大神教你玩Spring 5的Servlet与响应式技术栈解析
Posted 广东互动学堂
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大神教你玩Spring 5的Servlet与响应式技术栈解析相关的知识,希望对你有一定的参考价值。
本文要点
Java大力转向了异步和非阻塞并发。
Spring 5为Web应用程序引入了完全非阻塞的反应式技术栈。
反应式技术栈使用更少的资源处理更高的并发量,而且在客户端和服务器端的流式处理方面有突出的表现。
Spring MVC为现有的应用程序提供了一些反应式特性。
Spring Boot 2内置了反应式Web容器,默认使用的是Netty,当然也可以选择Tomcat、Jetty或Undertow。
Spring 5提供了Servlet和响应式这两种Web技术栈,在应用层面充分向异步和非阻塞并发靠拢。这篇文章主要介绍了几种可选项以及如何在这些选项中做出选择。
文中我分别使用“Servlet栈”和“响应栈”来指代Spring 5所提供的两种技术栈,应用程序可以分别通过Spring MVC(spring-webmvc模块)和Spring WebFlux(spring-webflux模块)来使用这两个技术栈。
改变的动机
相关厂商内容
罗辑思维Go语言微服务改造完整过程
Netflix的未来IT架构模型:Serverless
成功靠团队,看一线大厂是如何打造高效技术团队的
区块链浪潮来袭,企业技术leader如何理性抉择?
2018,如果不懂这项技术,你可能将被淘汰
现如今,“响应式”俨然已经成为一个热门词汇。不过,它真的是大势所趋,异步Web开发的发展经历了从早期简单的Servlet容器到现如今的异步无处不在。我们为此做好准备了吗?
传统的Java使用线程池来并行执行阻塞式的IO操作(比如进行远程调用)。表面上看,这样做很简单,但实际上可能不是这么回事。首先,在进行同步或共享数据结构时,应用程序就会变得很复杂。其次,每个阻塞操作都会占用一个线程,以致于难以伸缩,而且这种等待所带来的延迟我们是无能为力的(这样会让客户端和服务器端都慢下来)。
因此,出现了各种解决方案(比如协程、actor等),把并发的复杂性归到框架或编程语言当中。现在出现了一个有关Java轻量级线程模型的提议,叫作Loom,但要看到它被应用到生产环境可能还要等上好几年。而在当前,我们能够做点什么来更好地处理异步并发呢?
在Java开发者当中普遍存在这样的误解,他们认为伸缩需要更多的线程。或许,在使用命令式编程范式和阻塞式模型时,这样想是对的,但通常来说并非如此。如果一个应用程序是完全非阻塞的,那么它完全可以使用少量的线程来实现伸缩,Node.js就是最好的例子。而在Java里,我们不一定要局限于只使用单个线程,我们可以启动足够的线程,把CPU的核数都用上。不过原则依旧:我们并不依赖更多的线程来实现高并发。
我们是如何让应用程序变成非阻塞式的?首先,我们必须放弃与命令式编程有关的串行逻辑,我们使用异步API,对事件作出反应。当然,使用太多的回调函数很快就会让事情变得复杂起来。我们可以使用更好的模型,比如Java 8引入的CompletableFuture,它提供了链式API,处理事件的逻辑是按步骤串联在一起的,而不是按照嵌套回调的方式组织在一起。
CompletableFuture.supplyAsync(() -> "stage0") .thenApply(s -> s + "-stage1") .thenApplyAsync(s -> { // insert async call here... return s + "-stage2"; }) .thenApply(s -> s + "-stage3") .thenApplyAsync(s -> { // insert async call here... return s + "-stage4"; }) .thenAccept(System.out::println);
这种方式虽好,但只能返回单一值。如果要处理一个异步的序列,那该怎么办?Java 8的流式API提供了针对流元素的函数式操作,不过它只支持集合(消费者从流中拉取数据),不适用于“实时”流(生产者向流中推送数据,中间还可能有延迟)。
于是乎,出现了一些反应式类库,如RxJava、Reactor、Akka Streams等。它们看起来很像Java 8 Streams,只不过是为异步序列而设计的,并且加入了反应式流回压特性,让消费者能够控制生产者的速率。
在一开始,从命令式编程转换到函数式或声明式的编程风格可能会觉得不习惯,这需要点时间适应。这个与生活中的其他事情一样,比如学习骑自行车或学习一门新语言。不要放弃,它们会变得越来越容易,而且终究会给你带来好处。
从命令式到声明式的转变就好比使用Java 8的Streams API来重写循环代码。在使用Java 8 Streams API时,你声明要“做什么”,而不是“如何做”,代码更具有可读性。使用反应式类库也是类似,只要声明要做什么,不需要处理与并发、线程和同步相关的问题,所以使用更少的硬件资源就可以实现更高效的伸缩。
最后,Java 8的lambda语法也是促成我们转向反应式编程的因素之一,它促进了函数式编程、声明式API和响应式类库的使用,让我们对新的编程模型充满了遐想。就像可以使用注解来开发REST端点一样,我们也可以使用Java 8的lambda语法来开发函数式的路由和请求处理器。
技术栈选择
Spring并不是第一个提供异步非阻塞特性的开发框架,不过它在企业级应用层面提供了各个层次的选择。能够做出自由的选择是非常关键的一点,因为并非所有的应用程序都能随意更改,况且有些应用根本就不需要做出更改。随着微服务架构的发展,单个应用程序可以独立发生变更,那么选择性、一致性和持续性也就变得越发重要。
接下来让我们来看看我们都有哪些选择。
应用服务器
长久以来,Servlet API是事实上的应用服务器标准。不过,随着时间推移,出现了一些替代方案,对于想尝试事件循环并发和非阻塞式IO的项目来说,它们早就把目光移到了Servlet API和Servlet容器之外。
确实,在过去几年,Tomcat和Jetty发展得很不错。但这20年来一直没怎么发生改变的是,我们一直在使用阻塞式的Servlet API。Servlet API在3.1版本中引入了非阻塞式API,不过还没有被实际采用,因为它要求应用服务器做出深度的修改,把原先围绕阻塞式IO而设计的核心框架和应用程序接口全部都改掉。所以实际情况是,开发者需要在Servlet的阻塞式API和不依赖Servlet API的第三方异步运行时(如Netty)之间做出选择。
在Spring 5中,我们可以选择是使用阻塞式API还是反应式运行时。Spring WebFlux应用程序可以运行在Servlet容器上。从Spring Boot 2开始,WebFlux默认使用Netty,不过也可以选用Tomat或Jetty,只需要修改几行配置代码。
在控制器上使用注解
Spring MVC的注解方式可以用在Servlet栈(Spring MVC)和反应式栈(Spring WebFlux)上。也就是说,我们可以在阻塞式和非阻塞式之间做出选择,同时保持编程模型不变。
响应式客户端
使用响应式客户端可以在不处理与线程相关代码的情况下,更有效地调度对远程服务的调用。这对于服务器端的并发性能来说无疑有巨大的好处。
使用响应式客户端不仅限于响应式栈。下面的代码也可以用在Servlet栈上,一个Spring MVC控制器也可以处理请求并生成响应式类型的响应:
@RestControllerpublic class CarController { private final WebClient carsClient = WebClient.create("http://localhost:8081"); private final WebClient bookClient = WebClient.create("http://localhost:8082"); @PostMapping("/booking") public Mono<ResponseEntity<Void>> book() { return carsClient.get().uri("/cars") .retrieve() .bodyToFlux(Car.class) .take(5) .flatMap(this::requestCar) .next(); } private Mono<ResponseEntity<Void>> requestCar(Car car) { return bookClient.post() .uri("/cars/{id}/booking", car.getId()) .exchange() .flatMap(response -> response.toEntity(Void.class)); }}
在上面这个例子中,控制器使用了响应式的非阻塞WebClient从远程获取车辆数据,然后尝试通过第二次调用远程服务预定车辆服务,最后,将响应返回给客户端。我们声明异步远程调用,然后并发执行它们(事件循环方式),不需要处理与线程和同步相关的代码,一切看起来多么简单。
响应式类库
注解编程模型的好处之一是可以灵活地选择方法签名。应用程序可以灵活地选择方法参数和返回值,这样就可以更方便地支持多个反应式类库。
不管是Servlet栈还是反应式栈,都可以在控制器的方法签名中使用Reactor或RxJava类型。而且这是可配置的,我们也可以使用其他响应式类库。
函数式Web端点
除了可以在控制器上使用注解,Spring WebFlux还支持轻量级的函数式编程模型,也就是基于lambda表达式来路由和处理请求。
函数式端点与注解控制器非常不一样。在使用注解时,我们告诉框架应该要做什么,然后让框架尽可能为我们做更多的工作——还记得好莱坞的“不要打给我,我会打给你”法则吗?相反,函数式编程模型提供了一系列辅助类,用于从头到尾处理请求消息。下面是一个简短的代码示例:
RouterFunction<?> route = RouterFunctions.route(POST("/cars/{id}/booking"), request -> { Long carId = Long.valueOf(request.pathVariable("id")); Long id = ... ; // Create booking URI location = URI.create("/car/" + carId + "/booking/" + id); return ServerResponse.created(location).build();});
下面使用Netty来运行它:
HttpHandler handler = RouterFunctions.toHttpHandler(route);ReactorHttpHandlerAdapter adapter = new ReactorHttpHandlerAdapter(handler);HttpServer server = HttpServer.create("localhost", 8080);server.startAndAwait(adapter);
函数式端点可以与反应式类库共存,因为它们都是基于函数式和声明式风格的API而构建的。
Web技术栈架构
现在让我们深入了解Servlet技术栈和响应式技术栈。
Servlet栈由经典的Servlet容器和Servlet API组成,使用Spring MVC作为Web框架。最开始,Servlet API采用了“每请求一个线程”的模型,也就是说,一个线程负责处理一个请求,让请求流经整个filter-servlet链条,在必要的时候需要阻塞线程。后来,Web应用程序对Servlet API提出了更多的需求,于是加入了更多的特性:
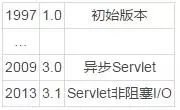
可惜的是,3.1版本引入的非阻塞IO无法与现有的那些使用了命令式和阻塞式语义的Web框架集成在一起。这也是Spring MVC不支持非阻塞IO的原因,不过新出现的Spring WebFlux却成为非阻塞Web框架的基石,它同时支持Servlet API和其他的应用服务器。3.0版本引入的异步Servlet为开发者带来了异步处理响应消息的可能性,也就是说,即使是在请求消息已经流经了整个filter-servlet链条,仍然可以对响应消息做额外的处理。Spring MVC充分利用了这一特性,这也就是为什么可以在带有注解的控制器上使用反应式返回类型。
响应式栈可以运行在Tomcat、Jetty、Servlet 3.1容器、Netty和Undertow上。这些应用服务器实现了Reactive Streams API,用以处理HTTP请求。在这些容器之上是WebHandler API层,与Servlet API处于同一层,只不过它是异步非阻塞的。
下图是两种技术栈的对比:
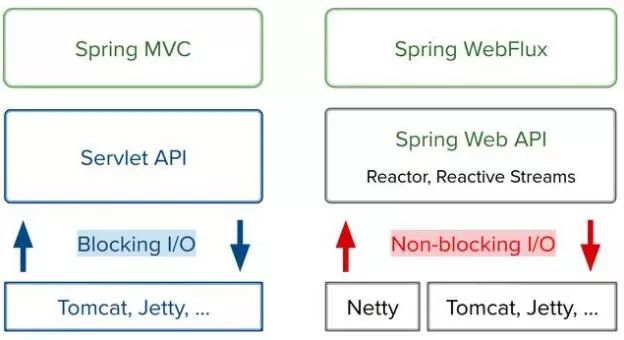
尽管两种技术栈都使用了Tomcat和Jetty,但用法不一样。在Servlet栈中,通过阻塞式的Servlet API来使用它们。而在反应式栈中,则通过Servlet 3.1的非阻塞IO来使用它们,甚至不会暴露出Servlet API——它们大部分是阻塞和同步的(比如处理请求参数、二进制数据请求等),主要留给应用程序使用。
响应式、非阻塞和回压
Servlet栈和响应式栈都支持在控制器上使用注解,不过它们的并发模型是不一样的。
在Servlet栈里,允许应用程序发生阻塞,这也就是为什么Servlet容器需要使用一个很大的线程池来应对可能发生的阻塞。这个可以从Filter和Servlet接口看出来,它们是命令式的,而且返回的是void。阻塞式的InputStream和OutputStream也是一样。
而在反应式栈里,应用程序不能发生阻塞。事件轮询只提供了少量的线程,如果应用程序发生阻塞,很快就会殃及整个服务器。这个可以从WebFilter和WebHandler看出来,它们返回的是Mono<Void>。那些用在请求消息体和响应消息体中的反应式类型也是一样。
请求消息体可以通过Flux<DataBuffer>来访问,也就是说,我们必须一次性处理完整个数据块。这个看起来有点棘手,不过框架提供了内置的编码和解码器,用于将字节流转换成对象流。
例如,我们可以从客户端上传一个JSON数据流:
// 每秒钟弹出一辆车Flux<Car> body = Flux.interval(Duration.ofSeconds(1)).map(i -> new Car(...));// 将数据流发送给服务器WebClient.create().post() .uri("http://localhost:8081/cars") .contentType(MediaType.APPLICATION_STREAM_JSON) .body(body, Car.class) .retrieve() .bodyToMono(Void.class) .block();
在服务器端,使用一个Spring WebFlux控制器来摄入数据流,再使用一个Spring Data反应式Repository将数据插入到数据库:
// 在数据到达时将其插入数据库@PostMapping(path="/cars", consumes = "application/stream+json")public Mono<Void> loadCars(@RequestBody Flux<Car> cars) { return repository.insert(cars).then();}
流可以持续很长一段时间。对流的处理也是很高效的,不需要占用额外的线程或内存。Spring WebFlux和Spring Data都支持反应式流,那么上述的代码可以扩展成一个处理管道,这个管道支持从数据库到HTTP运行时的反应式流回压。数据库端可以控制HTTP读取数据块并转成对象的速率:
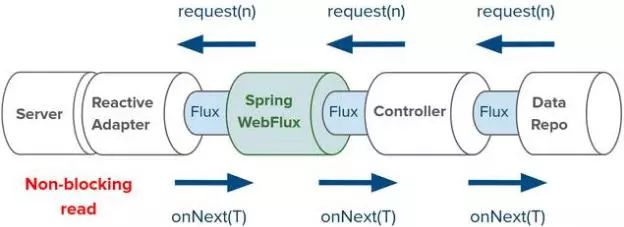
假设我们将控制器摄入的汽车数据插入到MongoDB的一个集合中,其他客户端向MongoDB发起JSON请求:
WebClient.create().get() .uri("http://localhost:8081/cars") .accept(MediaType.APPLICATION_STREAM_JSON) .retrieve() .bodyToFlux(Car.class) .doOnNext(car -> { logger.debug("Received " + car)); //... }) .block();
在服务器端,控制器是这样处理JSON数据流的:
@GetMapping(path = "/cars", produces = "application/stream+json")public Flux<Car> getCarStream() { return this.repository.findCars();}
这一次,响应式流回压的方向与上次相反,是从HTTP运行时流向数据库。HTTP运行时控制着数据对象从数据库中出来、序列化成JSON,再写到HTTP响应消息里的速率:
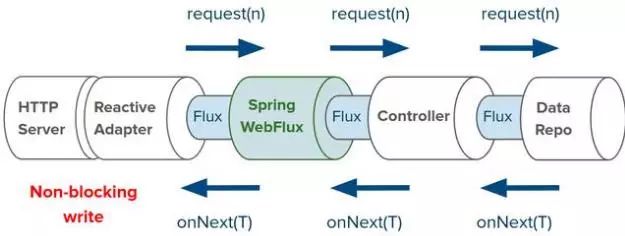
上面演示了如何在响应式栈中通过使用Flux<Car>来摄入和流式化数据。如果换成是一般(有边界)的集合,那该怎么办?Flux支持任意类型的数据序列,不管是有边界的还是无边界的,所以不需要为此做出任何改动。
我们仍然返回Flux,框架会自动检查媒体类型并做出相应处理。
下面的代码使用“application/json”来渲染一个JSON数组:
@GetMapping(path = "/cars", produces = "application/json")public Flux<Car> getCars() { return this.repository.findAll();}
“application/json”是非流式媒体类型,框架会假设Flux是一个有边界的集合,使用Flux.collectionToList()来获取所有元素,把它们收集到一个List当中,再把集合写入响应消息。
在这个章节里,我们介绍了响应式栈。Servlet栈依赖阻塞式IO,所以不支持非阻塞或流式的@RequestBody注解。不过,因为Servlet 3.0提供了异步请求特性,控制器的方法仍然能够进行一些异步处理,所以,Spring MVC控制器可以调用反应式客户端并返回反应式类型。
在Servlet栈中处理“application/json”时,Spring MVC也会将Flux中的元素收集到一个List中,并以JSON数组的形式写到响应消息里:
@GetMapping("/cars")public Flux<Car> getCars() { return this.repository.findAll();}
而对于“application/stream+json”和其他流式媒体类型,Spring MVC会用到响应式流回压:
@GetMapping(path = "/cars", produces = "application/stream+json")public Flux<Car> getCarStream() { return this.repository.findCars();}
不过,与响应式栈不同的是,Servlet栈的写入操作是阻塞式的,而且是在单独的线程中进行的:
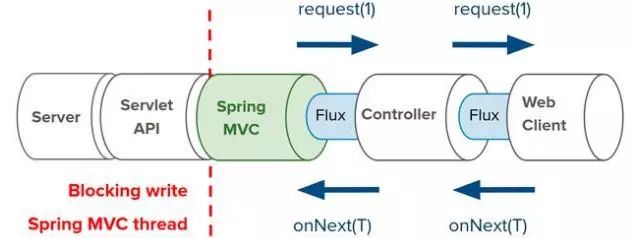
做出选择
你应该选择哪个?Spring MVC还是Spring WebFlux?
这是个很现实的问题,但却难以给出答案。这两个框架各有优势,也存在一些交集。或许,我们可以把它们放在一起,这样就可以看到更多的可能性。
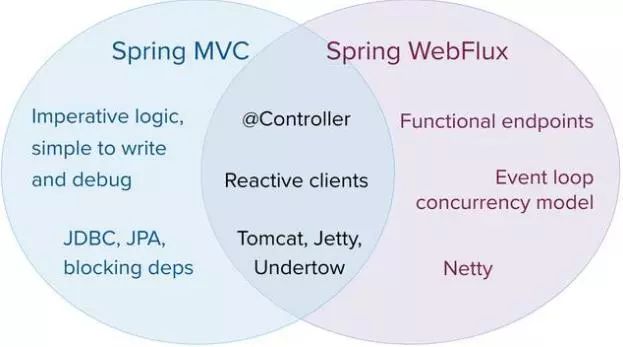
Spring MVC基于典型的Servlet栈提供了一个简单的命令式模型,可用于阻塞或非阻塞式的场景。Spring WebFlux提供了事件循环式的并发模型和函数式的编程模型。我们可以在它们的交集中看到共性的东西。
如果你的应用程序没有伸缩方面的问题,或者横向伸缩的成本在预算之内,那么就没必要做出任何改变。命令式的代码是最容易编写的,而且我希望在不久的将来,大部分应用程序能够归到这个频谱的一边。

当然,命令式代码也会越变越复杂。对于现代应用程序来说,调用远程服务是件很常见的事。有时候,使用命令式风格进行同步调用是没有问题的,但如果要在有限的硬件资源上进行伸缩,那么就需要考虑并发和异步。反应式编程为此提供了有效的解决方案。我希望大部分应用程序能够在Spring MVC中使用WebClient或其他反应式类库(如Spring Data反应式Repository),因为这样只需要做出少许的改动,却会带来很多好处。
响应式栈和Spring WebFlux有多方面的好处。或许,有些场景所要求的高并发和低延迟是传统阻塞式IO无法提供的,又或者横向或纵向伸缩的成本太高。对Spring Cloud Gateway来说,Spring WebFlux显然是个正确的选择,因为它有高并发方面的需求。
响应式栈的反应式处理管道非常适用于流式场景当中,而大部分应用程序都有这样的场景。它支持响应式流回压和非阻塞写入操作,可用于处理请求消息和响应消息。
有些人选择了响应式栈,只是为了能够使用函数式编程模型。函数式端点在Kotlin应用程序中非常流行,WebFlux提供了一个Kotlin DSL用于处理路由请求消息。因为函数式编程模型的简单和清晰,或许十分合适用在微服务上。
来源丨JAVA技术开发
以上是关于大神教你玩Spring 5的Servlet与响应式技术栈解析的主要内容,如果未能解决你的问题,请参考以下文章
教你玩转Spring Cloud Alibaba,150页全解中文文档,限时分享
【手把手教你搓Vue响应式原理】(五) Watcher 与 Dep