为什么已有Elasticsearch,我们还要重造实时分析引擎AresDB?
Posted AI前线
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么已有Elasticsearch,我们还要重造实时分析引擎AresDB?相关的知识,希望对你有一定的参考价值。
过去,我们采用过许多第三方数据库作为我们的实时分析解决方案,但没有一款数据库既能够实现所有功能,同时又满足我们对于可伸缩性、性能、成本和运营的要求。
AresDB 发布于 2018 年 11 月,是一个开源的实时分析引擎,它使用了一种非同寻常的算能来源——图形处理单元(GPU),使我们的分析能力得以大规模增长。作为一种新兴的实时分析工具,GPU 技术在过去几年中取得了显著进步,非常适用于实时计算和并行数据处理。
更多优质内容请关注微信公众号“AI 前线”(ID:ai-front)
在以下章节中,我们将详述 AresDB 的设计,以及它如何使我们更有效地统一、简化和改进 Uber 的实时分析数据库解决方案。在阅读这篇文章后,我们希望你能够在自己的项目中尝试一下 AresDB,并根据你自己的分析需求发掘这个工具的价值!
数据分析对 Uber 业务的成功起到至关重要的作用,在其他功能中,这些分析被用于:
构建 仪表盘(DashBoard) 来监控我们的业务指标
根据我们收集的聚合指标制定 自动化决策(比如 行程定价 和 欺诈检测)
构建 即席查询(ad hoc queries) 以诊断并解决业务运营问题
我们可以将这些功能按照不同需求归纳如下:
| 仪表盘 | 决策系统 | 即席查询 | |
|---|---|---|---|
| 查询模式 | 固定 | 固定 | 随意 |
| 查询 QPS | 高 | 高 | 低 |
| 查询延迟 | 低 | 低 | 高 |
| 数据集 | 子集 | 子集 | 所有数据 |
仪表盘和决策系统利用实时分析系统,在较高 QPS 和较低延迟下,基于相对较小但非常有价值的数据子集(具有最大的数据时效性)构建相似查询。
在 Uber,实时分析最常被用来计算时间序列聚合,通过这些计算,能让我们洞察用户体验从而相应地改进我们的服务,我们可以在一个时间范围内针对任意过滤或连接(Join)后的数据请求特定维度(如按天、按小时、按城市 ID 和行程状态)的指标。多年来,Uber 已经部署过多种解决方案,通过不同的方式来解决这个问题。
我们尝试过的第三方解决方案包括:
Apache Pinot:一个用 Java 编写的开源分布式分析数据库,可用于大规模数据分析。Pinot 的内部使用 Lambda 架构来批量或实时查询列存储中的数据,使用反向位图索引进行过滤,并依赖星形树(译注:图论术语 Star-Tree,仅有一个顶点不是叶子的树)缓存聚合结果。但是,它不支持基于键的去重、Upsert 操作、Join 操作,以及像地理空间过滤这样的高级查询特性。此外,Pinot 作为一个基于 JVM 的数据库,执行查询操作时会消耗较高的内存。
Elasticsearch:基于 Apache Lucene 构建,用于对存储文档和反向索引进行全文关键字搜索。Elasticsearch 已被业界广泛采用并扩展了对聚合的支持,在 Uber 它被用于实现各种流媒体分析的需求;它的反向索引支持过滤,但尚未优化基于时间范围的存储和过滤;它的记录存储格式为 JSON 文档,因而会额外增加存储和查询访问的开销。Elasticsearch 与 Pinot 一样,它也是一个基于 JVM 的数据库,因此不支持 Join 操作,并且执行查询操作需要更高的内存开销。
虽然这些技术各具优势,但都缺少关键功能来满足我们的使用场景。我们需要跳出思维定式,更确切地说是要基于 GPU 来实现一个统一又精简的解决方案。
为了以较高帧率将视图渲染为逼真的图像,GPU 会高速并行处理大量的几何图形和像素。虽然在过去几年里,处理单元的时钟频率增长已趋近平稳,但是根据 摩尔定律,这只不过是单纯增加了芯片上的晶体管数量。因此,每秒以十亿次(GFLOP/s)计的 GPU 计算速度正在迅速增加,下方图 1 比较了在过去几年中 NVIDIA 的 GPU 和 Intel 的 CPU 的理论计算速度。
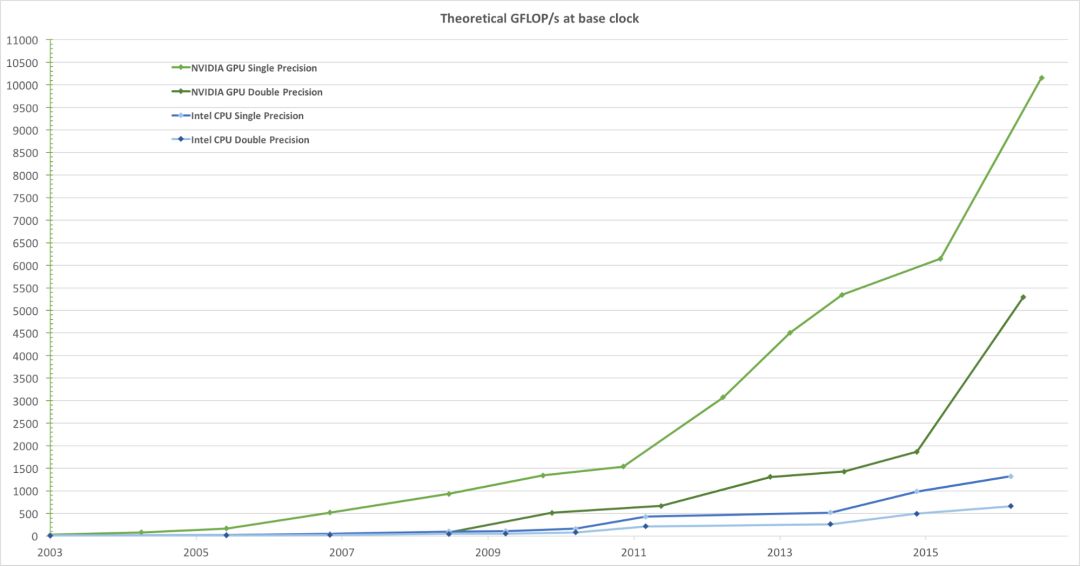
图 1:近年来 CPU 和 GPU 单精度浮点性能的比较,图片来自 NVIDIA 的 [CUDA C 编程指南](https://docs.nvidia.com/cuda/cuda-c-programming-guide/index.html)
在我们设计实时分析查询引擎时,集成 GPU 处理便是我们的最佳选择。在 Uber,最常见的实时分析查询场景需要处理数天的数据和数百万到数十亿条记录,然后在短时间内过滤和聚合这些数据,通用 GPU 的并行处理模型完全适用于这种类型的计算任务,因为他们能够做到:
非常快速地并行处理数据。
提供更大的计算吞吐量 (GFLOPS/s) ,非常适用于处理可并行化的繁重计算任务(每单位数据)。
从计算到存储(从 ALU 到 GPU 全局内存)的数据访问吞吐量比中央处理器(CPU)更大,而具有 I/O(内存)约束的并行任务需要大量数据,因此 GPU 是处理这种数据的理想选择。
当我们决定使用基于 GPU 的分析数据库之后,我们又评估了现有的一些能满足我们需求的解决方案:
Kinetica:最初于 2009 年面向美国军事和情报应用市场推出的基于 GPU 的分析引擎。尽管它的 GPU 技术在分析方面展示了巨大潜力,但我们发现,想要满足我们的用例还需要更多关键特性,包括:Schema 变更、部分插入或更新、数据压缩、列级内存 / 磁盘备份保留配置,以及按地理空间连接。
OmniSci:一个基于 SQL 的开源查询引擎,看起来似乎是一个很有前景的选择,但在评估之后,我们意识到它缺少 Uber 使用场景中的关键特性,例如去重。虽然 OminiSci 在 2017 年开源了他们的项目,但在对他们这个基于 C++ 的解决方案进行一些分析之后,我们得出的结论是,无论是给代码库贡献代码还是新建一个分支都行不通。
GPUQP、CoGaDB、GPUDB、Ocelot、OmniDB 和 Virginian:学术机构经常使用这些基于 GPU 的实时分析引擎,然而出于其学术目的,这些解决方案侧重于开发算法和验证设计概念,不能处理现实世界中的生产场景,我们的业务规模远超这些方案的应用范围,因此我们调低了对他们的期望。
总的来说,这些引擎证明了通过 GPU 技术处理数据具有巨大的优势和潜力,同时也激励我们自研基于 GPU 的实时分析解决方案来满足 Uber 的需求,有了这些构思,我们构建了开源的 AresDB。
抽象来看,AresDB 将大部分数据存储在主机内存中,内存连接到 CPU,由 CPU 处理数据输入过程,如遇异常可通过磁盘恢复数据。查询时,AresDB 将数据从主机内存传输到 GPU 内存,以便在 GPU 上并行处理。如下方图 2 所示,AresDB 由一个内存存储器、一个元数据存储器和一个磁盘存储器组成:
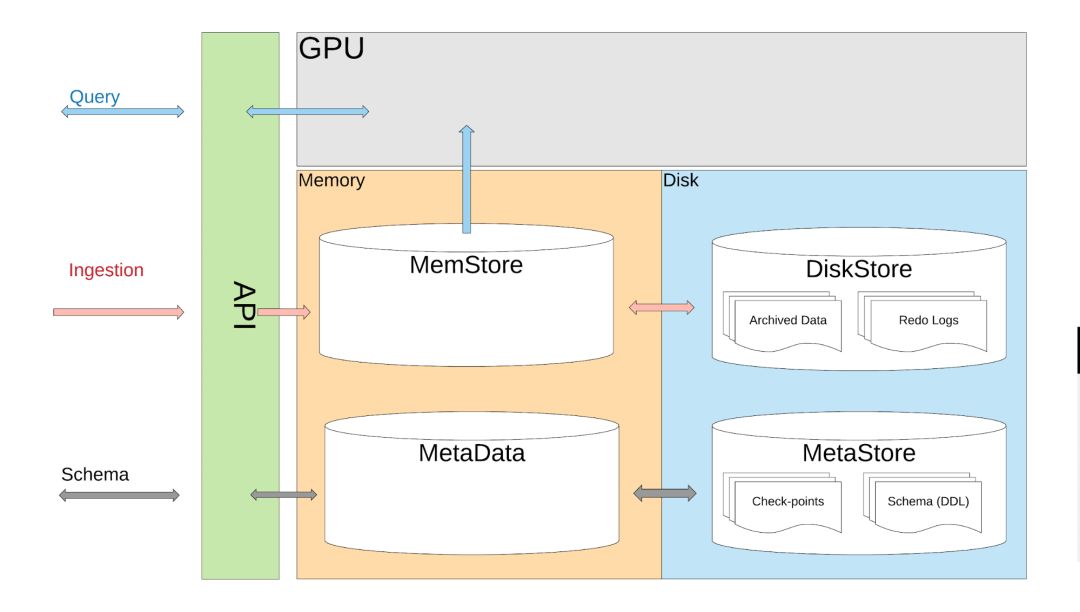
图 2:AresDB 单实例架构包含内存和磁盘存储以及元存储
与大多数关系型数据库管理系统(RDBMS)不同,AresDB 中没有数据库作用域或 Schema 作用域,所有表都同属于一个 AresDB 集群或实例并具有相同作用域,以使用户能够直接引用的。用户可以将自己的数据存储为事实表(Fact Table)和维度表(Dimension Table)。
事实表存储一个无限的时间序列事件流,用户用事实表存储实时发生的事件(Event)或事实(Fact),每个事件都关联一个事件时间,该表通常通过事件时间来查询。为了说明用事实表存储的信息类型,我们举一个 Uber 打车的例子,其中每一次行程都是一个事件,叫车时间通常被定义为事件时间,如果一个事件关联了多个时间戳,那么只有其中一个可以被指定为事实表中显示的事件时间。
维度表存储实体(包括城市、客户端和驱动程序等)的当前属性。例如,用户可以在维度表中存储城市信息,如城市名称、时区和国家。与事实表相比,维度表不会随时间无限增长,大小总是有限的(例如,对 Uber 来说,城市表的上限是世界上实际的城市数量)。维度表不需要一个特别的时间列。
下方的表格详述了 AresDB 目前支持的数据类型:
| 数据类型 | 容量(字节) | 详细信息 |
|---|---|---|
| Bool | 1/8 | 布尔型数据,存储为一个二进制位 |
| Int8, Uint8 | 1 | 整数类型,用户可以根据字段的基数(Cardinality)和内存开销来选择 |
| Int16, Uint16 | 2 | |
| Int32, Uint32 | 4 | |
| SmallEnum | 1 | 字符串会被自动翻译成枚举类型,SmallEnum 类型可以保存基数不高于 256 的字符串 |
| BigEnum | 2 | 与 SmallEnum 相似,基数上限是 65535(译注:2^16-1) |
| Float32 | 4 | 浮点数,我们支持 Float32,未来若有需求再支持 Float64 |
| UUID | 16 | 通用唯一识别码 |
| GeoPoint | 4 | 地理点 |
| GeoShape | 可变长度 | 多边形或多个多边形 |
用 AresDB 存储字符串会自动转换为 枚举类型(enum),这样做可以提高存储和查询的效率,支持大小写敏感的等式检查,但不支持高级操作,例如:字符串拼接、字符串子串、glob 匹配和正则表达式匹配,我们打算日后增加完整的字符串支持。
AresDB 的架构支持以下特性:
压缩基于列存储的数据以提高存储效率(仅存储数据字节数这一项就可以减少内存开销)和查询效率(在查询过程中从 CPU 内存到 GPU 内存传输的数据更少)
通过主键去重实时执行 Upsert 操作,可在几秒钟内实现高数据准确性和接近实时的数据时效性
GPU 驱动的查询处理过程能够高度并行化地处理数据,提供低查询延迟(亚秒到秒)
AresDB 按照列式格式存储所有数据,每列的值存储为列式值向量,每列值的有效性或无效性用一个二进制位表示,存储在单独的空向量中。
AresDB 将未压缩和未排序的列式数据(实时向量)储存在实时存储中,实时存储中记录的数据被实时分发到多个 Batch 的配置容量中,导入时创建新的 Batch,记录归档后清除旧的 Batch。我们用主键索引来定位重复和更新的记录,下面的图 3 展示了我们组织实时记录并通过主键值定位这些记录的过程:
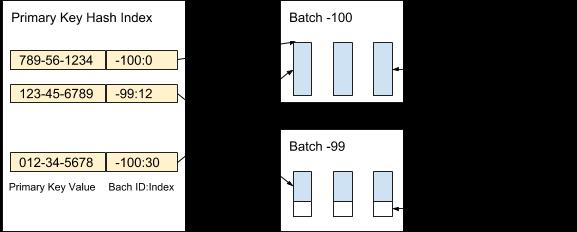
图 3:我们使用主键值来定位每个记录的 Batch 和 Batch 的位置
每个 Batch 中每列的值都以列向量的形式存储,每个值向量中值的有效性或无效性被存储为一个独立的 null 向量,每个值的有效性以一个二进制位表示。在下面图 4 的示例中,city_id 列包含五个值:
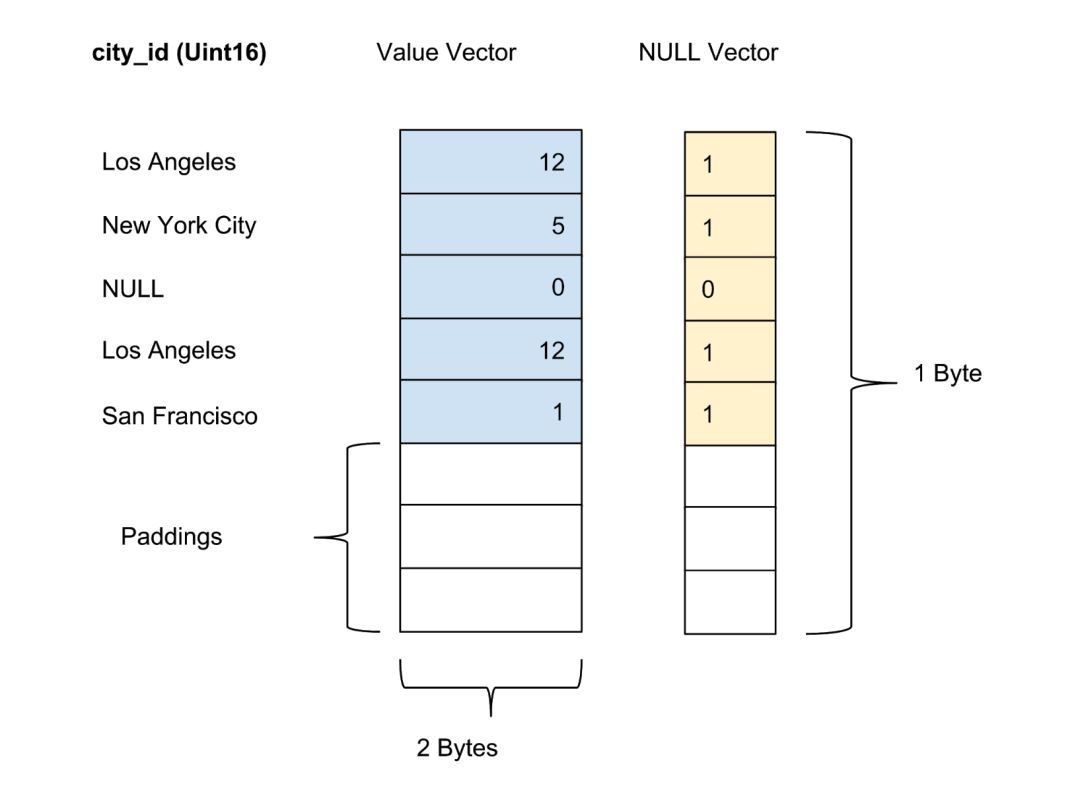
图 4:我们在数据表中存储未压缩列的值(实际值)和 null 向量(有效性)
对于已排序和已压缩的成熟列数据(归档向量),AresDB 会通过事实表的方式将其储存在归档存储中,归档存储中的记录也被分成了多个 Batch。与实时 Batch 不同的是,归档 Batch 包含特殊的日期记录,这些日期用协调世界时(UTC)表示,并使用与 Unix 初始时间的日期差作为 Batch 的 ID。
每条记录都按照用户配置的列顺序排序,如图 5 所示,我们先按 city_id 列排序,然后再按 status 列排。
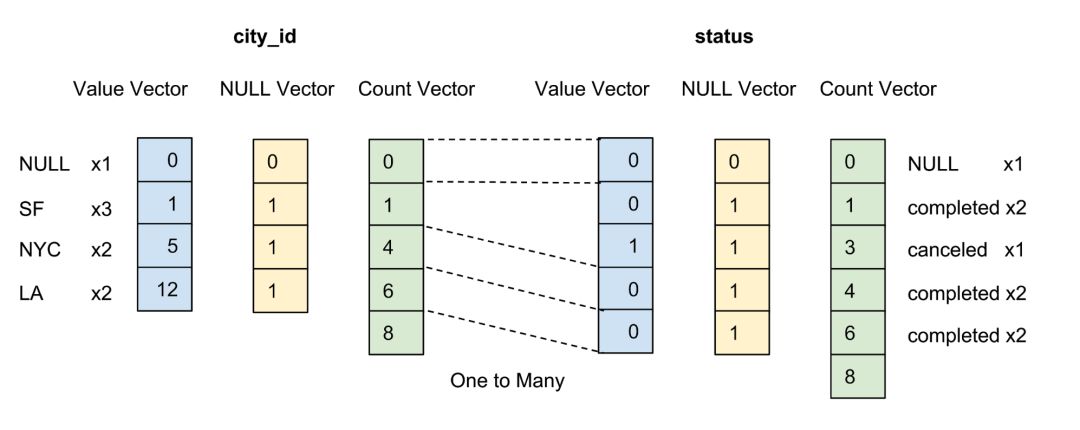
图 5:我们先根据 city_id 列将所有行排序,然后按 status 列排序,最后使用游程编码压缩每一列。每一列在被排序和压缩后都会有一个计数向量。
设置按用户配置的列排序顺序的目的是:
提前排序低基数的列以最大化压缩效果,最大化压缩能够提高存储效率(减少存储数据所需的字节)和查询效率(减少从 CPU 传输到 GPU 内存的字节)。
支持对常见的等式过滤(如 city_id=12)进行基于范围的预过滤,预过滤能够最小化从 CPU 内存到 GPU 内存需要传输的字节来降低开销,从而最大化查询效率。
某一列只有在用户配置的排序顺序中出现才会被压缩,我们不会尝试压缩高基数列,因为压缩高基数列所节省的存储量可以忽略不计。
在排序之后,会用各种游程编码压缩每个合格列的数据,除了值向量和 null 向量之外,我们还引入了计数向量来表示重复的相同值。
客户端向 AresDB 导入数据,需要通过 Ingestion HTTP API 发起一个 UpsertBatch 的 Post 请求,UpsertBatch 是一种自定义的序列化二进制格式,这种格式可以保证数据是随机访问的,同时也能最大限度地减少空间开销。
当 AresDB 接收到一个导入数据的 UpsertBatch 请求时,首先会将它写入重做日志(Redo Log)的末尾,用于从异常中恢复。然后,AresDB 会识别出事实表中的延迟记录(late records),每当向实时存储导入数据时都会跳过这些数据。如果记录的事件时间早于归档的截止事件时间,则被认为是“延迟”记录。AresDB 使用主键索引来定位 Batch 应该被放到哪个实时存储中,如下面图 6 所示,全新的记录(记录的主键值从未出现过)将被存入空白空间,而已有的记录将直接更新:
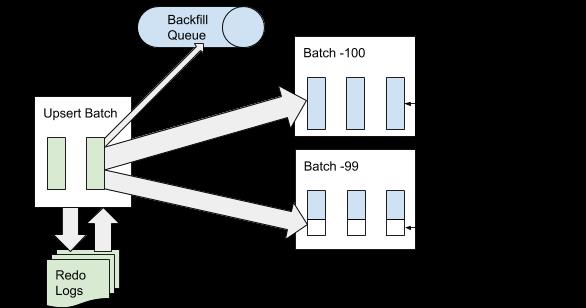
图 6:在导入过程中,追加 UpsertBatch 到重做日志后,将“延迟”记录追加到回填队列中,而在实时存储中存入其他记录。
在导入数据时,要么将新记录追加到实时存储中,要么更新实时存储中已有的记录,抑或将数据追加到等待放入归档存储的回填队列中。
我们会定期运行一个名为“归档”的计划过程,将实时存储中的新记录(以前从未归档的记录)合并到归档存储中,归档只处理实时存储中的记录,其事件时间将位于旧的截止时间(上次归档过程的截止时间)和新的截止时间(基于表 Schema 中的归档延迟设置项中的新的截止时间)。
我们每天批量处理归档数据的时候,用记录的事件时间来确定记录应该被合并到哪个归档 Batch。在合并过程中,归档不需要给主键值索引去重,因为只有在新旧截止时间范围内的记录会被归档。
接下来的图 7 展示了一条基于给定记录时间的时间线:
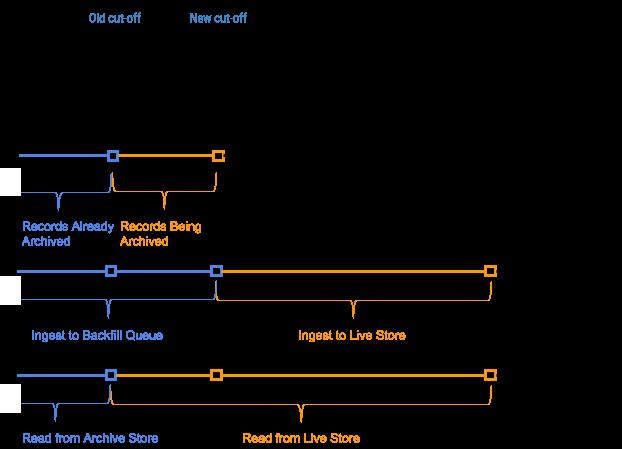
图 7:通过事件时间和截止时间来确定哪些记录是新的(实时的),哪些记录是旧的(事件时间早归档截止时间)。
在这种情况下,两次归档操作运行的间隔时间被称作归档间隔(Archiving Interval),而在事件发生后直到可被归档前的这段持续时间被称作归档延迟(Archiving Delay),二者都可以在 AresDB 的表 Schema 配置中定义。
如图 7 所示,事实表中的旧记录(事件时间早于归档截止时间)被追加到回填队列中,最终由回填进程处理。每当回填队列的时间或大小达到阈值,就会触发这个进程。与实时存储的导入过程相比,回填操作是异步进行的,CPU 和内存资源开销相对更大,回填在以下场景中使用:
处理偶尔很晚到达的数据
借助上游手工修复历史数据
为最近添加的列填充历史数据
与归档不同的是,回填是幂等的,并且需要基于主键值进行去重,被回填的数据最终对查询可见。
回填队列一直保留在内存中,并且预先配置了一定的空间。在大量回填载入期间,直到回填操作运行后清除了队列才会解除客户端阻止运行的状态。
在当前的实现下,用户需要使用 Uber 创建的 Ares 查询语言(AQL)来对 AresDB 进行查询。AQL 是一种有效的时间序列分析查询语言,不像其他类 SQL 语言一样遵循 SELECT FROM WHERE GROUP BY 这种标准的 SQL 语法。相反,AQL 是在结构化字段中指定的,可以与 JSON、YAML 和 Go 对象一起使用。例如,与
SELECT count(*) FROM trips GROUP BY city_id WHERE status = ‘completed’ AND request_at >= 1512000000等效的 JSON 格式的 AQL 写法如下:
{
“table”: “trips”,
“dimensions”: [
{“sqlExpression”: “city_id”}
],
“measures”: [
{“sqlExpression”: “count(*)”}
],
;”> “rowFilters”: [
“status = ‘completed'”
],
“timeFilter”: {
“column”: “request_at”,
“from”: “2 days ago”
}
}AQL 采用 JSON 格式,为仪表盘和决策系统开发者提供比 SQL 更好的程序化查询体验,因为开发者可以用代码轻松地编写和操作查询语句,并且无须担心诸如 SQL 注入这样的问题。JSON 格式是 Web 浏览器、前端服务器和后端服务器这种经典架构的通用查询格式,一直到数据库(AresDB)都支持。此外,AQL 还为时间过滤和桶化(Bucketization)提供了方便的 语法糖,并提供原生的时区支持。这门语言还支持隐式子查询等功能,以避免常见的查询错误并使后台开发者可以方便地进行查询分析和重写。
尽管 AQL 提供了各种好处,但我们充分意识到大多数工程师更熟悉 SQL,所以接下来,我们的研究方向就包括为查询操作提供 SQL 接口来增强 AresDB 的用户体验。
如下图 8 描绘了 AQL 查询的执行流程:
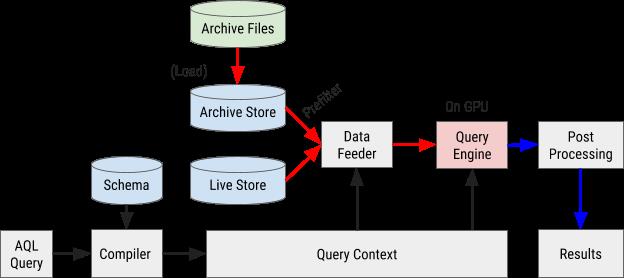
图 8:AresDB 的查询执行流程利用了我们自主开发的 AQL 查询语言,可以快速高效地处理并检索数据。
AQL 查询会被编译成内部的查询上下文,过滤器、Dimension 和 Measurement(译注:相当于关系型数据库中的 Table)中的表达式被解析成抽象语法树(AST),以便后续通过 GPU 进行处理。
AresDB 将归档数据发送至 GPU 进行并行处理前,会对数据进行预过滤以降低性能开销。由于存档数据是按照预先配置的列顺序排列的,所以一些过滤器可能可以通过二分搜索定位相应的匹配范围来利用此排序。特别是,所有首个 X 排序列上的相等过滤器和 X+1 排序列上的范围过滤器(可选)都可以作为预过滤处理,如图 9 所示:
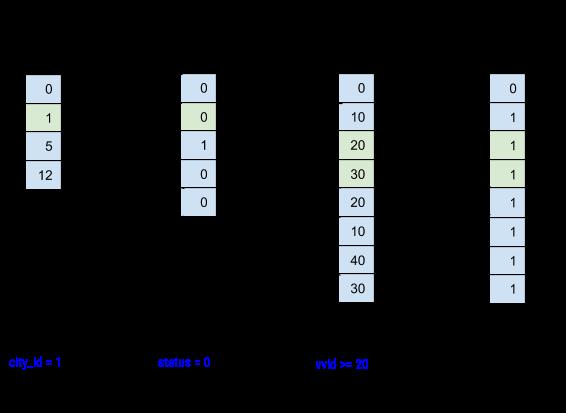
图 9:AresDB 预过滤列数据,然后将其发送到 GPU 进行处理。
在预过滤后,只需将绿底色的值(满足过滤条件的值)推送到 GPU 以进行并行处理,输入数据被馈送到 GPU,每次执行一个 Batch(包括实时 Batch 和归档 Batch)。
AresDB 利用 CUDA 流(译注:CUDA 流表示 GPU 中的操作队列)来馈送并执行流水数据。每次查询交替使用两个流,以便在处理过程中同步传输数据。下方图 10 的时间线描绘了这一过程:
图 10:在 AresDB 中,两个 CUDA 流交替传输和处理数据
为简单起见,AresDB 利用 Thrust 库 来实现查询执行过程,该程序提供了经过微调的并行算法构建块,以便在当前的查询引擎中快速实现。
Thrust 使用随机访问迭代器来访问输入和输出向量数据,每个 GPU 线程将输入迭代器取到其工作负载位置,读取值并执行计算,然后将结果写入到输出迭代器上的对应位置。
AresDB 遵循 OOPK 模型(每个内核一个操作符)来计算表达式。
下面的图 11 是通过查询编译阶段的维度表达式request_at – request_at % 86400生成的示例 AST:
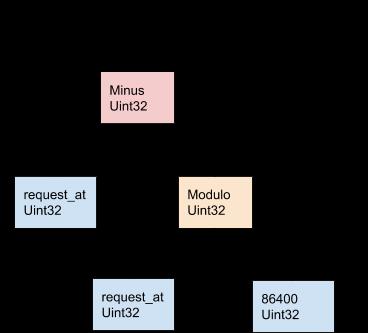
图 11:AresDB 利用 OOPK 模型对表达式求值进行建模
在 OOPK 模型中,AresDB 查询引擎遍历 AST 树的每个叶子节点,并为其父节点返回一个迭代器。在根节点也是叶子节点的情况下,直接在输入迭代器上执行根操作。
在每个非根非叶节点(本示例中的 取模 运算),分配一个临时的暂存空间向量来存储 request_at % 86400 表达式产生的中间结果,利用 Thrust 在 GPU 上启动一个内核函数来计算这个运算符的输出。结果存储在暂存空间迭代器中。
在根节点上,启动内核函数的方式与非根非叶结点相同,并根据表达式的类型采取不同的输出操作,具体如下:
过滤操作,以减少输入向量的基数
将维度输出写入维度向量,以供后续聚合
将度量输出写入度量向量,以供后续聚合
在表达式求值后,执行 排序 和 归约 操作以备最终聚合,在排序和归约操作中,我们使用维度向量的值作为排序和归约的关键值,并使用度量向量的值作为要聚合的值。通过这种方式,具有相同维度值的行将组合在一起并进行聚合。下面的图 12 详述了这个排序和归约的过程:
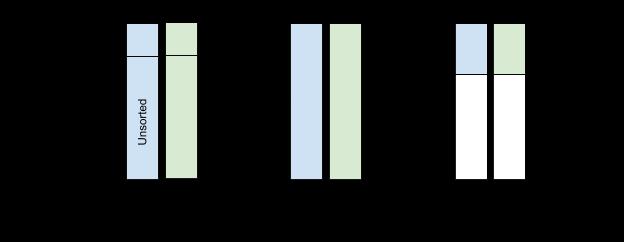
图 12:在表达式求值之后,AresDB 根据维度(键值)和度量(值)向量上的关键值对数据进行排序和归约。
AresDB 还支持以下高级查询功能:
Join:目前 AresDB 支持从事实表到维度表的散列连接
HyperLogLog 基数估计:AresDB 实现的 Hyperloglog 算法
地理相交(Geo Intersect):目前 AresDB 只支持 GeoPoint 和 GeoShape 之间的相交操作
AresDB 作为基于内存的数据库,需要管理以下类型的内存使用:
| 分配者 | 管理模式 | |
|---|---|---|
| 实时存储向量(实时存储列数据) | C | 跟踪式 |
| 归档存储向量(归档存储列数据) | C | 管理式(加载和释放) |
| 主键索引(利用散列表删除重复记录) | C | 跟踪式 |
| 回填队列(存储等待回填的“延迟”到达数据) | Golang | 跟踪式 |
| 归档 / 回填过程临时存储(归档和回填过程汇总分配的临时内存) | C | 跟踪式 |
| 导入 / 查询临时存储;进程开销; 分配碎片化; | Golang 和 C | 静态配置预估 |
当 AresDB 投入生产时,它会利用配置的总内存运算。此预算由所有六种内存类型共享,并且还应为操作系统和其他进程留出充足的空间。此预算还包括静态配置的开销预估、服务器监控的实时数据存储以及服务器可根据剩余内存预算决定加载和释放的归档数据。
下面的图 13 描绘了 AresDB 主机的内存模型:
图 13:AresDB 管理自己的内存使用情况,使其不超过配置的进程总预算。
AresDB 允许用户为事实表在列级别配置预加载的日期和优先级,并且仅在预加载日期内预加载归档数据。非预加载的数据按需从磁盘中加载到内存。一旦内存占满,AresDB 也可以将归档数据从主机内存中清除。AresDB 的释放策略基于预加载天数、列优先级、Batch 日期和列的大小。
AresDB 还管理多个 GPU 设备,建立设备资源模型(如 GPU 线程和设备内存),当处理查询的时候跟踪 GPU 内存的使用情况。AresDB 通过设备管理器管理 GPU 设备,并将 GPU 设备资源划分为两个维度:GPU 线程和设备内存,当处理查询时能够跟踪使用情况。在查询编译之后,AresDB 允许用户估计执行查询所需的资源量。无论在哪台设备上,只有满足内存要求的设备才能够启动查询,如果设备没有足够的内存,则查询必须等待资源满足后执行。目前,AresDB 可以在同一 GPU 设备上同时运行一或多个查询,只要该设备满足所有资源要求。
在目前的实现中,AresDB 不会在设备内存中缓存输入数据,如果缓存下来,则可以在多个查询中重用这些数据。AresDB 的目标是支持针对不断实时更新且难以正确缓存的数据集的查询,我们打算在未来的迭代中实现具有数据缓存功能的 GPU 内存,这一步将有助于优化查询性能。
在 Uber,我们用 AresDB 构建仪表盘来实时提取业务洞察。AresDB 扮演着存储持续更新的新鲜原始数据和用 GPU 低功耗能力在几秒钟内计算针对这些数据的关键指标,从而用户可以交互地使用仪表盘。例如,在数据存储中具有较长寿命的匿名行程数据由多种服务进行更新,包括我们的调度、支付和评级系统。为了有效利用形成数据,用户将数据切分并划分为不同的维度,从而为实时决策获得洞察。
用 AresDB 打造的 Uber 摘要仪表盘是一个广泛使用的分析仪表盘,公司的各个团队会用它来检索相关的产品指标,并实时响应来提高用户体验。
图 14:Uber 摘要仪表盘按小时呈现的视图用 AresDB 查看特定时间段的实时数据分析。
为了构建上面的模拟仪表盘,我们对以下的表进行建模:
Trips(事实表)
| trip_id | request_at | city_id | status | driver_id | fare |
|---|---|---|---|---|---|
| 1 | 1542058870 | 1 | completed | 2 | 8.5 |
| 2 | 1541977200 | 1 | rejected | 3 | 10.75 |
| … |
Cities(维度表)
| city_id | city_name | timezone |
|---|---|---|
| 1 | San Francisco | America/Los_Angeles |
| 2 | New York | America/New_York |
| … |
要创建上述两个建模表,我们首先需要在 AresDB 中按照以下 Schema 创建表:
| Trips | Cities |
|---|---|
| { “name”: “trips”, “columns”: [ { “name”: “request_at”, “type”: “Uint32”, }, { “name”: “trip_id”, “type”: “UUID” }, { “name”: “city_id”, “type”: “Uint16”, }, { “name”: “status”, “type”: “SmallEnum”, }, { “name”: “driver_id”, “type”: “UUID” }, { “name”: “fare”, “type”: “Float32”, } ], “primaryKeyColumns”: [ 1 ], “isFactTable”: true, “config”: { “batchSize”: 2097152, “archivingDelayMinutes”: 1440, “archivingIntervalMinutes”: 180, “recordRetentionInDays”: 30 }, “archivingSortColumns”: [2,3]} | { “name”: “cities”, “columns”: [ { “name”: “city_id”, “type”: “Uint16”, }, { “name”: “city_name”, “type”: “SmallEnum” }, { “name”: “timezone”, “type”: “SmallEnum”, } ], “primaryKeyColumns”: [ 0 ], “isFactTable”: false, “config”: { “batchSize”: 2097152 }} |
如 Schema 中所述,Trips 表被创建为事实表,表示事实发生的行程事件,而 Cities 表被创建为维度表,存储有关城市的信息。
创建表之后,用户可以利用 AresDB 客户端库 从事件总线(如 Apache Kafka)或流式或 Batch 平台(如 Apache Flink 或 Apache Spark)中获取数据。
在模拟仪表盘中,我们选择两个指标作为示例:行程总价和活跃司机。在仪表盘中,用户可以按城市指标过滤数据,例如:旧金山(San Francisco)。为了在仪表盘上显示过去 24 小时这两个指标的时间序列,我们可以在 AQL 中运行以下查询:
| 过去 24 小时中旧金山总行程费用(按小时) | 过去 24 小时中旧金山活跃司机数(按小时) |
|---|---|
| { “table”: “trips”, “joins”: [ { “alias”: “cities”, “name”: “cities”, “conditions”: [ “cities.id = trips.city_id” ] } ], “dimensions”: [ { “sqlExpression”: “request_at”, “timeBucketizer”: “hour” } ], “measures”: [ { “sqlExpression”: “sum(fare)” } ], “rowFilters”: [ “status = ‘completed'”, “cities.city_name = ‘San Francisco'” ], “timeFilter”: { “column”: “request_at”, “from”: “24 hours ago” }, “timezone”: “America/Los_Angeles”} | { “table”: “trips”, “joins”: [ { “alias”: “cities”, “name”: “cities”, “conditions”: [ “cities.id = trips.city_id” ] } ], “dimensions”: [ { “sqlExpression”: “request_at”, “timeBucketizer”: “hour” } ], “measures”: [ { “sqlExpression”: “countDistinctHLL(driver_id)” } ], “rowFilters”: [ “status = ‘completed'”, “cities.city_name = ‘San Francisco'” ], “timeFilter”: { “column”: “request_at”, “from”: “24 hours ago” }, “timezone”: “America/Los_Angeles”} |
查询的示例结果:
上述模拟查询将在以下时间序列结果中产生结果,这些结果可以很容易地绘制成时间序列图,如下所示:
| 过去 24 小时中旧金山总行程费用(按小时) | 过去 24 小时中旧金山活跃司机数(按小时) |
|---|---|
| { “results”: [ { “1547060400”: 1000.0, “1547064000”: 1000.0, “1547067600”: 1000.0, “1547071200”: 1000.0, “1547074800”: 1000.0, … } ]} | { “results”: [ { “1547060400”: 100, “1547064000”: 100, “1547067600”: 100, “1547071200”: 100, “1547074800”: 100, … } ]} |
在上面的示例中,我们演示了如何利用 AresDB 在几秒钟内实时导入实时发生的原始事件,并立即针对数据发起任意的用户查询,从而在亚秒内计算指标。AresDB 帮助工程师轻松构建数据产品来提取对企业至关重要的指标,员工或机器可以通过这些指标做出具有实时洞察能力的决策。
AresDB 在 Uber 被广泛使用,为我们的实时数据分析仪表盘提供支持,使我们能够针对业务的各个方面大规模制定数据驱动的决策。通过开源这个工具,我们希望社区中的其他人可以利用 AresDB 分析自己的数据。
未来,我们打算通过以下功能来赋能这个项目:
分布式设计:我们正在构建 AresDB 的分布式设计,包括复制集(Replication)、分片(Sharding)管理以及 Schema 管理,从而提高 AresDB 的可伸缩性并降低运营成本。
开发者支持和工具:自 2018 年 11 月开源 AresDB 以来,我们一直致力于构建更直观的工具,重构代码结构,丰富文档,提高初次使用的体验,使开发者能够快速将 AresDB 集成到他们的分析工具栈中。
扩展功能集:我们还计划扩展查询功能集,包括窗口函数(Window Function)和嵌套循环连接(Nested Loop Join)等功能,从而让 AresDB 可以支持更多使用场景。
查询引擎优化:我们还将研究开发更先进的方法来优化查询性能,例如:底层虚拟机(LLVM) 和 GPU 内存缓存。
特别感谢 Kate Zhang、Jennifer Anderson、Nikhil Joshi、Abhi Khune、Shengyue Ji、Chinmay Soman、Xiang Fu、David Chen 还有 Li Ning,是你们让这个项目取得了巨大的成功!
查看英文原文:
https://eng.uber.com/aresdb/
今日荐文
6天面试斩获6家硅谷巨头Offer,我是如何做到的?
喜欢这篇文章吗?点一下「好看」再走 以上是关于为什么已有Elasticsearch,我们还要重造实时分析引擎AresDB?的主要内容,如果未能解决你的问题,请参考以下文章 TCP已有SO_KEEPALIVE参数,为什么还要在应用层加入心跳?