ELK总结——第二篇Logstash的搭建
Posted 运维猫
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ELK总结——第二篇Logstash的搭建相关的知识,希望对你有一定的参考价值。
1、简介
Elasticsearch是当前主流的分布式大数据存储和搜索引擎,可以为用户提供强大的全文本检索能力,广泛应用于日志检索,全站搜索等领域。Logstash作为Elasicsearch常用的实时数据采集引擎,可以采集来自不同数据源的数据,并对数据进行处理后输出到多种输出源,是Elastic Stack 的重要组成部分。本文从Logstash的工作原理,使用示例,部署方式及性能调优等方面入手,为大家提供一个快速入门Logstash的方式。文章最后也给出了一些深入了解Logstash的的链接,以方便大家根据需要详细了解。
2、Logstash 下载与安装
请参考:https://www.elastic.co/cn/,选择您喜欢的下载与安装方式。

3、Logstash 架构
基于 Logstash 构建的日志收集处理体系是基于消息的,整个系统分别由四个组件组成。
1.Shipper 搬运者,将事件发送到 Logstash 。一般来说在应用服务所在的机器上只需要部署该组件。
2.Broker and Indexer 收集事件并进行处理,完成如数据过滤,数据格式化等,然后传输到指定存储系统或是进行在本地数据持久化等。
3.Search and Storage 用于存储和搜索事件。
4.Web Interface 网络接口。简单来说就是通过 Web 向用户展示数据并提供检索服务等。
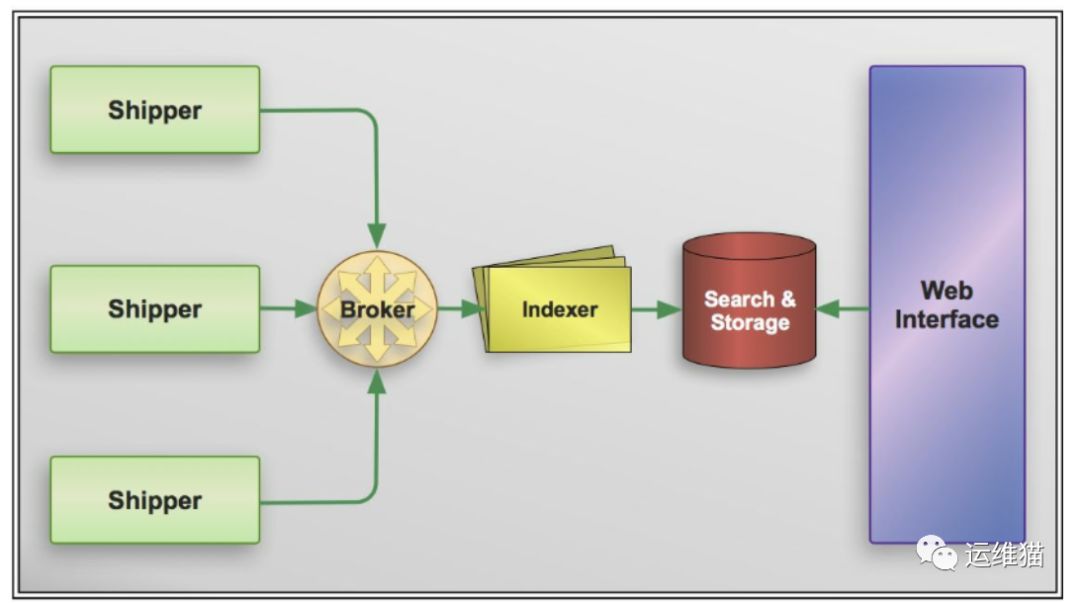
Broker and Indexer 一般均由 Logstash 担当,除此之外,logstash 也可以同时作为 Shipper ,可以理解为一种自收自发的模式。不过 Logstash 同时作为 Shipper 的话,就表示每台应用服务器的机器都需要部署 Logstash 实例,比起 filebeat 这种专门用于收集发送的应用资源消耗更大(filebeat 也可以跳过 Logstash ,直接将事件传输到如 Elasticsearch 的存储服务,但是 filebeat 在数据处理方面过于薄弱)。
4、Logstash工作原理
4.1处理过程
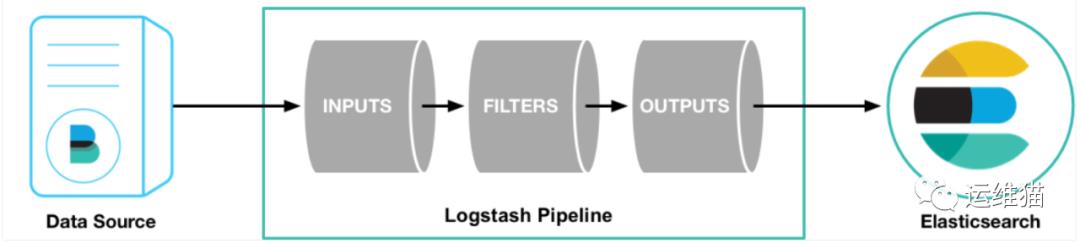
如上图,Logstash的数据处理过程主要包括:Inputs, Filters, Outputs 三部分, 另外在Inputs和Outputs中可以使用Codecs对数据格式进行处理。这四个部分均以插件形式存在,用户通过定义pipeline配置文件,设置需要使用的input,filter,output, codec插件,以实现特定的数据采集,数据处理,数据输出等功能。
1.Inputs:用于从数据源获取数据,常见的插件如file, syslog, redis, beats 等。
2.Filters:用于处理数据如格式转换,数据派生等,常见的插件如grok, mutate, drop, clone, geoip等。
3.Outputs:用于数据输出,常见的插件如elastcisearch,file, graphite, statsd等。
4.Codecs:Codecs不是一个单独的流程,而是在输入和输出等插件中用于数据转换的模块,用于对数据进行编码处理,常见的插件如json,multiline。
4.2执行模型
1.每个Input启动一个线程,从对应数据源获取数据。
2.Input会将数据写入一个队列:默认为内存中的有界队列(意外停止会导致数据丢失)。为了防止数丢失Logstash提供了两个特性:Persistent Queues:通过磁盘上的queue来防止数据丢失 Dead Letter Queues:保存无法处理的event(仅支持Elasticsearch作为输出源)。
3.Logstash会有多个pipeline worker, 每一个pipeline worker会从队列中取一批数据,然后执行filter和output(worker数目及每次处理的数据量均由配置确定)。
5、典型应用场景
因为 Logstash 自身的灵活性以及网络上丰富的资料,Logstash 适用于原型验证阶段使用,或者解析非常的复杂的时候。在不考虑服务器资源的情况下,如果服务器的性能足够好,我们也可以为每台服务器安装 Logstash 。我们也不需要使用缓冲,因为文件自身就有缓冲的行为,而 Logstash 也会记住上次处理的位置。
如果服务器性能较差,并不推荐为每个服务器安装 Logstash ,这样就需要一个轻量的日志传输工具,将数据从服务器端经由一个或多个 Logstash 中心服务器传输到 Elasticsearch。
随着日志项目的推进,可能会因为性能或代价的问题,需要调整日志传输的方式(log shipper)。当判断 Logstash 的性能是否足够好时,重要的是对吞吐量的需求有着准确的估计,这也决定了需要为 Logstash 投入多少硬件资源。
6、Logstash的设计非常规范,有三个组件
1.Shipper 负责日志收集。职责是监控本地日志文件的变化,并输出到 Redis 缓存起来。
2.Broker 可以看作是日志集线器,可以连接多个 Shipper 和多个 Indexer。
3.Indexer 负责日志存储。在这个架构中会从 Redis 接收日志,写入到本地文件。
7、Logstash配置文件详解
通过源码安装 ,相关设置放在 /usr/local/logstash/config 。/usr/local/logstash/config 下有以下文件和文件夹。
1.conf.d : 用于存储 Logstash 相关管道配置的文件夹。以服务方式启动的 Logstash 将会读取该文件夹下的所有 *.conf 文件。
2.Logstash.yml: Logstash 的设置项文件。所有可以通过命令行启动指定的参数都可以在该文件中找到并设置,包括上述提到的读取 *.conf 文件的路径,可以改变 path.config 来改变要读取的 *.conf 文件的位置。
3.jvm.options: Logstash 是依赖于 JVM 运行的,可以通过改设置文件改变 JVM 的参数。
4.log4j2.properties: Logstash 应用本身用到的日志服务(log4j)的设置项。
5.startup.options: 在 /usr/share/Logstash/bin 下有脚本 system-install ,用于安装 Logstash 。而 startup.options 就是安装时用到的参数。例如在安装时会用到 java ,可以通过 startup.options 改变 java 的路径,还有诸如应用的用户(通过服务启动的 Logstash 应用的用户为 logstash),服务名等信息。不过如果想要 startup.options 中的设置项生效,只能执行 system-install 脚本,重新安装 Logstash 。
你的顺手 以上是关于ELK总结——第二篇Logstash的搭建的主要内容,如果未能解决你的问题,请参考以下文章