ELK-部署Logstash
Posted Java软件编程之家
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK-部署Logstash相关的知识,希望对你有一定的参考价值。
点击上方"Java软件编程之家",还没关注的赶紧关注了,关注后回复"资源"还可以免费获取大量电子书
根据部署计划,logstash部署在node2节点上。下面我们开始部署logstash
安装jdk8
具体不讲解
安装Logstash7
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.0.1.tar.gz2、解压logstash
tar -zxvf /opt/zip/logstash-7.0.1.tar.gz -C /opt/soft3、配置环境变量
$LS_HOME=/opt/zip/logstash-7.0.1$PATH:$LS_HOME/bin
4、测试运行logstash
logstash -e 'input { stdin { } } output { stdout {} }'
上图表示运行成功!
控制台输入hello,如果返回如下内容表示环境安装成功!

配置logstash
logstash有两类配置文件,分别是管道类配置文件和logstash启动和执行参数类配置文件;其中logstash启动和执行参数类配置文件在logstash安装包config目录下,下面是对参数类配置文件配置范围的简单说明:
logstash.yml
logstash启动和执行的基本配置
pipelines.yml
如果需要在单个Logstash实例中运行多个管道,可以通过配置该文件来实现
jvm.options
包含JVM参数配置。使用此文件设置总堆空间的初始值和最大值等
log4j.properties
包含log4j 2库的默认设置。
startup.options
当执行$LS_HONE/bin/system-install安装脚本时,会读取这里的配置进行相应的路径安装
管道类配置一般是我们自己定义,这是我们使用logstash的主要关注点。一般格式如下:
input { //这里配置从哪里收集数据,例如file, beat, redis等 }filter { //这里配置对收集过来的数据的过滤规则,通过插件或手写正则方式 }output { //这里配置收集的数据往哪里发送或保存,例如elasticsearch,redis,kafka等 }
logstash.yml文件配置如下:
# 节点描述node.name: node2# 持久化数据存储路径path.data: /var/elk/logstash/data# 管道IDpipeline.id: node2# 主管道配置目录(需要手工创建该目录)path.config: /var/elk/logstash/config# 定期检查配置是否已更改,并在配置发生更改时重新加载配置config.reload.automatic: true# 几秒钟内,Logstash会检查配置文件config.reload.interval: 3s# 绑定网卡地址http.host: "0.0.0.0"# 绑定端口http.port: 9600# logstash 日志目录path.logs: /var/elk/logstash/logs
启动logstash
$LOGSTASH_HOME/bin/logstash
如果看到如下日志信息,表示启动成功:
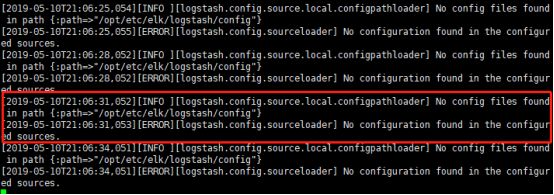
因为我们没有配置任何管道,所以上面日志提示了我们。
另外可以将logstash配置成systemd系统服务,使之作为守护进程方式运行在后台。也可以直接执行下面命令将logstash运行在后台:
nohup $LOGSTASH_HOME/bin/logstash &准备日志数据
上传日志文件hello.log到服务器/opt/source/logs目录下
该日志文件日志格式如下:
2019-04-30 17:30:18.051 [main] INFO c.l.c.common.logger.LoggerFactory -using logger: com.lazy.cheetah.common.logger.slf4j.Slf4jLoggerAdapter另外还有一段java的报错日志信息,如下:
: java.sql.SQLSyntaxErrorException: Table 'lazy_tcc.lazy_tcc_transaction' doesn't existat com.lazy.tcc.core.repository.jdbc.mysqlTransactionRepository.findAllFailure(MysqlTransactionRepository.java:264)at com.lazy.tcc.core.scheduler.job.CompensableTransactionJob.doExecute(CompensableTransactionJob.java:42)at com.lazy.tcc.core.scheduler.job.CompensableTransactionJob.execute(CompensableTransactionJob.java:33)at org.quartz.core.JobRunShell.run(JobRunShell.java:202)at org.quartz.simpl.SimpleThreadPool$WorkerThread.run(SimpleThreadPool.java:573)Caused by: java.sql.SQLSyntaxErrorException: Table 'lazy_tcc.lazy_tcc_transaction' doesn't existat com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:120)at com.mysql.cj.jdbc.exceptions.SQLError.createSQLException(SQLError.java:97)at com.mysql.cj.jdbc.exceptions.SQLExceptionsMapping.translateException(SQLExceptionsMapping.java:122)at com.mysql.cj.jdbc.ClientPreparedStatement.executeInternal(ClientPreparedStatement.java:974)at com.mysql.cj.jdbc.ClientPreparedStatement.executeQuery(ClientPreparedStatement.java:1024)at com.mchange.v2.c3p0.impl.NewProxyPreparedStatement.executeQuery(NewProxyPreparedStatement.java:76)at com.lazy.tcc.core.repository.jdbc.MysqlTransactionRepository.findAllFailure(MysqlTransactionRepository.java:257)4 common frames omitted
方便后面通过cat xxxx >> hello.log方式模拟程序运行时写日志,我们再上传几个日志文件到/opt/source/logs目录下

测试日志数据读者可以自行准备,一般的java web应用日志都可以拿来用。
配置管道
1、进入logstash管道配置目录
cd /opt/etc/logstash/config/由于我们之前logstash.yml配置文件的path.config: /opt/etc/elk/logstash/config,该配置表示logstash管道配置目录,logstash会读取该目录下所有以.conf为后缀的文件进行收集工作。由于我们配置了config.reload.automatic: true,每间隔3slogstash发现配置文件有修改就会热加载配置文件一次。
2、编写hello.conf文件,内容如下
# 输入块定义input {# 文件收集插件file {# 收集器IDid => "hello_1"# 以 换行符结尾作为一个事件发送# 排除.gz结尾的文件exclude => "*.gz"# tail模式mode => tail# 从文件尾部开始读取start_position => "end"# 收据数据源路径文件path => "/opt/source/logs/hello.log"# 为每个事件添加type字段type => "hello"# 每个事件编解码器,类似过滤器# multiline支持多行拼接起来作为一个事件codec => multiline {# 不以时间戳开头的pattern => "^%{TIMESTAMP_ISO8601}"# 如果匹配上面的pattern模式,将执行what策略negate => true# previous策略是拼接到前一个事件后面what => "previous"#总结:凡是不以时间戳开头的事件/行直接拼接到上一个事件/行>后面作为一个事件处理,# 例如Java堆栈处理结果是整个Java错误堆栈作为一条数据,因为Java报错信息是不以时间戳开头的}}}# 过滤块定义filter {#不做任何过滤,原样发送给输出阶段}# 输出块定义output {# 输出到elasticsearchelasticsearch {hosts => ["http://node3:9200"]index => "hello_%{+YYYY.MM.dd}"}}
说明:
logstash工作原理是通过管道模式进行设计的,一般一个管道有三个阶段,分别是输入、过滤、输出。
每个阶段主要靠插件方式进行配置。插件也分为输入类(input)插件,过滤类(filter)插件,输出类(output)插件,以及编解码(codec)类插件。每一类官方都提供足够多的现成插件供我们使用,如果确实不能满足,也可以自己开发插件,但一般不建议自己开发。
input {...}
input块定义logstash管道第一个阶段,该阶段作用是收集数据源信息,数据源可以是文件、数据库、kafka、redis、elasticsearch等,不同数据源使用不同的输入插件,例如上面我们使用file文件收集插件收集/opt/source/logs/hello.log文件,默认使用tail模式,从尾部开始收集。file插件默认是将每行数据作为一个事件发送到下一个阶段。这里需要注意,例如Java日志中报错的堆栈信息最好额外(像上面通过multiline codec进行处理)处理下,因为不额外处理它们回被换行符切分来作为独立的多个事件发送,最后保存也是保存为多条数据,这样可能导致后面查询日志时报错信息分散在不同的地方。
下面是官方提供的输入类插件列表:
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
filter {...}
filter块定义logstash管道第二个阶段,该阶段作用是对input块发送过来的事件进行额外过滤,一般也是通过过滤类插件进行配置。下面是官方提供的过滤类插件列表:
https://www.elastic.co/guide/en/logstash/7.0/filter-plugins.html
那么这里就有个问题,我们怎么获取input块发送过来的数据。
一般输入插件将事件(例如file插件通过换行符分割事件)数据都报错到message属性中发送到下一个阶段,所以我们可以从message字段中获取。
例如可以使用grok插件对发送过来的message字段进行额外的过滤,通过正则匹配的方式将message日志中的匹配日期正则的数据提取到新的字段中,这些字段最后会作为输出的独立的一个属性保存。例如下面:
filter {grok {match => ['message','%{TIMESTAMP_ISO8601:logdate}']}}
上面通过grok插件通过TIMESTAMP_ISO860正则从message属性中将匹配的数据复制一份出来保存到logdate属性中。
output {...}
output块定义logstash管道第三个阶段,该阶段作用是将收集、过滤好的信息进行落盘,一般可以保存到elasticsearch、redis、kafka等等。该阶段也是通过插件进行配置的,不同的输出数据源官方提供了不同的插件。下面是输出类插件官方提供的列表:
https://www.elastic.co/guide/en/logstash/7.0/output-plugins.html
启动logstash
1、重启logstash
ps aux | grep logstash | awk '{print $2}' | xargs kill -9nohup logstash &
2、浏览器访问我们之前安装的es管理界面应用
http://node3:9100/

可以看到现在没有任何索引数据。
3、cd /opt/source/logs
4、cat hello-0.log >> hello.log
5、访问es管理界面
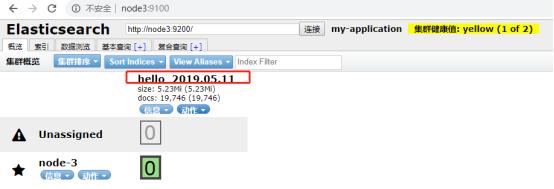
此时我们看到成功再es上创建了索引。由于我们输出插件配置的是elasticsearch,且index配置的是 index => "hello_%{+YYYY.MM.dd}",表示按天创建索引。
通过数据浏览,我们可以看到,Java错误堆栈正确无误的收集到了,关键是顺序也是正确的(这是由于mutiline codec的作用):
现在为止,我们以及搭建了Elasticsearch和logstash,整个ELK还差Kibana还未搭建,接下来我们将继续搭建Kibana来完成整个ELK平台搭建。
参考资料
1、logstash工作原理官方文档:
https://www.elastic.co/guide/en/logstash/7.0/pipeline.html
https://www.elastic.co/guide/en/logstash/current/input-plugins.html
https://www.elastic.co/guide/en/logstash/7.0/plugins-inputs-file.html
https://www.elastic.co/guide/en/logstash/7.0/codec-plugins.html
https://www.elastic.co/guide/en/logstash/7.0/plugins-codecs-multiline.html
https://www.elastic.co/guide/en/logstash/7.0/filter-plugins.html
https://www.elastic.co/guide/en/logstash/7.0/plugins-filters-grok.html
https://www.elastic.co/guide/en/logstash/7.0/output-plugins.html
https://www.elastic.co/guide/en/logstash/7.0/plugins-outputs-elasticsearch.html
https://github.com/kkos/oniguruma/blob/master/doc/RE
11、logstash自带通用正则模板
https://github.com/logstash-plugins/logstash-patterns-core/blob/master/patterns/grok-patterns
------------- 正文结束 ------------
以上是关于ELK-部署Logstash的主要内容,如果未能解决你的问题,请参考以下文章