当Elasticsearch遇见智能客服机器人
Posted IT大咖说
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了当Elasticsearch遇见智能客服机器人相关的知识,希望对你有一定的参考价值。

内容来源:2017年6月10日,趋势科技个人消费者部机器学习工程师杨文俊在“Elastic Meetup 南京”进行《Elasticsearch辅助的智能客服机器人》演讲分享。IT 大咖说作为独家视频合作方,经主办方和讲者审阅授权发布。
阅读字数:1605 | 4分钟阅读
摘要
本次分享主要会介绍一下ES是如何帮我们完成NLP的任务的。在做NLP相关任务的时候,ES的相似度算法并不足以支撑用户的搜索,需要使用一些与语义相关的方法进行改进。但是ES的很多特性对我们优化搜索体验是非常有帮助的。
我们主要服务的项目是MAC上的APP——Dr.cleaner以及Dr.X系列产品。
Dr.cleaner在多个国家、地区的清理类MAC APP中排名第一,日活接近百万。
多语言、跨时区:我们的APP在国内可能还不是非常出名,它的目前的客户基本都在海外,其中美国是主要客户,同时也有其它国家跟地区的用户。
数量跟不上:随着用户数的急剧增加,客服的数量跟不上用户数的增长。
客服机器人首要能解决产品相关的问题,其次要能解决MAC/ios相关的技术问题,多语言的问题需要通过翻译API翻译成英语再尝试给出解决方案。
任何智能客服如果没有足够的知识库支撑,即使它的算法再强大也不行。所以我们把很多MAC相关的网站抓下来塞进我们的数据库中。
StackExcangeApple分论坛(公开数据源)、Apple Discussion、Mac world、WikiHow…
当用户问题出现的时候,我们如何从文档知识库中找出我们需要的东西?我们之前尝试过直接使用ES,但是距离语义还是太远了,效果并不好。


WMD也有明显缺点,它的算法复杂度非常高,计算速度很慢。WMD不是银弹,即使WMD之后也可能会得到一些不太好的结果。
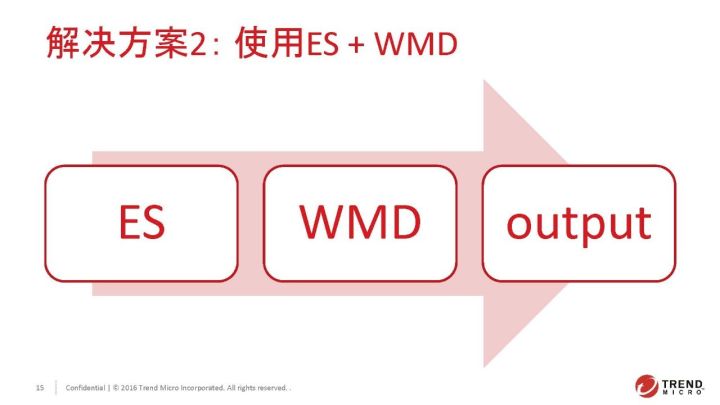
我们的知识库会先经过ES过滤一层。原始的知识库大概是几十万级别,如果直接用WMD计算的话速度会非常慢。ES在一定程度上保证了它的字面差得不会那么离谱,当字面比较相近的时候它还是能匹配出一些东西。

这个是最原始的mapping,我们基于这个mapping一步步去做优化。
采用BM25之后,当一个词的出现频率越高,到一定的阈值之后,它的影响是非常小的。
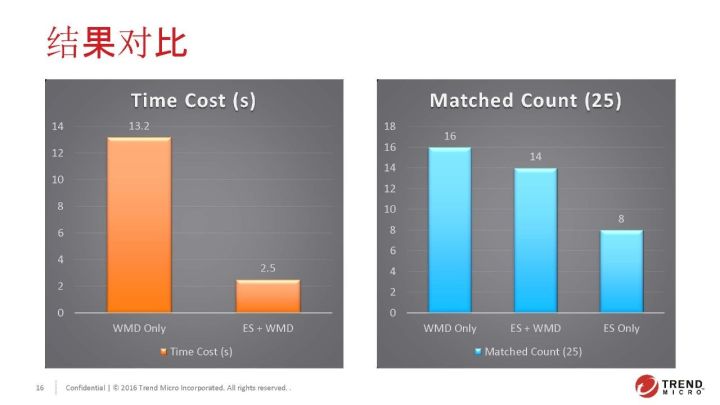
我们做了一个实验,修改了mapping,分别使用BM25 or TFIDF。从知识库中随机选取100个问题和10个回答,让ES进行查询,然后对比两边的结果。
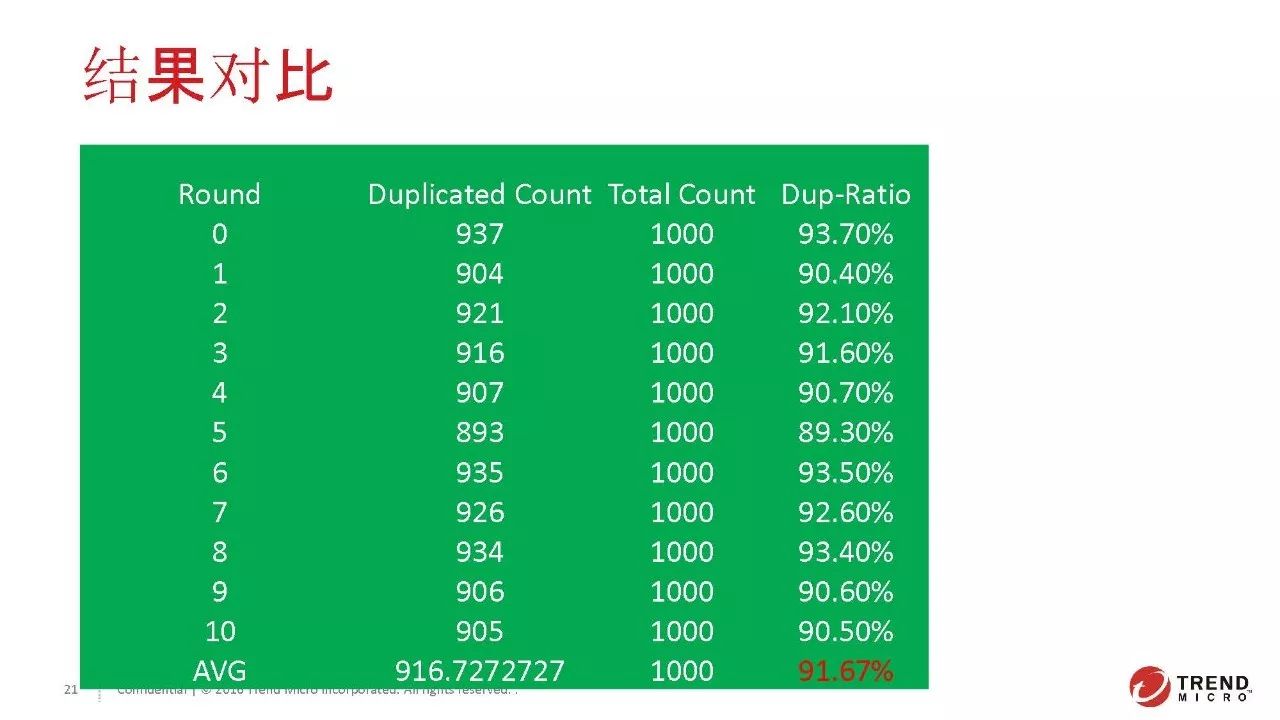
我们一共进行了10轮,每轮会有100个回答。如上图可见,两个算法的重复度大概是91%。
根据实验得出,BM25的作用还是比较明显的,最终我们采用了BM25去做相似度的算法。

我们的方案:Term Suggester + Custom Analyzer
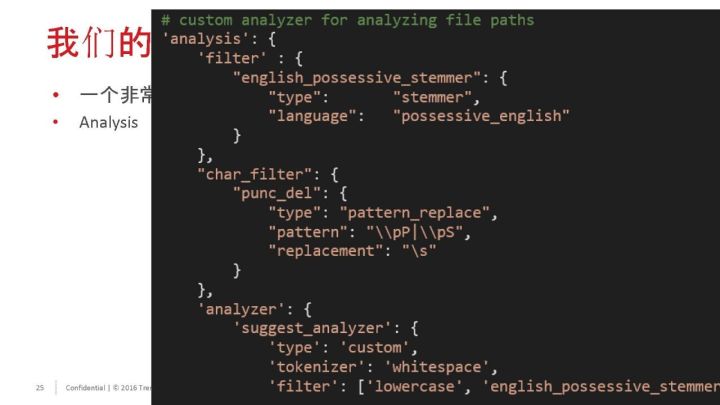
支持直接输入一句话:How to replace macbookk SSD?
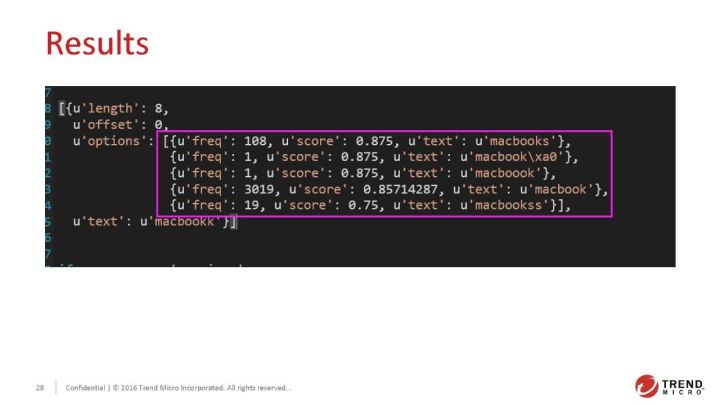
设定最小出现次数为3,修改了”string_distance”,把它改为”jarowinkler”。它默认的相似度是基于编辑距离的一些定制化,编辑距离默认会输出整数。

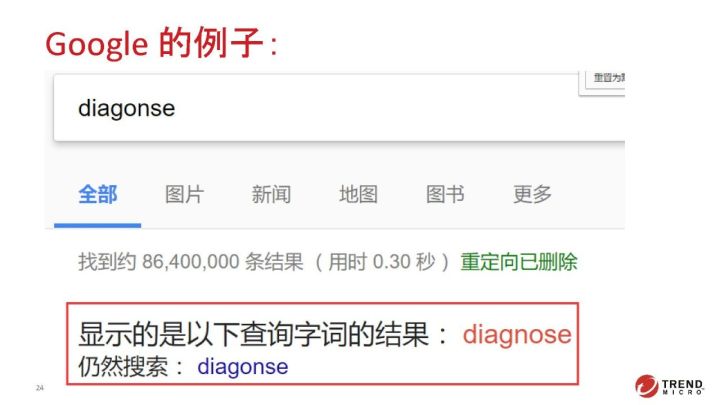
增加用户行为数据的支撑。Google的算法很大一部分就是有用户行为数据支撑。
“瞻前顾后”,从我们的角度来说,要考虑前后两个词的关系。

首先使用Gensim生成备选词组,然后使用规则过滤出比较精确的候选词组。当我们获得一个正确的词组后,可以根据候选词组生成常见的错误写法。最后再实时处理用户输入和批量处理ES存储的知识库。
规则就是纯英文字符,去掉数字。主要是品牌名和版本号。

WMD的计算强度比较大,如果我们在输入词中能把一些不重要的词去掉,就可以降低WMD的计算强度。
在我们的一些知识库中,它的表达方式不一样。但重要的词换一个表达方式,能够提高准确率。
当前我们的解决方案用Python NLTK进行分析过滤,输出每个词的词性,ES存储结果。
我们更为推荐的是使用ES分析、过滤、存储一条龙解决方案,但是这种解决方案需要自己写一个ES的Pos插件。
性能:Java实现的东西一般来说要比纯Python的快,特别是在比较消耗CPU资源的时候。
简单:逻辑不需要在ES和Python两边同时维护。
节省空间:NLTK的模型文件也比较大,多个Docker镜像就意味着占用多个内存、磁盘。

人为地定义同义词很难,我们是基于Word2vec生成“同义词”。

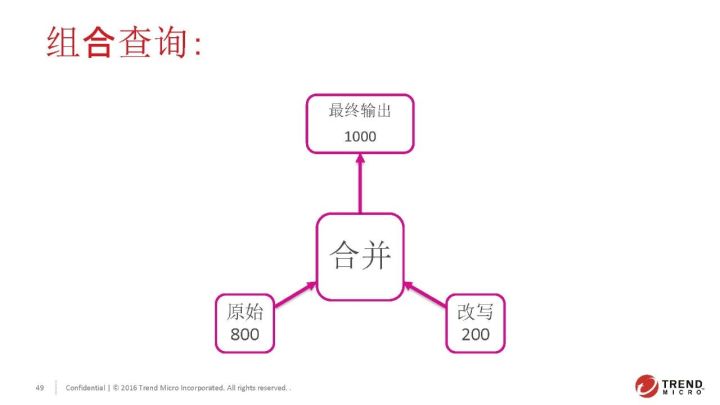
我们的同义词方案是通过同义词进行查询改写。
基于Machine Learning的重排序,模型按照预测的点击概率进行重新排序。
我今天的分享就到这里,谢谢大家!
相关推荐
推荐文章
近期活动
点击【阅读原文】进入干货密道
以上是关于当Elasticsearch遇见智能客服机器人的主要内容,如果未能解决你的问题,请参考以下文章