ELK日志审计系统-logstash
Posted 程序员文章集锦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK日志审计系统-logstash相关的知识,希望对你有一定的参考价值。
在给某央企做日志服务之前,做过ELK stack的调研。同时结合对SOC系统的实际应用,对ELK整个系统有更全面的认识。由于项目时间有点久,文档稍微有点旧。不过ELK的使用没有多大变化。
文档分为4个部分,分别是Logstash、ES、kibana、安全分析模型。logstash 补充一些conf配置。
综述:
ELK Stack是Elasticsearch、Logstash、Kibana三个开源软件的组合。在实际应用中,三者通常是配合共用,而且又都先后归于Elastic.co公司名下,故有此简称。
ELK Stack在最近两年迅速崛起,成为机器数据分析,或者说实时日志处理领域,开源界的第一选择。处理的日志主要包括系统日志、应用程序日志和安全日志。系统运维和开发人员可以通过日志了解服务器软硬件信息、检查配置过程中的错误及错误发生的原因。经常分析日志可以了解服务器的负荷,性能安全性,从而及时采取措施纠正错误。
ELK Stack迅速崛起,主要是因为和传统的日志处理方案相比,ELK Stack具有如下几个优点:
处理方式灵活:Elasticsearch是实时全文索引,不需要像storm那样预先编程才能使用;
配置简易上手:Elasticsearch全部采用JSON接口,Logstash是Ruby DSL 设计,都是目前业界最通用的配置语法设计;
检索性能高效:Elasticsearch设计优良,虽然每次查询都是一次实时计算,但是elasticsearch优秀的设计可以使人们在对全天的数据进行查询时也能够实现查询结果的秒级响应;
集群线性扩展:不管是Elasticsearch集群还是Logstash集群都是可以线性扩展的;
前端操作炫丽:Kibana界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。
Logstash
目录结构:

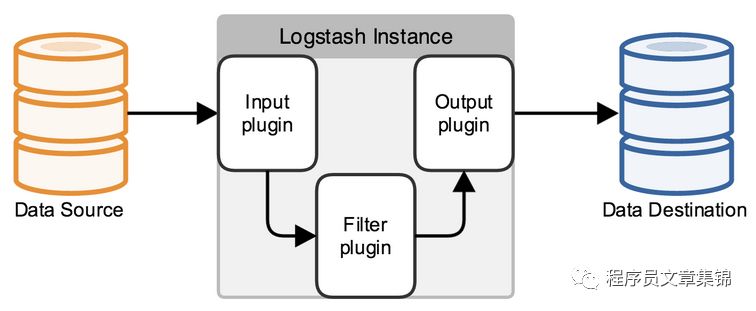
Logstash是一款用于接收、处理并输出日志的工具。它可以处理各种各样的日志,包括系统日志,WEB日志(Apache日志、nginx日志、Tomcat日志等),各种应用日志等。
Logstash是用ruby语言编写,运行在java环境下。结合不同的开源组件,完成Logstash的配置并执行不同的功能。
在Logstash的生态系统中包含四个部分:
Shipper:发送事件到Logstash,远程代理一般只执行该部分。
Broker and Indexer:接受事件并建立索引。
Search and Storage:允许用户搜索和存储事件。
Web Interface:基于web的接口。
Logstash服务器可以独立的运行一个或多个部件,这使得用户可以分开运行各个部件然后再集合成一个整体。
Logstash功能如下:
1.1 Logstash的下载、安装、配置及运行
由于Logstash的运行依赖于Java环境,而Logstash 1.5以上版本需要java版本不低于1.7,因此推荐使用最新版本的Java。
下载Logstash- 5.2.0:
#wget https://download.elastic.co/logstash/logstash/logstash- 5.2.0.tar.gz
将其安装在/usr/local目录下(安装后即可使用):
#tar zxvf logstash-5.2.0.tar.gz –C /usr/local
运行Logstash:
bin/logstash -f conf/topic.conf
进入Logstash安装目录:#cd /usr/local/logstash-5.2.0/bin
方式一:直接在命令中书写配置,采用如下方式运行:
#./logstash –e 'input { stdin {} } output { stdout {} }'
方式二:编写配置文件apache_accesslog.conf,采用如下方式运行:
#./logstash –f /home/elk/apache_accesslog.conf
方式三:使用参数–w修改filter和output的pipeline线程数量,默认是CPU核数
#./logstash -f /home/elk/apache_accesslog.conf -w 16
1.2 Logstash插件介绍
1.2.1 Input插件介绍
Logstash配置一定要有一个input和一个output。如果没有写明input,默认就会使用input { stdin {} },同理,没有写明output就是output { stdout {} }。
l 读取文件(File)
Logstash可以读取日志文件,它使用一个名叫FileWatch的Ruby Gem库来监听文件变化。这个库支持glob展开文件路径,而且会记录一个叫.sincedb的数据库文件来跟踪被监听的日志文件的当前读取位置。所以,不用担心logstash会漏过数据。
sincedb文件中记录了每个被监听的文件的inode,major number,minor number和pos。
配置示例:
input {file {path => ["/var/log/*.log", "/var/log/message"]type => "system"start_position => "beginning"}}
解释:读取/var/log/文件夹下的“*.log”、“message”日志文件,类型定义为“system”,读取位置为文件开始位置。
以下是一些比较常见的配置项,可以用来指定FileWatch库的行为:
Ø discover_interval
logstash监听的path下是否有新文件的时间间隔,默认值是15秒。
Ø exclude
可以排除不想被监听的文件,这里跟path一样支持glob展开。
Ø close_older
一个已经监听中的文件,如果超过这个值的时间内没有更新内容,就关闭监听它的文件句柄。默认是3600秒,即一小时。
Ø ignore_older
在每次检查文件列表的时候,如果一个文件的最后修改时间超过这个值,就忽略这个文件。默认是86400秒,即一天。
Ø sincedb_path
如果不想用默认的$HOME/.sincedb(Windows平台上在C:WindowsSystem32configsystemprofile.sincedb),可以通过这个配置定义sincedb文件到其他位置。
Ø sincedb_write_interval
logstash写一次sincedb文件的时间间隔,默认是15秒。
Ø stat_interval
logstash检查一次被监听文件状态的时间间隔(是否有更新),默认是1秒。
Ø start_position
logstash从什么位置开始读取文件数据,默认是结束位置,也就是说logstash进程会以类似tail -F的形式运行。如果是要导入原有数据,把这个设定改成"beginning",logstash进程就从头开始读取,有点类似cat,但是读到最后一行不会终止,而是继续变成tail -F。
注意:
1. 通常要导入原有数据进Elasticsearch的话,你还需要filter/date插件来修改默认的"@timestamp"字段值。
2. FileWatch只支持文件的绝对路径,而且不会自动递归目录。所以有需要的话,请用数组方式都写明具体哪些文件。
3. LogStash::Inputs::File只是在进程运行的注册阶段初始化一个FileWatch对象。所以它不能支持类似fluentd那样的path=>"/path/to/%{+yyyy/MM/dd/hh}.log"写法。达到相同目的,你只能写成path=>"/path/to/*/*/*/*.log"。FileWatch模块提供了一个稍微简单一点的写法:/path/to/**/*.log,用**来缩写表示递归全部子目录。
4. start_position仅在该文件从未被监听过的时候起作用。如果sincedb文件中已经有这个文件的inode记录了,那么logstash依然会从记录过的pos开始读取数据。所以重复测试的时候需要每回删除sincedb文件(官方博客上提供了另一个巧妙的思路:将sincedb_path定义为/dev/null,则每次重启自动从头开始读)。
5.因为windows平台上没有inode的概念,Logstash某些版本在windows平台上监听文件不能做到完全可靠,所以在windows平台上,推荐考虑使用nxlog作为收集端。
l 标准输入(Stdin)
Stdin是logstash里最简单和基础的插件了。
配置示例:
input {stdin {add_field => {"key" => "value"}codec => "plain"tags => ["add"]type => "std"}}
把整段配置都写入一个文本文件stdin.conf,然后运行命令:
# ./logstash -f /home/elk/stdin.conf
输入"hello world"并回车后,会在终端看到如下输出:
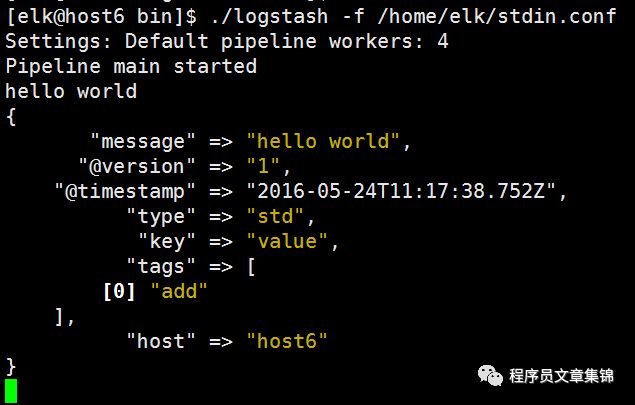
解释:
type和tags是logstash事件中两个特殊的字段,type用来标记事件类型——一般情况下可以提前知道事件的类型;而tags则是在数据处理过程中,由具体的插件来添加或者删除该标签。
1.2.2 Codec插件介绍
l 采用JSON编码
在早期的版本中,有一种降低logstash过滤器的CPU负载消耗的做法盛行于社区:直接输入预定义好的JSON数据,这样就可以省略掉filter/grok配置。
这个建议依然有效,不过在当前版本中需要稍微做一点配置变动——因为现在有专门的codec设置。
配置示例(社区常见的示例都是用的Apache的customlog,不过Nginx是一个比Apache更常用的新型web服务器,所以这里用nginx.conf做示例):
logformat json '{"@timestamp":"$time_iso8601",''"@version":"1",''"host":"$server_addr",''"client":"$remote_addr",''"size":$body_bytes_sent,''"responsetime":$request_time,''"domain":"$host",''"url":"$uri",''"status":"$status"}';
access_log /var/log/nginx/access.log_json json;
注意:
在$request_time和$body_bytes_sent变量两头没有双引号,这两个数据在JSON里应该是数值类型。
重启nginx应用,然后把input/file区段配置修改成下面这样:
input{file{path=> "/var/log/nginx/access.log_json""codec => "json"}}
运行结果:
下面访问一下nginx发布的web页面,然后会看到logstash进程输出类似下面这样的内容:
{"@timestamp" => "2014-03-21T18:52:25.000+08:00","@version" => "1","host" => "raochenlindeMacBook-Air.local","client" => "123.125.74.53","size" => 8096,"responsetime" => 0.04,"domain" => "www.domain.com","url" => "/path/to/file.suffix","status" => "200"}
1.2.3 Filter插件介绍
l 时间处理(Date)
filters/date插件可以用来转换日志记录中的时间字符串,变成LogStash::Timestamp对象,然后转存到@timestamp字段里。
注意:因为在outputs/elasticsearch中常用%{+YYYY.MM.dd}这种写法来读取@timestamp数据,所以一定不要直接删掉这个字段保留自己的字段,而是应该用filters/date转换后删除自己的字段。
配置示例:
filters/date插件支持五种时间格式:
Ø ISO8601
类似"2011-04-19T03:44:01.103Z"这样的格式。具体Z后面可以有"08:00"也可以没有,".103"这个也可以没有。常用场景里来说,Nginx的log_format配置里就可以使用$time_iso8601变量来记录请求时间成这种格式。
Ø UNIX
UNIX时间戳格式,记录的是从1970年起始至今的总秒数。Squid的默认日志格式中就使用了这种格式。
Ø UNIX_MS
这个时间戳则是从1970年起始至今的总毫秒数。据我所知,javascript里经常使用这个时间格式。
Ø TAI64N
TAI64N格式比较少见,是这个样子的:@4000000052f88ea32489532c。
Ø Joda-Time库
Logstash内部使用了Java的Joda时间库来作时间处理。所以可以使用Joda库所支持的时间格式来作具体定义。Joda时间格式定义见下表:
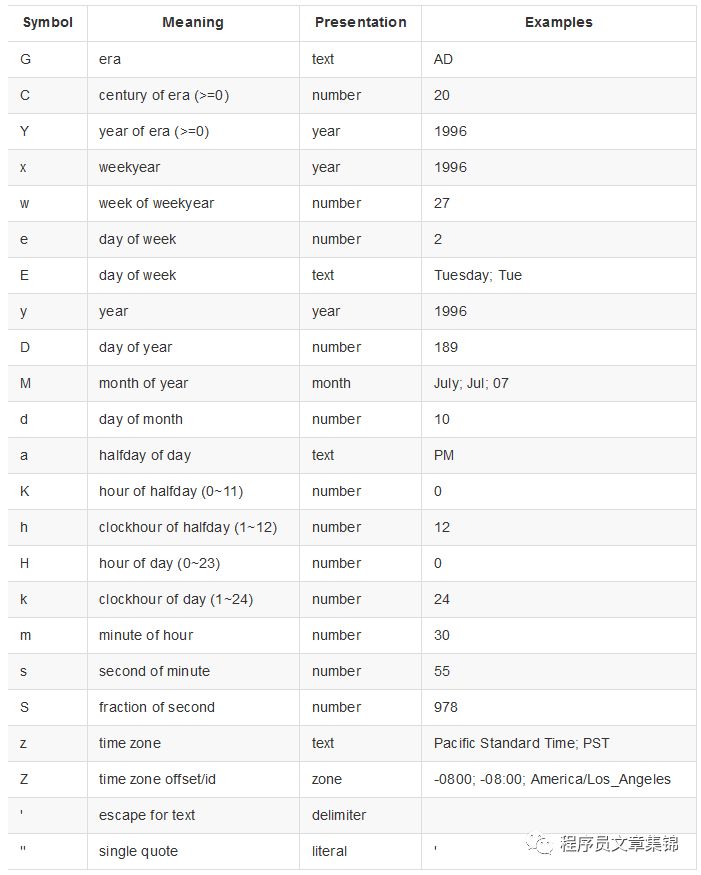
下面是一个Joda时间格式的配置示例:
filter {grok {match => ["message", "%{HTTPDATE:logdate}"]}date {match => ["logdate", "dd/MMM/yyyy:HH:mm:ss Z"]}}
注意:时区偏移量只需要用一个字母Z即可。
l Grok正则捕获
Grok是Logstash最重要的插件。可以在grok里预先定义好正则表达式,在稍后(grok参数或者其他正则表达式里)引用它。
Grok支持把预定义的grok表达式写入到文件中,官方提供的预定义grok表达式见:https://github.com/logstash-plugins/logstash-patterns-core/tree/master/patterns。
注意:在新版本的logstash里面,pattern目录已经为空,最后一个commit提示core patterns将会由logstash-patterns-core gem来提供,该目录可供用户存放自定义patterns。
下面是从官方文件中摘抄的最简单但是足够说明用法的示例:
USERNAME [a-zA-Z0-9._-]+
USER %{USERNAME}
第一行,用普通的正则表达式来定义一个grok表达式;第二行,通过打印赋值格式,用前面定义好的grok表达式来定义另一个grok表达式。
grok表达式的打印复制格式的完整语法是下面这样的:
%{PATTERN_NAME:capture_name:data_type}
可以将配置成下面这样:
input{ stdin{} } #标准输入filter {grok {match => { #利用过滤插件,过滤出符合指定格式的信息"message"=> "%{WORD} %{NUMBER:request_time:float} %{WORD}"}}}output{ stdout{ codec => rubydebug} } #标准输出
运行进程,输入“begin 123.456 end”,然后可以得到如下结果:
{"message" => "begin 123.456 end","@version" => "1","@timestamp" => "2014-08-09T12:23:36.634Z","host" => "raochenlindeMacBook-Air.local","request_time" => 123.456}
配置示例:
filter {
geoip {
source => "message"
}
}
运行结果:

配置说明:
GeoIP库数据较多,如果不需要这么多内容,可以通过fields选项指定自己所需要的。下例为全部可选内容:
filter {geoip {fields => ["city_name", "continent_code", "country_code2", "country_code3", "country_name", "dma_code", "ip", "latitude", "longitude", "postal_code", "region_name", "timezone"]}}
需要注意的是:geoip.location是logstash通过latitude和longitude额外生成的数据。所以,如果是想要经纬度又不想重复数据的话,应该像下面这样做:
filter {geoip {fields => ["city_name", "country_code2", "country_name", "latitude", "longitude", "region_name"] remove_field => ["[geoip][latitude]", "[geoip][longitude]"]}}
注意:
geoip插件的"source"字段可以是任一处理后的字段,比如"client_ip",但是字段内容却需要小心。geoip库内只存有公共网络上的IP信息,查询不到结果的,会直接返回null,而logstash的geoip插件对null结果的处理是:不生成对应的geoip字段。
l JSON编解码
有些日志可能是一种复合的数据结构,其中只是一部分记录是JSON格式的。这时候,需要在filter阶段,单独启用JSON解码插件。
配置示例:
filter {json {source => "message"target => "jsoncontent"}}
运行结果:
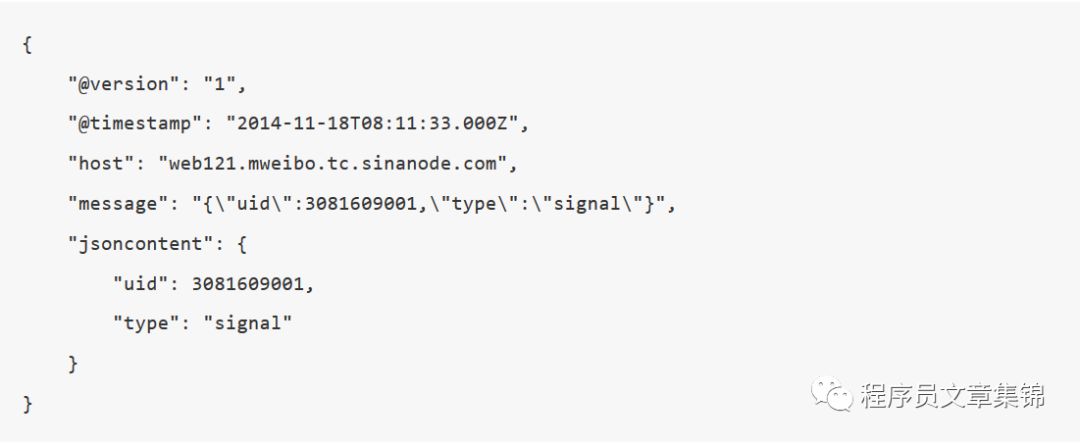
如果不打算使用多层结构的话,删掉target配置即可。新的结果如下:
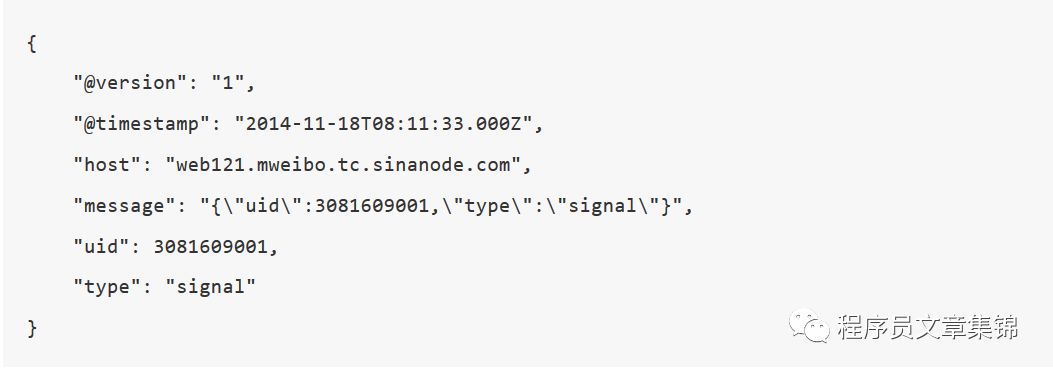
l Key-Value切分
在很多情况下,日志内容本身都是一个类似于key-value的格式,但是格式具体的样式却是多种多样的。logstash提供filters/kv插件,帮助处理不同样式的key-value日志,变成实际的LogStash::Event数据。
配置示例:
filter {ruby {init => "@kname = ['method','uri','verb']"code=>"event.append(Hash[@kname.zip(event['request'].split(' '))])"}if [uri] {ruby {init => "@kname = ['url_path','url_args']"code=>"event.append(Hash[@kname.zip(event['uri'].split('?'))])"}kv {prefix => "url_"source => "url_args"field_split => "&"remove_field => [ "url_args", "uri", "request" ]}}}
解释:
Nginx访问日志中的$request,通过这段配置,可以详细切分成method,url_path,verb,url_a,url_b…
进一步的,如果url_args中有过多字段,可能导致Elasticsearch集群因为频繁update mapping消耗太多内存在cluster state上而宕机。所以,更优的选择是只保留明确有用的url_args内容,其他部分舍去。
配置示例:
kv {prefix => "url_"source => "url_args"field_split => "&"include_keys => [ "uid", "cip" ]remove_field => [ "url_args", "uri", "request" ]}
上例即表示,除了url_uid和url_cip两个字段以外,其他的url_*都不保留。
l 数值统计(Metrics)
filters/metrics插件是使用Ruby的Metriks模块来实现在内存里实时的计数和采样分析。
例如,如果有一个字段的响应是一个HTTP响应状态码,并且要计算每一种反应,可编写配置文件如下:
filter {
metrics {
meter => [ "http_%{response}" ]
add_tag => "metric"
}
}
默认情况下,Metrics插件每5秒或者依照flush_interval中设置的时间进行刷新。Metrics显示出事件流中的新事件,并显示出其他插件的输出结果。
Ø 例子:记录追踪每一秒中的事件数
配置示例:
input {generator {type => "generated"}}filter {if [type] == "generated" {metrics {meter => "events"add_tag => "metric"}}}output { #给生成的事件赋予度量标签if "metric" in [tags] {stdout {codec => line {format => "rate: %{[events][rate_1m]}"}}}}
运行:# ./bin/logstash -f example.conf
结果可以观察到每一秒出现的事件速率,如下:
rate: 23721.983566819246
rate: 24811.395722536377
rate: 25875.892745934525
l 数据修改(Mutate)
filters/mutate插件是Logstash另一个重要插件。它具有类型转换、字符串处理和字段处理等能力。
类型转换
类型转换是filters/mutate插件最初诞生时的唯一功能。其应用场景在之前Codec/JSON小节已经提到。可以设置的转换类型包括:"integer","float"和"string"。示例如下:
filter {mutate {convert => ["request_time", "float"] #将request_time类型转换为float}}
注意:mutate除了转换简单的字符值,还支持对数组类型的字段进行转换,即将["1","2"]转换成[1,2]。但不支持对哈希类型的字段做类似处理。有这方面需求的可以采用稍后讲述的filters/ruby插件完成。
字符串处理:
Ø gsub
gsub => ["urlparams", "[\?#]", "_"]
通过使用正则表达式替换字符串中的值,若该字段不是字符串,这种替换将无效。
Ø split
filter {
mutate {
split => ["message", "|"]
}
}
随意输入一串以|分割的字符,比如"123|321|adfd|dfjld*=123",可以看到如下输出:
{"message" => [[] "123",[] "321",[] "adfd",[] "dfjld*=123"],"@version" => "1","@timestamp" => "2014-08-20T15:58:23.120Z","host" => "raochenlindeMacBook-Air.local"}
Ø join
仅对数组类型字段有效
在之前已经用split切割的基础再join回去。配置改成:
filter {mutate {split => ["message", "|"]}mutate {join => ["message", ","]}}
filter区段之内,是顺序执行的。所以最后看到的输出结果是:
{"message" => "123,321,adfd,dfjld*=123","@version" => "1","@timestamp" => "2014-08-20T16:01:33.972Z","host" => "raochenlindeMacBook-Air.local"}
Ø merge
合并两个数组或者哈希字段。依然在之前split的基础上继续:
filter {mutate {split => ["message", "|"]}mutate {merge => ["message", "message"]}}
会看到输出:
{"message" => [[] "123",[] "321",[] "adfd",[] "dfjld*=123",[] "123",[] "321",[] "adfd",[] "dfjld*=123"],"@version" => "1","@timestamp" => "2014-08-20T16:05:53.711Z","host" => "raochenlindeMacBook-Air.local"}
如果src字段是字符串,会自动先转换成一个单元素的数组再合并。把上一示例中的来源字段改成"host":
filter {mutate {split => ["message", "|"]}mutate {merge => ["message", "host"]}}
结果变成:
{"message" => [[] "123",[] "321",[] "adfd",[] "dfjld*=123",[] "raochenlindeMacBook-Air.local"],"@version" => "1","@timestamp" => "2014-08-20T16:07:53.533Z","host" => [[] "raochenlindeMacBook-Air.local"]}
可以发现,目的字段"message"确实多了一个元素,但是来源字段"host"本身也由字符串类型变成数组类型了。
字段处理:
Ø rename
重命名某个字段,如果目的字段已经存在,会被覆盖掉:
filter {
mutate {
rename => ["syslog_host", "host"]
}
}
Ø update
更新某个字段的内容。如果字段不存在,不会新建。
Ø replace
作用和update类似,但是当字段不存在的时候,它会起到add_field参数一样的效果,自动添加新的字段。
执行次序:
需要注意的是,filter/mutate内部是有执行次序的。其次序如下:

而filter_matched这个filters/base.rb里继承的方法也是有次序的。

l Ruby处理
如果了解Ruby语法,filters/ruby插件将会是一个非常有用的工具。
比如需要稍微修改一下LogStash::Event对象,但是又不打算为此写一个完整的插件,用filters/ruby插件是非常方便的。
配置示例:
filter {ruby {init => "@kname = ['client','servername','url','status','time','size','upstream','upstreamstatus','upstreamtime','referer','xff','useragent']"code => "new_event = LogStash::Event.new(Hash[@kname.zip(event['message'].split('|'))])new_event.remove('@timestamp')event.append(new_event)"}}
解释:
通常是用filters/grok插件来捕获字段的,但是正则耗费大量的CPU资源,很容易成为Logstash进程的瓶颈。
而实际上,很多流经Logstash的数据都是有自己预定义的特殊分隔符的,可以很简单的直接切割成多个字段。
filters/mutate插件里的"split"选项只能切成数组,后续很不方便使用和识别。而在filters/ruby里,可以通过"init"参数预定义好由每个新字段的名字组成的数组,然后在"code"参数指定的Ruby语句里通过两个数组的zip操作生成一个哈希并添加进数组里。短短一行Ruby代码,可以减少50%以上的CPU使用率。
注:从Logstash-2.3开始,LogStash::event.append不再直接接受Hash对象,而必须是LogStash::Event对象。所以示例要先初始化一个新的event,再把无用的@timestamp移除,再append进去。否则会把@timestamp变成有两个时间的数组了。
l split拆分事件
配置示例:
filter {split {field => "message"terminator => "#" #以“#”拆分事件}}
运行结果:
这个测试中,在input/stdin的终端中输入一行数据:"test1#test2",结果看到输出两个事件:

提示:
split插件中使用的是yield功能,其结果是split出来的新事件,会直接结束其在filter阶段的历程,也就是说写在split后面的其他filter插件都不起作用,直接进入到output阶段。所以,要保证split配置写在全部filter配置的最后。
l elapsed
elapsed记录一对开始事件与结束事件,并计算它们之间经过的时间。
配置示例:
filter {grok {match => ["message", "%{TIMESTAMP_ISO8601} START id: (?<task_id>.*)"]add_tag => [ "taskStarted" ]}grok {match => ["message", "%{TIMESTAMP_ISO8601} END id: (?<task_id>.*)"]add_tag => [ "taskTerminated"]}elapsed {start_tag => "taskStarted"end_tag => "taskTerminated"unique_id_field => "task_id"}}
解释:
start_tag字段描述“开始事件”,end_tag字段描述“结束事件”,unique_id_field字段标识任务ID。
1.2.4 Output插件介绍
l 保存进Elasticsearch
配置示例:
output {elasticsearch {hosts => ["192.168.0.2:9200"]index => "logstash-%{type}-%{+YYYY.MM.dd}"document_type => "%{type}"workers => 1flush_size => 20000idle_flush_time => 10template_overwrite => true}}
解释:
批量发送:flush_size和idle_flush_time共同控制Logstash向Elasticsearch发送批量数据的行为。以上面示例来说:Logstash会努力攒到20000条数据一次性发送出去,但是如果10秒钟内也没攒够20000条,Logstash还是会以当前攒到的数据量发一次。
默认情况下,flush_size是500条,idle_flush_time是1秒。这也是很多人改大了flush_size也没能提高写入ES性能的原因——Logstash还是1秒钟发送一次。
索引名:写入的ES索引的名称,这里可以使用变量。为了更贴合日志场景,Logstash提供了%{+YYYY.MM.dd}这种写法。在语法解析的时候,看到以+号开头的,就会自动认为后面是时间格式,尝试用时间格式来解析后续字符串。所以,处理过程中不要给自定义字段取个加号开头的名字。
此外,注意索引名中不能有大写字母,否则ES在日志中会报 InvalidIndexNameException,但是Logstash不会报错。
l 标准输出(Stdout)
配置示例:
output {stdout {codec => rubydebugworkers => 2}}
解释:
输出插件统一具有一个参数是workers。Logstash为输出做了多线程的准备。
1.3 Logstash配置实战
1.3.1 路由器日志采集
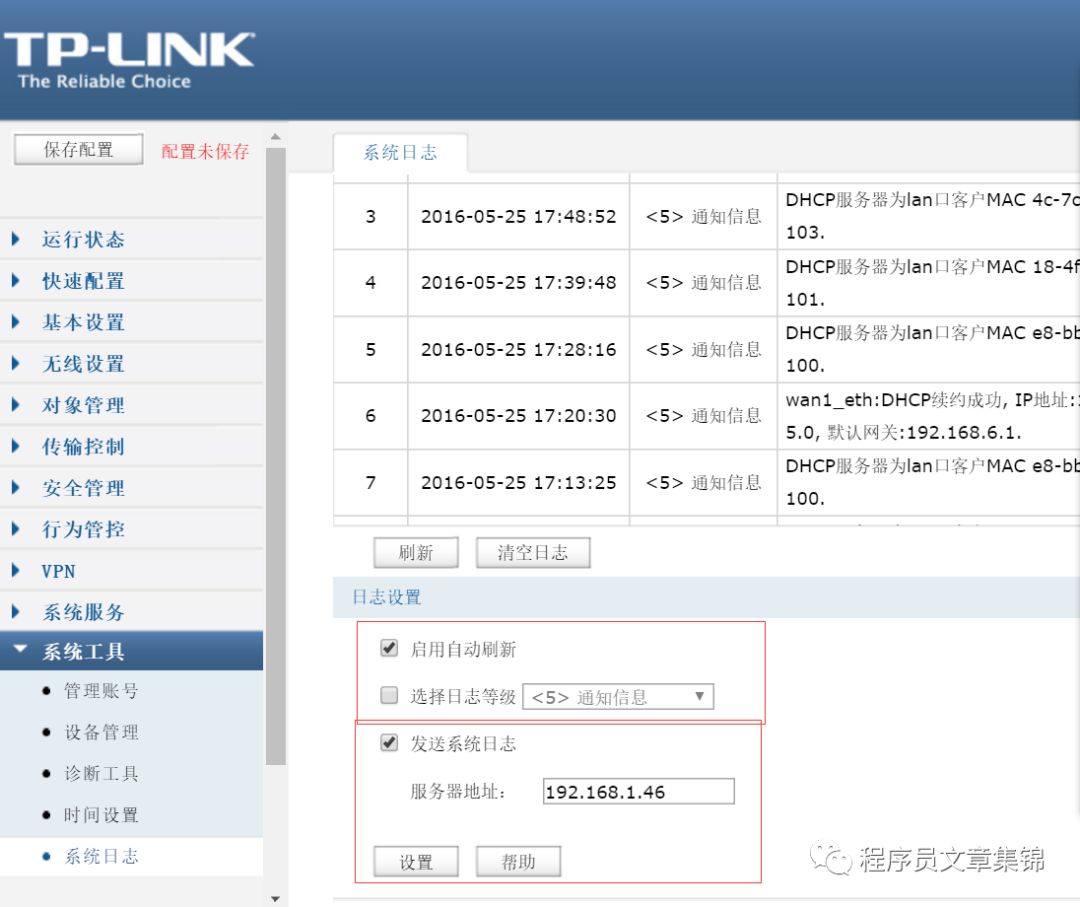
2)配置服务器的rsyslog.conf文件,将收集的路由器端口添加至配置文件中。
在rsyslog.conf中添加:*.* @@192.168.1.1:514。
3)配置logstash.conf文件
input{syslog{port => 514}}output{elasticsearch{hosts => “192.168.1.46”index => “route_log”}}
1.3.2 交换机日志采集
虽然没有设备进行实际操作,但大体流程同路由器一致,先登陆交换机,配置远程日志输出位置,其次在服务器配置rsyslog.conf中交换机远程IP与端口,最后就是配置logstash.conf文件(同路由器,也是使用syslog插件)。
1.3.3 Windows日志采集
日志文件是windows系统中一个比较特殊的文件,它记录着Windows系统中所发生的一切,如各种系统服务的启动、运行、关闭等信息。Windows日志包括应用程序、安全、系统等几个部分,它的存放路径是“%systemroot%system32config”,应用程序日志、安全日志和系统日志对应的文件名为AppEvent.evt、SecEvent.evt和SysEvent.evt。这些文件受到“Event Log(事件记录)”服务的保护不能被删除,但可以被清空。
windows日志通过eventlog服务传送,其功能类似于Linux下的Syslog服务,同时在windows客户机推荐是用nxlog软件进行收集windows日志。下面讲解安装nxlog。
2.3.3.1 安装软件nxlog
2)安装步骤:
①下载之后一路next即可。
②安装完成后nxlog的根目录为C:Program Files (x86) xlog。
③同时在Windows的服务(services.msc)里也会多出来一个名为nxlog的服务,此时服务是未开启的状态。
2.3.3.2 修改nxlog的conf文件
类似于logstash.conf文件,配置如输入输出以及路由信息。
<Input in>Module im_msvistalog# For windows 2003 and earlier use the following:# Module im_mseventlog</Input><Input testfile>Module im_fileFile "C:\test\*.log"SavePos TRUE</Input><Output out>Module om_tcpHost 192.168.1.100Port 515</Output><Route 1>Path testfile => out</Route>
2.3.3.3 Windows下启动nxlog服务
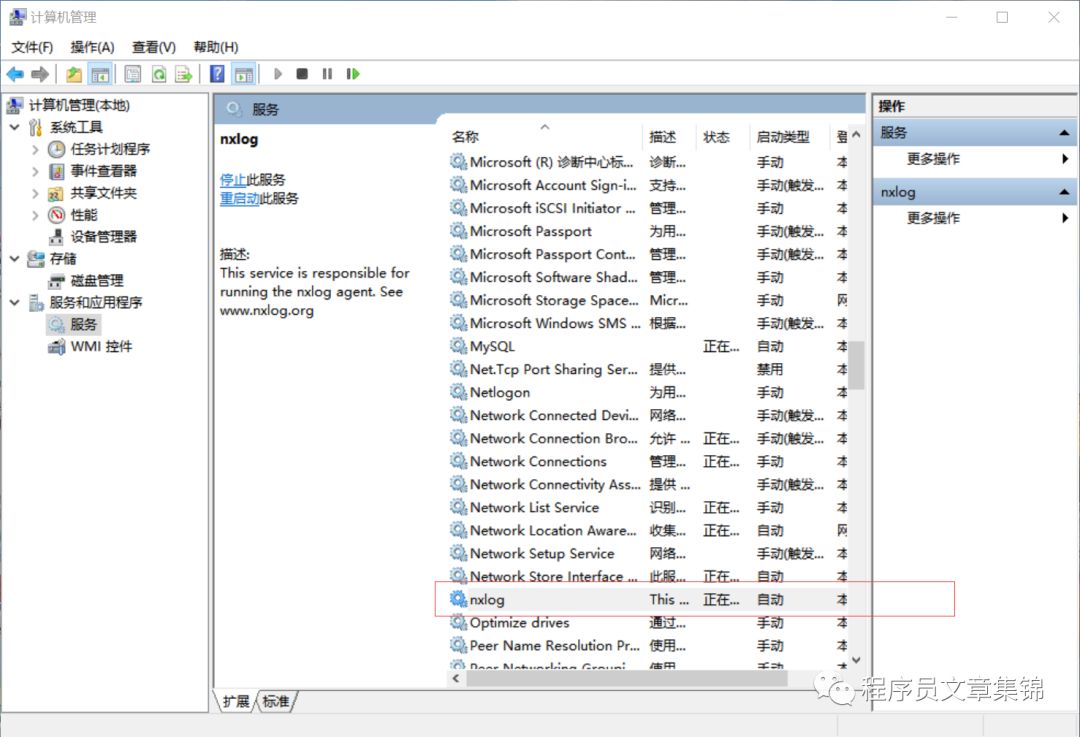
2.3.3.4 配置logstash文件
注:监听端口号为515
input {tcp {codec => "json"port => 515tags => ["windows","nxlog"]type => "nxlog-json"}} # end inputfilter {if [type] == "nxlog-json" {date {match => ["[EventTime]", "YYYY-MM-dd HH:mm:ss"]timezone => "Europe/London"}mutate {rename => [ "AccountName", "user" ]rename => [ "AccountType", "[eventlog][account_type]" ]rename => [ "ActivityId", "[eventlog][activity_id]" ]rename => [ "Address", "ip6" ]rename => [ "ApplicationPath", "[eventlog][application_path]" ]rename => [ "AuthenticationPackageName", "[eventlog][authentication_package_name]" ]rename => [ "Category", "[eventlog][category]" ]rename => [ "Channel", "[eventlog][channel]" ]rename => [ "Domain", "domain" ]rename => [ "EventID", "[eventlog][event_id]" ]rename => [ "EventType", "[eventlog][event_type]" ]rename => [ "File", "[eventlog][file_path]" ]rename => [ "Guid", "[eventlog][guid]" ]rename => [ "Hostname", "hostname" ]rename => [ "Interface", "[eventlog][interface]" ]rename => [ "InterfaceGuid", "[eventlog][interface_guid]" ]rename => [ "InterfaceName", "[eventlog][interface_name]" ]rename => [ "IpAddress", "ip" ]rename => [ "IpPort", "port" ]rename => [ "Key", "[eventlog][key]" ]rename => [ "LogonGuid", "[eventlog][logon_guid]" ]rename => [ "Message", "message" ]rename => [ "ModifyingUser", "[eventlog][modifying_user]" ]rename => [ "NewProfile", "[eventlog][new_profile]" ]rename => [ "OldProfile", "[eventlog][old_profile]" ]rename => [ "Port", "port" ]rename => [ "PrivilegeList", "[eventlog][privilege_list]" ]rename => [ "ProcessID", "pid" ]rename => [ "ProcessName", "[eventlog][process_name]" ]rename => [ "ProviderGuid", "[eventlog][provider_guid]" ]rename => [ "ReasonCode", "[eventlog][reason_code]" ]rename => [ "RecordNumber", "[eventlog][record_number]" ]rename => [ "ScenarioId", "[eventlog][scenario_id]" ]rename => [ "Severity", "level" ]rename => [ "SeverityValue", "[eventlog][severity_code]" ]rename => [ "SourceModuleName", "nxlog_input" ]rename => [ "SourceName", "[eventlog][program]" ]rename => [ "SubjectDomainName", "[eventlog][subject_domain_name]" ]rename => [ "SubjectLogonId", "[eventlog][subject_logonid]" ]rename => [ "SubjectUserName", "[eventlog][subject_user_name]" ]rename => [ "SubjectUserSid", "[eventlog][subject_user_sid]" ]rename => [ "System", "[eventlog][system]" ]rename => [ "TargetDomainName", "[eventlog][target_domain_name]" ]rename => [ "TargetLogonId", "[eventlog][target_logonid]" ]rename => [ "TargetUserName", "[eventlog][target_user_name]" ]rename => [ "TargetUserSid", "[eventlog][target_user_sid]" ]rename => [ "ThreadID", "thread" ]}mutate {remove_field => ["CurrentOrNextState","Description","EventRe"EventTime",ceivedTime","EventTimeWritten","IPVersion","KeyLength","Keywords","LmPackageName","LogonProcessName","LogonType","Name","Opcode","OpcodeValue","PolicyProcessingMode","Protocol","ProtocolType","SourceModuleType","State","Task","TransmittedServices","Type","UserID","Version"]}}}output{elasticsearch{hosts => “192.168.1.46”index => ”windows_log”}}
1.3.4 Linux日志采集
1)配置rsyslog.conf文件

若需通过syslog远程连接客户机,可在客户机在配置文件中添加:
#*.* @@remote-host:514
2)配置logstash .conf 文件
input{syslog{port => 514}}output{elasticsearch{hosts => “192.168.1.46”index => ”linux_log”}}
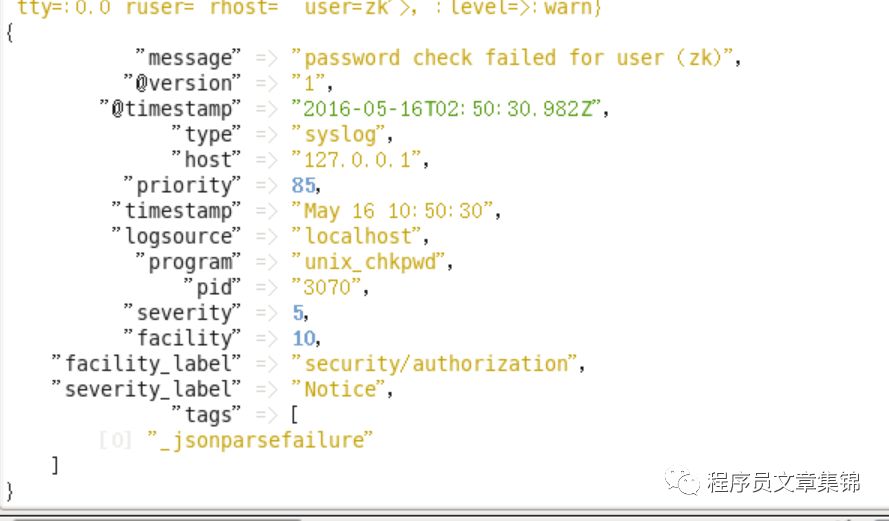
3)启动logstash,若出现:
syslog udp listener died /syslog tcp listener died 错误,则使用root权限启动logstash,则输出syslog日志。
1.3.5 mysql日志采集
日志是mysql数据库的重要组成部分。日志文件中记录着mysql数据库运行期间发生的变化;也就是说用来记录mysql数据库的客户端连接状况、SQL语句的执行情况和错误信息等。当数据库遭到意外的损坏时,可以通过日志查看文件出错的原因,并且可以通过日志文件进行数据恢复。
MySQL日志主要包含:错误日志、查询日志、慢查询日志、事务日志、二进制日志。此处只需要开启查询日志(general_log)便可以查看用户登录、语句执行等信息。
1)进入数据库后,执行下面语句,可看到下图。
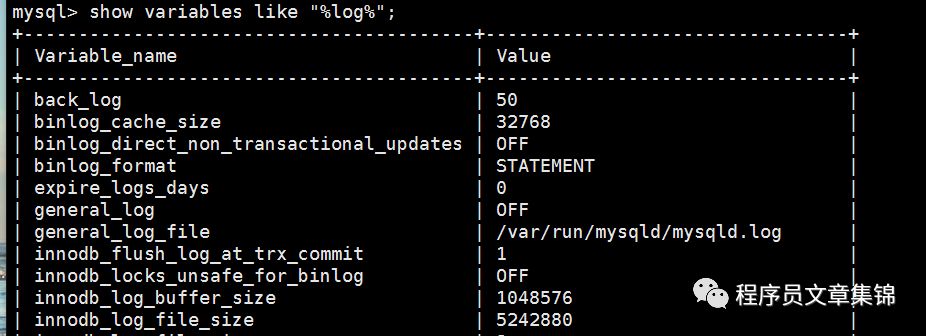
2)General_log会记录数据库的所有信息(包括用户操作,默认不开启),可通过执行Set global general_log=on,开启普通日志。
注:general_log_file即为日志文件存储位置。
3)配置logstash 输入为
input{file{path => “/var/run/mysqld/mysqld.log”type => "mysql"start_position => "beginning"}}output{elasticsearch{hosts => “192.168.1.46”index => “mysql_log”}}
执行./logstash -f xxx.conf 便可收集mysql所有日志(包括用户强登记录)。
1.3.6 Oracle日志采集
Oracle日志分三大类: Alert log files--警报日志,Trace files--跟踪日志(用户和进程)和 redo log 重做日志(记录数据库的更改)。
审计(Audit)用于监视用户所执行的数据库操作,并且Oracle会将审计跟踪结果存放到OS文件(默认位置$ORACLE_BASE/admin/$ORACLE_SID/adump/)或数据库(存储在system表空间中的SYS.AUD$表中,可通过视图dba_audit_trail查看)中。
不管你是否打开数据库的审计功能,以下这些操作系统会强制记录:用管理员权限连接Instance;启动数据库;关闭数据库。此处我们需要审计功能来记录用户强登数据库。
1)进入数据库后,执行下述语句(查看是否开启审计功能),可看到下表
show parameter auditNAME TYPE VALUE----------- ----------- --------audit_file_dest string data/app/oracle/admin/orcl/adumpaudit_sys_operations boolean FALSEaudit_syslog_level stringaudit_trail string DB
2)发现11g版本未关闭审计功能,故无需操作,日志文件存储在/data/app/oracle/admin/orcl/adump下。
注:oracle10g版本未开启日志审计功能,需要手动打开,执行如下语句:
audit session whenever not successful;
其它操作同11g版本。
3)配置lagstash conf文件如下
input{file{path => "/data/app/oracle/admin/orcl/adump/*"start_position=>"beginning"sincedb_path => "/dev/null"}}output{elasticsearch{hosts => “192.168.1.46”index => “oracle_log”}}
即可收集到oracle日志(包括用管理员权限连接Instance;启动数据库;关闭数据库等)。
1.3.7 Tomcat日志采集
1) 安装步骤略,服务器安装在/home/elk/zk/apache-tomcat-8.0.35/位置,其日志在当前目录logs文件夹下。

2) 配置logstash.conf文件
input {file {type => "tomcat_access"path => [“/home/elk/zk/apache-tomcat-8.0.35/logs/catalina.out"]exclude => ["*.log","*.txt"]sincedb_path => "/dev/null"start_position => "beginning"}file {type => "apache_access"path => ["/home/elk/zk/apache-tomcat-8.0.35/logs/*.txt"]exclude => ["*.log"]sincedb_path => "/dev/null"start_position => "beginning"}}filter {if [type] == "tomcat_access" {multiline {patterns_dir => "/usr/local/logstash/patterns"pattern => "(^%{CATALINA_DATESTAMP})"negate => truewhat => "previous"}if "_grokparsefailure" in [tags] {drop { }}grok {patterns_dir => "/usr/local/logstash/patterns"match => [ "message", "%{CATALINALOG}" ]}date {match => [ "timestamp", "yyyy-MM-dd HH:mm:ss,SSS Z", "MMM dd, yyyy HH:mm:ss a" ]}}if [type] == "apache" {grok {patterns_dir => "/usr/local/logstash/patterns"match => { "message" => "%{COMBINEDAPACHELOG}" }}date {match => [ "timestamp", "dd/MMM/yyyy:HH:mm:ss Z" ]}}}output {stdout {}elasticsearch {hosts => “192.168.1.46”index => “tomcat_log”}}
注:上面文件/usr/local/logstash/patterns内容如下:
COMMONAPACHELOG %{IPORHOST:clientip} %{USER:ident} %{USER:auth} [%{HTTPDATE:timestamp}] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-)COMBINEDAPACHELOG %{COMMONAPACHELOG} %{QS:referrer} %{QS:agent}CATALINA_DATESTAMP %{MONTH} %{MONTHDAY}, 20%{YEAR} %{HOUR}:?%{MINUTE}(?::?%{SECOND}) (?:AM|PM)CATALINALOG %{CATALINA_DATESTAMP:timestamp} %{JAVACLASS:class} %{JAVALOGMESSAGE:logmessage}
上面文本内容是关于解析tomcat日志的正则表达式,COMMONAPACHELOG、COMBINEDAPACHELOG以及CATALINA_DATESTAMP是既定好的解析格式。而后面的一系列操作是在既定格式上进行进一步的解析。
3)启动es与logstash即可收集tomcat服务器的catalina与access日志。
1.3.8 Apache日志采集
1) 安装步骤略,服务器上安装在/usr/local/apache2/位置,其日志在当前目录logs文件夹下。
2) 配置logstash.conf文件
input{file{path => “/usr/local/apache2/logs/access_log”sincedb_path => "/dev/null"start_position => "beginning"}file{path => “/usr/local/apache2/logs/error_log”sincedb_path => "/dev/null"start_position => "beginning"}}filter {if [path] =~ "access" {mutate { replace => { "type" => "APACHE_LOG" } }grok {match => { "message" => "%{COMBINEDAPACHELOG}" }}}date {match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]}geoip {source => "clientip"}}output {elasticsearch {hosts => "192.168.1.46"template_overwrite => trueindex => "logstash-%{type}-%{+YYYY.MM.dd}"}stdout { codec => rubydebug }}
3)启动es与logstash即可收集apache服务器的access_log与error_log日志。
以上是关于ELK日志审计系统-logstash的主要内容,如果未能解决你的问题,请参考以下文章