如何通过 Amazon ElasticSearch 托管服务,对 VPC 中的网络流量进行实时监控
Posted AWS云计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何通过 Amazon ElasticSearch 托管服务,对 VPC 中的网络流量进行实时监控相关的知识,希望对你有一定的参考价值。
② 进入右上角“…”菜单 → 【设为星标】
每天接收关于亚马逊云计算的最新资讯!
AWS 托管的 Elasticsearch 是一款非常流行的基于 Apache Lucene(TM) 的、开源的、近实时的分布式搜索分析引擎,Lambda 则是 AWS 上最为便捷、灵活的无服务器函数服务。
有了这两者的结合,您可以在 AWS 上轻松部署并实时监控您的各项资源及应用的使用情况(例如:各种日志,业务数据等)。
我们非常高兴地看到,这两项服务已经在 AWS 中国(宁夏)区域正式上线了。本案例将以宁夏区域为依托,手把手教您如何使用 AWS 托管服务对 VPC 中的网络流量进行实时监控。
什么是 ElasticSearch
Elasticsearch是一款非常流行的基于 Apache Lucene(TM)的、开源的、近实时的分布式搜索分析引擎。
无论在开源还是专有领域,Lucene 可以被认为是迄今为止最先进、性能最好的、功能最全的全文检索引擎库。但是,Lucene 只是一个库,想要使用它,你必须使用 Java 来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene 非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
Elasticsearch 也使用 Java 开发并使用 Lucene 作为其核心来实现,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。它被用作全文检索、结构化搜索、数据分析、复杂的语言处理、地理位置和对象间关联关系用途。
Elasticsearch具有如下特点:

开源(遵循 Apache License 2.0);
检索性能高效。对于每次实时查询,基本可以达到全天数据查询的秒级响应;
数据分布式存储,集群线性扩展;
易于从多样的数据源中采集数据,并注入到 Elasticsearch;
前端操作炫丽,Kibana 界面上,只需要点击鼠标,就可以完成搜索、聚合功能,生成炫丽的仪表板。
根据 TechCrunch 于 2017 年 4 月公布的的开源软件知名度排行榜中,Elasticsearch 位列第 7 位。
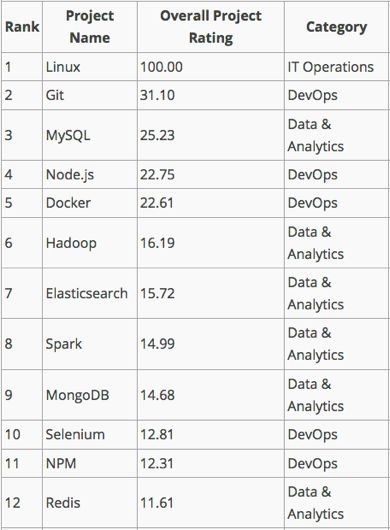
ElasticSearch 的典型应用场景
众所周知,业界存在各种各样的数据库和搜索引擎。那么基于什么样的业务或需求您可以考虑使用 ElasticSearch 呢?
下面列举几个典型的应用场景:
全文搜索
ElasticSearch 提供丰富的搜索与导航体验。例如:您的客户可以通过输入价格、产品特性和品牌等字段值来缩小搜索结果范围,并且支持创建高级搜索筛选条件、在输入时提供搜索建议以及近乎实时的索引更新。
Wikipedia 使用 Elasticsearch 提供带有高亮片段的全文搜索,还有 search-as-you-type 和 did-you-mean 的建议。
GitHub 使用 Elasticsearch 对 1300 亿行代码进行查询。
日志、 IoT、 移动设备分析
分析网站、移动设备、服务器、传感器和其他来源生成的非结构化和半结构化日志,用于数字营销、应用程序监控、欺诈检测、广告技术、游戏及 IoT 等多种应用场景。结合使用 Amazon Kinesis、Logstash 或 Amazon CloudWatch Logs 来捕捉和预处理日志数据,并将其加载到 Amazon Elasticsearch 服务中。
然后,您可以使用 Kibana 和 Elasticsearch 查询 DSL 来搜索、分析与显示数据,以便获取关于用户和应用程序的有价值的信息。
Expedia 使用 Amazon Elasticsearch 服务将应用程序日志和 Docker日志进行集中化存储和分析,实时掌握应用状态和故障分析。
实时监控(应用程序/基础架构)、故障分析
在面向客户的应用程序和网站中采集活动日志。使用 Logstash 将这些日志推送到 Amazon Elasticsearch Service 域。Elasticsearch 会对数据编制索引,并近乎实时地 (在不到一秒内) 将数据提供给分析工具。
然后,您可以使用内置 Kibana 插件使数据可视化,并执行中断与问题识别等运行分析工作。凭借 Elasticsearch 的地理空间分析,您可以找出发生问题的地理区域。然后,故障排除小组可以搜索索引并进行统计汇总,以确定根本原因并解决问题。
Netflix 使用 Amazon Elasticsearch 对众多的业务系统和基础架构进行自动化运维、故障发现和处理
业务、点击流分析
提供关于数字内容的实时指标,让作者和营销人员能够以最有效的方式与客户沟通。流式将数据加载到 Amazon Elasticsearch 服务之后,您可以聚合、筛选与处理这些数据,并近乎实时地刷新内容表现控制面板。
Hearst Corporation 利用 Amazon Elasticsearch 服务、Amazon Kinesis Streams 等服务构建了一个点击流分析平台,每天可以传输和处理来自全球 300 多个 Hearst 网站 的 30TB 数据。借助该平台,Hearst 能够在数分钟内将来自网站点击的整个数据流转化为聚合数据,并将其提供给编辑。
为什么选择 ElasticSearch服务
虽然 ElasticSearch 能够在上述诸多场景中帮到您,但是伴随着您业务的快速发展和对可用性、安全性要求的不断增加,您仍然会面临安装、维护、升级、扩展、安全性等方面的诸多挑战。
Amazon ElasticSearch 服务能够让您在如下 6 个方面轻松应对:
支持多种开源 API 和工具
Amazon Elasticsearch 服务让您可以直接访问 Elasticsearch 开源 API,因此您无需学习任何新的编程技术。
同时还支持 Logstash 这种开源数据注入、转换和加载工具,和 Kibana 这种开源可视化工具。让您轻松搭建ELK架构(Elasticsearch + Logstash + Kibana)或EKK架构(Elasticsearch + Kinesis + Kibana)
易于使用
您可以使用 Amazon Elasticsearch 服务在几分钟内部署一个生产就绪型 Elasticsearch 集群,无需预置基础设施或安装与维护 Elasticsearch 软件。
Amazon Elasticsearch 服务是一项完全托管的服务,可以简化软件修补、故障恢复、备份和监控等耗时的管理任务。
轻松扩展
Amazon Elasticsearch 服务允许您启动 PB 级群集。借助此服务,您可以通过 Amazon CloudWatch 指标来监控群集,只需一个 API 调用或在 AWS 管理控制台中点击几下即可扩大或缩减群集规模。
您可以选择不同的实例类型和存储选项 (包括 SSD 支持的 EBS 卷),从而让集群的配置符合自己的性能要求。
安全
Amazon Elasticsearch 服务可为您的域提供多个级别的安全性。它使用 VPC 提供网络隔离,使用 IAM 策略提供细粒度访问控制。Amazon Elasticsearch 服务会定期应用安全补丁,让您的域处于最新状态。
高度可用
Amazon Elasticsearch 服务可以感知可用区并在同一区域中的两个可用区之间复制数据,从而实现高可用性。Amazon Elasticsearch 服务可以监控集群的运行状况并自动替换故障节点。
与其他 AWS 服务紧密集成
Amazon Elasticsearch 服务内置集成多种其他 AWS 产品,其中包括用于无缝注入数据的 Kinesis + Lambda、AWS IOT 和 Amazon CloudWatch Logs、支持审核功能的 AWS CloudTrail、支持安全功能的 Amazon VPC 和 AWS IAM 以及支持云编排功能的 AWS CloudFormation。
说了这么多,
Amazon Elasticsearch 服务
究竟如何使用?
能够带来什么好处?
下面具体用一个案例来详细说明
使用它实时监控 VPC Flow Log
目标
在 AWS 中国(宁夏)区域,将 VPC Flow Log 实时注入到 Amazon ElasticSearch 服务中,并使用仪表盘进行实时监控和分析。
使用到的AWS服务
Amazon ElasticSearch
Amazon VPC Flow Logs
AWS Lambda
Amazon Cloudwatch
数据源
VPC Flow Logs
AWS Cloudtrail Logs
客户自定义 Logs
对于 Cloudtrail Logs,您可以通过设置将其输出到CloudWatch Log 中。
对于客户自定义Logs,您可以通过安装/配置CloudWatch Log Agents 将其输出到 CloudWatch Log 中,或者使用 logstash 将其直接注入到 Amazon ElasticSearch 服务中。
鉴于篇幅有限,在本例中,我们只示范如何将 VPC Flow Logs 注入到 Amazon ElasticSearch 服务中,并使用 Kibana 展示。
架构图
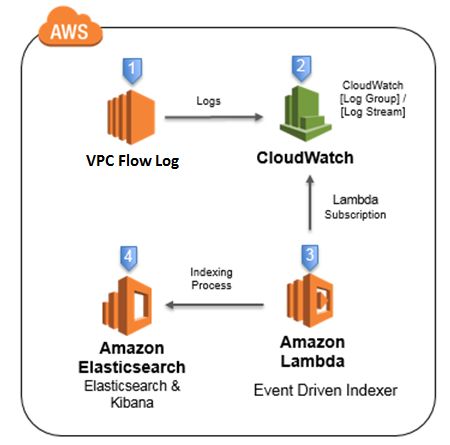
操作步骤
01
设置 Amazon ElasticSearch 域
在这一步,您将创建一个 Amazon Elasticsearch 域(domain),用来存储和分析日志。
创建域的同时,AWS 会自动同时安装 Kibana,随后您将会通过各种样式的图表在 Kibana 中展示这些数据。
1)在 AWS 管理控制台中
在左上角“服务”中,导航到 ElasticSearch Service,点击<创建新域>

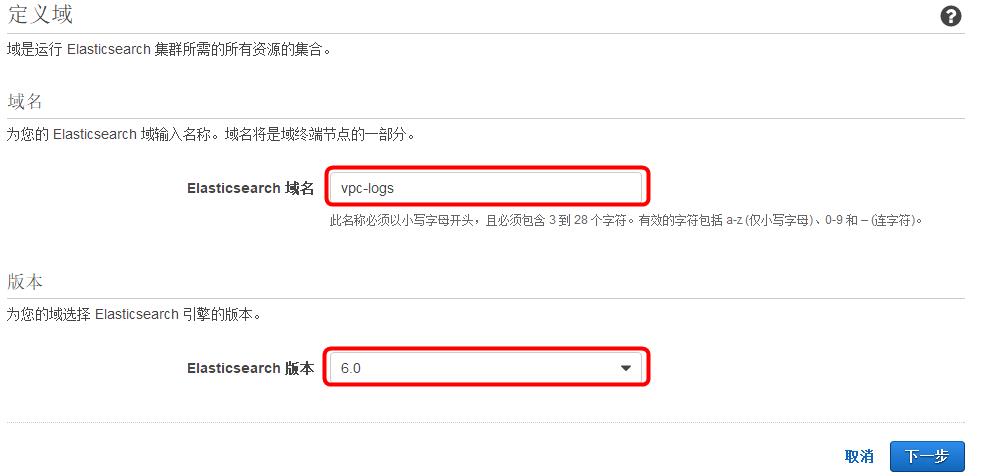
2)输入域名
例如:log-management,Elasticsearch 版本选择 “6.0“,然后点击<下一步>
3) 在《配置集群》页面中
《节点配置》部分,“实例计数”设置为 2,复选“启用专用主节点”和“启用区感知”,“专用主实例计数”选择默认值 “3”,其它保留默认设置,然后点击<下一步>
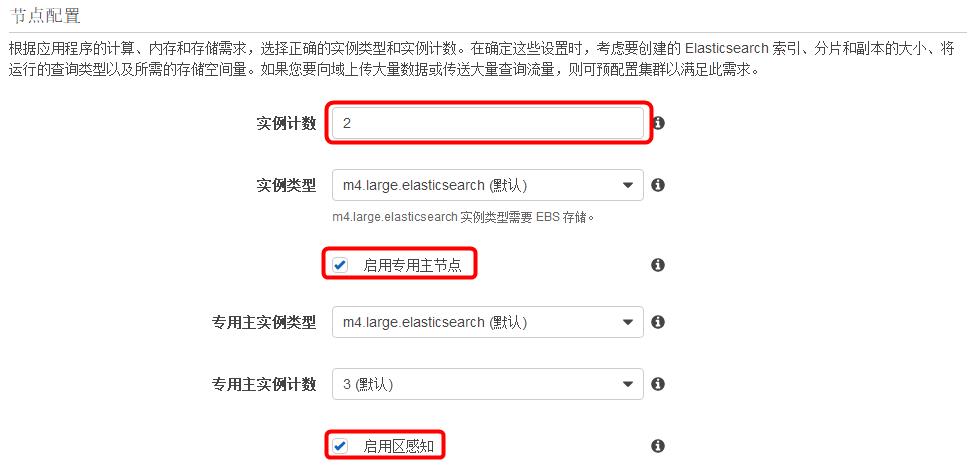
注:此处的设置仅为本示例使用,对于生产系统,建议您根据实际需要选择合适的实例数量和类型。
https://docs.aws.amazon.com/zh_cn/elasticsearch-service/latest/developerguide/es-createupdatedomains.html
4)在《设置访问权限》页面中
《网络配置》部分,选择“公有网络权限”
《访问策略》部分,“将域访问策略设置为”选择“允许从特定 IP 访问域”
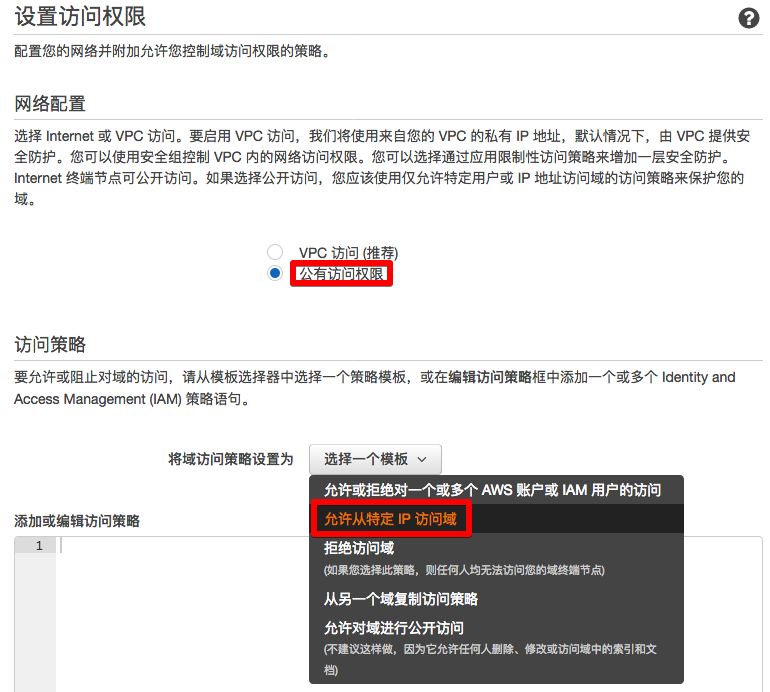
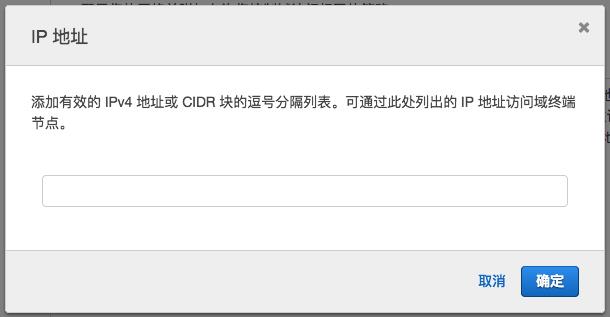
然后点击<下一步>。
5)在《审核》页面中
点击<确认>。至此,AWS 将会为您创建一个 ElasticSearch 集群,此过程大概需要 10-15 分钟。
点击该 ES 域,在“概述“页面,记录下”终端节点“名称,形如:search-vpc-logs-xxxxxxxx.cn-northwest-1.es.amazonaws.com.cn,这将在后续创建 Lambda 函数时用到。
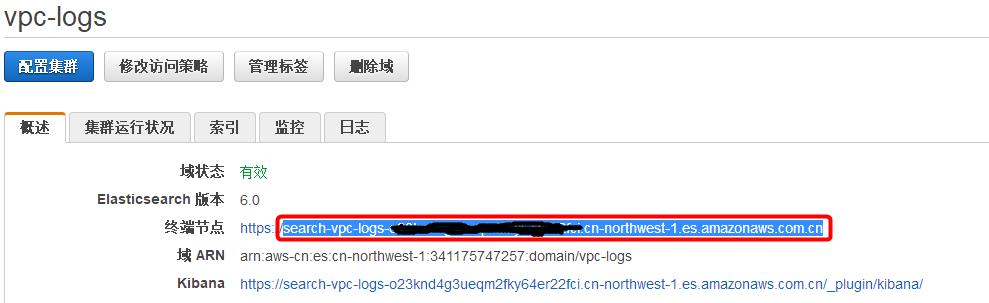
与此同时,我们可以继续进行下一步 ——
02
设置 VPC Flow Logs
在这一步,您将选取一个 VPC,开启 Flow Logs 功能,并将日志发送到 CloudWatch 中。这样,随后您可以通过 Lambda 将其注入到任务 01 中创建的 ElasticSearch 中。
1)在 AWS 管理控制台中
在左上角“服务”中,导航到 CloudWatch,在左侧面板中,点击<日志>。
2)创建日志组
如果您从未创建过日志组,则在浏览器中部会显示《欢迎使用 CloudWatch 日志》页面,点击<创建日志组>按钮,如果您之前创建过日志组,请点击<操作>按钮,在下拉列表中,选择<创建日志组>。
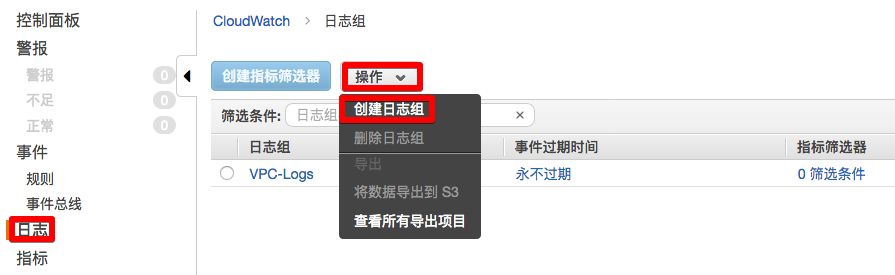
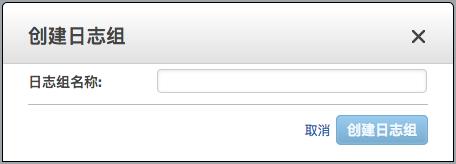
3 )在弹出窗口《创建日志组》中
输入日志组名称,例如: VPC-Logs 。点击<创建日志组>。
4)在 AWS 管理控制台中
导航到 VPC 服务。
5) 选择一个将要开启 Flow Logs 的 VPC 。
例如:默认的 VPC。
6) 在页面下方
点击<流日志>标签页。
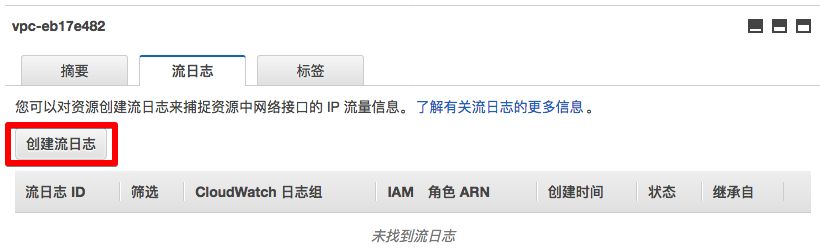
7)在弹出窗口《创建流日志》中
点击<设置权限>。
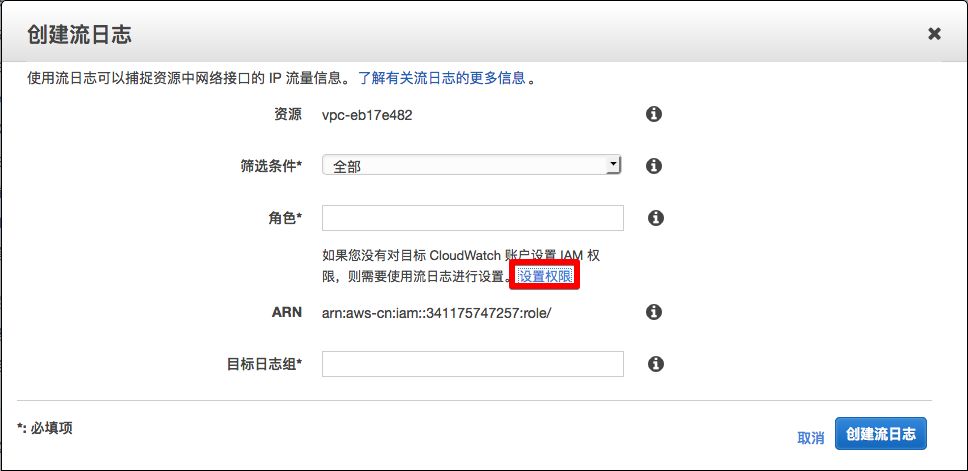
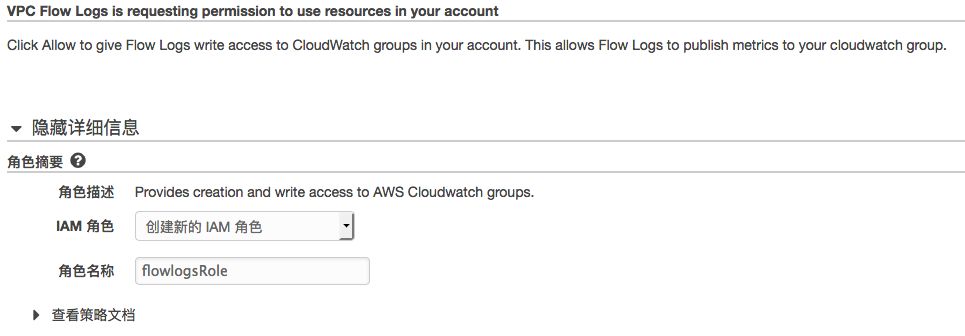
8)在新的弹出页面中
AWS 需要您授予 VPC Flow Logs 写入 CloudWatch 日志组(即第 3 步创建的日志组)的权限,并会创建一个名为 flowlogsRole 的角色。在这里点击<允许>。
9)该页面关闭后
会返回到第 7 步的《创建流日志》的窗口中,
点击“角色”,在下拉选项中,选择刚刚创建的角色“ flowlogsRole ”;
点击“目标日志组”,输入第3步创建的日志组名称,例如: VPC-Logs;
点击<创建流日志>。
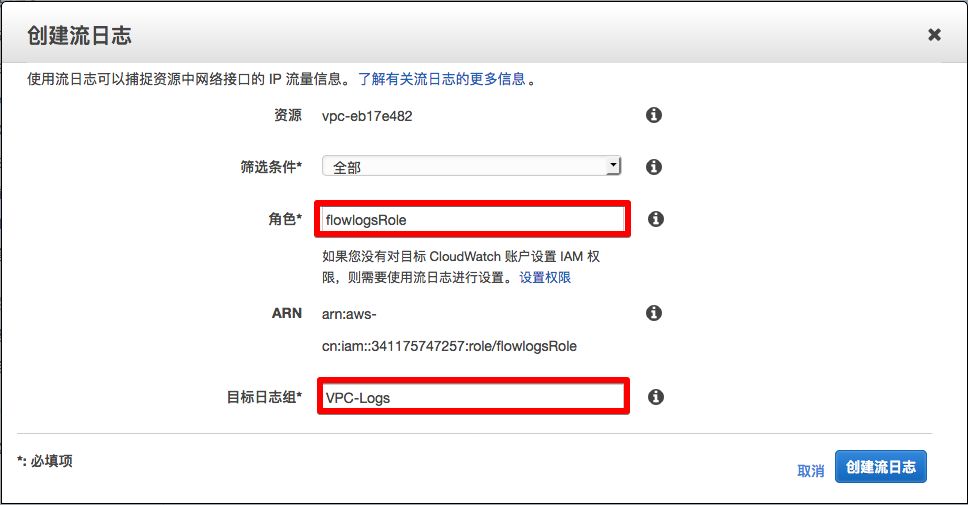
恭喜 ,您已成功将 VPC 的流日志实时注入到CloudWatch 日志组 VPC-Logs 中。稍微等少许时间,在该日志组中,您应该能够看到不断有新的日志产生。
03
通过 Lambda 将 CloudWatch 日志组中的数据流实时注入到 ElasticSearch 中
1)在 AWS 管理控制台中
导航到 Lambda 服务,点击“创建函数”。
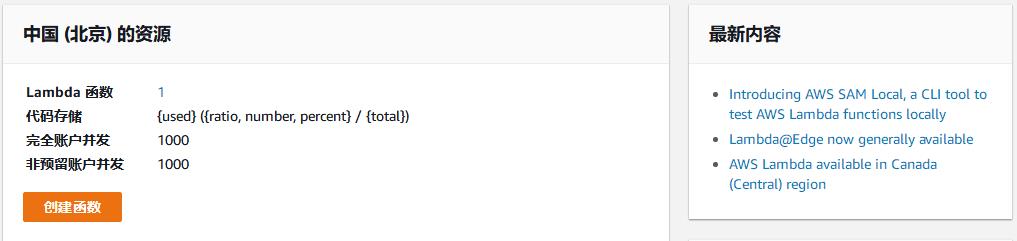
2) 在“创建函数”页面
选择“从头开始创作”;
在“名称”一栏,输入Lambda名称,例如“ LogsToElasticSearch_vpc-logs ”;
在“角色”一栏,选择“创建自定义角色”。因为 Lambda 在执行时,需要您授权相应的权限,以便能够从Cloudwatch Logs中读取数据,并写入到 ElasticSearch 中,所以在接下来的步骤中,你将会创建一个可供 Lambda 执行的角色。
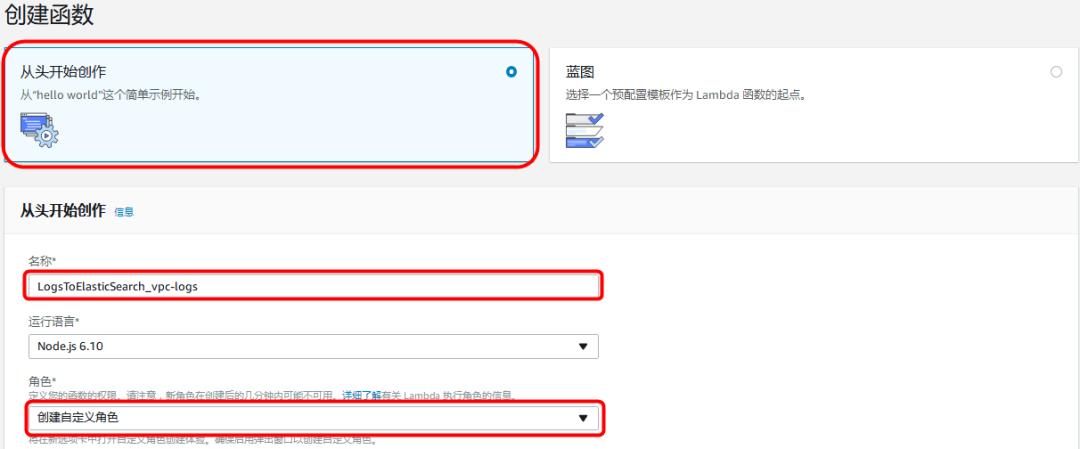
3)在新的弹出页面中
输入“角色名称“,例如:lambda_elasticsearch_execution,点击<查看策略文档>,<编辑>,在弹出的提示窗口中点击<确定>,将如下策略代码粘贴其中,点击<允许>。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"logs:CreateLogGroup",
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": [
"arn:aws-cn:logs:*:*:*"
]
},
{
"Effect": "Allow",
"Action": "es:ESHttpPost",
"Resource": "arn:aws-cn:es:*:*:*"
}
]
}
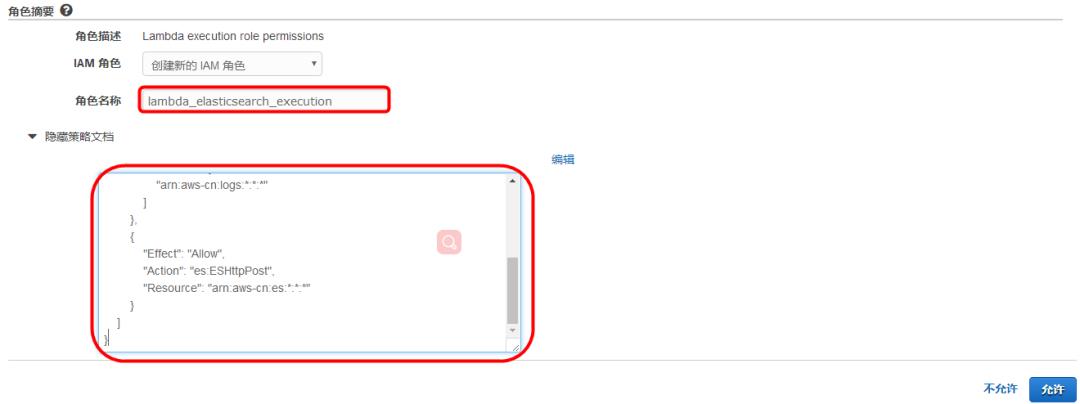
4)角色创建后,将返回到“创建函数”页面
在“角色”一栏,选择“选择现有角色”;
在“现有角色”一栏,选择上一步创建的角色,例如:lambda_elasticsearch_execution;
点击<创建函数>。
5))在新页面的“ Designer ”部分
在左侧栏“添加触发器”中,点击“ CloudWatch Logs”。
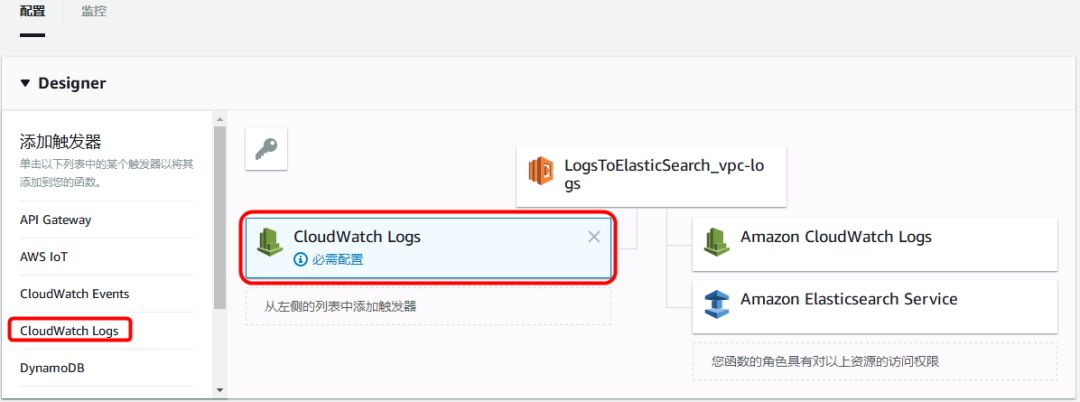
在“配置触发器”部分,
“日志组”选择任务 02 中创建的日志组,例如:VPC-Logs;
“筛选器”输入任意名称,例如 MyFilter;
“筛选器模式”留空;
请确保勾选“启用触发器”;
点击<添加>。
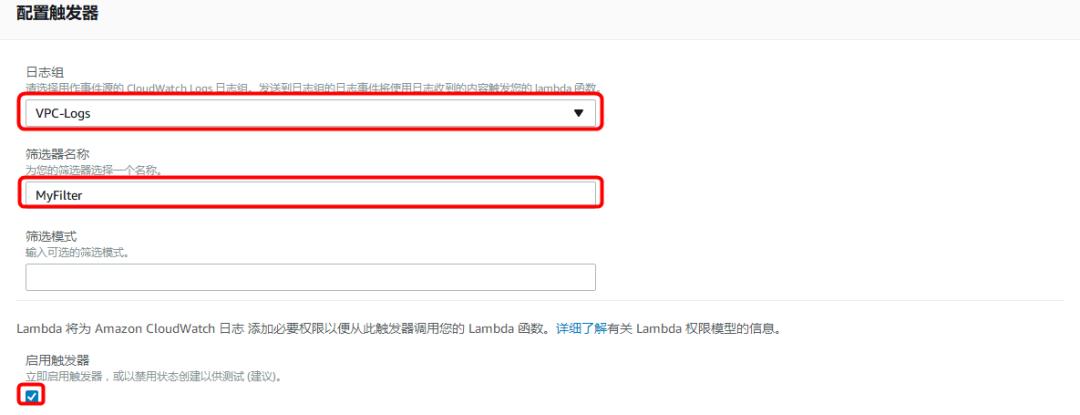
6)点选页面中部的 Lambda 函数按钮
页面下方将会出现”函数代码”部分
7) 在“函数代码“部分
从附录 1 中下载 Lambda 所需的 node.js 代码,并粘贴到代码编辑器中。代码中,将:
var endpoint = 'search-xxxxxxxxxxx.cn-northwest-1.es.amazonaws.com.cn;
改为:
任务 01 中记录下的”终端节点”名称(注意:不包括https://);
其它选项保持不变,页面右上方点击<保存>。
恭喜 ,您已成功将 CloudWatch 日志组 VPC-Logs 中的日志,实时注入到了 ElasticSearch 中。
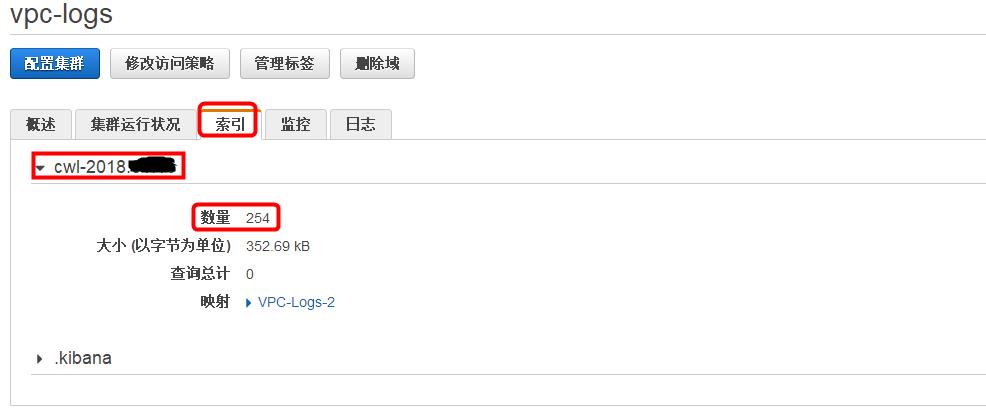
在 ElasticSearch 服务中,选择域 vpc-logs,点击“索引“页面,您将会看到一个新的 index(cwl-2018.x.x)已经创建,并产生了一些新的数据。
04
通过 Kibana 图形化展示数据
1)在 AWS 管理控制台中
左上角“服务”中,导航到 ElasticSearch Service,在左侧导航栏中,点击之前创建的域 log-management 。在“概述“页面,点击“ Kibana ”后面的链接,打开 Kibana 。
2)在打开的 Kibana 管理页面中
将“ Index pattern “中的 logstash-*,修改为cwl-*。其它保持不变,点击< Create >。
此时,您将会看到所有以“cwl-“开头的 index 的所有字段(fields)。
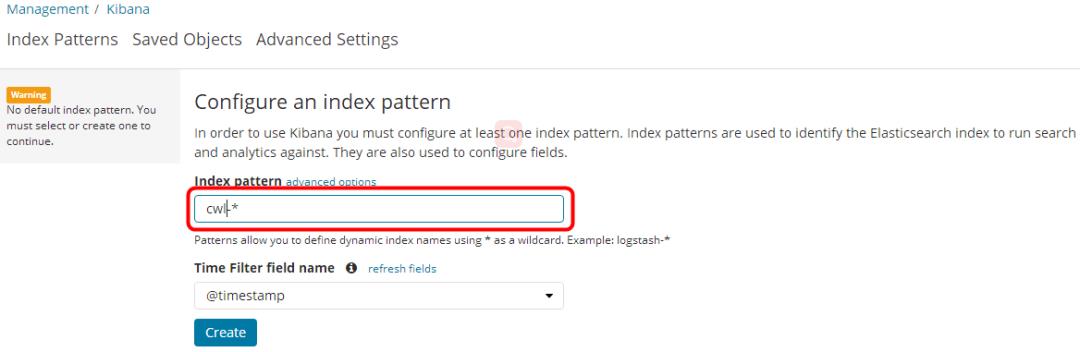
点击左侧导航栏中的< Discover >,您将会看到 ElasticSearch 中所有的数据。
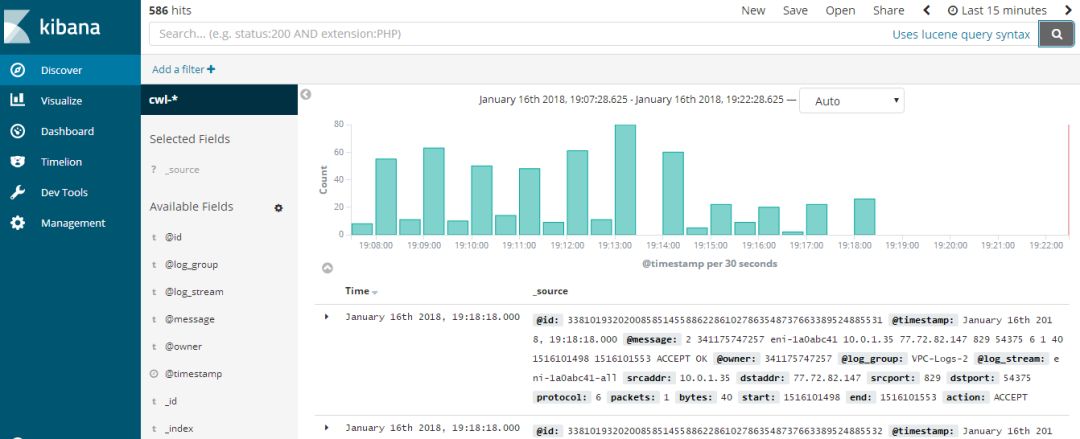
3) 在 Kibana 的左侧导航栏中,点击< Management >,页面中部点击< Saved Objects >
在右上方点击< Import >。
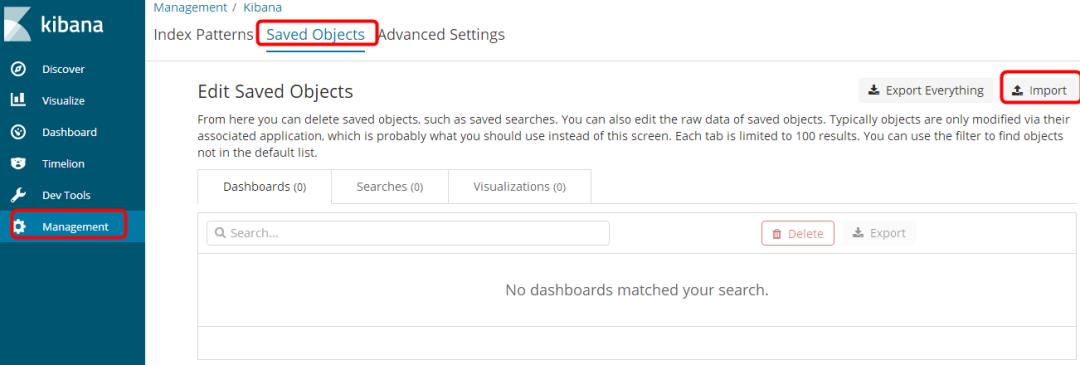
在弹出的窗口中,选择刚刚下载的 VPC-Logs-Kibana6.json,点击< Yes,overwrite all >
在新弹出的窗口中,点击< Confirm all changes >
此时,您会看到已经导入了 1 个 Dashboards 和 7 个 Virtualizations。
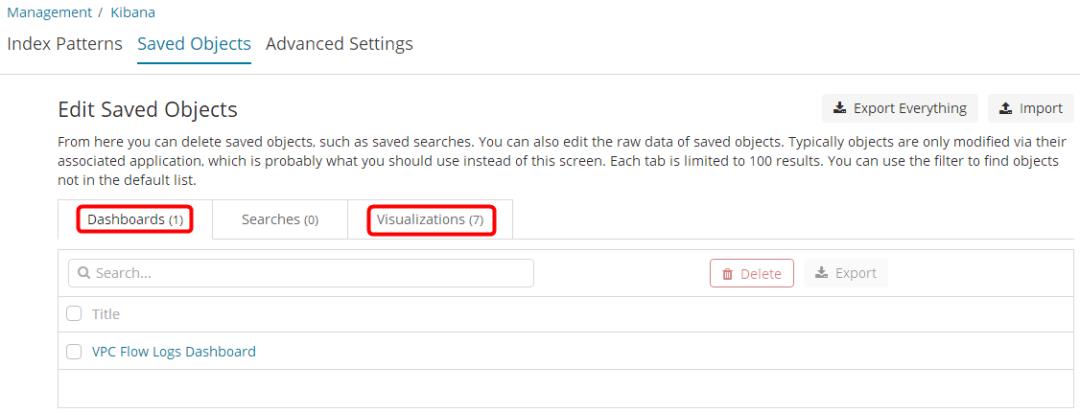
点击< Confirm all changes >
4)在 Kibana 的左侧导航栏中,点击<Dashboard >,选择“ VPC Flow Logs Dashboard ”
统计和分析页面即呈现在您的面前了。
附录
https://s3-us-west-2.amazonaws.com/cn-demo-scripts/LambdaVPCLogsToES.js
https://s3-us-west-2.amazonaws.com/cn-demo-scripts/VPC-Logs-Kibana6.json
—END—
马上点击“阅读原文”
申请并获得 AWS 中国区域账户的用户
将会获赠价值 500RMB 的 AWS 服务抵扣券!
以上是关于如何通过 Amazon ElasticSearch 托管服务,对 VPC 中的网络流量进行实时监控的主要内容,如果未能解决你的问题,请参考以下文章
通过 Cloud Formation 创建 Amazon Elasticsearch Service 时出现 CloudWatch 资源访问策略错误
如何从 Amazon elasticsearch 服务访问 Kibana?
Django-Haystack 使用带有 IAM 凭证的 Amazon Elasticsearch 托管
Amazon Elasticsearch 集群的正确访问策略
ruby 在Heroku上使用Rails&searchkick gem安全地使用Amazon Elasticsearch(签名请求)。
使用 Amazon Kinesis Data Firehose ElasticSearch Selivery 时是不是可以设置文档 ID