手把手教学:使用Elastic search和Kibana进行数据探索(Python语言)
Posted 36大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了手把手教学:使用Elastic search和Kibana进行数据探索(Python语言)相关的知识,希望对你有一定的参考价值。
探索性数据分析(EDA)帮助我们认识底层的数据基结构及其动力学,以此来最大限度发掘出数据的可能性。EDA是提取重要变量和检测异常值的关键。尽管存在着很多种机器学习算法,但EDA仍被视为理解和推动业务的最关键算法之一。
其实有很多种方式都能够执行实现EDA,例如Python的matplotlib、seaborn库,R语言的ggplot2,而且网络上有很多很好的资源,例如John W. Tukey的“探索性数据分析”, Roger D. Peng 的“用R进行探索性数据分析”等,不胜枚举。
在本文中,我主要讲解下如何使用Elastic search和Kibana实现EDA。

目录:
1. Elastic search
2. Kibana
3. 创建数据表
数据索引
链接Kibana
可视化
4. 搜索栏
1. Elastic Search (ES)
Elastic Search是一个开放源码,RESTful分布式和可扩展的搜索引擎。由于其简单的设计和分布式特性,Elastic Search从大量级数据(PB)中进行简单或复杂的查询、提取结果都非常迅速。另外相较于传统数据库被模式、表所约束,Elastic Search工作起来也更加容易。
Elastic Search提供了一个具有HTTP Web界面和无模式JSON文档的分布式、多租户的全文搜索引擎。
ES安装
安装和初始化是相对简单的,如下所示:
下载并解压Elasticsearch包
改变目录到Elasticsearch文件夹
运行bin/ Elasticsearch(或在Windows上运行bin elasticsearch.bat)
Elasticsearch实例在默认配置的浏览器中进行本地运行http://localhost:9200。
2.Kibana
Kibana是一个基于Elasticsearch的开源数据挖掘和可视化工具,它可以帮助用户更好地理解数据。它在Elasticsearch集群索引的内容之上提供可视化功能。
安装
安装和初始化的过程与Elasticsearch类似:
下载并解压Kibana包
用编辑器打开config/ Kibana.yml,配置elasticsearch.url指向本地ElasticSearch实例所在位置
更改目录到Kibana文件夹
运行bin/ Kibana(或在Windows上运行bin kibana.bat)
Kibana实例在默认配置的浏览器中进行本地运行http://localhost:5601.
将运行Kibana的终端保持打开状态,可以保证实例不断的运行。你也可以使用nohup模式在后台运行实例。
3. 创建数据表
使用ES和Kibana创建仪表板主要有三个步骤。接下来我将会用贷款预测的实际问题的数据来示例如何创建一个仪表板。请注册该问题,以便能够下载数据。请检查数据字典以获得更多详细信息。
注:在本文中,我将使用python读取数据并将数据插入到Elasticsearch中,并通过Kibana进行可视化。
读取数据
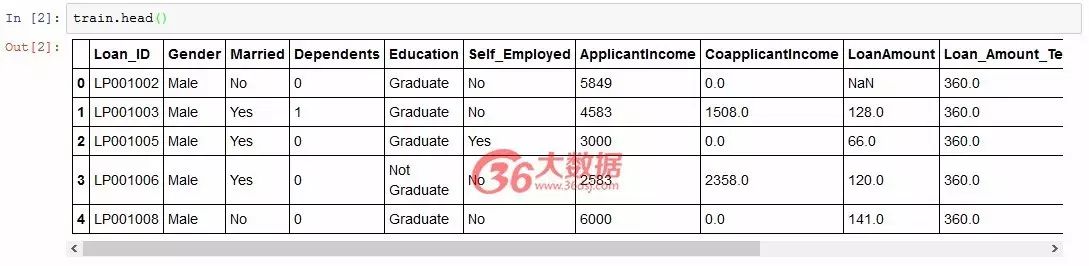
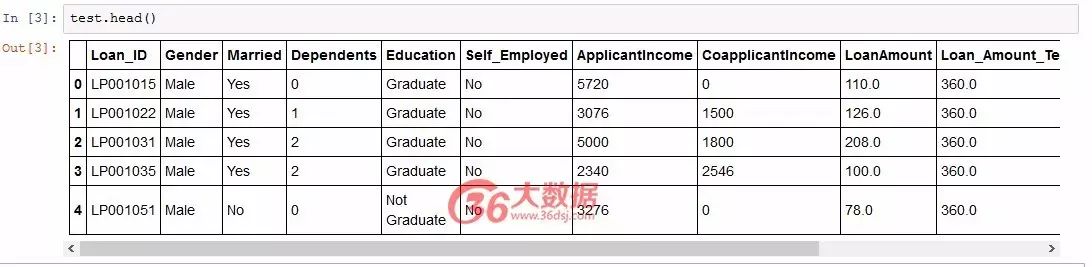
import pandas as pd
train_data_path = '../loan_prediction_data/train_u6lujuX_CVtuZ9i.csv'test_data_path = '../loan_prediction_data/test_Y3wMUE5_7gLdaTN.csv'train = pd.read_csv(train_data_path); print(train.shape)test = pd.read_csv(test_data_path); print(test.shape)
结果:
(614, 13) (367, 12)
3.1 数据索引
Elasticsearch将数据索引到其内部数据格式,并将其存储在类似于JSON对象的基本数据结构中。请找到下面的Python代码,将数据插入到ES当中。
请如下所示安装pyelasticsearch库以便通过Python索引。
pip install pyelasticsearchfrom time import timefrom pyelasticsearch import ElasticSearchCHUNKSIZE=100index_name_train = "loan_prediction_train"doc_type_train = "av-lp_train"index_name_test = "loan_prediction_test"doc_type_test = "av-lp_test"
def index_data(data_path, chunksize, index_name, doc_type): f = open(data_path) csvfile = pd.read_csv(f, iterator=True, chunksize=chunksize) es = ElasticSearch('http://localhost:9200/') try : es.delete_index(index_name) except : pass es.create_index(index_name) for i,df in enumerate(csvfile): records=df.where(pd.notnull(df), None).T.to_dict() list_records=[records[it] for it in records] try : es.bulk_index(index_name, doc_type, list_records) except : print("error!, skiping chunk!") pass
index_data(train_data_path, CHUNKSIZE, index_name_train, doc_type_train) # Indexing train data
index_data(test_data_path, CHUNKSIZE, index_name_test, doc_type_test) # Indexing test data
DELETE /loan_prediction_train [status:404 request:0.010s] DELETE /loan_prediction_test [status:404 request:0.009s]
3.2 链接Kibana
在浏览器上访问 http://localhost:5601
去管理模块中选取索引模式,点击添加。
如果你的索引数据中包含时间戳,则选复选框。否则,取消选中该框。
将之前用于数据索引到ElasticSearch中的索引输入。 (例如:loan_prediction_train)。
点击新建。
对loan_prediction_test重复上述4个步骤。 现在kibana已经与训练数据链接,并测试数据是否已经存在于elastic search中。
3.3可视化
单击 可视化>创建可视化>选择可视化类型>选择索引(训练或测试)>构建
例一
选择垂直条形图,并选择绘制Loan_status分布的训练索引。
将y轴作为计数,x轴代表贷款状态
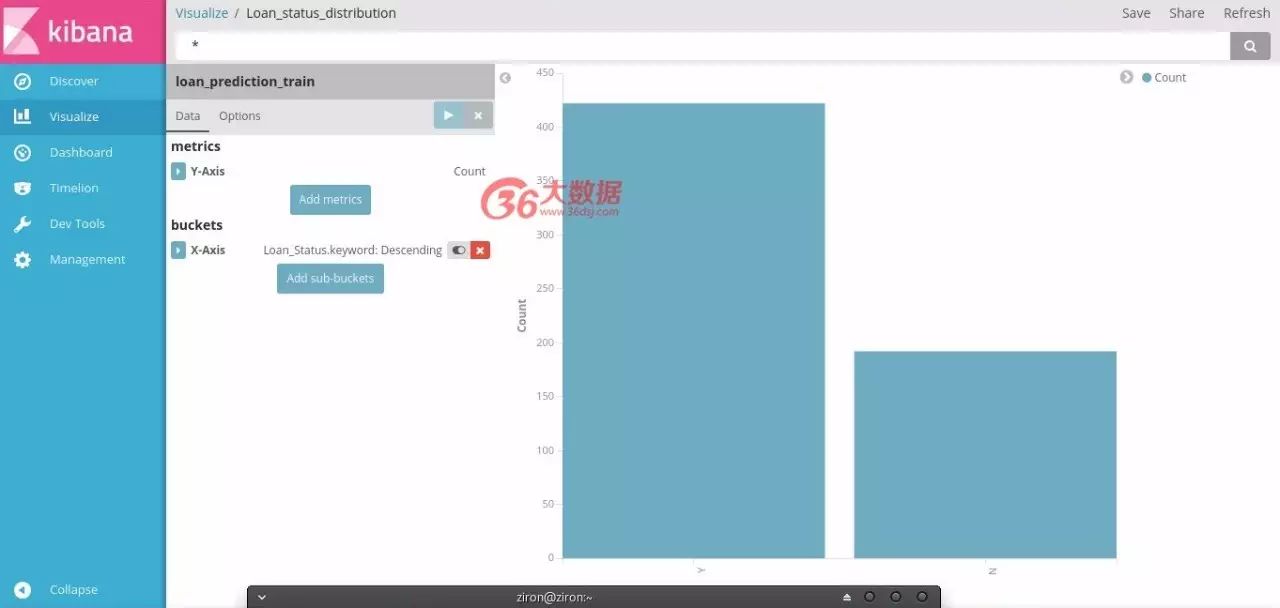
保存可视化
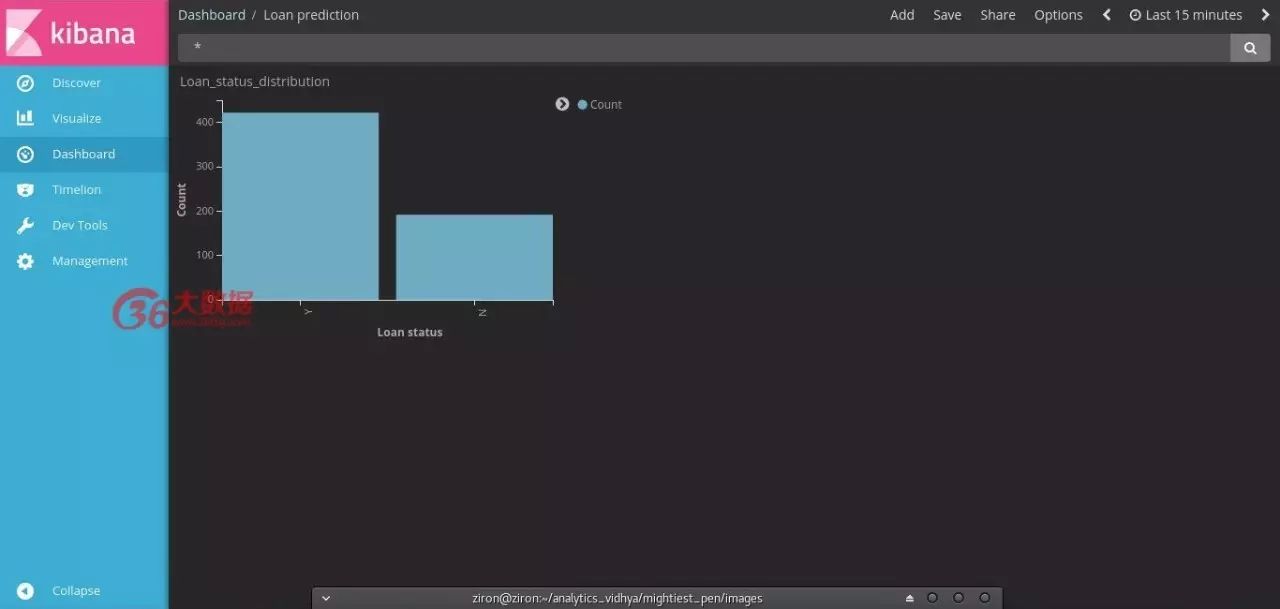
添加仪表板>选择索引>添加只保存的可视化。
Voila!! Dashboard 生成啦!
例二
单击可视化>创建可视化>选择可视化类型>选择索引(训练或测试)>构建
选择垂直条形图,并选择训练索引绘制已婚分布。
选择y轴为计数,x轴为已婚
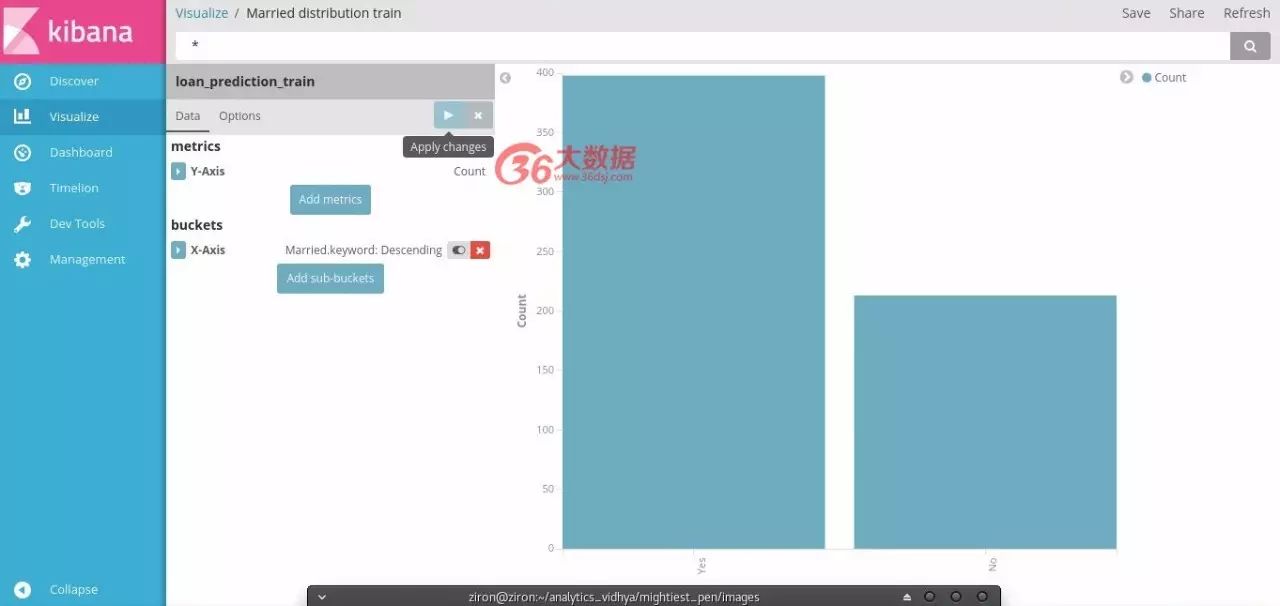
保存可视化。
重复上述步骤进行索引测试。
打开已创建的仪表板添加这些可视化
例三
类似的性别分布。这一次我们将使用饼图。
单击可视化>创建可视化>选择可视化类型>选择索引(训练或测试)>构建
选择饼图并选择列车索引绘制已婚分布。
按“已分隔”列选择切片大小作为计数和分割片段
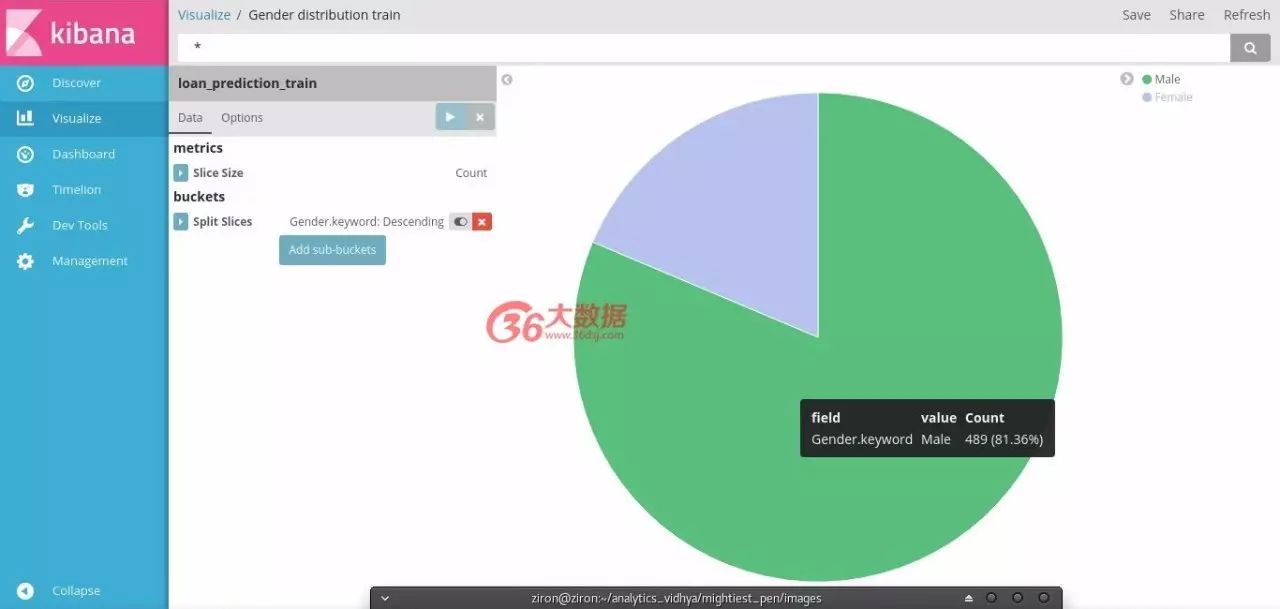
保存可视化。
重复上述步骤进行索引测试。
打开已创建的仪表板添加这些可视化
最后,创建所有可视化的仪表板将如下所示!
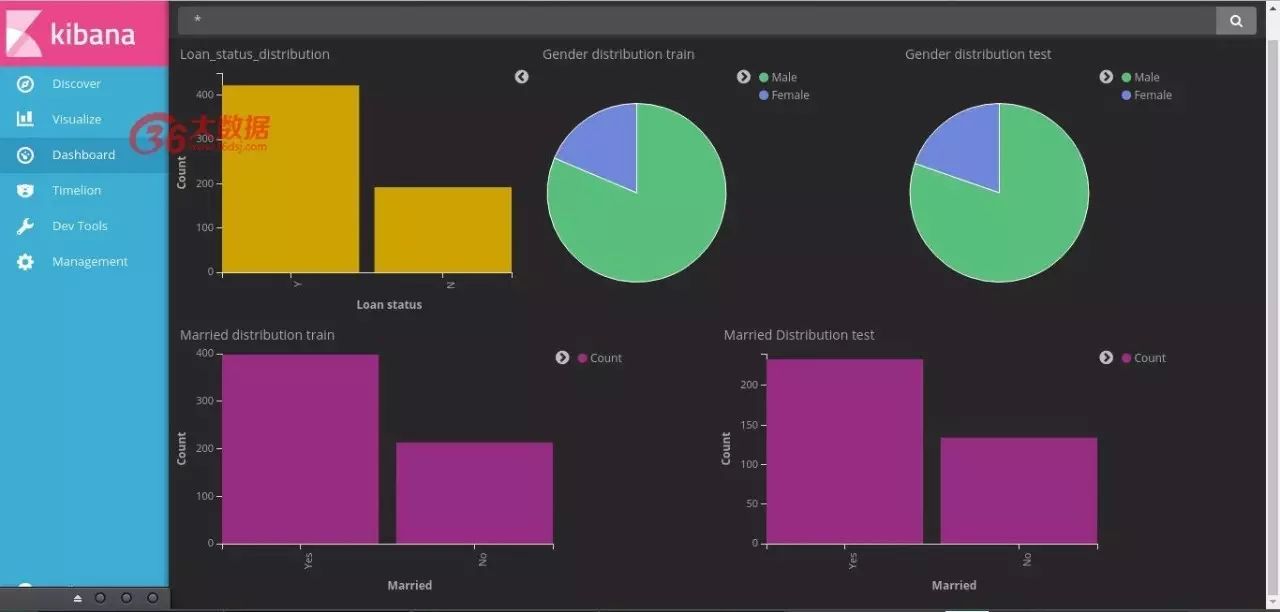
是不是很漂亮!
剩下将由你来探索更多的elasticsearch和Kibana了,并创建多种多样的可视化效果。
4.搜索栏
搜索栏允许用户通过字符串来搜索来数据,这便有助于我们理解数据中的更改,并在一个特定属性中进行更改,这对于可视化来说是不容易的。
举例
转到发现>添加Loan_Status和Credit_History
使用搜索栏仅选择Credit_History为0.(Credit_History:0)
现在可以查看Loan_Status列中的更改记录。
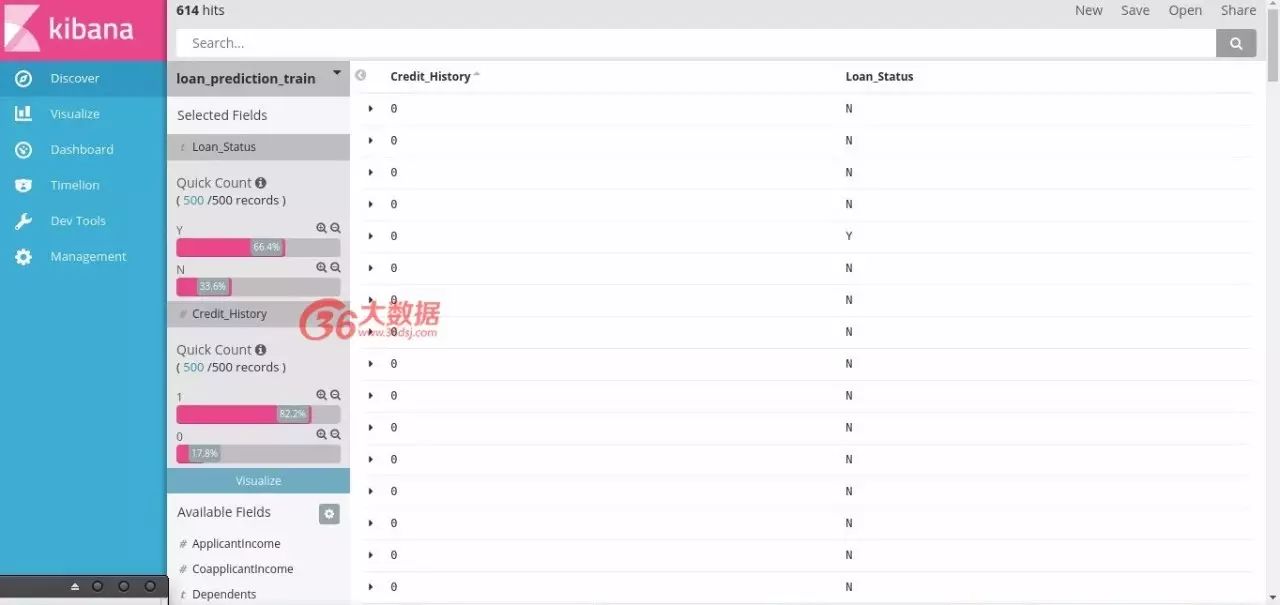
观点:大多数信用记录为0的客户没有收到贷款(贷款状态为N = 92.1%)
以上为全文。
End
你投稿,我送书
为了让大家能有更多的好文章可以阅读,36大数据联合华章图书共同推出「祈文奖励计划」,该计划将奖励每个月对大数据行业贡献(翻译or投稿)最多的用户中选出最前面的10名小伙伴,统一送出华章图书邮递最新计算机图书一本。投稿邮箱:dashuju36@qq.com
“讲述大数据在金融、电信、工业、商业、电子商务、网络游戏、移动互联网等多个领域的应用,以中立、客观、专业、可信赖的态度,多层次、多维度地影响着最广泛的大数据人群
36大数据
搜索「36大数据」或输入36dsj.com查看更多内容。
投稿/商务/合作:dashuju36@qq.com
↓↓↓
以上是关于手把手教学:使用Elastic search和Kibana进行数据探索(Python语言)的主要内容,如果未能解决你的问题,请参考以下文章
如何使用现有索引创建 Elastic App Search Engine(来自 GraphDB Elastic Search Connector 的数据)