陈曦:性能与稳定并存 Elasticsearch调优实践
Posted 云加社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了陈曦:性能与稳定并存 Elasticsearch调优实践相关的知识,希望对你有一定的参考价值。
本文整理自作者在云加社区线下沙龙活动中的精彩分享,主题内容Elassticsearch调优实践。
以下为分享内容:
我今天分享的是Elassticsearch调优实践,首先自我介绍一下,我资历比较浅,我是腾讯TEG基础架构部后台开发工程师,虽然我不是项目经理,但是我们项目负责人就在下面,我还是很有压力的。
今天分享一下使用ES的经验以及我们对ES内核的改动,在此之前介绍一下ES的功能,首先来看ES的基础概念,这部分介绍一下Elastic Stack。在场有多少用过ES的?还是挺多的,ES首先是一个搜索引擎,我总结了一下特点,高性能,它是通过Lucene实现搜索引擎,在此之上增加了分布式集群。可扩展,系统支持多分片存储,高并发写入、查询。第二是高可靠。第三是易于管理,节点可以弹性伸缩。第四是易使用,具有很强大的综合分析能力,比如说分桶聚合,桶内的运算都可以支持,甚至通过脚本进行复杂的运算。
Elastic Stack提供数据采集、清洗、存储、可视化完整解决方案。Beats负责数据采集,Logstash负责数据清洗转发,ES本身就是存储和搜索,第四个Kibana就是把你的数据作可视化展示,是比较完整的工具链。ES有比较广泛的应用领域,对内部和外部系统都有广泛的使用。主要有日志分析是一个场景,再有数据分析统计,还有搜索,全文检索都可以做的。功能比较强大。
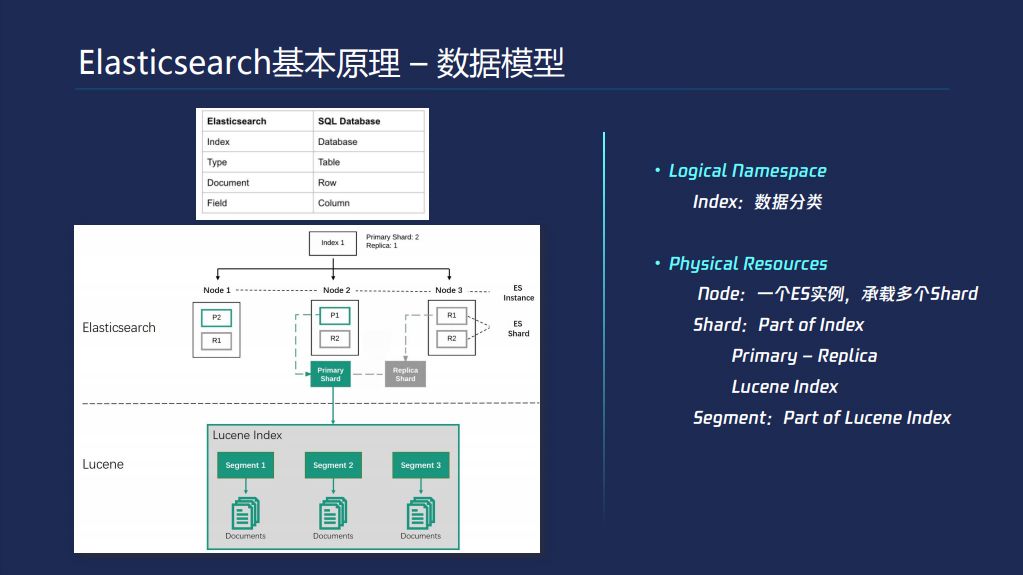
我们再来看一下Elassticsearch的基础概念-数据模型,第一张图把ES数据模型概念和传统数据库做了对比。ES本身是schema less的,有比较特殊的字段需要通过Mapping设置一下,每个数据点就是一行数据Document,ES数据分类通过Index这层完成的。这是逻辑的概念,我们再来看物理实际存储的架构,首先分为两层,一个是ES,下面是Lucene,一个ES集群有多个node组成的。一个ES实例会承载一些Shard,多个shard会落到不同机器上面,P1和P2是两个不同的Shard,并且shard有主从的概念,对于ES每个Shard落地下来是一个Lucene Index。
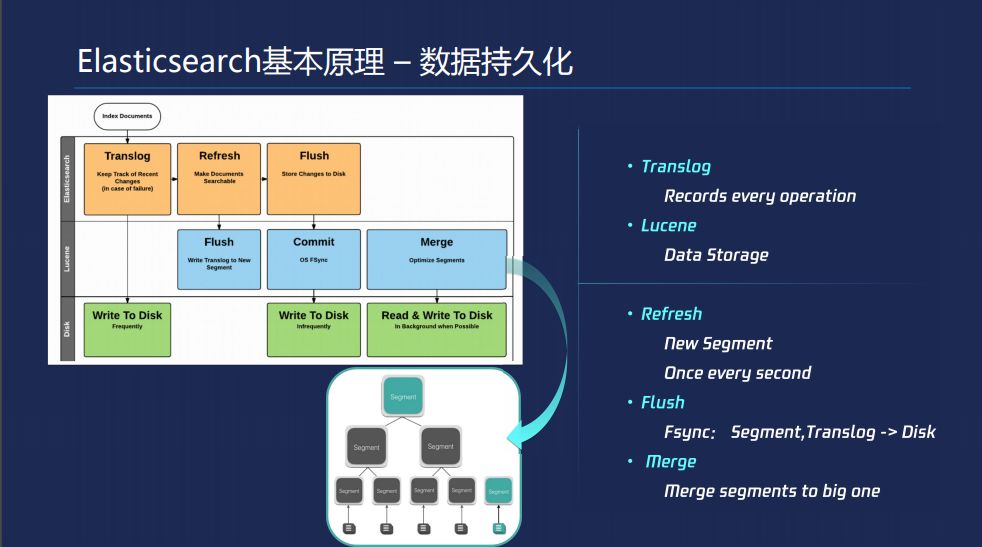
Lucene基于节点宕掉的考虑会写Translog,每次写入会产生这个Translog,对你的每次操作都会产生Disk的IO,对Lucene有三个不同的过程,第一个是Refresh,先缓存内存里面,过一段时间,默认情况是每秒一次,把它整理成一个Lucene的Segment,当一秒钟一次刷成Refresh的时候数据就可以搜索了。第二就是Flush,这个时候会把Lucene内存结构实际刷盘下去。再有一个就是第三个过程是Merge,把一些小的segment不断合成大的segment。
第二部分就是Elassticsearch的调优,通用的方案,这个地方列了几个点。有没有同学分享一下拿ES存储的什么东西,跟大家分享一下你们的方案。

ES的调优第二部分主要是从三个层面分享,存储成本、集群稳定性和集群性能。存储成本是字段存储选项和为字符串字段选择合适的格式。
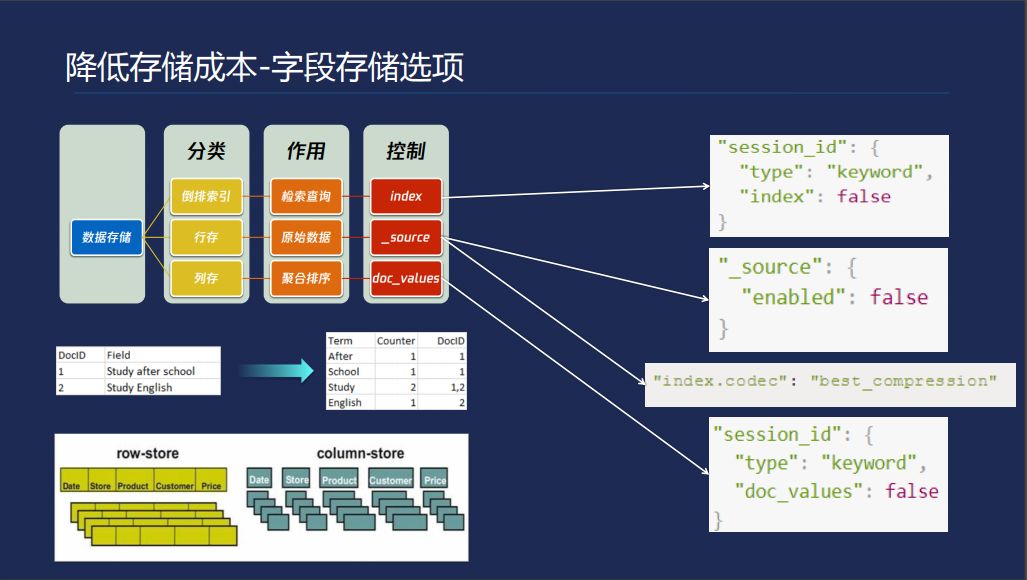
首先看字段存储选项,ES里面的数据有三份数据,倒排索引、行存和列存。行存是我们写入ES的数据,把整个结构体存下来,以便于你日后拉取数据。列存通常情况下用于聚合和排序,这个是把你写入的每个字段按列存储,这样方便快速拿到一列的数据。对于这三种存储我们其实并不是对于很多的使用场景中都用得到,比如说ES可以存储数据,我存很多数据的监控。最后想查某个IP的CPU曲线,我只需要拿到数据看曲线就可以了,这种场景可以把cpu字段的index关掉。比如说我的数据同样是统计分析的场景,我之后只是想拿这个数据看曲线,其是拿列存就可以了,原始数据没必要保存。打开最佳压缩后,经过我们发现最优的行存的成本能降40%。
日志场景之类的,要保存日志的话,有一个docvalues,我存的日志就想看文本,或者我存的评论,我对于字段聚合的要求不是特别高,我只是想放进去,我要的时候把整个结构体拿出来。

降低成本的第二方面:字符串。一个是text,一个是keywork。text做分词,然后对每个词都可以建倒排索引,拿一个词可以搜到一整段话。如果仅仅是想把这个文本存进去并且取出来的话,后面都是可以去掉的。
第二种存储格式就是keywork,你可以模糊匹配,但不能拿一个词搜索整段话,由于它不需要做分词,所以速度比较高。
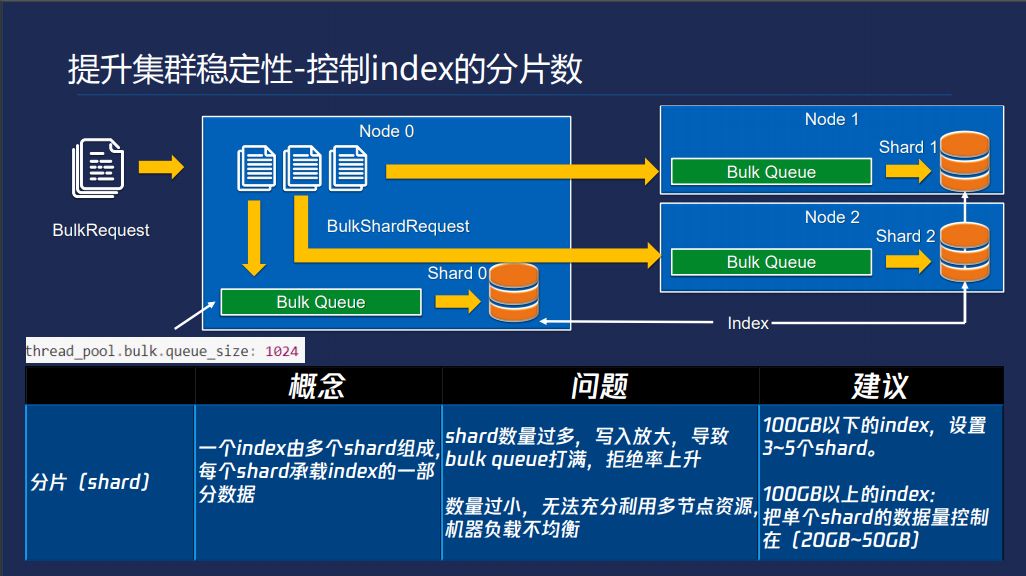
集群的稳定性,要控制index的分片数,一个index是多个shard组成的,这个图中一个index有三个shard,分布不同节点上,一个请求写几百个几千个文档在里面,当你的请求到达ES某个节点的时候会计算对于几千个文档里面分别属于哪个shard,以shard为粒度分组。然后放到BulkQueue存储,BulkQueue的默认值是100,shard数量过大的问题这个Queue就很容易被打满。但是shard数过小的话,就无法充分利用节点资源,我们给的建议并不适用于每个场景,具体看业务,100GB以下的index设置3-5个shard。大的Index单shard不超过50GB。
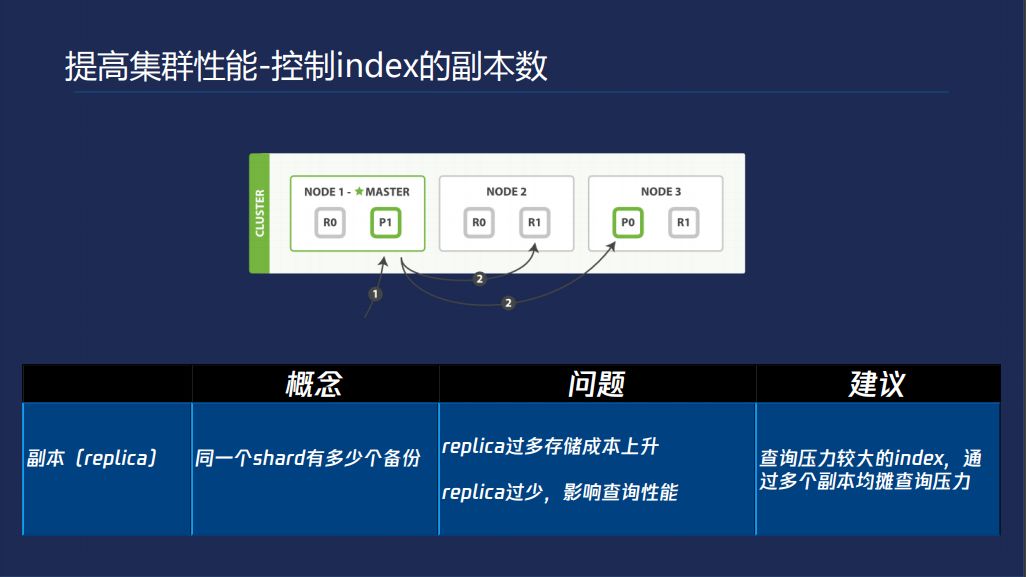
提高集群性嫩控制index的副本数,每个shard可以指定多个副本,这个查询时,找到shard所在的节点,既可以主shard也可以从shard。这是一种很常见的做法。
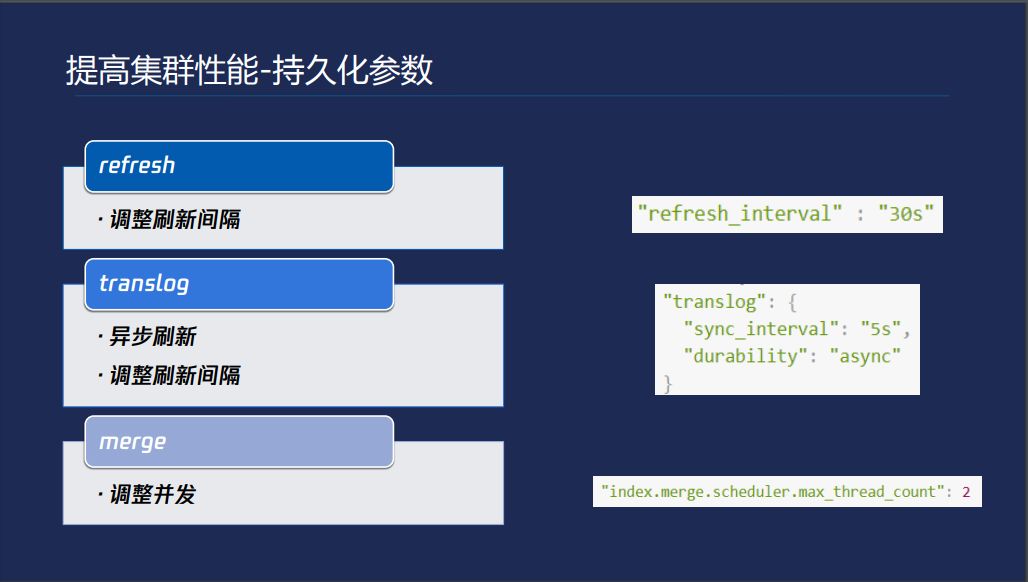
提高集群性能的持久化参数,就是我们之前讲了,默认情况下是ES每1秒产生一个新的segment,如果我们对数据的可见性要求不是特别大的话,可以把这个放大一点。默认情况下translog是每写一次就刷盘一次,可以改成异步刷新。Merge策略,底层的不断把小的合并成大的,但是默认情况下ES默认配置跟你这个节点CPU个数是相关的,CPU个数越大,占的资源就越多,对于有几十个CPU的要控制一下,避免占用更多的资源。

还有提高性能的第三方面是写入方式。批量写入,我们通常推荐一般场景下在1000-10000之间都是可以的,可以根据业务的不同进行调整。写入的时候不指定ID,你如果指定ID,Lucene首先会考虑你这个ID是否已经存在,如果有的话,就把原来的删掉,把现在的加进去,你每次都是写入和查询。若不指定ID,ES通过算法保证产生一个唯一的ID,就免去了前面的查询,提高了集群效率。
另外就是routing,避免小的查询过去轮询很多shard,显著降低调度开销,提升查询效率。还有一个是让index压力分摊。最后一个是综合考虑index上的shard的数量,调度开销过大,可能会产生过程中有拒绝。
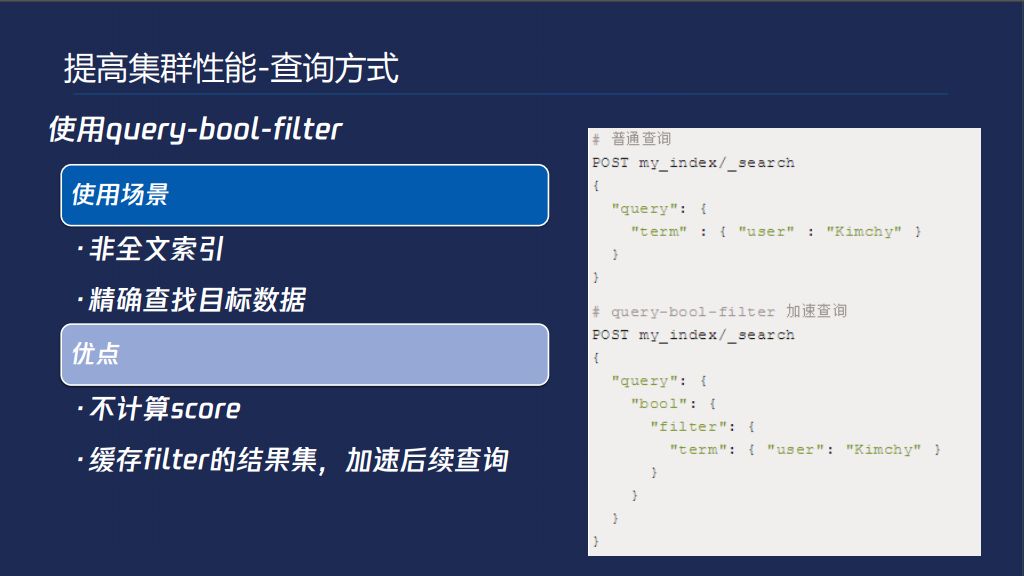
提高集群性能的查询方式,默认查询是ES,会有打分逻辑,把你数据搜到以后,根据数据元信息计算分数出来,根据这个分数做一个排序,就是你这个数据和你的查询条件的相关性,类似于推荐的功能,如果说我们对于想要查询的数据,我们认为相关信息都是一样的,我只是精确的查到某条信息而已,通过下面的方式避免了打分的过程,提高了效率,Filter的结果集是可以做缓存的,以后再使用就可以利用了。

最后一部分分享一下我们在ES内核的改进和我们增加的功能,主要是四个方面,一个是运管平台,每个系统都有。ES优化方面有三个,降低索引成本,集群稳定性和集群性能。存储成本,一个是内存优化、冷热分离降低磁盘。提升集群稳定性。最后一个是提高集群的性能,做查询计划的优化,我们的优化不仅于此。
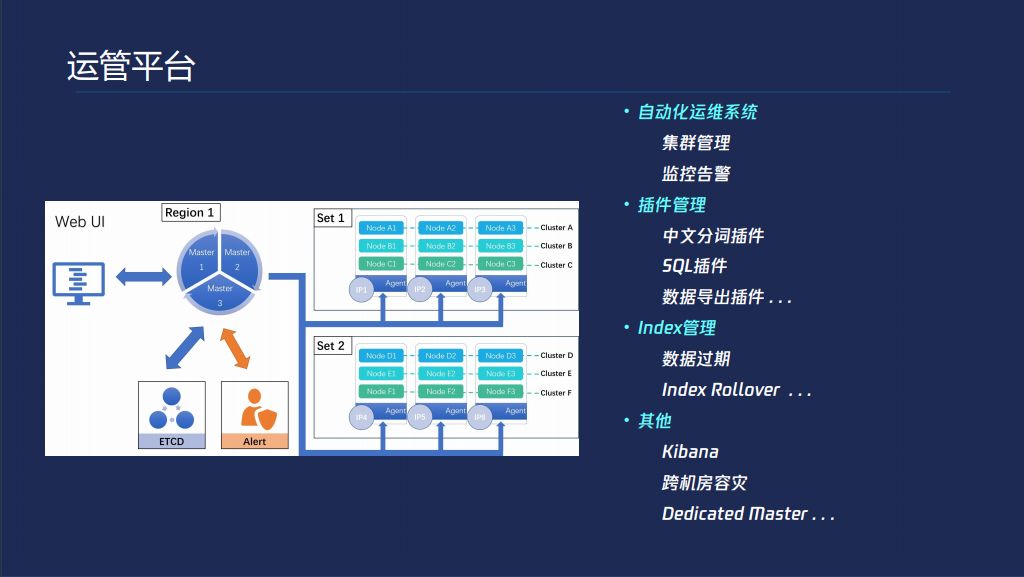
运管平台,各个业务的运管平台都差不多,首先有一个自动化的系统,提供集群的管理,官方的升级方案不允许新建index,我们是支持的,你的集群在异常情况下,我们可以支持你升级。
插件管理,我们本身可以预装一些插件。Index管理,数据过期,index Rollover就是说我可以做一个逻辑表的概念,直接往这个逻辑表里面每天写就可以了,我会自动按照一定时间间隔创建index,你不需要关心里面有多少index。还有Kibana、跨机房容灾、Dedicated Master,提升集群的稳定性。
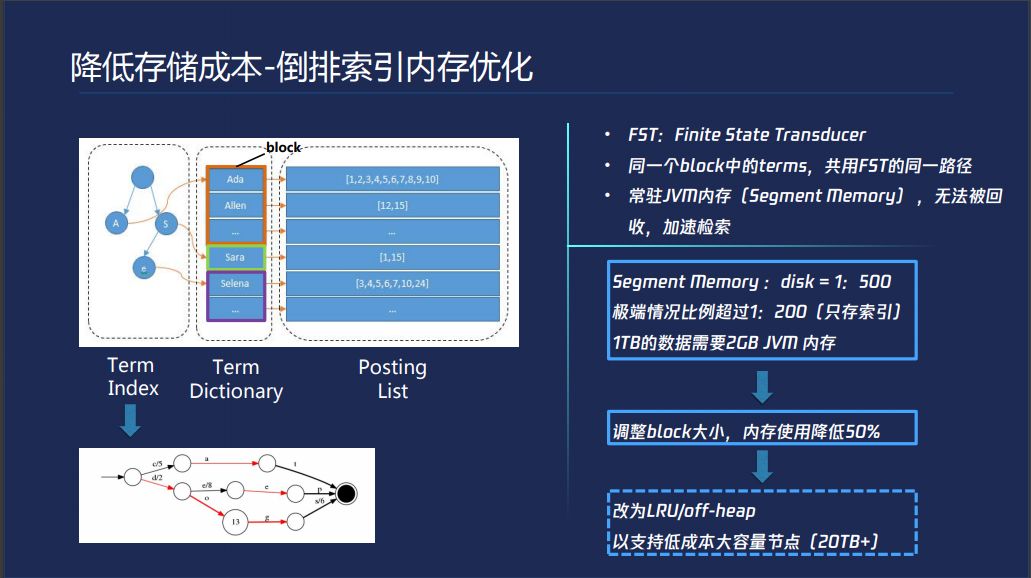
ES存储成本的倒排索引内存优化,倒排索引有一个词典和一个倒排表,ES为了加速查询过程,把词典划分成一个一个的block,前缀相同的词可以放到block里面,前缀相同的前缀树指向block,在这个小范围内一个个匹配词典就可以了,这样可以快速加大性能,这个东西快是因为常驻内存。FST虽然做了前缀和后缀的收敛,它是常驻在JVM里面的。我们为了利用压缩技术,通常JVM的配置在32G以下,对比较大的节点,Disk比较大的情况下,普通场景1T数据需要2GB的内存,有很多人拿JVM索引,这个地方就更严重了。
我们目前初期方案调整了这个大小,内存使用率降低了50%,我们现在正在考虑大容量的节点,降低使用成本,我们一个节点会大20个T这种,这种情况下,你的JVM就装不下了。LRU,我只存一部分,其他的放到磁盘,或者我们把这个东西拿到堆外,这是我们后面会做的事情,现在还在调研这块。
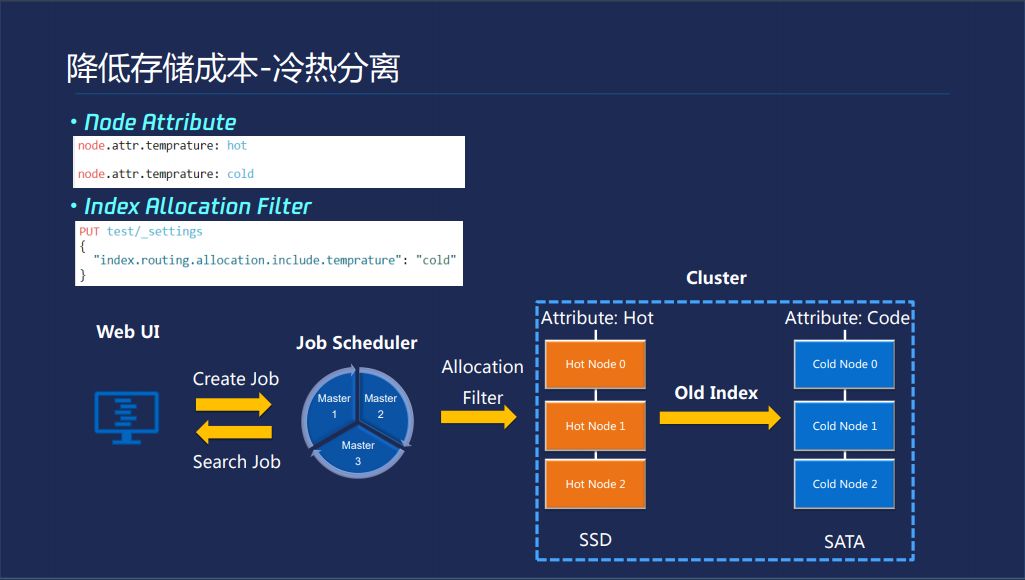
降低存储成本的另一个方法就是冷热分离,ES本身可以对于每个NODE加一些属性在里面,你通过ES的一个命令可以强制把一个表所有数据搬迁到指定的一个属性的节点上面,所以我们在机器上架的时候可以同时加上两个属性,用户可以在前面WEB界面配置哪类的index多久之后迁移到冷机器,降低你的使用成本。我们后台就有一个调度器,会发送命令,从而降低你的使用成本。
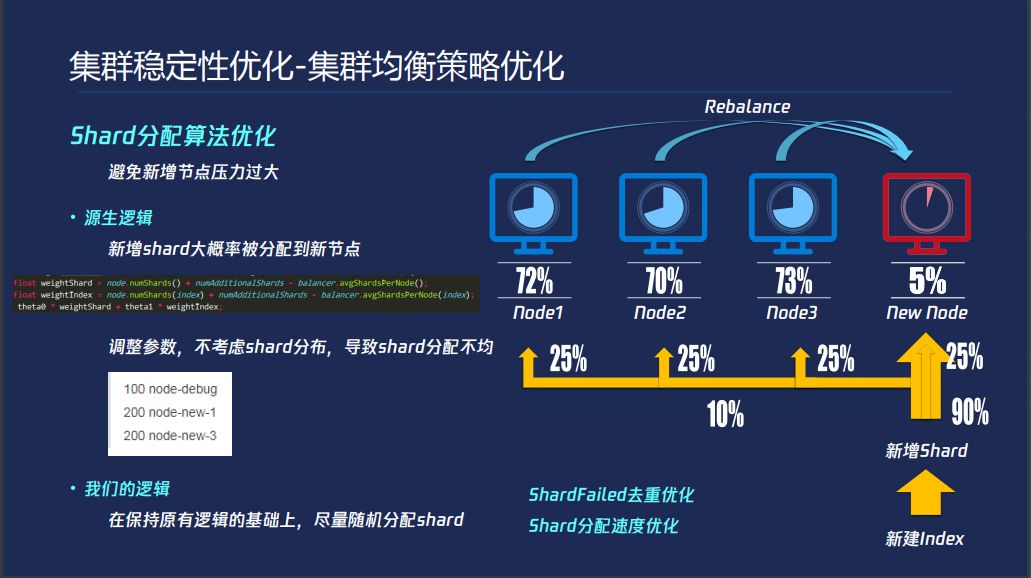
稳定性优化,集群均衡策略,通常情况下我们随着业务的增长,比如一开始购买了三个节点,业务增长上来之后,你的磁盘使用率也好,慢慢增长,增长一定情况下,70-80%的时候要做扩容,这里讲的是横向扩容,增加一个新的节点,之后ES本身的Rebalance逻辑会把大容量节点数据开始往小的节点上搬,这个没有问题,Rebalance通过参数控制可以控制速度,问题在哪呢?问题是你此时新建index,默认情况下,新增了shard绝大部分都会放在新的节点上,ES认为这些磁盘使用率比较高,默认把大量的Shard放在小的节点上面,新增的shard读写压力比较大,这种情况下就造成单点过热的问题,这个默认就是跟ES算法有关,ES算法里面会综合考虑当前节点上有多少Shard以及index的shard当前的集群分布,最后的结果,因为你新增的index在各个节点上没有shard存在,所以主要考虑了每个节点所有shard的分布,这样就会把新增的shard放在新增节点上面,虽然上面有两个数可以调的,但是这样依然不能解决问题,是因为底层的原数据的存储以及迭代规则有关系,就很容易造成有些节点分配的shard过多有些节点分配的shard过少。
这个主要解决的问题这个节点宕掉会产生很多shard failed的请求,这主要在大集群,比如说你有几十个节点,分配过会多出现这样的问题,我们把这个地方优化了一下,就是把重复的SHARDFailed请求的全部去掉,可以大大降低MASTER的压力。在大集群中发现新建一个INDEX很慢,这是可优化的地方。
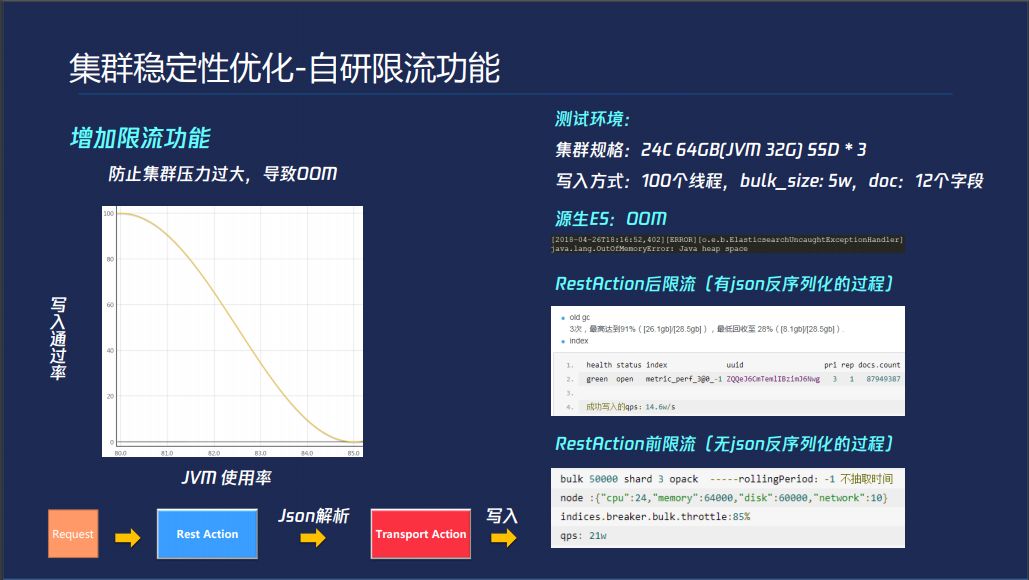
集群稳定性优化的自研限流功能,ES本身对于JVM判断不准,会导入写入量大的情况下会导致OOM,我们在解析之前判定,做了一个曲线可以做到限流的功能。大的查询优化,查询的时候有可能查询到多个子查询,查询到第五次的时候会把你查询的所有结果做一个缓存。我们把这个地方也做了优化,根据你查询到数据量进行预估,超过一定量就不做缓存了。
我们的产品一个是ES,一个是CTSDB,我今天讲的是这篇文章提炼出来的点,这个会更系统,CTSDB是我们的时序数据库,谢谢大家。
Q&A:
Q:我们公司在用ES的时候有一个场景发生了高负载,有ES节点挂,后面做恢复的时候启不起来,是内存的问题,内存只占60%多,但是就是启起不来。
A:我们往往碰到一个问题,一个节点挂掉之后难以加入到集群,有两个问题,一个在于TCP半连接队列的问题,一个是ShardFailed的问题。
Q:我主要想问一下ES有做日志分析,这个日志分析主要是做什么的?
A:ES现在使用50%-60%场景是日志分析,可以扫描所有的本地日志文件,上传到ES,有解析功能,把一段文字转化成一个结构,存储起来,然后你可以各种查询,然后可视化,做监控告警。
Q:我们只是做单纯的察看,你的日志分析是类似数据挖掘的吗?
A:我们这边因为还在跟官方谈,后面会接入这些能力。
Q:像这个产品,需求量特别大,今天有500G,过期日志怎么处理?
A:通过冷热分离,单副本存储,磁盘是三副本。
Q:你们有做权限控制吗?
A:我们有自研的一套。
陈曦,腾讯高级工程师,腾讯Elasticsearch Service 、CTSDB后台开发者。多年云服务后台支撑系统研发经验,在日志分析、数据搜索、时序数据库研发、大型Elasticsearch集群调优等方面有较为丰富的实践经验。
推荐阅读:
关注云加社区,回复 3 加读者群
点击 阅读原文,获取本文PPT文件
以上是关于陈曦:性能与稳定并存 Elasticsearch调优实践的主要内容,如果未能解决你的问题,请参考以下文章
ElasticsearchElasticsearch性能调优
干货|eBay的Elasticsearch性能调优实践(上)