使用ElasticsearchKafka和Cassandra构建流式数据中心
Posted 小象
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用ElasticsearchKafka和Cassandra构建流式数据中心相关的知识,希望对你有一定的参考价值。
译者:施聪羽
原文链接:http://thenewstack.io/building-streaming-data-hub-elasticsearch-kafka-cassandra/
小象科技原创作品,欢迎大家疯狂转发;
机构、自媒体平台转载务必至后台留言,申请版权。
导读:本文介绍了一种用Elasticsearch、Kafka和Cassandra三个开源组件构建流式数据中心的架构,以帮助大家搭建自己明智而又有伸缩性的架构从而避免我们曾经碰到的那些坑。
以下为正文:
在过去的一年里,我遇到了一些软件公司讨论如何处理应用程序的数据(通常以日志和metrics的形式)。在这些讨论中,我经常会听到挫折感,他们不得不用一组零碎的工具,随着时间的推移将这些数据汇总起来。这些工具,如: - 运维人员使用的,用于监控和告警的工具
- 开发人员用于跟踪性能和定位问题的工具
- 一个完整独立的系统,商业智能(BI)和业务依赖其分析用户行为。
虽然这些工具使用不同的视角,适用不同的场景,但是他们同样都是关注数据来源和类型。因此,许多软件团队说,“如果时间充裕,我们可以建立一个更好的”,坦率地说,现在有很多出色的开源代码,自己重头建立一套是否更有意义值得商榷。在Jut我们就是这样做的。我们使用开源的大数据组件建立了一个流式数据分析系统,这篇文章描述了我们使用的片段以及我们如何把它们组合在一起。我们将介绍:
- 数据摄取:如何引入不同类型的数据流
- 索引及保存数据:高效存储以及统一查询
- 串联:系统中的数据流过程
- 调优:让整个过程真正的快速,用户才会真的使用它。
我希望通过阅读这篇文章将有助于您的系统在一个理智的,可扩展的方式避免一些我们遇到的陷阱。
当涉及到业务分析和监控,大部分相关的数据类型,格式和传输协议并不是固定的。你需要能够支持系统不同的数据来源和数据发送者。例如,您的数据可能包括下列任何一种:
- 自定义的应用程序事件。
- 容器级指标和日志。
- statsd或收集的度量指标。
- 来自第三方的webhook事件,像GitHub或Stripe。
- 应用程序或服务器日志。
- 用户行为。 虽然这些都有不同的格式和象征,他们在系统内部需要一个统一的格式。无论你选择哪一个格式,你都需要对输入的数据流做转换。
我们选择了简单灵活的数据格式:每个记录(“点”)是一系列的键/值对,它可以方便地表示为一个JSON对象。所有的点都有一个“时间”字段,度量点也有一个数值型的“值”字段;其他点可以有任何的“形状”。前端HTTPS服务器(运行nginx)接收数据,多路分配并发送到本地的每个数据类型“连接器”进程(运行Node.js)。这些进程将传入的数据转换为系统的内部格式,然后将它们发布到一个Kafka topic(可靠性),从中,它们可以被用于索引和/或处理。 除了上面的数据类型,多考虑使用连接器,能使您自己的团队最容易将输入数据整合到您的数据总线。你可能不需要太多我在这里描述的通用性或灵活性,但设计一些灵活性总是好的,这使你系统能够摄取更多的数据类型,防止以后新数据到来要重新建造。
所有这些数据都需要保存在某个地方。最好在一个数据库中,当您的数据需要的增长时,将很容易扩展。并且如果该数据库提供对分析类型的查询方式支持,那最好不过了。如果这个数据中心只是为了存储日志和事件,那么你可以选择Elasticsearch。如果这只是关于度量指标,你可以选择一个时间序列数据库(TSDB)。但是我们都需要处理。我们最终建立了一个系统,有多个本地数据存储,以便我们能够最有效地处理不同类型的数据。
ElasticSearch保存日志以及Events
我们使用Elasticsearch作为事件数据库。这些事件可以有不同的“形状”,这取决于他们来自哪一个来源。我们使用了一些Elasticsearch API,效果很好,特别是查询和聚合API。
Cassandra和ElasticSearch保存Metrics
而metrics,原则上,是完全存储在Elasticsearch(或任何其他数据库),使用一个专门的匹配metrics数据结构以及metrics冗余数据的数据库将更有效。 最好的方法是使用现有的开源时间序列数据库(TSDB)。
我们最初是这么使用的 —— 我使用开源TSDB并使用Cassandra作为后端。这种方法的挑战是,TSDB有自己的查询API,它不同于Elasticsearch的API。由于API之间的不同,为事件和指标提供一个统一的搜索和查询界面是很难的。 这就是为什么我们最终决定写自己的TSDB,通过Casandra和Elasticsearch存储metrics。
具体来说,我们在Cassandra中存储的时间/值的键值对,在Elasticsearch中存储元数据,并在顶部有一个查询和管理层。这样,搜索和查询事件以及metrics可以统一在Elasticsearch做。 流式处理引擎 那么现在我们有一个摄取数据的途径和一些数据库。我们是否可以准备添加前端应用程序并使用我们的数据?并没有!尽管Elasticsearch本身可以做一些日志和事件分析,我们仍然还需要一个处理引擎。因为:
- 我们需要一个统一的方式来访问事件和指标,包括实时或历史的数据。
- 对于某些情况(监控、报警),当它发生时,我们需要实时处理这些数据。
- 度量指标!我们想要做的不只是寻找度量指标并读出来
- 度量指标是为了优化现有的度量。
- 即使是事件,我们需要一个比Elasticsearch API更通用的处理能力。例如,join不同的来源和数据,或做字符串解析,或自定义聚合。 从这里开始,事情变得非常有趣。你可以花一天(或更多)研究别人是如何建立数据管道,了解Lambda,Kappa等数据架构。实际上有很多非常好的资料在那里。我们就开门见山:我们达到的效果,是一个支持实时数据流和批处理计算的处理引擎。在这方面,我们完全支持,有兴趣的可以看这里以及这里。
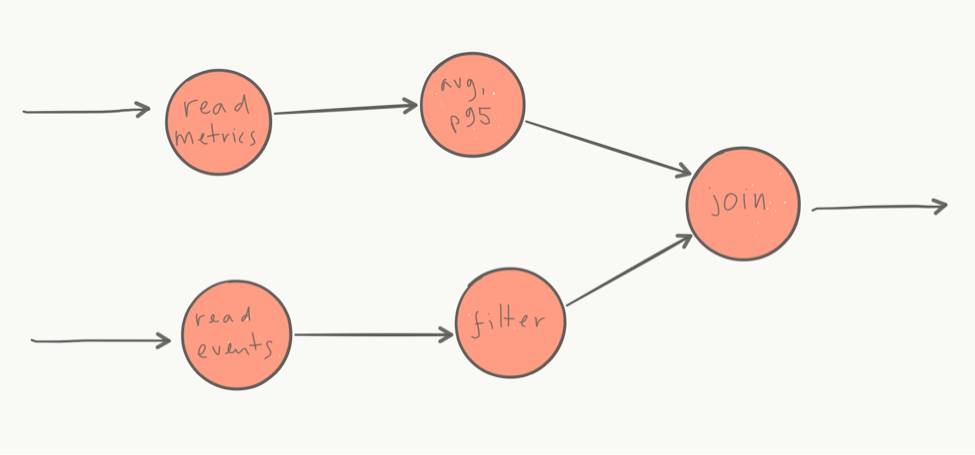
在这里,不同于存储和摄取,我们从头建立了自己的处理引擎,- 不是因为没有其他的流处理引擎,而是由于我们看重查询的性能,我们将在下面的部分单独讨论。更具体地说,我们建立了一个流处理引擎,实现了数据流处理模型,计算表示被表示为一系列操作的有向图,将输入转化为输出的,这些操作包括聚合,窗口,过滤或join。这能很自然的将模型的查询和计算组合起来,适合实时和批量,且适合分布式运行。
当然,除非你真的在寻找建立一个新的项目,然而我们推荐你使用一个开源的流处理引擎。我们建议你看看Riemann, Spark Streaming或者Apache Flink。
我们使用流处理引擎,基于数据流模型的计算。但用户如何表达查询和创建这样的数据流图?一个方法是提供一个API或嵌入式DSL。该接口将需要提供查询和筛选数据、定义转换和其他处理操作的方法,而且最重要的是,提供一种将多个处理阶段组合并应用到流图的方法。上述每一个项目都有自己的API,而个人的偏好可能有所不同,API常见的一个挑战是,SQL分析师或Excel用户无法方便的使用。
一个可能的解决问题的方案,在这一点上,可以让这些用户通过基于这些API构建的工具来访问系统(例如,一个简单的web应用程序)。
另一种方法是提供一个简单的查询语言。这是我们Jut在做的。因为目前没有现有的数据流的查询语言(如SQL之于关系查询),我们创建了一个数据流查询语言称为Juttle。它的核心,Juttle的流图查询语言可以用简单的语法,声明处理管道,如上图所示。
它具有这些原语,search,window,join,aggregation和group-by,语法简单。当然,在处理一个流程图数据之前,你需要取得到数据 - Juttle允许您定义查询获取数据,通过事件和/或度量的任何组合,实时和/或历史的,都具有相同的语法和结构。下面是一个简单的例子,遵循一个模式… query | analyze | view (注意链接使用管道操作符,语法类似shell)。 ``` read -from :1 day ago: datatype = 'weblog' | reduce -every :minute: count() by status_code | @timechart ```
到目前为止,我们已经采取了一个组件为中心的视角-我们已经讨论了组成成分和它们的作用,但没怎么提到关于如何将它们组合在一起。现在我们将视角切换到以数据为中心,看看支持实时和历史查询需要哪些步骤。让我们使用一个异常检测算法的实例来解说。这是一个很好的例子,因为我们需要查询历史数据来训练潜在的统计模型,实时流数据来测试异常,然后我们需要把结果写回系统,同时异常告警。
但是,在我们做任何查询之前,我们需要串联下摄取的整个过程,传入的数据是如何写入索引存储。这是由import服务完成的,服务完成了包括写入时间序列数据库,将指标数据和元数据存储在Elasticsearch和Cassandra。
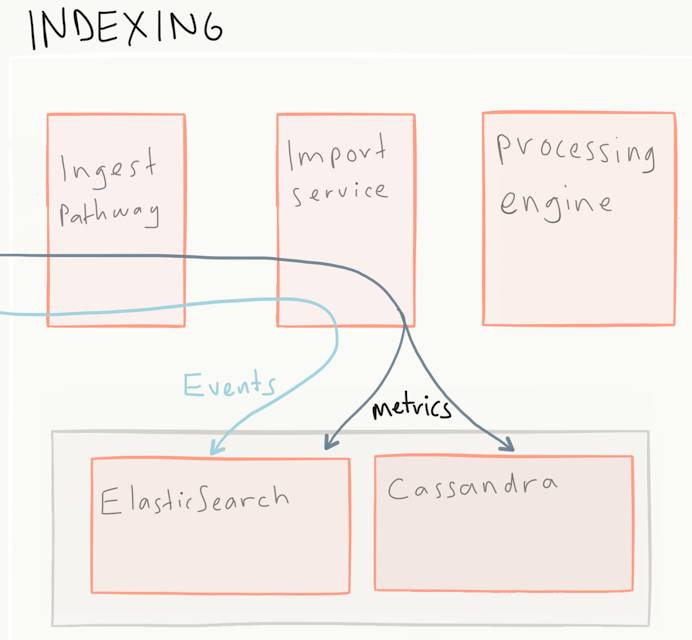
现在一个用户来了,启动了一个异常检测的job。这需要读取历史数据,通过任务处理引擎直接查询底层数据库来进行的。不同的查询和数据可以进一步做性能优化(下面讨论),和/或实施度量数据库的读取路径(查询Elasticsearch中的元数据,获取Cassandra中的度量值,并结合结果产生实际的度量点)。
历史数据涵盖了一些过去范围内的数据,处理引擎将历史数据转换成流向图的实时数据。为了做到这一点,处理引擎直接将数据导入import服务的入口点。请注意,这种切换必须小心,以免数据丢弃或者数据重复。
在这一点上,我们有一个训练有素的异常检测流图运行在实时数据上。当检测到异常时,我们希望它将警报发送给一些外部的系统,这可以通过处理引擎向外部的HTTP服务POST数据。除了发送警报,我们还希望保持对内部系统的跟踪。换句话说,我们希望能够将数据流写回系统中。从概念上讲这是通过处理引擎管道返回数据到摄取途径。
那么我们已有了一个摄取数据的工作系统的和一些数据库以及处理引擎。我们可以准备添加前端应用程序并分析我们的数据了吗?还没有! 嗯,我们实际上可以这样做,但问题是我们的查询性能仍然会非常慢。而缓慢的查询意味着……没有人会使用我们的系统。
因此,让我们重新审视一下“统一处理引擎”的概念。按照我们的解释,它是同一个系统使用相同结构,抽象和查询来处理历史或实时的数据。 性能挑战来自于这样的一个事实,历史数据比实时数据要多的多。例如,假设我们有一百万点/秒的速度输入到系统,并有一个是足够快处理过程,可以在数据录入时进行实时查询。现在采取相同的查询语义查询过去一天的数据 。
这将需要一次性处理数百亿点(或者,至少,必须能跟的上从存储点读取的速度)。假设计算是分布式的,我们可以通过增加计算节点来解决,但在最好的情况下,这将是低效和昂贵的。 所以这就是优化的所在。有许多方法可以优化数据查询。其中一些包括对查询本身进行转换 。例如,上游数据的filters或aggregations尽可能不改变查询语义。我们说的这种优化,是将数据的filter和处理尽量由数据库去做。这需要做以下的:
- 自动识别可以由数据库处理查询的部分
- 将对应的部分转换成目标数据库的查询语言
- 运行后端查询并将结果注入到数据流图的正确位置
我们做到了!当然,如果不需要一个可视化层,我们就完成了。只能通过API来查询系统。建立一个客户端应用程序来创建查询,流和可视化数据,组合仪表板是另外一个棘手的问题,所以我们将改天讨论这个。
现在,让我们来总结一下我们在建设这个数据中心过程中的所见所闻:
- 一个摄取途径,可以接受不同来源的输入数据,并将其转换为统一的格式,并储存起来供以后消费。(在Jut,这是基于Kafka建立的)。
- 事件和度量的数据库。在Jut,Events使用Elasticsearch,自己构建的度量数据库则基于Cassandra。
- 一个处理引擎(或是两个,如果你要用lambda ISH架构)。
- 在系统上运行查询的API或查询语言。 唷。建立这套系统,是一个漫长而有趣的旅程。即便你要建立你自己的系统,可以先试试Jut。你可能会觉得很好用。
以上是关于使用ElasticsearchKafka和Cassandra构建流式数据中心的主要内容,如果未能解决你的问题,请参考以下文章