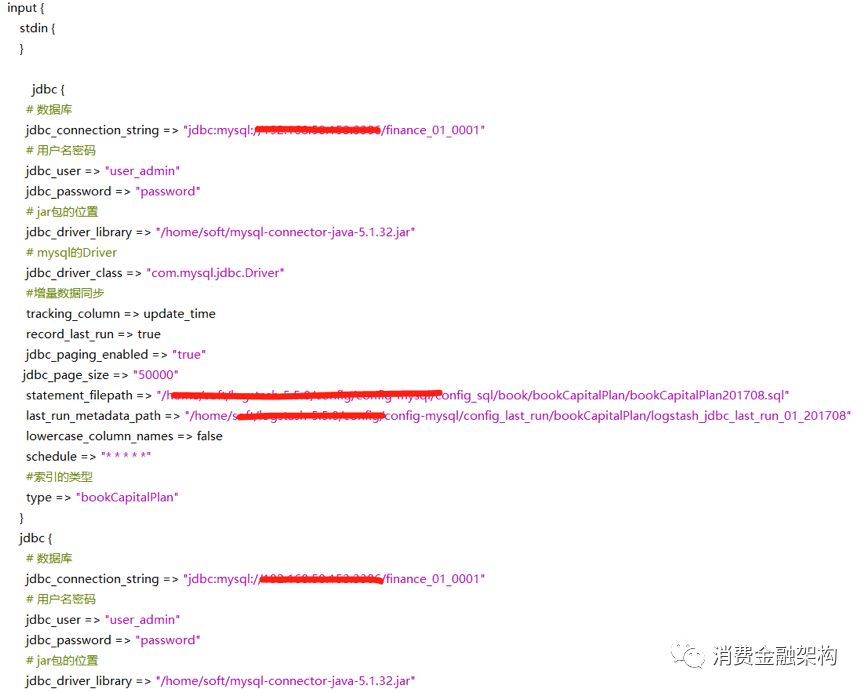
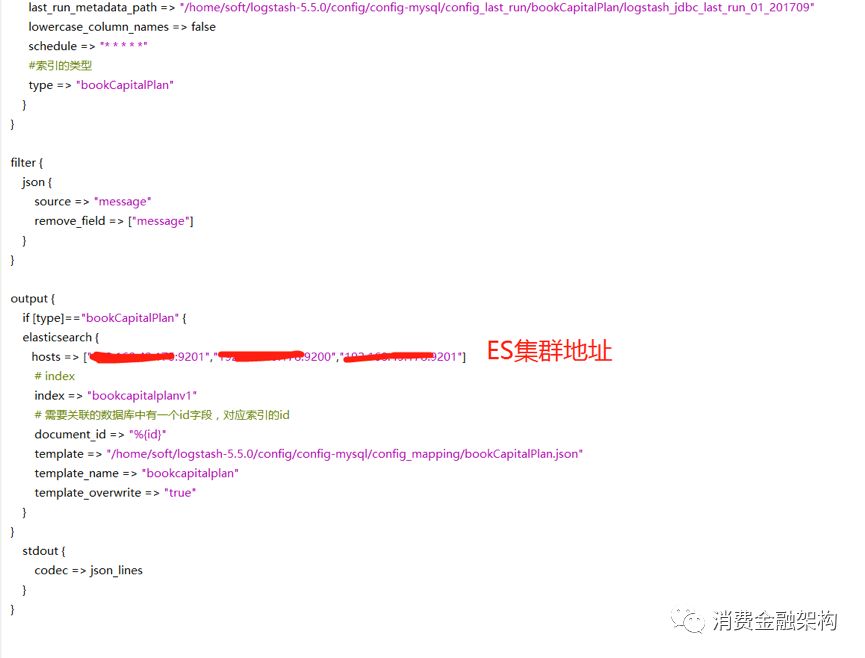


关于模版
一般来说,服务器日志按月建索引,这些索引配置信息是一样的,这些共同的配置信息就可以配置在模板中,包括索引的设置(setting)、映射(mapping)、别名(aliases)等。
在logstash中配置模板方式如下:
(1) 在logstash配置文件的output组件中配置:
template: 模板文件路径
template_name: 模板名称
template_overwrite:覆盖系统默认的模板
(2) 创建模板文件,格式:文件名称.json
模板分为静态模板和动态模板。静态模板适用于字段个数和字段类型固定保持不变的情况,动态模板可以配置字段类型动态映射。动态模板配置举例说明:
{
"template": "bookcapitalrepaymentchargeoff*", //该模板匹配哪些索引,可以使用通配符
"version": 50001,
"order": 1,
"settings": {
"index.refresh_interval": "10s"
},
"aliases": {
"bookcapitalrepaymentchargeoff": {} //别名
},
"mappings": { //映射
"_default_": {
"_all": {
"enabled": true,
"norms": false
},
"properties": {
"id": {
"type": "keyword" //keyword表示精确匹配,text表示全文检索
},
"repayDate": {
"type": "keyword"
},
"payDate": {
"type": "keyword"
},
"bookDate": {
"type": "keyword"
},
"gmtCreated": {
"type": "keyword"
},
"gmtModified": {
"type": "keyword"
},
"principalAmount": { //金额要使用数值类型,否则不能进行聚合运算
"type": "float"
},
"interestAmount": {
"type": "float"
},
"compoundAmount": {
"type": "float"
},
"feeAmount": {
"type": "float"
},
"feeAmountInvoice": {
"type": "float"
},
"manageAmount": {
"type": "float"
},
"manageAmountInvoice": {
"type": "float"
},
"serverAmount": {
"type": "float"
},
"serverAmountInvoice": {
"type": "float"
},
"damagesAmount": {
"type": "float"
},
"lateFeeAmount": {
"type": "float"
},
"fineAmount": {
"type": "float"
},
"otherAmount": {
"type": "float"
},
"advanceFeeAmount": {
"type": "float"
},
"totalAmount": {
"type": "float"
}
},
"dynamic_templates": [{ //动态模板
"message_field": {
"path_match": "message",
"match_mapping_type": "string",
"mapping": {
"type": "text"
}
}
},
{
"string_fields": { //自己指定名称,表示把字符串类型的字段同时映射为两种类型,一种是keyword精确查找,另一种是text全文检索
"match": "*",
"match_mapping_type": "string",
"mapping": {
"type": "keyword",
"ignore_above": 256,
"fields": {
"text": {
"type": "text"
}
}
}
}
}]
}
}
}
注:(1)因为es中字段映射一旦确定就不能修改,所以如果日后索引中需要修改字段类型,则需要重建索引并迁移数据。通常给索引起别名,项目中使用别名,当索引数据迁移完毕后修改别名指向新的索引即可,实现无停机索引迁移。
(2)es默认有字段类型推断,会把字符串映射为keyword和text,根据实际需要使用。
(3)分布式主键是long类型,超过16位会精度丢失,因此同步脚本中可以把id转换为字符串,映射中指定为字符类型
(4)日期字段如果格式确定,则可以使用date类型,指定pattern,但实际项目中数据格式如果不统一则使用字符串。
(5)数值类型中如果既有整型,又有浮点型,最好指定映射类型为浮点型,防止系统先根据整形推断后把类型映射为整形,而后出现浮点型数据引起报错。
注:因本文主要介绍数据库内容同步,没有用到太多filter,如用于日志收集,更多资料:
http://blog.csdn.net/cs13522431352/article/details/76576997
4.5. 同步效率优化
优化前:
---------------------------------------------
2张表合计:259773
分页size:100000
同步用时:15:27~15:35 8分钟
---------------------------------------------
2张表合计:259773
分页size:50000
同步用时:14:54~15:02 8分钟
---------------------------------------------
2张表合计:259773
分页size:10000
同步用时:15:17~15:24 7分钟
---------------------------------------------
2张表合计:259773
分页size:1000
同步用时:15:40~15:49 9分钟
---------------------------------------------
增量字段updatetime增加索引后无明显影响
同步效率大概就是:30万/10分钟
优化方案:
---------------------------------------------
一,两台相同配置的logstash同时同步(更慢):
同步用时:15:09~15:24 16分钟
同步用时:15:27~15:39 12分钟
结论:意义不大,除了插入,交叉数据还会更新
---------------------------------------------
二,修改配置(提速一倍):
修改/home/soft/logstash-5.5.0/config/logstash.yml配置文件
# pipeline线程数,官方建议是等于CPU内核数
pipeline.workers: 4
# 实际output时的线程数
pipeline.output.workers: 24
# 每次发送的事件数
pipeline.batch.size: 3000
# 发送延时
pipeline.batch.delay: 5
同步用时:15:45~15:49 4分钟
同步用时:15:51~15:54 3分钟
结论:有效 线上环境如果开启30线程数会更快,但是CPU占用会飙升(测试环境高达344%),所以需要配置合理 配合方案三 ,效率会提升显著,在测试环境时因pipeline.batch.size设置为10000发生或内存溢出,更改config目录下的jvm.options中内存大小解决。
---------------------------------------------
三,两天机器同步不同数据(根据拆分力度n倍提升)
结论:有效,两台机器同步不同数据
---------------------------------------------------------------------
最终结论:
配置设置 |
数据拆分 |
配置设置+数据拆分 |
|
优化前 |
30万/10分钟 |
30万/10分钟 |
30万/10分钟 |
优化后 |
30万/4分钟 |
30万/5分钟 |
30万/1分钟 |
因初次同步时,需同步全量的数据,量级会达到亿级,时间过久
需要增强同步效率,有效的优化方案为:1,配置设置 2,数据拆分,但需要根据硬件配置以及数据情况而定才能最优。
财务最终优化后的情况将实现:查询毫秒级出结果,数据一分钟内实现数据库同步。
数据查询一致性方面:为不影响现有查询,我们还做了---如ES文件存储中无数据时,会自动再用原mysql,sj方式查询数据,从而不影响初次同步时或一分钟内数据查不到的情况,进而做到业务人员无感知的优化上线及同步数据过程。
如果你想进入消费金融行业
消费金融架构
快速关注,请猛扫下面二维码!
以上是关于从秒级查询提升到了毫秒级-财务平台logstash同步ES实战笔记的主要内容,如果未能解决你的问题,请参考以下文章