统一ElasticsearchMySQLHive的SQL查询引擎,我们把它开源了!
Posted InfoQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了统一ElasticsearchMySQLHive的SQL查询引擎,我们把它开源了!相关的知识,希望对你有一定的参考价值。
作者 | 刘思源
编辑 | Natalie
那么面对这些问题,360 是如何构建高效统一的 SQL 查询引擎呢?以下内容来自 ArchSummit 全球架构师峰会 奇虎 360 大数据中心资深研发工程师 刘思源的演讲内容整理,以飨读者。
360 内部有很多业务线,除了大家平时熟知的 PC 安全卫士、360 浏览器、360 搜索以及移动端的手机卫士等应用软件之外,还有很多其他领域的业务产品。下图为整个公司从资产角度呈现出的业务线概况。
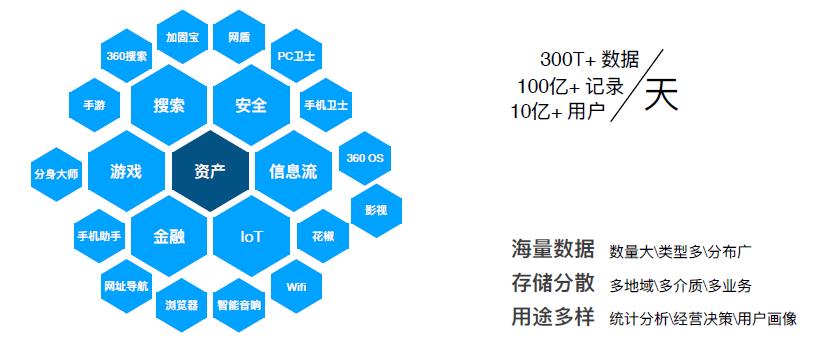
从图中可以看到,公司内业务方向主要分为搜索、安全、视频信息流、游戏、金融和 IoT 六个领域,以这些领域为核心由向外衍生出诸多产品,这些产品每日新增打点数据 300T+,换算后有接近 100 亿 + 条记录,覆盖用户数达到 10 亿 +。由于业务对数据的使用场景在时延和量级上有不同的需求,所以数据往往分散存储在诸多存储介质上,在进行数据产出时需要抽取合并不同介质的数据,以公司内部场景为例。
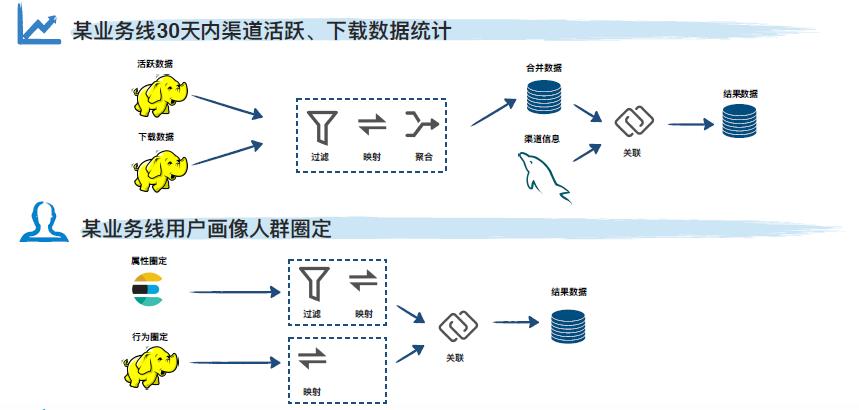
某业务线要处理一定周期内各渠道活跃、下载数据的指标,由于渠道信息数据量较小,且往往会涉及频繁增删改,这部分数据通常存放于 mysql 中,而用户的活跃下载数据实时打点写入,最终会落地 HDFS,一旦两部分数据需要关联分析时流程通常很冗长,对于业务人员而言处理难度较高。此外,在用户画像的场景下,由于行为数据和属性数据处于异构数据源,业务人员也会面临类似的问题,导致处理数据的效能低下。
针对业务痛点进行深入分析后,我们发现:数据分析人员的技能树通常向两个方向发展,一类是技术型,Spark、Flink 信手拈来,Python、R 语言一日千行,他们对业务和数据的理解可能不深入,但他们一定懂得怎样快速清洗加工数据;另一类是业务型,线性回归、残差网络各类算法应用自如,方差期望、概率分布准确求解,他们对技术栈的了解可能不完备,但他们可以从海量数据中抓出关键的信息打动老板。
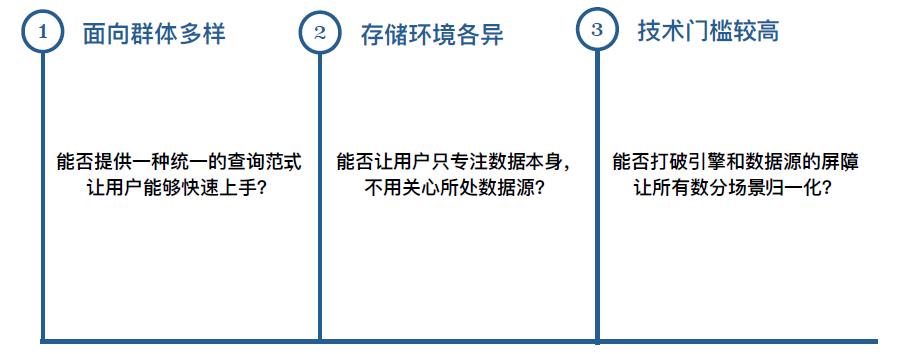
然而,日趋复杂的数据分析场景逐步提升了处理数据的难度,如果底层数据处理平台无法跟随场景进行演进,业务会陷入数据加工细节,导致产品迭代速度变缓,最终湮没在互联网快速迭代的大潮中。
因此,我们考虑对外提供统一的查询范式,屏蔽底层数据源和操作细节,让业务人员摆脱加工数据的技术束缚,不论是对成本控制还是效率提升都是一本万利的事情。

对于统一查询的场景,我们参考了业界已有的引擎,调研发现:受限于当下计算体系结构,每一种引擎都存在优劣势。面临选择的场景,我们考虑使用动态调度的思想,使用 Apache Calcite 作为上层解析器,通过多一次解析搞清楚用户的查询意图,再向对应引擎解释路由,让合适的引擎做合适的事儿。
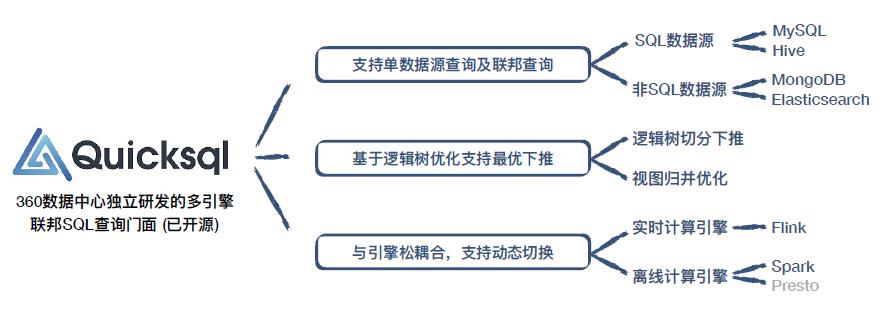
QuickSQL 是我组自行研发的开源多引擎联邦查询门面,对外提供统一标准的 SQL,针对联邦查询进行了逻辑树级别优化,与引擎完全解耦合,可在运行时动态选取引擎执行。业务通过统一的 SQL 门面,能够处理各类复杂的数据加工场景。其基础架构如下:
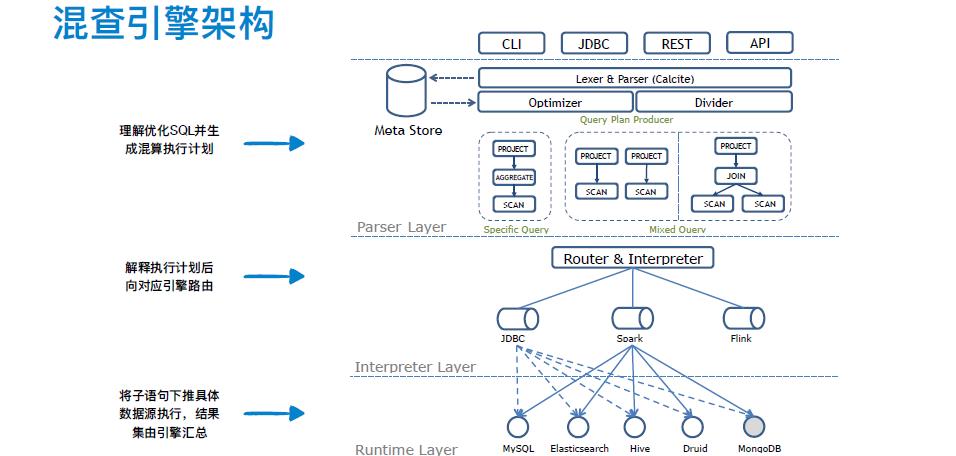
QuickSQL 对外提供多种接口,用户可以直接通过 CLI 进行分析,也可以在平台中通过其他接口进行远程调用。
整体架构包含三层:解析层,解释层和运行时层。
解析层主要通过与元数据库交互进行语句解析和校验,结合独立的权限系统,可以在校验时进行表和字段级别的权限判断。解析生成的逻辑计划会经历联邦查询优化和逻辑树切分。切分后的逻辑子树由解释层进行方言解释和语句路由。对于特定源的查询直接由 JDBC 完成,混查场景则借助 Spark 或 Flink 作为分布式计算中间引擎进行数据周转处理。运行时层提供了下推语句的预聚合及抽取计算。
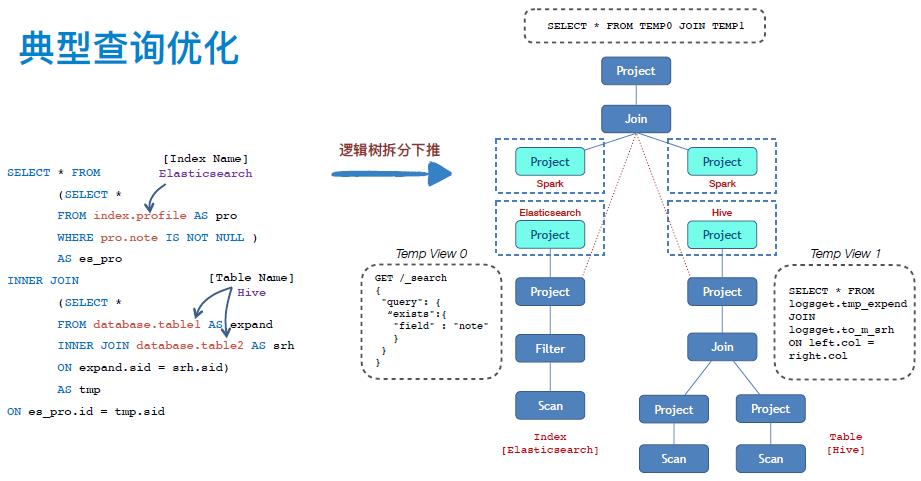
以上图中混查场景为例,语句包含两张同库 Hive 表,一份 Elasticsearch 的 index。
经过词法语法分析后,生成右图虚线连接的原始逻辑计划树,在联邦查询优化场景下,针对这棵不寻常的逻辑树进行分析优化,采用后序遍历的方式,根据定义好的切点类型在指定位置进行切分。
切点的类型包含:1. 跨数据源,跨库的关联或子查询;2. 数据源不支持的操作和函数。
切分后再向切点处补足相对应节点使各逻辑计划整体完整, 经过切分后的逻辑计划会成为计划森林,包含一个父计划和多个子计划,针对每个逻辑计划再向相应数据源的方言进行转换,由中间计算引擎的临时表查询能力进行数据汇总和再加工。
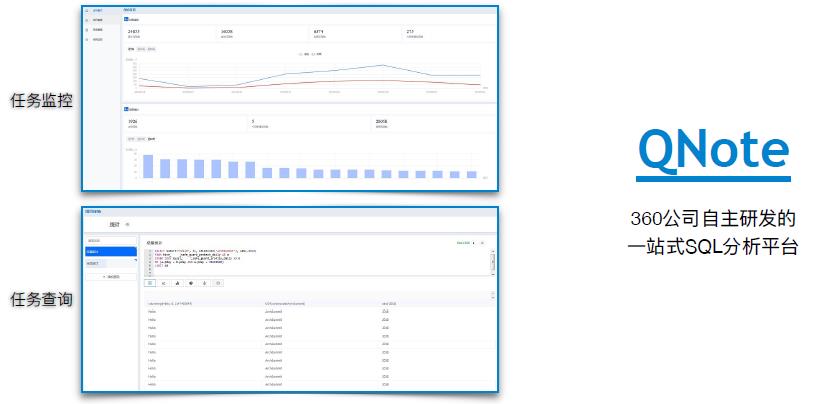
QNote 是数据中心基于统一 SQL 查询引擎开发的交互式分析平台,主要面向数据分析、产品、运营和开发人员,通过统一的 SQL 语法对各类数据源包括 Hive、MySQL、Elasticsearch 等进行查询,基于底层查询引擎 QuickSQL,用户还可以进行跨源、跨库关联查询,甚至可以二次导入 CSV 文本与其他数据源进一步关联分析,能够覆盖绝大多数查询分析场景。
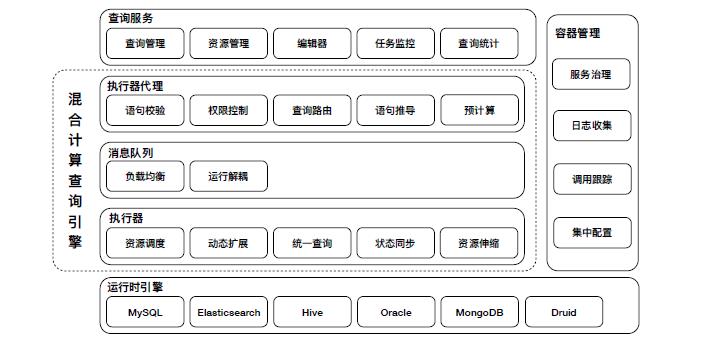
QNote 的业务架构图如上,主要包含三层:查询服务层,混合计算层,运行时层。
查询服务层主要提供用户侧与查询交互相关的功能,包括查询管理、监控大盘、编辑器、订阅服务及例行化调度等。
混合计算层主要分为两部分,一部分为执行器代理,主要对查询服务提供 SDK,帮助外部服务理解 SQL,并进行初步校验。另一部分为执行器,主要针对用户大批量的查询进行资源调度,统一解析,和状态同步等。两部分由中间消息队列作衔接,达成负载均衡和双向解耦。
运行时层包含所有接入联邦查询的数据源,各数据源提供语句的下推执行和结果抽取。
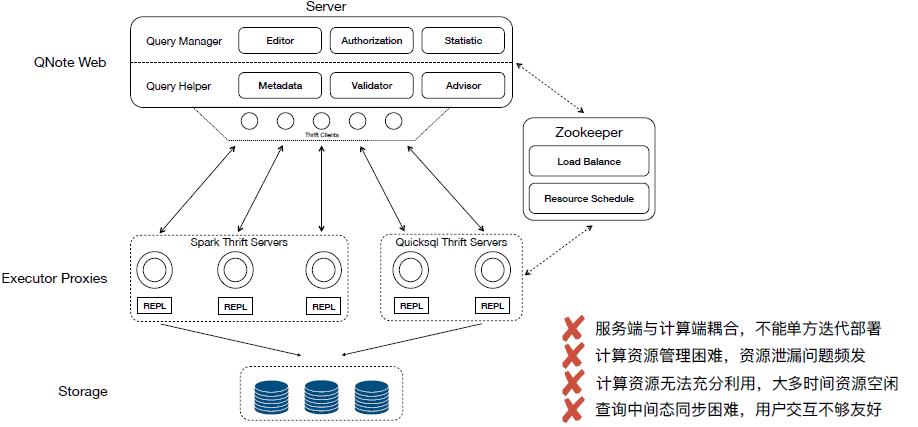
初版的 QNote 架构设计参考了 Zeppelin 模式,整体结构为基于 Thrift RPC 长连接的查询处理方式,主体分为两部分,查询服务和执行器代理,双方由 Zookeeper 提供负载均衡。
查询服务主要提供查询管理,语句校验推导等。执行器代理集成了 QuickSQL 统一查询能力,对外提供标准化 SQL 查询支持,每个用户对应一条 3 小时租约的查询连接。通过在多客户端部署并向 Zookeeper 同步并发量做到对大量查询的分流。
这样的结构看似简单直接,但在实际生产环境中遇到很多问题,诸如:部署困难,资源易泄漏,资源利用率低,查询并行度差,服务端无法扩展等等。面对种种问题,开发人员开始琢磨系统重构,针对性能、可用性和扩展性三方面进行调整。

旧版架构的核心问题在于双端耦合过紧,无法横向扩展,其他问题均为此问题的衍生。于是考虑通过引入消息队列一招制敌,将服务端计算端解耦,让查询能够完全并行。此外借助消息队列提供的具备 Rebalance 机制的发布 - 订阅模式,可以让计算端轻松达成高可用,甚至计算端可以自行调度资源,达到开源节流的目的。
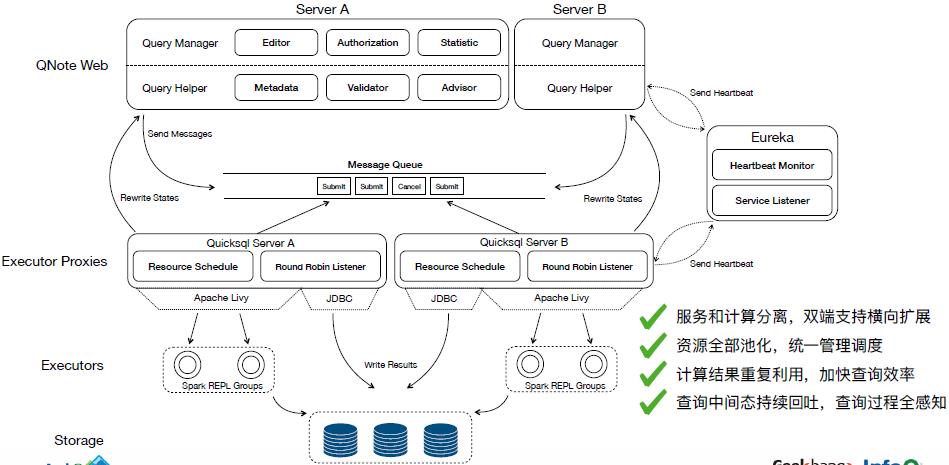
经历重构后的系统架构如上,查询服务,消息队列和执行器代理三部分共同支撑整个交互式查询平台,查询服务与执行器的交互间接通过向队列投掷 SUBMIT,CANCEL 消息来完成,由执行器代理拉取消息并调度资源进行处理,结果集回写公共存储。
此外,双端都会注册至 Eureka,由 Eureka 对多实例进行心跳检测。该架构基本解决了之前遇到的问题,达成服务与计算分离,查询全并行,资源充分利用等目的。
上面四张图展示了 QuickSQL 统一查询的性能比较,由于 QuickSQL 会牺牲一次解析的时间辅助查询,所以在 MySQL 和 Elasticsearch 的查询中会慢 0.5 s,在 Hive 查询中由于底层使用了 Spark-Hive 作引擎,因此性能会稍优于 Hive 原生查询。
最后一张图展示了在混查场景下的性能比较,可以看到在处理 MySQL 和 Elasticsearch 的关联查询时,由于数据源自身具备索引,QuickSQL 能够充分利用数据源本身的能力实现下推执行,性能会远远优于 Hive 数据源与其他数据源在同等规模数据下关联的性能。
QuickSQL 统一查询下阶段开发将主要关注以下几方面:
-
接入流式 SQL 场景,将离线数据和流式数据的处理范式归一化。 -
丰富 SQL 操作语法,引入 UDF,构建更完善的查询引擎。 -
接入 MongoDB 和 Druid 等常见数据源,满足更多查询场景。 -
提供更为丰富的应用接入方式,引导应用快速接入。
希望感兴趣的朋友可以一起参与开发讨论。
https://github.com/Qihoo360/Quicksql
演讲嘉宾介绍:
刘思源,奇虎 360 大数据中心资深研发工程师,现负责交互式查询平台和数据联邦查询引擎的设计和研发,对大数据计算平台和微服务有深入研究。见证了 360 大数据平台从无到有,从单一到生态,从集成到服务化的演化过程。致力于推动 SQL 在大数据平台中多种场景的落地,Apache Calcite 贡献者。
点个在看少个 bug 以上是关于统一ElasticsearchMySQLHive的SQL查询引擎,我们把它开源了!的主要内容,如果未能解决你的问题,请参考以下文章