搜索之路:Elasticsearch的诞生
Posted 码农翻身
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了搜索之路:Elasticsearch的诞生相关的知识,希望对你有一定的参考价值。
经过三年的历练,张大胖已经成为了一个利用Lucene这个著名的开源软件做搜索的高手,各种细节知识和最佳实践尽在掌握。
(张大胖的学搜索的历程参见上一篇文章:《》)
随着互联网应用的爆炸式增长,搜索变成了网站的一个常见需求,各个网站都想搜索产品,搜索帖子,搜索服务......张大胖的“业务”变得十分繁忙,经常在业余时间给人做Lucene的咨询,赚了不少外快。
但是张大胖也敏锐地觉察到了两个问题:
1. Lucene做搜索很强大,但是API用起来太“低级”,很多人抱怨:我就想搜索一下我的产品描述,现在还得理解什么“Directory”,"Analyzer","IndexWriter",实在是太复杂了!
2. 互联网的数据是海量的,仅仅是单机存储索引是远远不够的。
俗话说:“软件开发中遇到的所有问题,都可以通过增加一层抽象而得以解决”。 张大胖觉得,是时候对Lucene做一个抽象了。
保险起见,张大胖拉了大神Bill来做顾问,帮自己设计。
这个新的抽象层应该对外提供一个什么样的API呢?
很多时候,Web开发面对的都是领域模型,比如User,Product, Blog,Account之类。用户想做的无非就是搜索产品的描述, 搜索Blog的标题,内容等等。
张大胖说:“如果能围绕着领域模型的概念进行搜索的各种操作就好了,这样简单而直接,如同CRUD。”
Bill 提示到:“Web时代了,程序员都喜欢采用RESTful的方式来描述一个Web资源, 对于搜索而言,完全可以借鉴一下嘛!”
张大胖眼前一亮: “要不这样?”
/coolspace/blog/1001 : 表示一个编号为1001的博客
/coolspace/user/u3876:表示一个ID为u3876的用户
/coolspace表示一个“索引库”
/blog ,/user 表示“索引的类型”(可以理解为编程中的领域模型)。 1001, u3876表示数据的ID
格式是/<index>/<type>/<id>
如果和关系数据库做个类比的话:
索引库<--->数据库
索引的类型 <--->数据库的表
Bill说:“这样挺好的,用户看到的就是领域模型, 当用户想去操作时候,用HTTP的GET, PUT等操作就好了,交互的数据可以使用JSON这个简单的格式。”
张大胖开始定义基本的操作。
(1) 把文档加入索引库
例如:把一个blog的“文档”加入索引库,这个文档的数据是JSON格式,其中的每个字段将来都可以被搜索:
PUT /coolspace/blog/1001
{
"title" : "xxxxxxx",
"content" : "xxxxxxxxxxxx",
"author" : "xxxxx",
"create_date": "xxxxxx"
...
}
(2)把一个blog文档删除,从此就再也搜索不到了:
DELETE /coolspace/blog/1001
(3) 用户搜索
用户想搜索的时候也很简单,发起一个这样的请求就行:
GET /coolspace/blog/_search
但是如何表达查询的具体需求呢,这时候必须得定义一个规范了,例如:想查询一个内容字段(content)包含“java"的 blog。
GET /coolspace/blog/_search
{
"query" : {
"match" : {
"content" : "java"
}
}
}
这个query下面可以增加更加复杂的条件,表示用户的查询需求,反正是JSON格式,可以非常灵活。
返回值也是JSON, 这里就不再展示了。
这个抽象层是以HTTP+JSON来表示的, 和具体的编程语言无关,不管是Java, 还是Python,Ruby,只要能发起HTTP调用,就可以使用。
通过这样一个抽象层, Lucene那些复杂的API全部被隐藏到了海平面以下。
对于程序员来说,使用HTTP+JSON是非常自然的事情,好用就是最大的生产力。
到目前为止,进展还算顺利,接下来要考虑的就是如何存储海量的索引数据。
张大胖说: “这个简单,如果索引太大,我们把它切割一下,分成一片一片的,存储到各个机器上不就得了?”
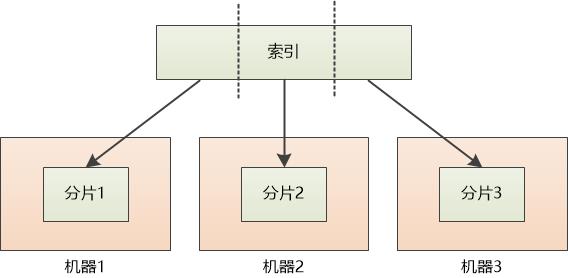
Bill问道: “想得美! 你分片以后,用户去保存索引的时候,还有搜索索引数据的时候,到哪个机器上去取?”
张大胖说:“这个简单,首先我们保存每个分片和机器之间的对应关系, 嗯,我觉得叫node显得更专业。”
分片1 :node1
分片2 :node2
分片3 :node3
“分片在英文中叫做shard。 ” Bill 友情提示。
“好的, 然后可以用余数算法来确定一个‘文档’到底保存在哪个shard中。” 虽然张大胖觉得这个词看起来不爽,还是开始使用了
shard 编号 = hash(文档的ID) % shard 总数
“这样对于任意一个文档,对它的ID做hash计算,然后对总分片数量求余, 就可以得到shard的编号,然后就可以找到对应的机器了。 ” 张大胖觉得自己的这个算法又简单,效率又高,洋洋得意。
Bill觉得这两年张大胖进步不小,开始使用算法来解决问题了, 他问道:“如果用户想增加shard数该怎么处理呢? 这个余数算法就会出问题啊 !”
比如原来shard 总数是3, hash值是100, shard编号 = 100 % 3 = 1
假设用户又增加了两台机器,shard总数变成了5, 此时 shard 编号 = 100 % 5 = 0 , 如果去0号机器上去找索引,肯定是找不到的。
张大胖挠挠头:“要不采用分布式一致性算法, 嗯,它会减少出错的情况,还是无法避免,这该怎办?”
Bill建议:“要不这样,我们可以立下一个规矩: 用户在创建索引库的时候,必须要指定shard数量,并且一旦指定,就不能更改了!”
PUT /coolspace
{
"settings" : {
"number_of_shards" : 3
}
}
虽然对用户来说有点不爽, 但余数算法的高效和简单确实太吸引人了,张大胖表示同意。
“索引数据分布了,如果某个节点坏掉了,数据就会丢失,我们得做个备份才行。” 张大胖的思考很深入。
“对, 我们可以用新的node 来做replica,也可以为了节省空间, 复用现有的node来做replica。为了做区分,可以把之前的分片叫做主分片,primary shard。” Bill英文就是好。
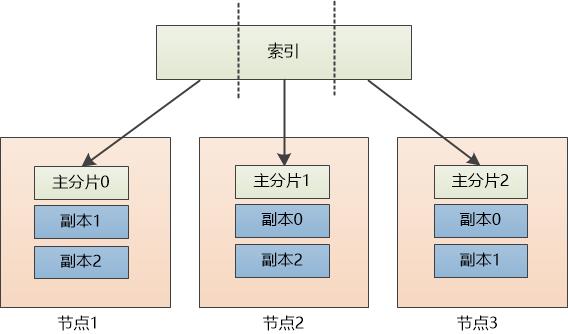
(此处的设置为:每个主分片有两个副本)
PUT /coolspace/_settings
{
"number_of_replicas" : 2
}
虽然主分片的数目在创建“索引库”的时候已经确定,但是副本的数目是可以任意增减的,这依赖于硬件的情况:性能和数量。
“现在每个主分片都有两个副本, 如果某个节点挂了也不怕,比如节点1挂了,我们可以位于节点3上的副本0提升为 主分片0, 只不过每个主分片的副本数不够两个了。” 张大胖说道。
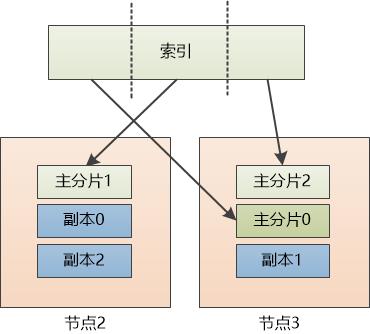
Bill 满不在乎地说: “没事,等到节点1启动后,还可以恢复副本。”
Bill和张大胖立刻意识到,他们建立了一个集群, 这个集群中可以包含若干node , 有数据的备份,能实现高可用性。
但是另外一个问题马上就出现了:对于客户端来说,通过哪个node来读写‘文档’呢?
比如说用户要把一个'文档'加入索引库: PUT /coolspace/blog/1001, 该如何处理?
Bill说:“这样吧,我们可以让请求发送到集群的任意一个节点,每个节点都具备处理任何请求的能力。”
张大胖说:“具体怎么做呢? ”
Bill 写下了处理过程:
(1)假设用户把请求发给了节点1
(2)系统通过余数算法得知这个'文档'应该属于主分片2,于是请求被转发到保存该主分片的节点3
(3)系统把文档保存在节点3的主分片2中,然后将请求转发至其他两个保存副本的节点。副本保存成功以后,节点3会得到通知,然后通知节点1, 节点1再通知用户。
“如果是做查询呢? 比如说用户查询一个文档: GET /coolspace/blog/1001, 该如何处理?” 张大胖问道。
“同样,查询的请求也可以分发到任意一个节点,然后该节点可以找到主分片或者任意一个副本,返回即可。 ”
(1) 请求被发给了节点1
(2)节点1计算出该数据属于主分片2,这时候,有三个选择,分别是位于节点1的副本2, 节点2的副本2,节点3的主分片2, 假设节点1为了负载均衡,采用轮询的方式,选中了节点2,把请求转发。
(3) 节点2把数据返回给节点1, 节点1 最后返回给客户端。
“这个方式比较灵活,但是要求各个节点之间得能互通有无才行!” 张大胖说道。
“不仅如此,对于一个集群来说,还得有一个主节点(master node),这个主节点在处理数据请求上和其他节点是平等的,但是它还有更重要的工作,需要维护整个集群的状态,增加移除节点,创建/删除索引库,维护主分片和集群的关系等等。”
“那如果这个主节点挂了呢? ” 张大胖追问。
“那只好从剩下的节点中重新选举喽!”
“哎呀,这就涉及到分布式系统的各种问题了,什么一致性,脑裂,太难了!” 张大胖开始打退堂鼓。
“我们只是选取一个Master, 要简单得多,你可以看看一个叫做Bully的算法, 改进一下应该就可以用了。 ”
开发分布式系统的难度要远远大于一个单机系统,半年以后,这个被Bill命名为Elasticsearch的系统才发布了第一个版本。
由于它屏蔽了很多Lucene的细节,又支持海量索引的存储,很快就大受欢迎。
当然, Elasticsearch不是Bill和张大胖创造的,这里才是其传奇的历史:(来源:《Elasticsearch权威指南》)
许多年前,一个刚结婚的名叫 Shay Banon 的失业开发者,跟着他的妻子去了伦敦,他的妻子在那里学习厨师。 在寻找一个赚钱的工作的时候,为了给他的妻子做一个食谱搜索引擎,他开始使用 Lucene 的一个早期版本。
直接使用 Lucene 是很难的,因此 Shay 开始做一个抽象层,Java 开发者使用它可以很简单的给他们的程序添加搜索功能。 他发布了他的第一个开源项目 Compass。
后来 Shay 获得了一份工作,主要是高性能,分布式环境下的内存数据网格。这个对于高性能,实时,分布式搜索引擎的需求尤为突出, 他决定重写 Compass,把它变为一个独立的服务并取名 Elasticsearch。
第一个公开版本在2010年2月发布,从此以后,Elasticsearch 已经成为了 Github 上最活跃的项目之一,他拥有超过300名 contributors(目前736名 contributors )。 一家公司已经开始围绕 Elasticsearch 提供商业服务,并开发新的特性,但是,Elasticsearch 将永远开源并对所有人可用。
据说,Shay 的妻子还在等着她的食谱搜索引擎…
相关阅读:
(完)
码农翻身,用故事讲解技术本质, 更多精彩文章,请移步《》
以上是关于搜索之路:Elasticsearch的诞生的主要内容,如果未能解决你的问题,请参考以下文章
ElasticSearch探索之路分布式原理:分布式路由存储搜索原理
ElasticSearch探索之路集群与分片:选举动态更新近实时搜索事务日志段合并
ElasticSearch探索之路集群与分片:选举动态更新近实时搜索事务日志段合并
ElasticSearch探索之路集群与分片:选举动态更新近实时搜索事务日志段合并
ElasticSearch学习问题记录——Invalid shift value in prefixCoded bytes (is encoded value really an INT?)(代码片段