去哪儿网OPS团队基于Mesos/Docker构建的Elasticsearch容器化私有云
Posted 分布式实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了去哪儿网OPS团队基于Mesos/Docker构建的Elasticsearch容器化私有云相关的知识,希望对你有一定的参考价值。
本文主要介绍去哪儿网 OPS 团队利用 Mesos 资源管理平台和 Docker 容器技术所构建的 Elasticsearch 容器化的私有云。
主要有四个部分, 第一个部分主要介绍一个我们当初做这个平台的背景,和现在的规模和现状,第二个部分主要简单介绍一下整个平台的技术实现,最后分享是持续构建方面的工作以及监控和报警相关方面的工作。

2015年底到2016年初的这段时间,公司业务线对 ES 的需求量暴增,传统的使用 ES 的方式逐渐显现出一些弊端,主要有一下几点的内容:

针对上述所列的几点弊端,我们最初制定的几点设计目标如下:

最终,为了达到这几点目标,我们就设计和开发了这个平台。

自从16年3、4月份这个平台上线以来,工作效率得到了很大改进,主要有以下三个方面:

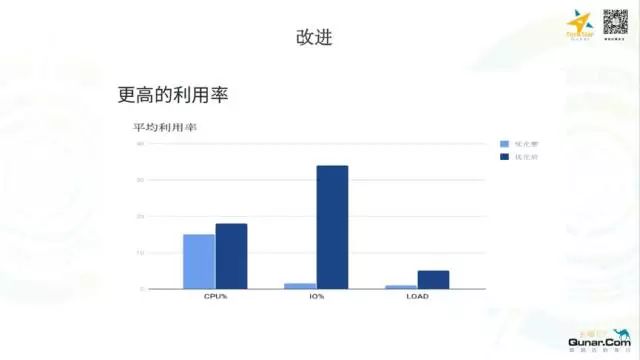
下面这个图是统计的过去传统的使用方式与现在的平台的方式使用 ES 所带来的资源利用率的提升:
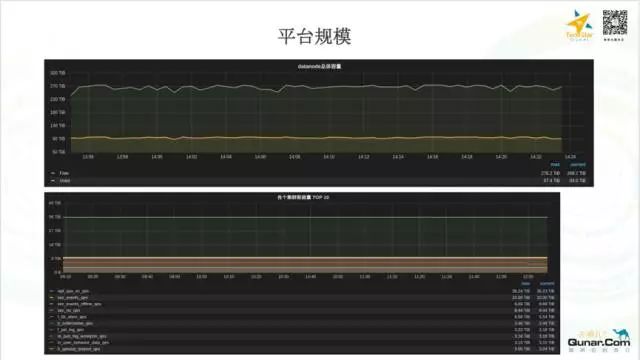
这个是我们目前的平台规模:
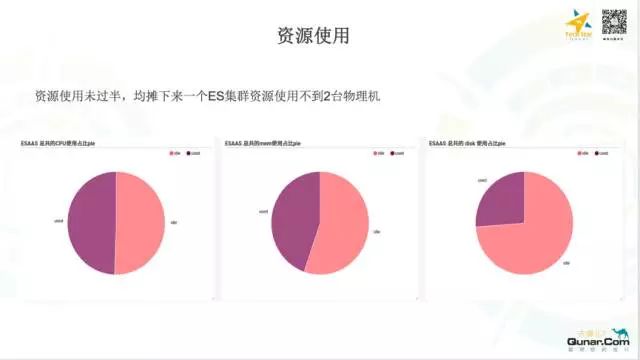
整个平台支持了很多重要系统后端的数据存储,比如:

刚开始做这个平台的时候,我们主要调研参考了以下三个系统和平台:

第一个 Elastic Cloud 是 Elastic 官方提供的一个公有云的服务,他能够提供快速集群构建的能力,也具备自助化配置,快速扩容能力,比较符合我们的预期功能。第二个 Amazon Elasticsearch Service 同样也是一个公有云服务,能够提供快速的集群构建能力,自助化配置等等,同样也为我们提供了极大的参考价值。第三个是一个开源的基于 Mesos 的一个调度框架,他的设计是一个 Framework 代表一个 ES 集群,Framework 的每一个 Executor 代表一个 ES 节点,但是也有许多不支持,包括不支持多种角色节点的配置,不支持自助化的配置,不支持插件的安装,这与我们的设计初衷是相违背的。结合了上述三个例子,我们设计指定了我们自己的技术方案。

整个平台基于 Mesos,所有组件以 Docker 容器的形式被 Marathon 调度跑起来,这个是一个整体的结构图:
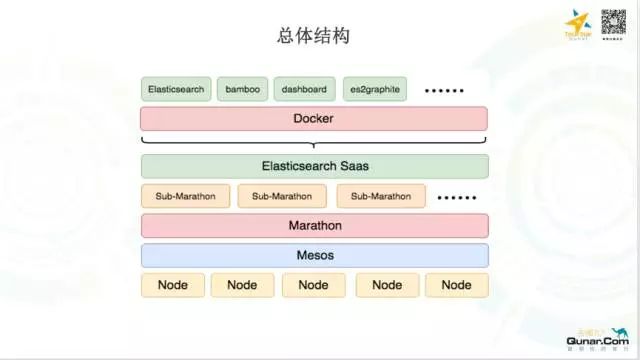
我们底层所有的机器都是被同一个 Mesos 来进行统一管理的,Mesos 之上运行着 Marathon 调度框架,值得注意的是,我们有两层的 Marathon,底层比较大的 Marathon 我们称之为 Root Marathon,上层包含在 Root Marathon 之中的小的 Marathon 我们称之为 Sub Marathon,Root Marathon 只负责调度内层的Sub Marathon,内存的 Sub Marathon 才是真正承载着我们每一个 Es Saas 服务。我们所有的组件都是跑在 Docker 容器里面的。
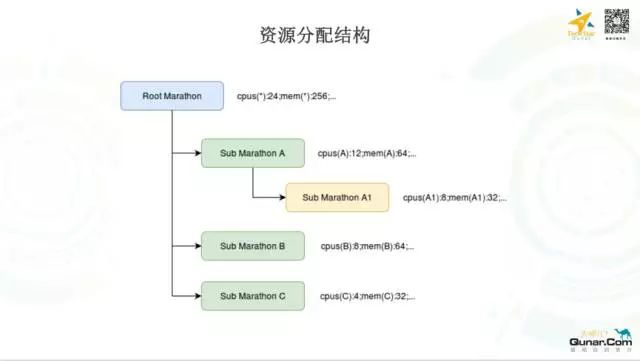
那么我们平台的资源是怎么分配的呢,这个图是一个分配的结构图,可以看到资源是按照 Marathon 分层的这种方式来分配的,Root Marathon 拥有系统所有的资源,Sub Marathon 是资源分配的最小单位,每一个都有它既定的资源,资源结构如此,当然集群间的逻辑隔离也是如此。
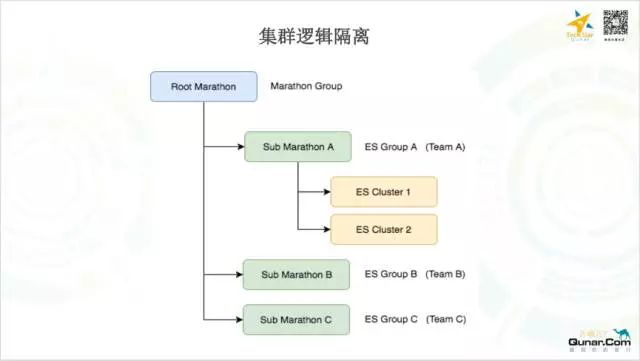
Sub Marathon 不仅有他自己的资源,而且我们将它和业务线做了一一映射,也就是说一个Sub Marathon 唯一的代表一个业务线,同时它也是承载了业务线的所有集群。
下面这个图展示的是 Sub Marathon 内部细节的结构图:
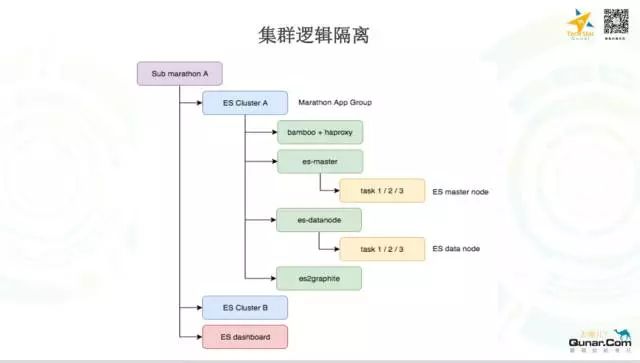
一个 Sub Marathon 可以承载多个 ES 集群,每一个 ES 集群有4个重要的组件,分别是:Bamboo,es-master,es-datanode,es2graphite,这4个组件是组成 ES 集群的基础,他们分别对应着一个 Marathon 的 APP,APP 的 task 是真正的 ES 节点。 下面这个图展示了上述4种基础组件之间的关系:
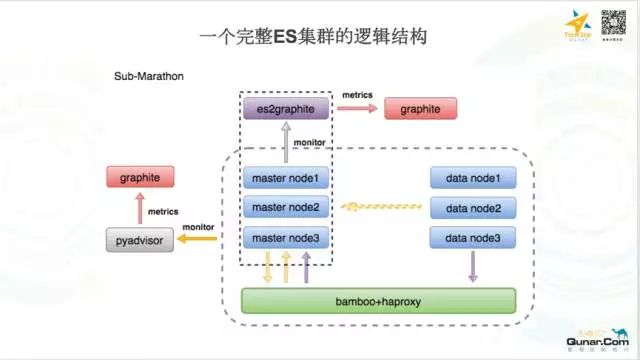
默认的 ES 有3个 master 节点和3个 datanode 节点,他们分为两个 Marathon APP 独立运行,他们之间互相的服务发现是由 Bamboo + HAProxy 这个组件来完成的,这样他们才能连成一个集群,es2graphite 负责收集 ES 集群指标,它的原理就是调用 ES 内部的接口获取指标,然后聚合打到后端的 Graphite 上分析展示。pyadvisor 这个组件不是存在每一个集群中的,而是 run 在每一个 mesos slave 上的一个服务,他们负责收集容器维度的指标,聚合之后打到后端 Graphite 上实时展示,下面就是一个具体的 slave 机器上的快照:
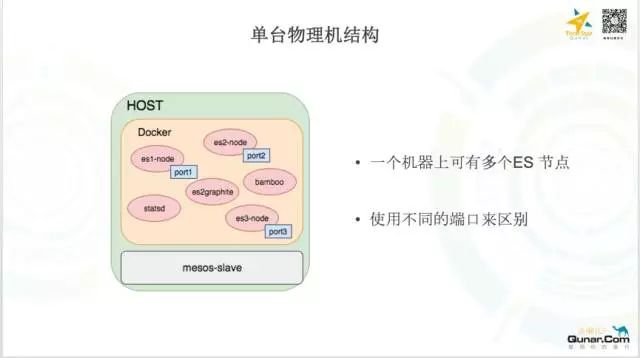
每个机器上可以跑多个 ES 节点,不同的 ES 节点之间使用端口号来区别。
在每一个 ES 集群中,起着至关重要作用的就是服务发现,而这个服务发现是由 Bamboo + HAProxy 这个组件来完成的。
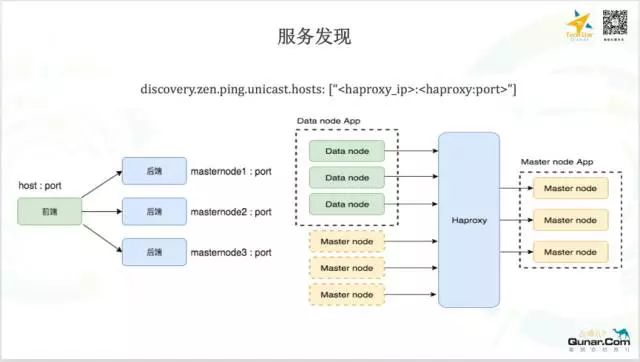
Bamboo 是一个开源的跑在 Marathon 之上服务发现的工具,它的原理就是注册了 Marathon 的 callback 接口接受 Marathon 事件消息时时解析并 reload haproxy。
在数据持久化和可靠性方面我们做了一下几个方面的工作:

配置和部署
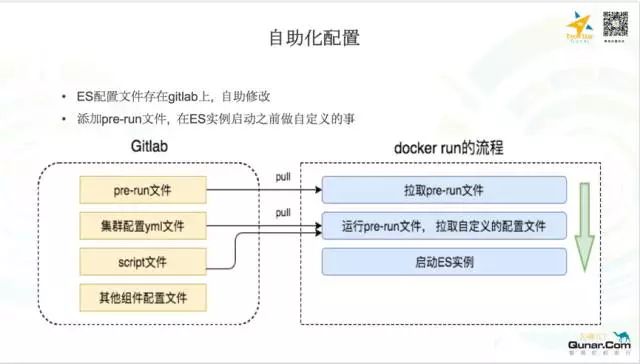
接下来介绍一下我们做的自助配置和持续构建方面的工作,有关所有的 ES 的配置我们都存在了 GitLab 中,包括一个特殊的 pre-run 文件,这个文件定义了在我们启动 ES 节点实例之前我们该做些什么,这个文件是可以修改的,可以由业务线同学自定义。同时一些其他的配置文件也是存在 GitLab 上的,修改之后,只需要重启容器即可生效。
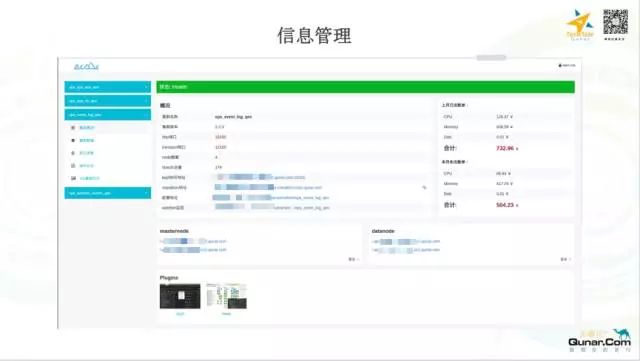
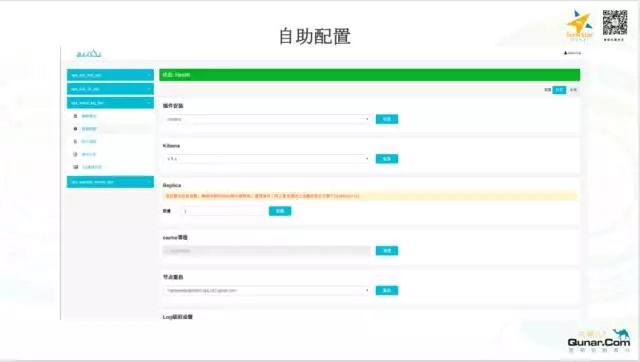
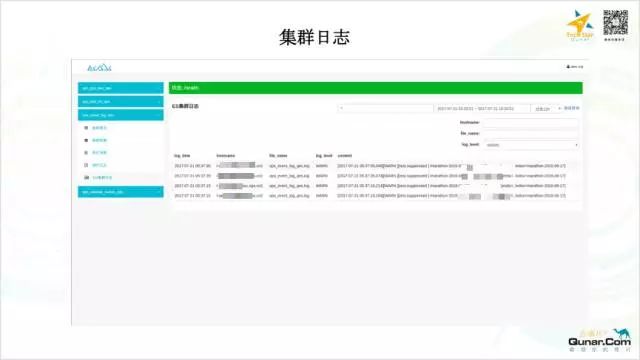
在新集群交付的时候,我们也是直接交付这个 Web 页面,业务线同学可以很方便的查到信息,也可以很方便的做一些操作。说到交付,我们在持续构建方面也做了一些工作。
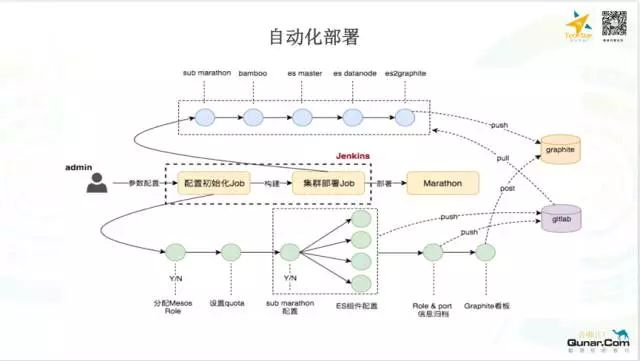
最后一部分说一下监控和报警,监控指标的收集,主要有两个方式:

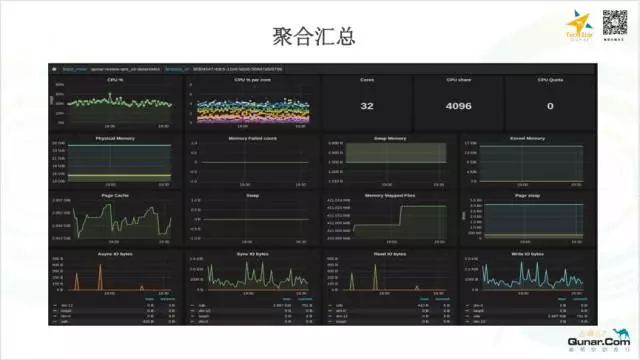
下面是指标聚合之后的一个示例:
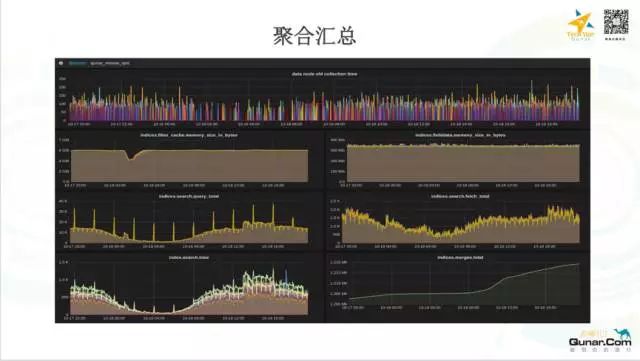
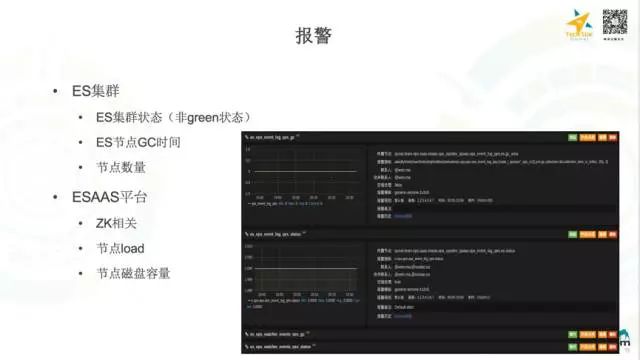
关于报警,主要有一下几个方面:
最后,用一张图来总结一下所有的内容:
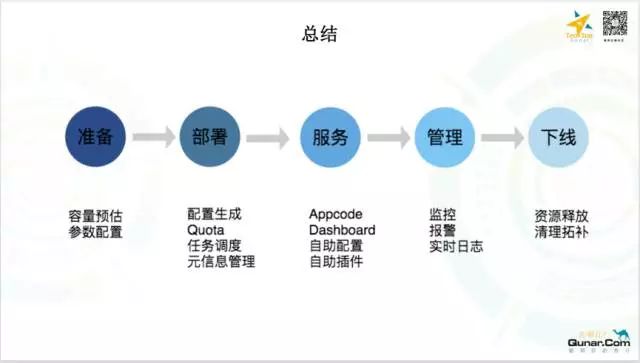
从 ES 的建立到销毁,我们做到了 ES 集群整个生命周期的管理,建立初我们会做容量预估和参数的配置,等到部署的时候,我们有持续构建部署的工具来做,服务上线之后我们提供了可以自助配置,自助插件的 web 工具,极大的方便了开发人员,同时也有完备的监控和报警。集群下线的时候,统一的回收资源,做一些清理拓补的工作。
以上是关于去哪儿网OPS团队基于Mesos/Docker构建的Elasticsearch容器化私有云的主要内容,如果未能解决你的问题,请参考以下文章
OPS基于Mesos/Docker构建的Elasticsearch容器化私有云