分布式系统如何设计?看Elasticsearch是怎么做的
Posted 51CTO技术栈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式系统如何设计?看Elasticsearch是怎么做的相关的知识,希望对你有一定的参考价值。
分布式系统类型多,涉及面非常广,不同类型的系统有不同的特点,批量计算和实时计算就差别非常大。
图片来自 Pexels
这篇文章会重点讨论分布式数据系统的设计,比如分布式存储系统,分布式搜索系统,分布式分析系统等。我们先来简单看下 Elasticsearch 的架构。
Elasticsearch 集群架构
Elasticsearch 是一个非常著名的开源搜索和分析系统,目前被广泛应用于互联网多种领域中。
尤其是以下三个领域特别突出:
搜索领域,相对于 Solr,真正的后起之秀,成为很多搜索系统的不二之选。
Json 文档数据库,相对于 MongoDB,读写性能更佳,而且支持更丰富的地理位置查询以及数字、文本的混合查询等。
时序数据分析处理,目前在日志处理、监控数据的存储、分析和可视化方面做得非常好,可以说是该领域的引领者了。
Elasticsearch 的详细介绍可以到官网查看。我们先来看一下 Elasticsearch 中几个关键概念:
节点(Node):物理概念,一个运行的 Elasticsearch 实例,一般是一台机器上的一个进程。
索引(Index):逻辑概念,包括配置信息 Mapping 和倒排正排数据文件,一个索引的数据文件可能会分布于一台机器,也有可能分布于多台机器。索引的另外一层意思是倒排索引文件。
分片(Shard):为了支持更大量的数据,索引一般会按某个维度分成多个部分,每个部分就是一个分片,分片被节点(Node)管理。
一个节点(Node)一般会管理多个分片,这些分片可能是属于同一份索引,也有可能属于不同索引,但是为了可靠性和可用性,同一个索引的分片尽量会分布在不同节点(Node)上。分片有两种,主分片和副本分片。
副本(Replica):同一个分片(Shard)的备份数据,一个分片可能会有 0 个或多个副本,这些副本中的数据保证强一致或最终一致。
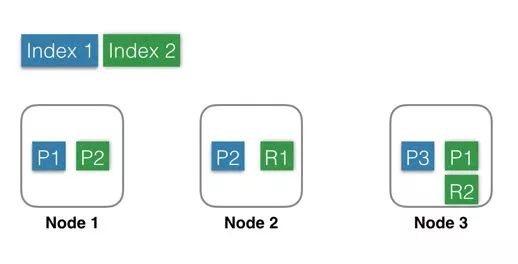
Index 1:蓝色部分,有 3 个 Shard,分别是 P1,P2,P3,位于 3 个不同的 Node 中,这里没有 Replica。
Index 2:绿色部分,有 2 个 Shard,分别是 P1,P2,位于 2 个不同的 Node 中。并且每个 Shard 有一个 Replica,分别是 R1 和 R2。
基于系统可用性的考虑,同一个 Shard 的 Primary 和 Replica 不能位于同一个 Node 中。
这里 Shard1 的 P1 和 R1 分别位于 Node3 和 Node2 中,如果某一刻 Node2 发生宕机,服务基本不会受影响,因为还有一个 P1 和 R2 都还是可用的。
因为是主备架构,当主分片发生故障时,需要切换,这时候需要选举一个副本作为新主,这里除了会耗费一点点时间外,也会有丢失数据的风险。
Index 流程
角色部署方式
接下来再看看角色分工的两种不同方式:
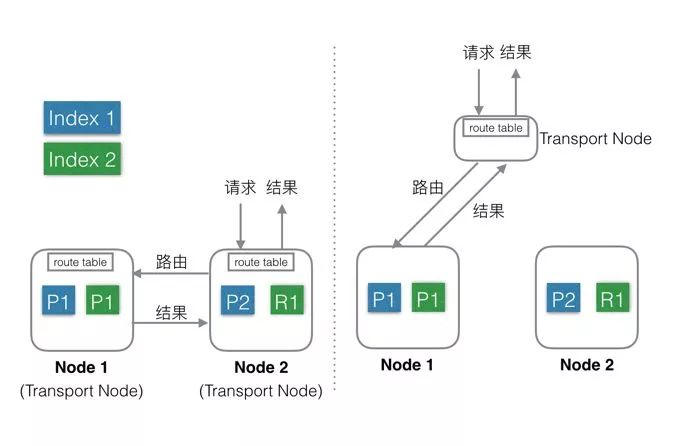
混合部署
分层部署
默认方式。
不考虑 MasterNode 的情况下,还有两种 Node,Data Node 和 Transport Node。
这种部署模式下,这两种不同类型 Node 角色都位于同一个 Node 中,相当于一个 Node 具备两种功能:Data 和 Transport。
当有 Index 或者 Query 请求的时候,请求随机(自定义)发送给任何一个 Node。
这台 Node 中会持有一个全局的路由表,通过路由表选择合适的 Node,将请求发送给这些 Node,然后等所有请求都返回后,合并结果,然后返回给用户。一个 Node 分饰两种角色。
好处就是使用极其简单,易上手,对推广系统有很大价值。最简单的场景下只需要启动一个 Node,就能完成所有的功能。
缺点就是多种类型的请求会相互影响,在大集群如果某一个 Data Node 出现热点,那么就会影响途经这个 Data Node 的所有其他跨 Node 请求。如果发生故障,故障影响面会变大很多。
Elasticsearch 中每个 Node 都需要和其余的每一个 Node 都保持 13 个连接。
这种情况下,每个 Node 都需要和其他所有 Node 保持连接,而一个系统的连接数是有上限的,这样连接数就会限制集群规模。
还有就是不能支持集群的热更新。
通过配置可以隔离开 Node。
设置部分 Node 为 Transport Node,专门用来做请求转发和结果合并。
其他 Node 可以设置为 Data Node,专门用来处理数据。
缺点是上手复杂,需要提前设置好 Transport 的数量,且数量和 Data Node、流量等相关,否则要么资源闲置,要么机器被打爆。
好处就是角色相互独立,不会相互影响,一般 Transport Node 的流量是平均分配的,很少出现单台机器的 CPU 或流量被打满的情况。
而 Data Node 由于处理数据,很容易出现单机资源被占满,比如 CPU,网络,磁盘等。
独立开后,DataNode 如果出了故障只是影响单节点的数据处理,不会影响其他节点的请求,影响限制在最小的范围内。
角色独立后,只需要 Transport Node 连接所有的 Data Node,而 Data Node 则不需要和其他 Data Node 有连接。
一个集群中 Data Node 的数量远大于 Transport Node,这样集群的规模可以更大。
另外,还可以通过分组,使 Transport Node 只连接固定分组的 Data Node,这样 Elasticsearch 的连接数问题就彻底解决了。
可以支持热更新:先一台一台的升级 Data Node,升级完成后再升级 Transport Node,整个过程中,可以做到让用户无感知。
Elasticsearch 数据层架构
数据存储
副本(Replica)
保证服务可用性:当设置了多个 Replica 的时候,如果某一个 Replica 不可用的时候,那么请求流量可以继续发往其他 Replica,服务可以很快恢复开始服务。
保证数据可靠性:如果只有一个 Primary,没有 Replica,那么当 Primary 的机器磁盘损坏的时候,那么这个 Node 中所有 Shard 的数据会丢失,只能 Reindex 了。
提供更大的查询能力:当 Shard 提供的查询能力无法满足业务需求的时候, 可以继续加 N 个 Replica,这样查询能力就能提高 N 倍,轻松增加系统的并发度。
问题
Replica 带来成本浪费。为了保证数据可靠性,必须使用 Replica,但是当一个 Shard 就能满足处理能力的时候,另一个 Shard 的计算能力就会浪费。
Replica 带来写性能和吞吐的下降。每次 Index 或者 Update 的时候,需要先更新 Primary Shard,更新成功后再并行去更新 Replica,再加上长尾,写入性能会有不少的下降。
当出现热点或者需要紧急扩容的时候动态增加 Replica 慢。新 Shard 的数据需要完全从其他 Shard 拷贝,拷贝时间较长。
分布式系统
基于本地文件系统的分布式系统
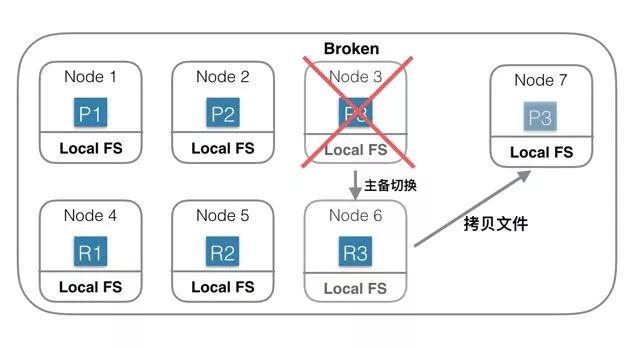
基于分布式文件系统的分布式系统
在这种架构下,资源可以更加弹性,当存储不够的时候只需要扩容存储系统的容量;当计算不够的时候,只需要扩容计算部分容量。
存储和计算是独立管理的,资源管理粒度更小,管理更加精细化,浪费更少,结果就是总体成本可以更低。
负载更加突出,抗热点能力更强。一般热点问题基本都出现在计算部分,对于存储和计算分离系统,计算部分由于没有绑定数据,可以实时的扩容、缩容和迁移,当出现热点的时候,可以第一时间将计算调度到新节点上。
总结
编辑:陶家龙、孙淑娟
出处:https://zhuanlan.zhihu.com/p/32990496
精彩文章推荐:
以上是关于分布式系统如何设计?看Elasticsearch是怎么做的的主要内容,如果未能解决你的问题,请参考以下文章