浅谈ElasticSearch架构以及集成
Posted 简栈文化
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅谈ElasticSearch架构以及集成相关的知识,希望对你有一定的参考价值。
简介
Elasticsearch是一个高度可扩展的开源的分布式Restful全文搜索和分析引擎。它允许用户快速的(近实时的)存储、搜索和分析海量数据。它通常用作底层引擎技术,为具有复杂搜索功能和要求的应用程序提供支持。以下是ES可用于的一些场景:
-
电商网站提供搜索功能:可使用 ES来存储产品的目录和库存,并为它们提供搜索和自动填充建议。 -
收集日志和交易数据,并进行分析:可使用 Logstash来收集、聚合和解析数据, 然后让Logstash将此数据提供给ES。然后可在ES中搜索和聚合开发者感兴趣的信息。 -
需要快速调查、分析、可视化查询大量数据的特定问题:可以使用ES存储数据,然后使用 Kibana构建自定义仪表板,来可视化展示数据。还可以使用ES的聚合功能针对这些数据进行复杂的商业分析。
我们要认识一个人Doug Cutting
为什么要提Doug Cutting,因为Elasticsearch的底层是Lucene,而Lucene就是Doug Cutting大神写的。
引用来自于:鲜枣课堂
1998年9月4日,Google公司在美国硅谷成立。正如大家所知,它是一家做搜索引擎起家的公司。
http://static.cyblogs.com/640.jpg 无独有偶,一位名叫Doug Cutting的美国工程师,也迷上了搜索引擎。他做了一个用于文本搜索的函数库(姑且理解为软件的功能组件),命名为Lucene。

http://static.cyblogs.com/pUm6Hxkd434Mk1VTAruKa8.jpg 左为Doug Cutting,右为Lucene的LOGO
Lucene是用JAVA写成的,目标是为各种中小型应用软件加入全文检索功能。因为好用而且开源(代码公开),非常受程序员们的欢迎。
早期的时候,这个项目被发布在Doug Cutting的个人网站和SourceForge(一个开源软件网站)。后来,2001年底,Lucene成为Apache软件基金会jakarta项目的一个子项目。

http://static.cyblogs.com/iaqYeVeXiaLwMxssVyfyV0f69tfVMod6.jpg Apache软件基金会,搞IT的应该都认识
2004年,Doug Cutting再接再励,在Lucene的基础上,和Apache开源伙伴Mike Cafarella合作,开发了一款可以代替当时的主流搜索的开源搜索引擎,命名为Nutch。

http://static.cyblogs.com/aqYeVeXiaLwMxssV.png Nutch是一个建立在Lucene核心之上的网页搜索应用程序,可以下载下来直接使用。它在Lucene的基础上加了网络爬虫和一些网页相关的功能,目的就是从一个简单的站内检索推广到全球网络的搜索上,就像Google一样。
Nutch在业界的影响力比Lucene更大。
大批网站采用了Nutch平台,大大降低了技术门槛,使低成本的普通计算机取代高价的Web服务器成为可能。甚至有一段时间,在硅谷有了一股用Nutch低成本创业的潮流。
随着时间的推移,无论是Google还是Nutch,都面临搜索对象“体积”不断增大的问题。
尤其是Google,作为互联网搜索引擎,需要存储大量的网页,并不断优化自己的搜索算法,提升搜索效率。

http://static.cyblogs.com/TAruKa8WKbr3qDia9ba.jpg Google搜索栏
在这个过程中,Google确实找到了不少好办法,并且无私地分享了出来。
2003年,Google发表了一篇技术学术论文,公开介绍了自己的谷歌文件系统GFS(Google File System)。这是Google公司为了存储海量搜索数据而设计的专用文件系统。
第二年,也就是2004年,Doug Cutting基于Google的GFS论文,实现了分布式文件存储系统,并将它命名为NDFS(Nutch Distributed File System)。
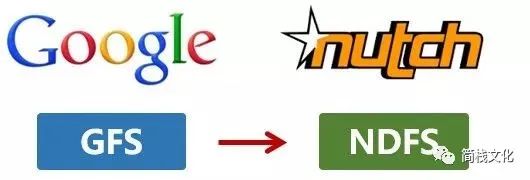
http://static.cyblogs.com/google_gfs_ndfs.jpg 还是2004年,Google又发表了一篇技术学术论文,介绍自己的MapReduce编程模型。这个编程模型,用于大规模数据集(大于1TB)的并行分析运算。
第二年(2005年),Doug Cutting又基于MapReduce,在Nutch搜索引擎实现了该功能。
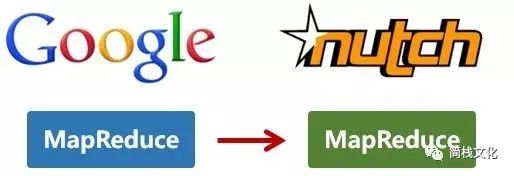
http://static.cyblogs.com/goole_mapreduce.jpg 2006年,当时依然很厉害的Yahoo(雅虎)公司,招安了Doug Cutting。

http://static.cyblogs.com/goole_mapreduce_002.jpg 这里要补充说明一下雅虎招安Doug的背景:2004年之前,作为互联网开拓者的雅虎,是使用Google搜索引擎作为自家搜索服务的。在2004年开始,雅虎放弃了Google,开始自己研发搜索引擎。所以。。。
加盟Yahoo之后,Doug Cutting将NDFS和MapReduce进行了升级改造,并重新命名为Hadoop(NDFS也改名为HDFS,Hadoop Distributed File System)。
这个,就是后来大名鼎鼎的大数据框架系统——Hadoop的由来。而Doug Cutting,则被人们称为Hadoop之父。

http://static.cyblogs.com/goole_mapreduce_003.jpg Hadoop这个名字,实际上是Doug Cutting他儿子的黄色玩具大象的名字。所以,Hadoop的Logo,就是一只奔跑的黄色大象。

http://static.cyblogs.com/goole_mapreduce_004.jpg 我们继续往下说。
还是2006年,Google又发论文了。
这次,它们介绍了自己的BigTable。这是一种分布式数据存储系统,一种用来处理海量数据的非关系型数据库。
Doug Cutting当然没有放过,在自己的hadoop系统里面,引入了BigTable,并命名为HBase。
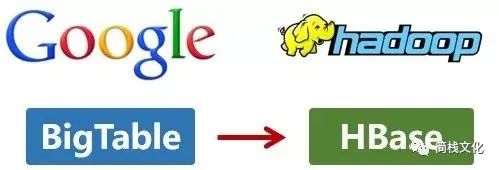
http://static.cyblogs.com/goole_mapreduce_005.jpg 好吧,反正就是紧跟Google时代步伐,你出什么,我学什么。
所以,Hadoop的核心部分,基本上都有Google的影子。
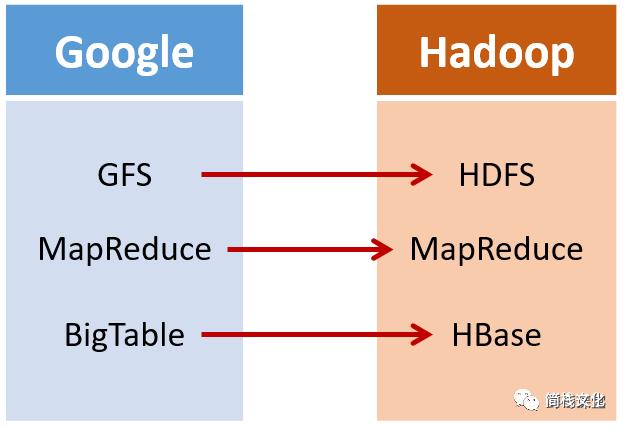
http://static.cyblogs.com/goole_mapreduce_006.png
其实从这里也能看到,站在巨人肩膀上或者仿照强者,也可以走出一条属于自己的道路。
安装Elasticsearch
➜ Tools brew search elasticsearch
==> Formulae
elasticsearch elasticsearch@2.4 elasticsearch@5.6
➜ Tools brew install elasticsearch@5.6
==> Downloading https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-5.6.16.tar.gz
######################################################################## 100.0%
Warning: elasticsearch@5.6 has been deprecated!
==> Caveats
Data: /usr/local/var/elasticsearch/elasticsearch_chenyuan/
Logs: /usr/local/var/log/elasticsearch/elasticsearch_chenyuan.log
Plugins: /usr/local/opt/elasticsearch@5.6/libexec/plugins/
Config: /usr/local/etc/elasticsearch/
plugin script: /usr/local/opt/elasticsearch@5.6/libexec/bin/elasticsearch-plugin
elasticsearch@5.6 is keg-only, which means it was not symlinked into /usr/local,
because this is an alternate version of another formula.
If you need to have elasticsearch@5.6 first in your PATH run:
echo 'export PATH="/usr/local/opt/elasticsearch@5.6/bin:$PATH"' >> ~/.zshrc
To have launchd start elasticsearch@5.6 now and restart at login:
brew services start elasticsearch@5.6
Or, if you don't want/need a background service you can just run:
/usr/local/opt/elasticsearch@5.6/bin/elasticsearch
==> Summary
以上是关于浅谈ElasticSearch架构以及集成的主要内容,如果未能解决你的问题,请参考以下文章