探秘ElasticSearch -lucene引擎搜索分析
Posted Thoughts和科技
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了探秘ElasticSearch -lucene引擎搜索分析相关的知识,希望对你有一定的参考价值。
一、引言
在Elastic Search里面,lucene是其当前的默认存储引擎(目前也只有lucene一个引擎)。ES为了支持各种查询请求,需要从分散在不同机器的数据里面发起查询,并把结果合并。但底层的数据的查询仍然是通过lucene的查询功能进行支持,为此我们分析lucene的【条件过滤】、【聚合】、【排序】的过程能反映出ES的查询底层实现。当然,对于ES怎么把做分布式查询部分,本文暂不涉及,后续会进行分析。本文聚焦在底层的存储引擎实现过程。
PS:本文分析基于Elastic Search 2.3.3,该版本使用的 Lucene 5.5.0。
二、lucene里面如何进行一次查询(Query)请求?
首先,我们定义这里指明的查询:通过条件过滤记录,根据需要做聚合查询,并按一定顺序排序返回全部或部分满足的记录。从一个整体流程图入手:
结合上图,下面参考一个lucene查询的简单例子:
// 1. 打开一个索引搜索
IndexSearcher searcher = new IndexSearcher(reader);
Analyzer analyzer = new StandardAnalyzer();
// 2. 进行查询语法分析,构建一棵Query树
QueryParser parser = new QueryParser("my_field", analyzer);
Query query = parser.parse(" hello OR world");
int count = 10;
// 3. 进行Search请求,先是构建一个Weight数(搜索引擎里面有词加权),然后构建Scorer树(其实就是查询词的倒排列表的封装)。
// 进行复杂的条件过滤,并返回结果。
TopDocs results = searcher.search(query, count);
ScoreDoc[] hits = results.scoreDocs;
int numTotalHits = results.totalHits;
int end = Math.min(numTotalHits, count);
// do print
System.out.println(numTotalHits + " total matching documents");
for(int start=0;start < end;start++)
{
Document doc = searcher.doc(hits[start].doc);
System.out.println("doc:"+ start + ",content:"+doc.toString());
}
我们总结一下流程:
输入Query语法
构建query树,其实就是AND OR NOT的一棵树
构建weight树,同Query树,加入了权重
构建scorer树,同Query树,直接封装了满足条件的倒排列表
Score树是查询出来满足查询条件值的倒排列表封装。
Scorer中间是BulkScorer,这个是包括了打分环节,打分的选择就是传统的搜索引擎打分方法,包括:Vector Space Model (VSM),按词向量进行相似度计算发奋。
Probablistic Models such as Okapi BM25 and DFR,这几个是概率模型。
Language models,自然语言模型。
接下来我们将从条件过滤、聚合、排序三方面展开描述lucene的实现过程。
三、条件过滤
3.1 条件过滤支持的语法
(注:下面支持语法查询类型的文本摘取网上,看本文参考)
(1) 语法关键字 + - && || ! ( ) { } [ ] ^ " ~ * ? : 如果所要查询的查询词中本身包含关键字,则需要用进行转义
(2) 查询词(Term) Lucene 支持两种查询词,一种是单一查询词,如"hello",一种是词组(phrase),如"hello world"。
(3) 查询域(Field) 在查询语句中,可以指定从哪个域中寻找查询词,如果不指定,则从默认域中查找。 查询域和查询词之间用:分隔,如title:"Do it right"。 :仅对紧跟其后的查询词起作用,如果title:Do it right,则仅表示在title 中查询Do,而 it right 要在默认域中查询。
(4) 通配符查询(Wildcard) 支持两种通配符:?表示一个字符,表示多个字符。 通配符可以出现在查询词的中间或者末尾,如te?t,test,tet,但决不能出现在开始, 如test,?test。
(5) 模糊查询(Fuzzy) 模糊查询的算法是基于Levenshtein Distance,也即当两个词的差别小于某个比例的时 候,就算匹配,如roam~0.8,即表示差别小于0.2,相似度大于0.8 才算匹配。
(6) 临近查询(Proximity) 在词组后面跟随~10,表示词组中的多个词之间的距离之和不超过10,则满足查询。
(7) 区间查询(Range) 区间查询包含两种,一种是包含边界,用[A TO B]指定,一种是不包含边界,用{A TO B} 指定。 如date:[20020101 TO 20030101],当然区间查询不仅仅用于时间,如title:{Aida TO Carmen}
(8) 增加一个查询词的权重(Boost) 可以在查询词后面加^N 来设定此查询词的权重,默认是1,如果N 大于1,则说明此查询 词更重要,如果N 小于1,则说明此查询词更不重要。 如jakarta^4 apache,"jakarta apache"^4 "Apache Lucene" 332
(9) 布尔操作符 布尔操作符包括连接符,如AND,OR,和修饰符,如NOT,+,-。 默认状态下,空格被认为是OR 的关系, QueryParser.setDefaultOperator(Operator.AND)设置为空格为AND。 +表示一个查询语句是必须满足的(required),NOT 和-表示一个查询语句是不能满足的 (prohibited)。
(10) 组合 可以用括号,将查询语句进行组合,从
3.2 查询语的实现
上一小节介绍了lucene支持的查询语法,而为了实现这些语法,lucene底层实现了下面几类Query查询对应,我们接下来从源码实现上尝试进行分析,了解其实现过程。完整的介绍,请看源码的介绍文档,https://lucene.apache.org/core/550/core/org/apache/lucene/search/package-summary.html#scoring
TermQuery类
这个实现是支持词的等值查询,比如 name=xxx 之类的查询。
实现过程分析:这个非常直观,其实就是从对应的列的词典里面找到有没有这个term,如果有就返回这个term的倒排记录。
BooleanQuery类
这个实现是支持逻辑运算符(AND/OR/NOT),并可以支持这积累逻辑运算符的任意组合。不管这3个逻辑运算符号多复杂,都可以通过优先级(NOT > AND > OR) 进行分析,形成一颗简单直观的树形结构进行描述。
举例: a or b and c not e(a b c e 是子条件)可以形成一个Query树,看下图
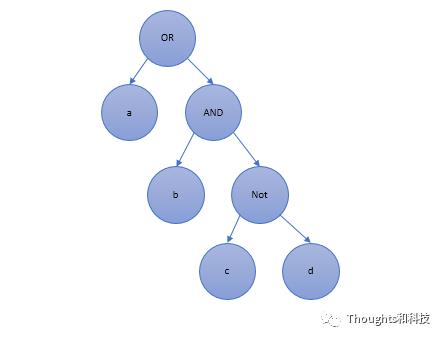
既然形成了一个树形的结构,我们的问题就来了,里面的AND OR NOT在对数据进行合并的时候,实现过程是如何的。也就是数据是怎么进行归并的?
归纳起来,无论Query树多么复杂,最后归类于下面三类查询,因为Query树是自下向上进行处理返回结果的,任何一个节点处理的也就是AND OR NOT中的一种逻辑。
AND
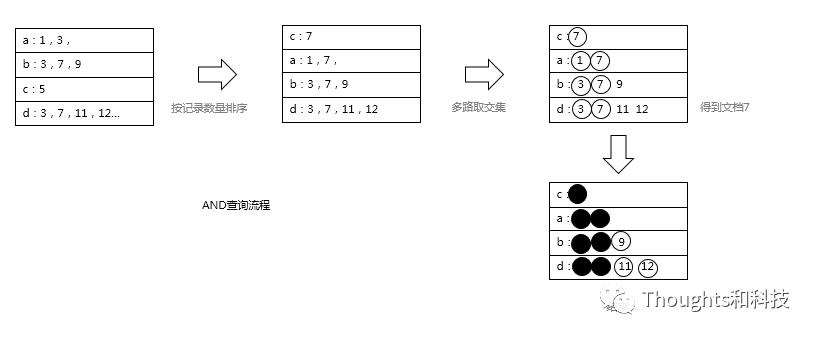
多路做交集,如果我们需要过滤条件 a AND b AND c,那么在lucene的实现过程为:
查询分别满足 a 、b、c的三个倒排(保存在Scorer对象里面)。
按a 、b、c三个条件的Scorer按满足的记录数从小到大排序(这个很重要)。
先从最少满足记录数的条件拿到一个docid,按顺序查询其它条件,看是否有该docid,如果不满足,更新docid并回到流程3。
OR
多路做归并,这个实现也AND差别较大,如果我们需要过滤条件 a OR b OR c,那么在lucene的实现过程为:
从最小文档号开始,每次设置一个长度为2048的窗口,比如现在min=100,那么设置的window为[ 100, 100+2048]
遍历条件a 、b、c的scorer倒排记录,把条件记录docid在window内[ 100, 100+2048],那么写入一个bit(2048个bit)位置。直到scorer的docid都大于[2048+10]则结束。
遍历bit位,收集满足的记录。如果scorer还有记录,清空bit位,回到2继续。
NOT
NOT逻辑是很直观的,它本质是一个AND操作,然后取反。
Phrase类
PhraseQuery
用于短语查询,比如输入“宝宝 加油”,要求出现的文本包括" 宝宝 加油"的词序列,中间可以穿插一些单词。适用于我们希望目标文档有一些相关的单词序列。 实现原理:
本质上,PhraseQuery还是需要分割成几个TermQuery,对于满足的记录,查询记录的词向量(TermVector)进行判断是否满足,这里不赘述。 MultiPhraseQuery
封装了多个PhraseQuery。 SpanNearQuery
类似PhraseQuery,但能够明确定义词之间的差距,比如可以控制 "宝宝" "加油" 这2个词之间包含多少个单词间隔。
TermRangeQuery类
对单词按ASCII的值进行字典排序,查找一个区间,比如希望所有c开头到d开头之间的词都满足。特别说明对于中文查询并不合适!
实现过程是,根据词典(按字典排序),获取到所有满足的单词,然后构造一个BooleanQuery树,底层通过OR关系连接每个TermQuery。如果查询的单词范围很广,那么对查询消耗更大。
NumericRangeQuery类
这个是数字范围查询,也是我们经常使用到的重要功能。我们有必要分析一下数字范围查询的索引原理。 现在回想一下TermRangeQuery,这个查询是根据词典排序进行查询。词典类似下图:
abc
abcd
abefgh
abefh
ba
bb那么如果我们词典按这个排序,由于单词查找按字典顺序查找,而存储的单词也按字典顺序在字典树表示起来,因此TermRange的查找会非常方便、快速。比如需要查找区间 [abcd TO ba]。
但是,有些情况下,这样的查找在某些场景下会非常糟糕:
假如我们需要查找 [a To z]之间的所有单词,那么假设有10w的单词,那么在查询过程中我们需要遍历这10w个单词的倒排列表,进行归并。试想一下10w路的倒排列表进行归并,这里面的肯定会非常庞大。
不过,通常情况下在现实场景中,TermRange的范围不会那么大,因为我们人类的词汇量还是收敛在一个较小的值里面的。很不幸,如果把这种RangeQuery的方法推广到数字类型,我们就不行了,因为32bit可以表达40亿个数字,64bit就是40亿的平方。假如我们有上亿个不同的数字值(比如精确到纳秒的时间范围)。
lucene通过 空间换时间 的办法解决了这个问题。请看下图
从这里构建的索引可以看,假如按每8bit进行一个划分,一个32bit的数字会划分出最多4个数字,分别在trie tree 1 到 trie tree 4 之间。那么数字范围怎么查询呢?举一个非常容易明白的例子,假如我们需要查询范围在[0x 01000000,0x 02000000) 之间的值,转化为十进制,我们知道这个区间的数字范围非常大,有 2的24次方 那么多。那么在lucene里面,它首先提取值[0x 01] 在trie tree 1 查找倒排,直接返回即可。不需要进行任何多路归并。这个做法是和TermRange不一样的地方。
PrefixQuery WildcardQuery,RegexpQuery类
这几个分别是前缀匹配,*匹配,正则匹配这几类,这几类是构建一个字符串的匹配自动机,然后对字典进行扫描。
FuzzyQuery
模糊查询,这里的模糊指的是判断2个词的“ Levenshtein distance.”(编辑距离)在一定范围之内,查出这些相似的Term 值。
四、聚合
4.1.什么是聚合?
引用百度百科:”一种查询(如 SQL 语句),它通过包含一个聚合函数(如 Sum 或 Avg )来汇总来自多个行的信息。” 其实很好理解,就是先根据查询条件查询满足符合条件的记录,对这些记录进行聚合计算,比如max/min/sum/avg/分组等。其最终目标就是求出一小部分值。
4.2 lucene做聚合的过程
lucene每个记录(document)是按列存储的,如果我们要做聚合查询,得到满足的doc id列表后,我们就需要查询出满足条件文档的对应值进行分析,如:是不是最大值、加到累计总值进行取平均等的聚合查询需求。lucene的当前版本已经支持DocValue的列式存储,并配合压缩、linux mmap技术,我们可以快速的读取到某个文档某个列的值。
五、 排序
通常情况下,我们的查询场景一般是按条件查询记录,并按某个顺序排序,返回前面的记录,如前100条。
在lucene的查询里面,归纳可得到分2类排序返回:
带条数限制的查询。如返回前面 100条,那么在lucene里面的实现就很简单。构建一个top 100的优先队列,把排序值大的值保留下来即可。但这种case需要用户自己考虑翻页情况下可能出现数据重复的情况出现。因为从原理上面讲,lucene无法保证在一些场景下(排序值相同或者数据有变化),2次查询返回的结果是有差异的。
不带条数限制的查询。这种就没办法了,只能维护所有记录的排序值,对满足的记录进行全量排序。因此需要慎用。
通过上面的基本原理,我们可以得出影响排序性能的因素:
是否有返回条数的限制。没有限制的情况尽量避免。
翻页的深度,如果我们需要翻页到1000条后,那么lucene需要维护1000大小的优先队列。
查询排序值的效率。通过lucene的DocValue列式存储,可以加快对数据的查找,减少无谓的IO消耗。
六、总结
本文主要结合lucene5.5.0版本对其查询的实现(过滤、聚合、排序)进行分析,从原理上描述其实现过程,为我们合理利用提供理论支撑。实际上,我们也发现lucene底层的实现其实还是有优化的空间,在一些case下需要灵活调整。
后记,如有不对,请指正 xib.cao@qq.com
以上是关于探秘ElasticSearch -lucene引擎搜索分析的主要内容,如果未能解决你的问题,请参考以下文章