高效搜索引擎ElasticSearch实战篇
Posted CodeApi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了高效搜索引擎ElasticSearch实战篇相关的知识,希望对你有一定的参考价值。
elasticsearch是什么?
Elasticsearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。
elasticsearch能做什么?
简单的说像一些电商的商品搜索(淘宝、天猫等),就需要用到elasticsearch去搜索商品,为什么不直接去数据库查询,还要多使用一个elasticsearch那?因为一般电商平台的商品数量都是巨大的,如果我们直接从数据库查询那么效率就会很低严重影响用户的使用体验,使用elastic search搜索引擎能够达到实时搜索,稳定,可靠,快速。
那接下来就让我们来学习怎么使用elastic search吧。
下载elasticsearch
https://www.elastic.co/cn/downloads/elasticsearch
这里我们下载windows版本的,大家也可以下载Linux版本进行安装。
下载完成后我们将其解压。

点击加压后的文件夹进入bin目录,然后点击elasticsearch.bat启动elastic search。
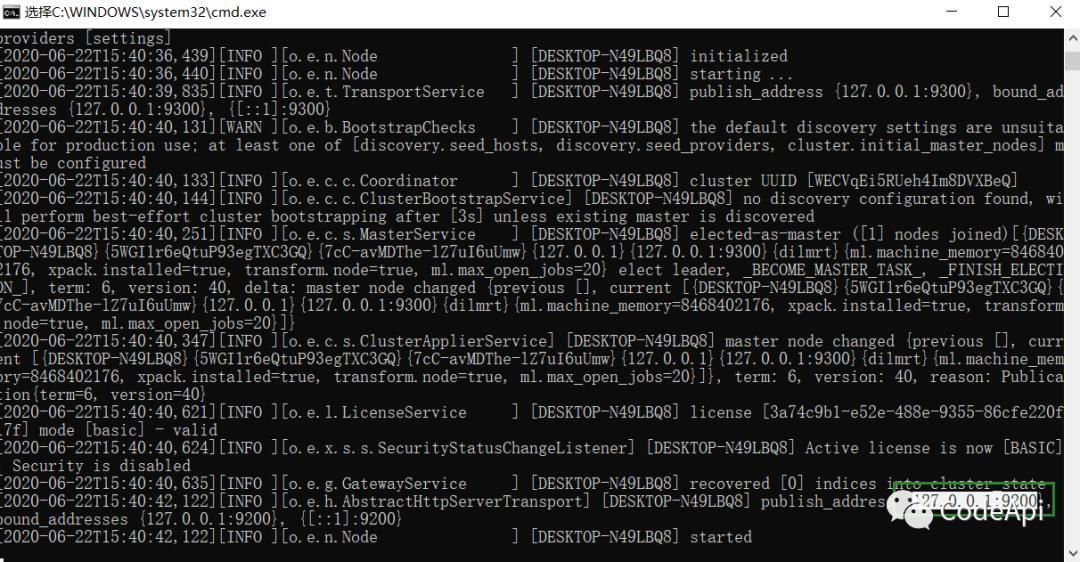
启动后的界面
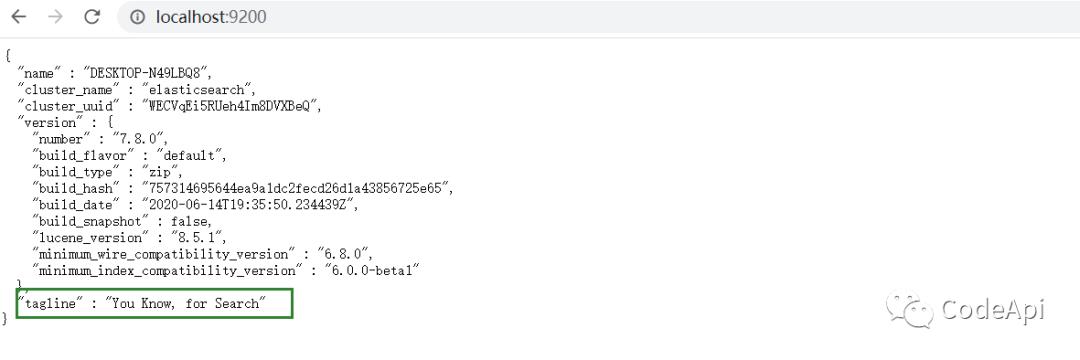
elastic search默认是不带可视化界面工具的,因此我们需要安装一个图形界面插件(elastic-search-head-master),就像我们安装navcat去操作mysql数据库一样。
这是一个git项目大家点击下载就行。
下载完成后是一个压缩包,我们把它移到和elasticsearch同一个目录,并解压。
进入这个文件夹可以看到这是一个前端项目,我们在路径栏中输入cmd打开命令窗口。
输入cnpm install命令安装项目需要的jar包(也可以使用npm命令,这里使用阿里云cnpm下载会很快),这里的npm命令是node.js的包管理命令(类似maven的功能),不了解的同学可以先去看一下node.js的基本知识。
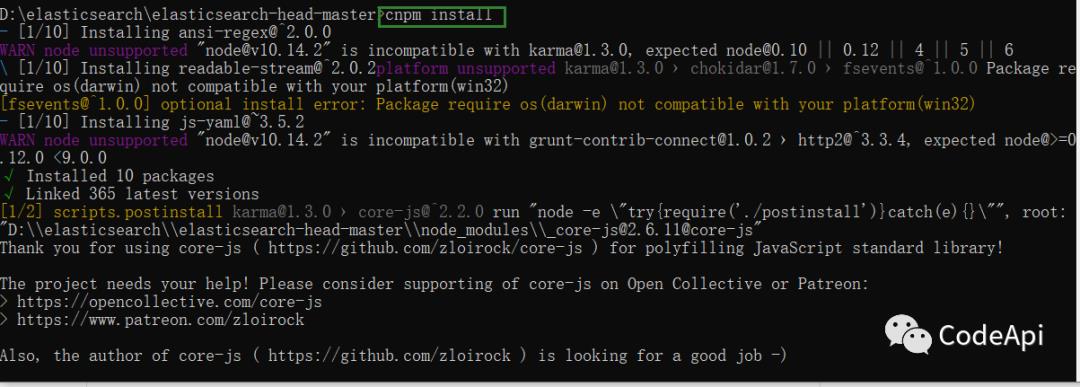
依赖的jar包下载完成后就可以启动项目了,我们输入 npm install start 启动项目。
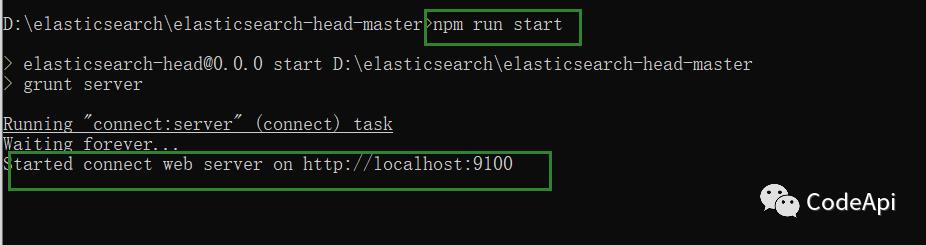

此时我们点击各个按钮会发现没有反应,按f12查看控制台发现报错(跨域问题),因为elasticsearch和这个项目是两个项目,所以存在跨域问题。
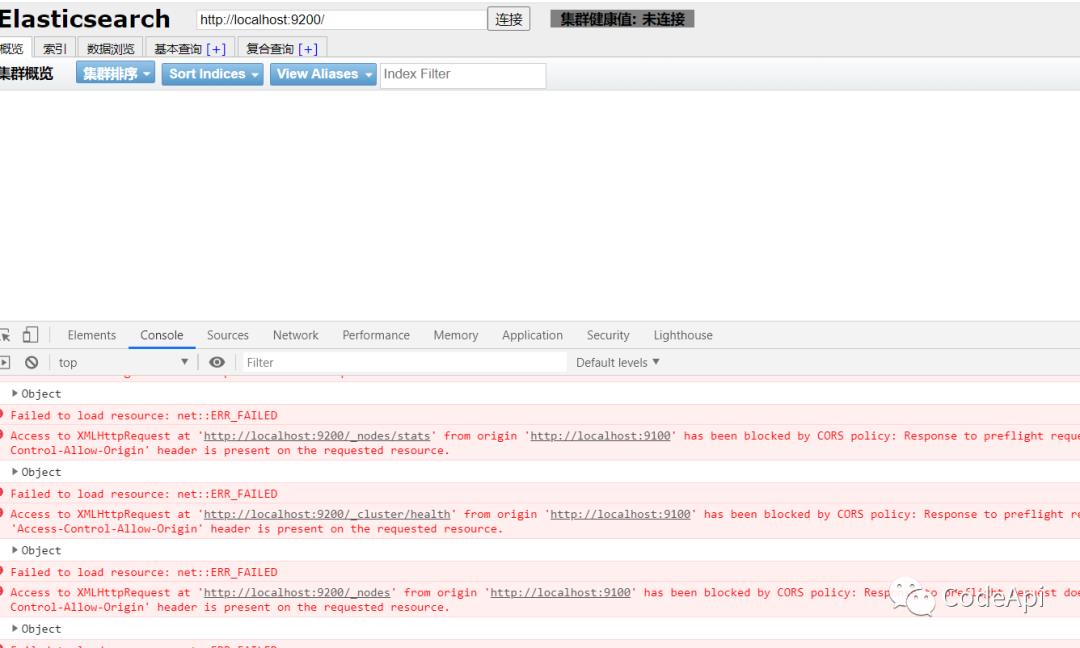
我们只需要修改elastic search(后面我们就简称es)的配置文件让其支持跨域即可。
我们用编辑器打开对应路径下的为配置文件。
在文件尾部添加如下配置,保存重启es即可。
http.cors.enabled: true
http.cors.allow-origin: "*"
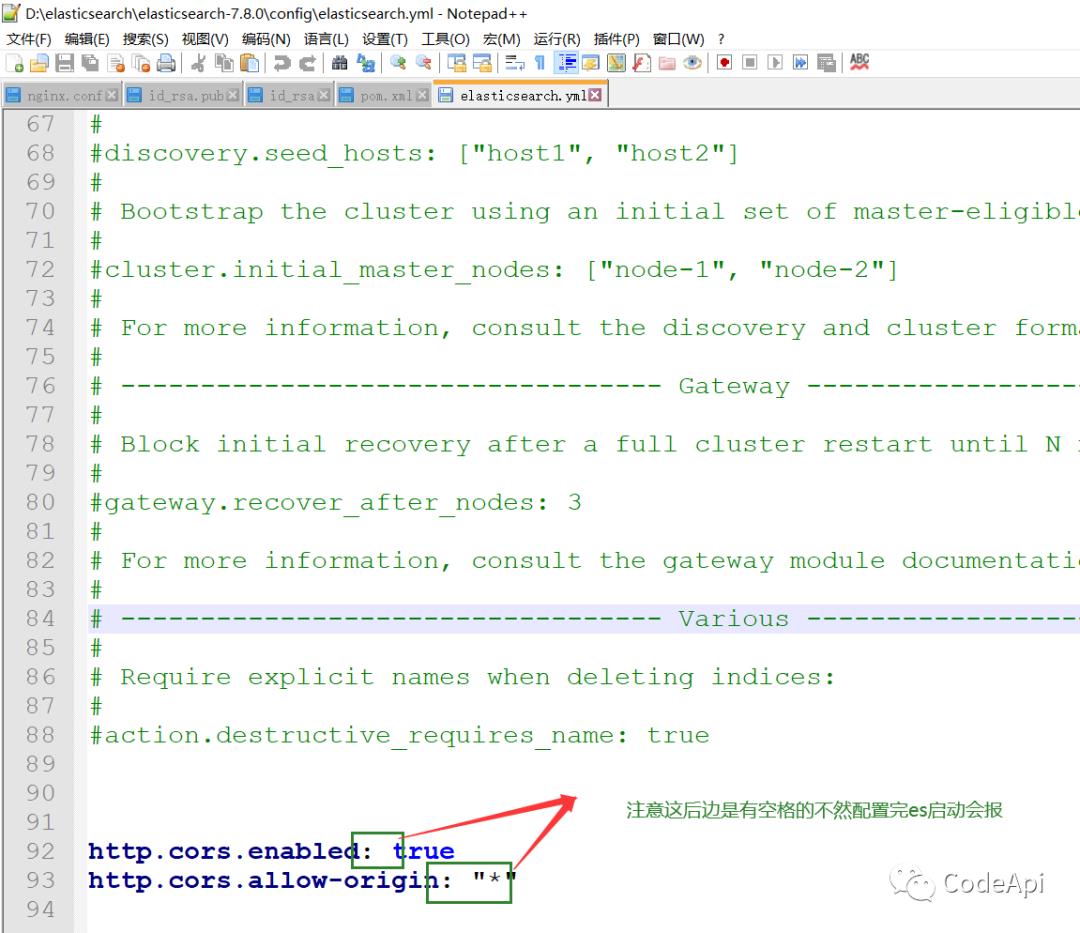
修改保存后重启es我们看到此时已没有问题。
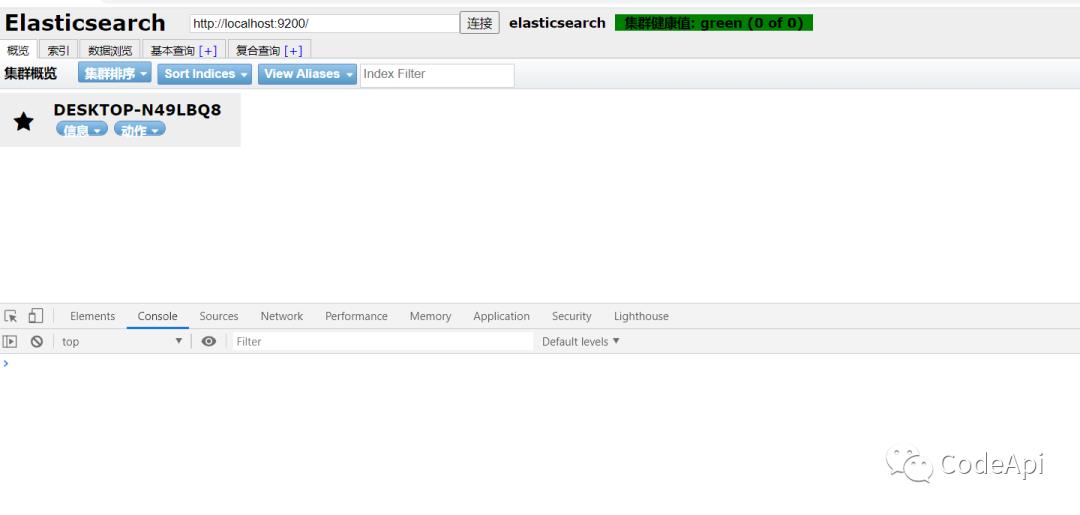
可以看到我们的es中是没有数据的,为了更好的测试使用es,我们还需要安装一个非常好用的工具Kibana。
下载压缩包:https://www.elastic.co/cn/downloads/kibana
下载成功后将其解压到elasticsearch所在目录
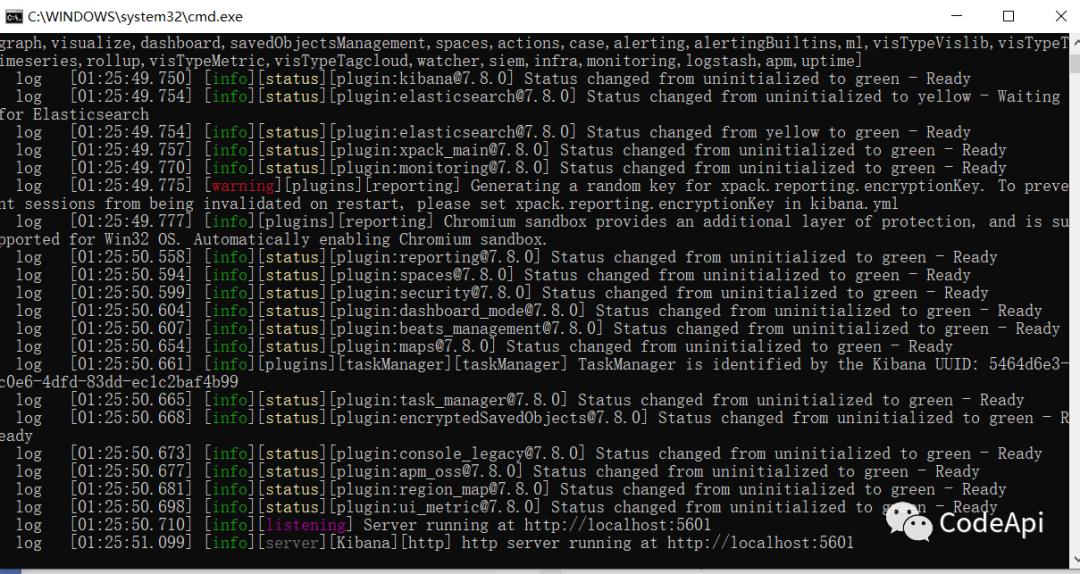
进入目录点击kibana.bat即可启动,启动需要等待一定的时间。
打开kibana/config目录下的kibana.yml文件在文件末尾添加如下代码。
i18.local: "zh-CN"

保存并重启kibana,在浏览器输入回车这时kibana就是中文的了。
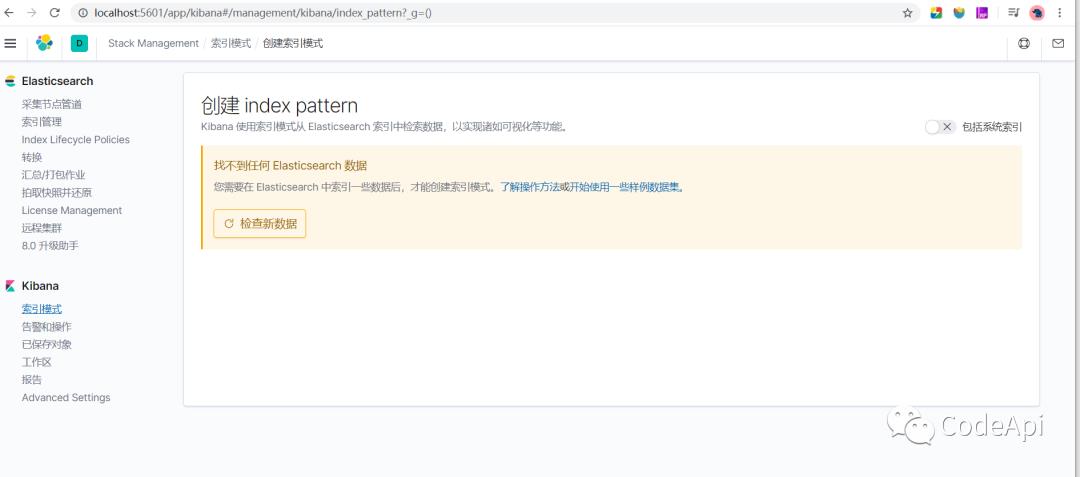
按下图步骤打开开发者工具。
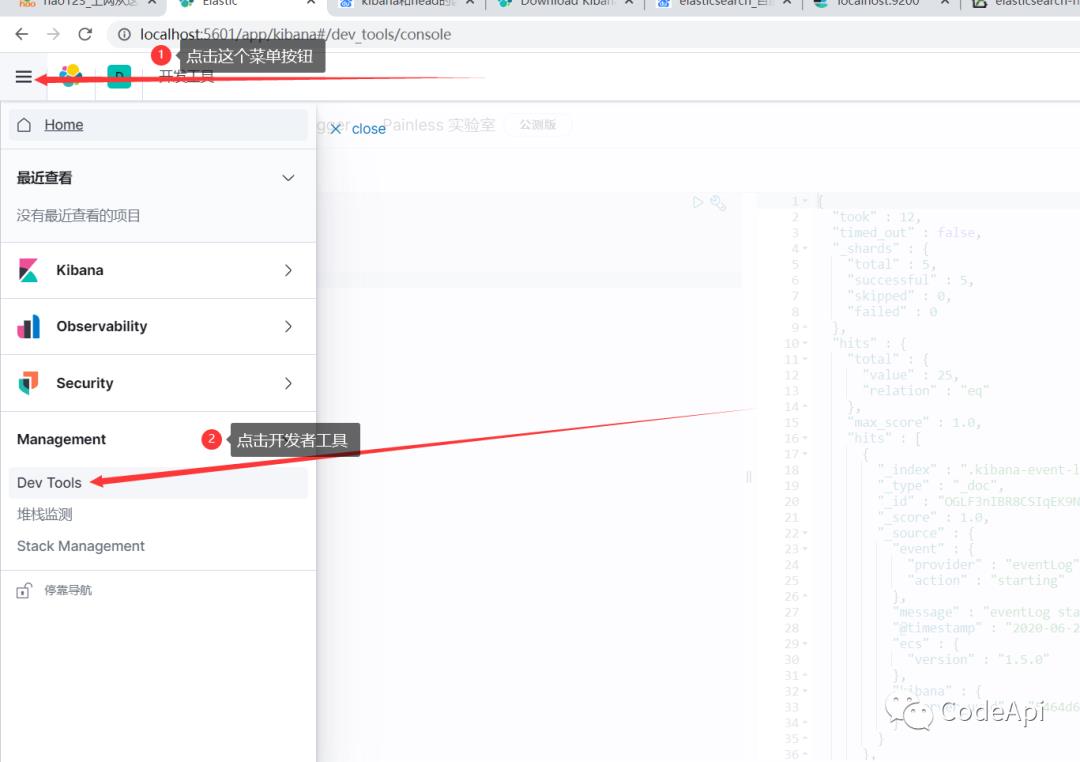
之后我们就可以在这个界面测试es的使用了。
我们知道搜索引擎之所以能找到我们想要的内容分词器功不可没,接下来我们就来测一下es的分词器。
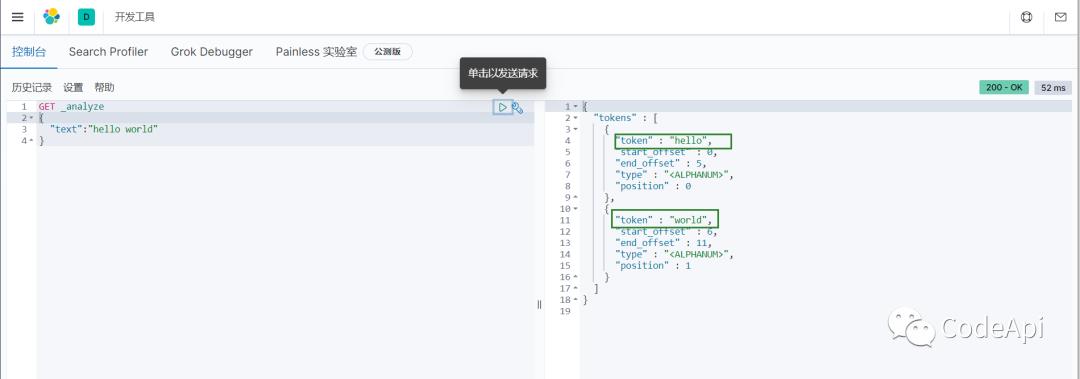
下图我们使用es的默认分词器去拆分Hello World,发现他把这句话查分成 hell 和world两个词,这个效果是不错的。es支持Restful风格的请求路径,不熟悉RestFul风格的小伙伴可以自行百度。
但是当我们输入中文搜索内容的时候发现,拆分效果就不是很理想,分词器只是把内容拆分成一个一个的汉字并没有分成词。
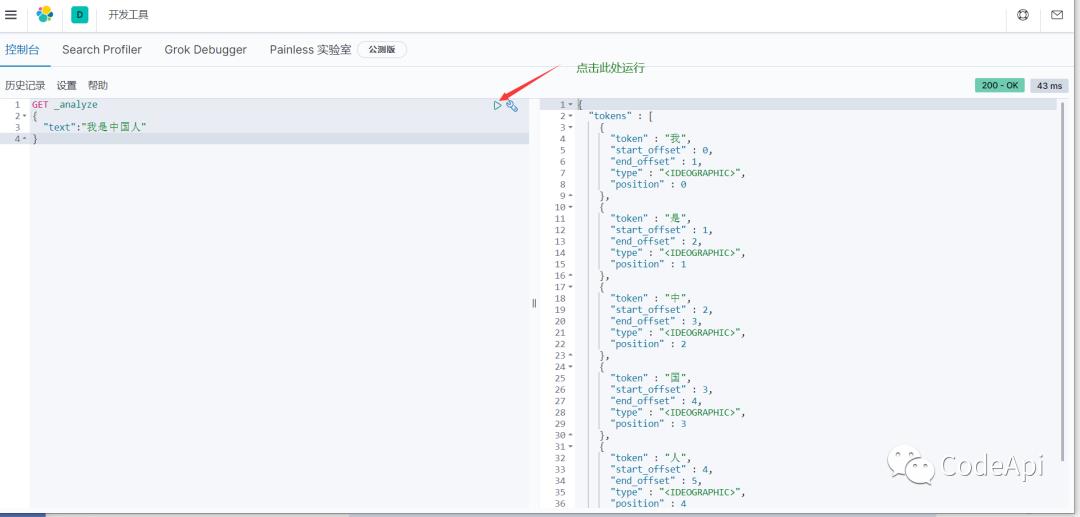
这是由于es默认的分词器对中文的支持不太友好(大家都懂的),因此我们需要给es再安装个中分分词器,中文分词器我们选择ik分词器。
接下来我们就安装ik分词器,安装的过程也是很简单:1.下载->2.解压->3.复制到es的plugins目录下->4重启es即可。
下载ik分词器:https://github.com/medcl/elasticsearch-analysis-ik
将其加压到es的plugins目录下
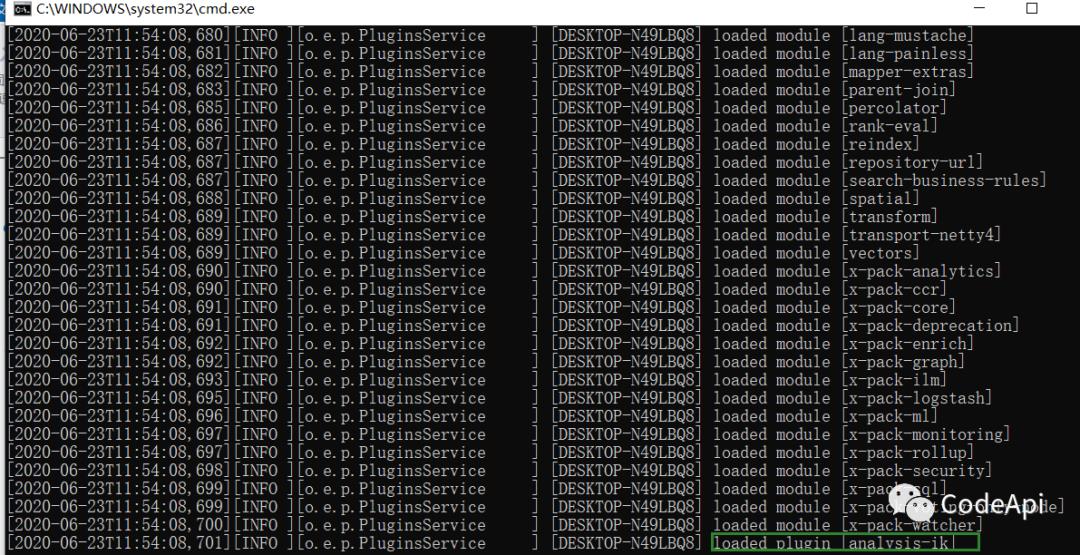
重启es即可。
可以看到已经加载到了ik分词器。
接下来我们就在kibana中使用ik分词器来测试一下效果。
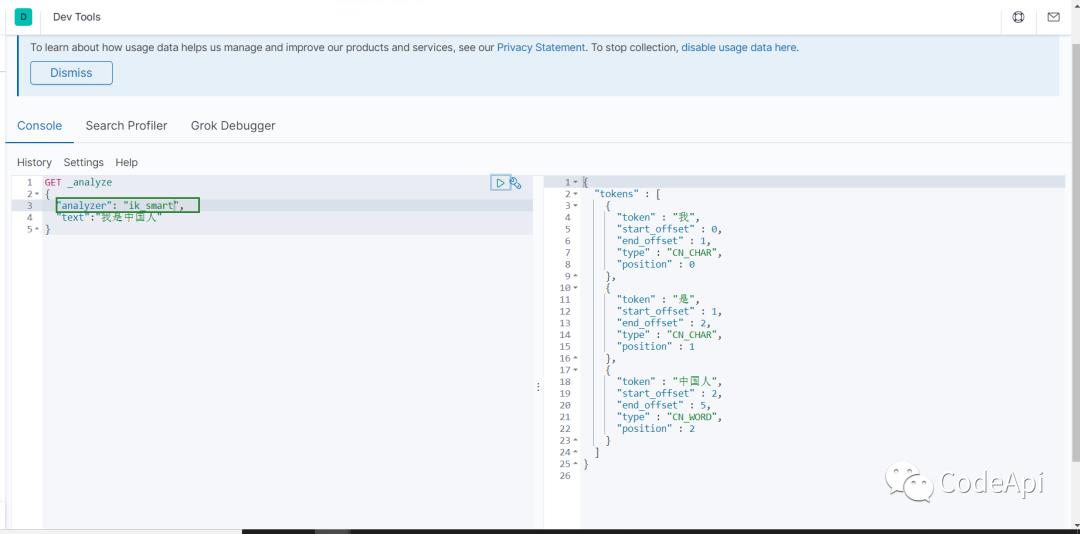
ik分词器的分词标准有两种:1.ik_smart、2.ik_max_word
ik_smart的分词效果如下:
ik_max_word的分词效果如下:
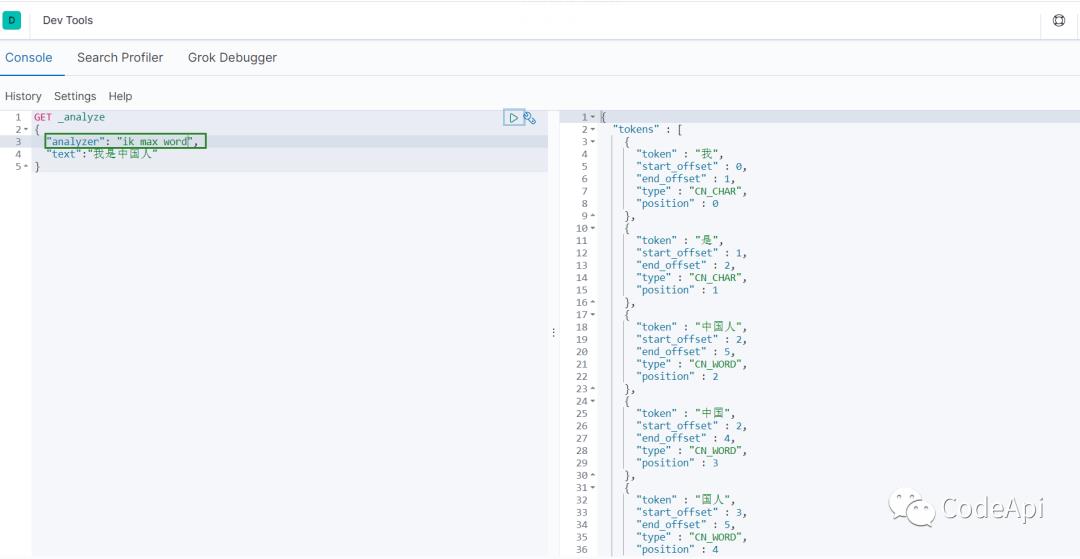
可以看到ik_max_word的效果是穷举所有可能的词汇。
我们再来试一下。
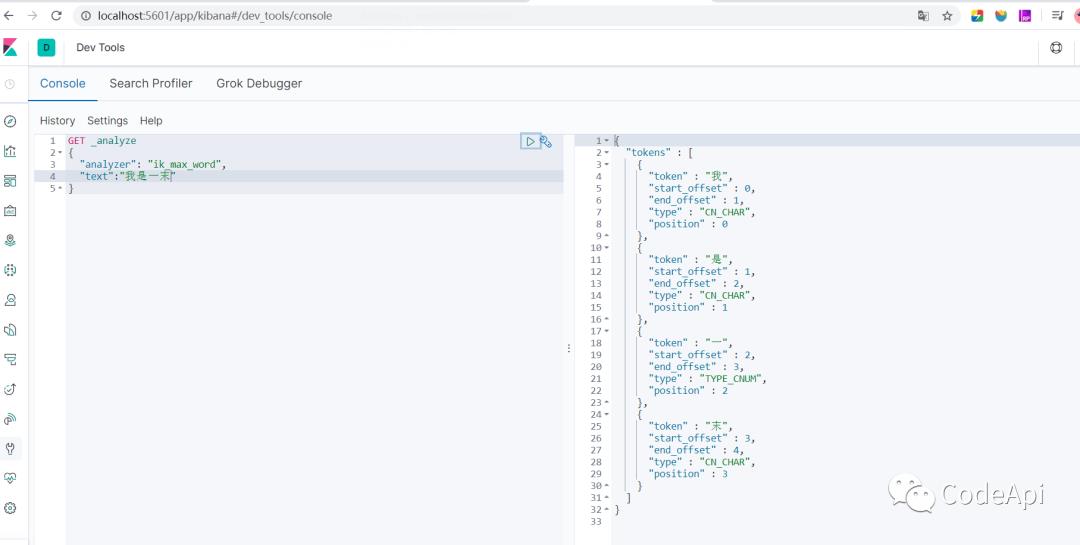
从上图中可以看出ik并没有识别"一末",这也正常因为"一末"并不是一个众所周知的名词,但是我如我们就是想让它识别出来怎么办?我们可以去配置我们自己的词典库,这样ik就能根据我们的词典库识别出我们想要的效果。
配置ik词典库
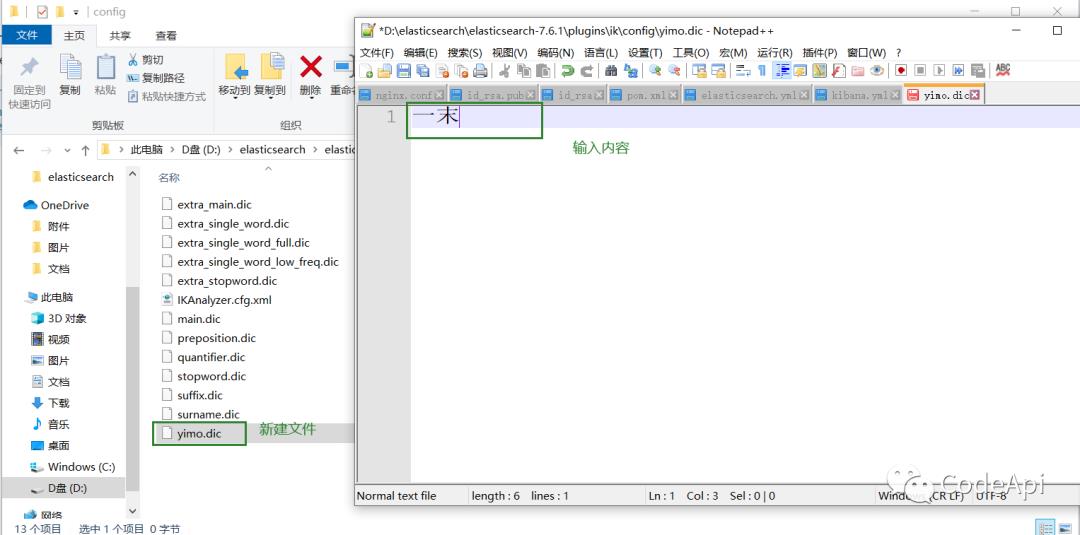
打开ik分词器的配置目录,我们可以看到很多.dic结尾的文件这些就是ik的词典库,我们可以新建一个自己的词典库:yimo.dic,把我们的词汇放进去。
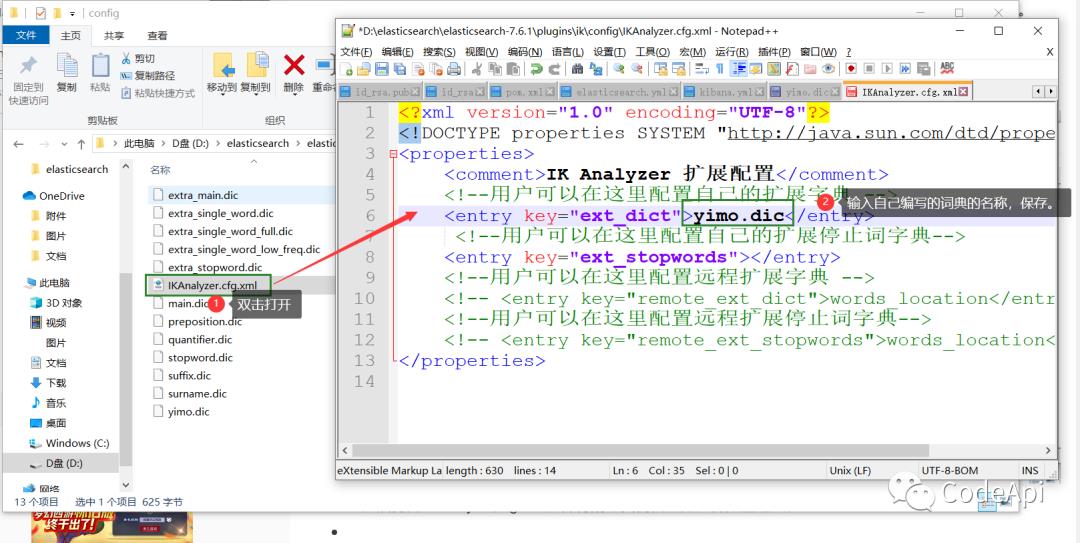
然后打开IKAnalyzer,cfg.xml文件将刚才我们新建为文件配置进去。
重启es,这时我们再来做一下刚才的那个测试,看效果:
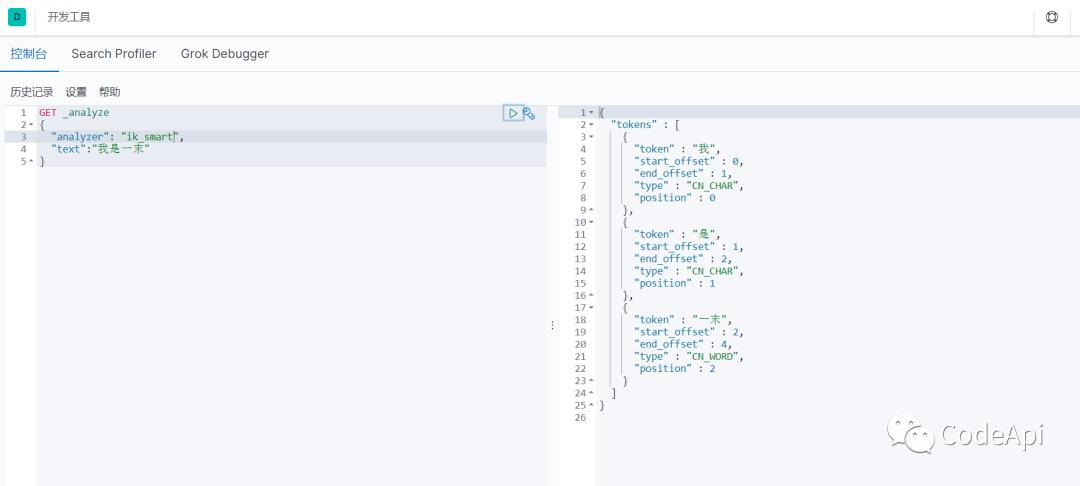
可以看到es已经准确的识别出"一末"。
简单的认识了es的使用方法之后我们来创建一个自己的索引(跟数据库中的建表是相似的),在kibana中输入下面内容创建索引。
PUT /student
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"age":{
"type": "long"
},
"sex":{
"type": "text"
}
}
}
}
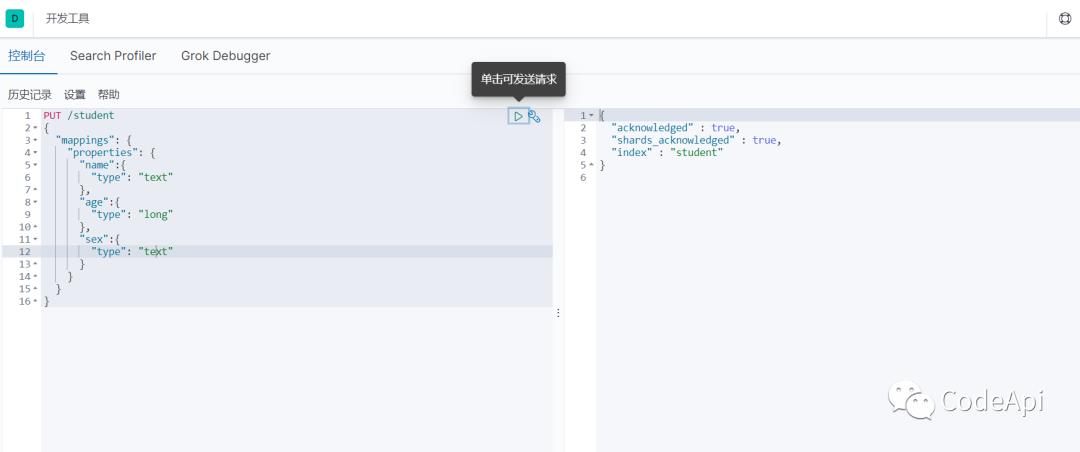
来到elasticsearch我们可以看到student索引已经成功创建。
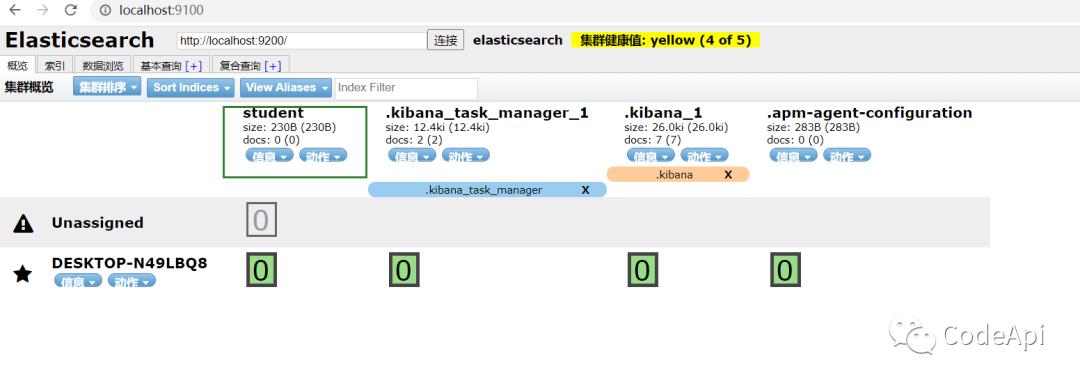
我们也可以在kibana中使用命令来获取指定索引的信息如下图:
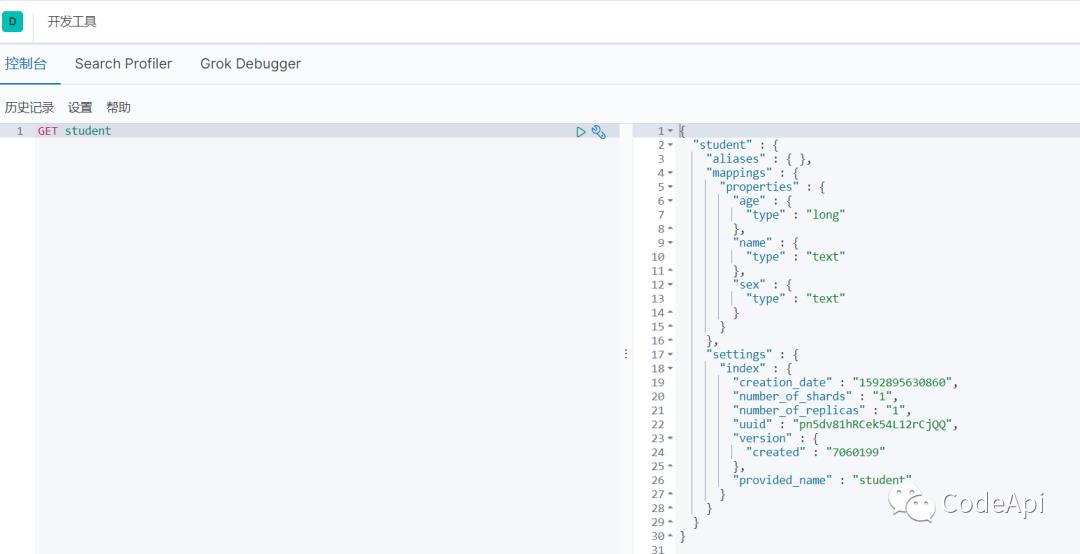
当然我们也可以向刚才的索引中添加数据,如下:
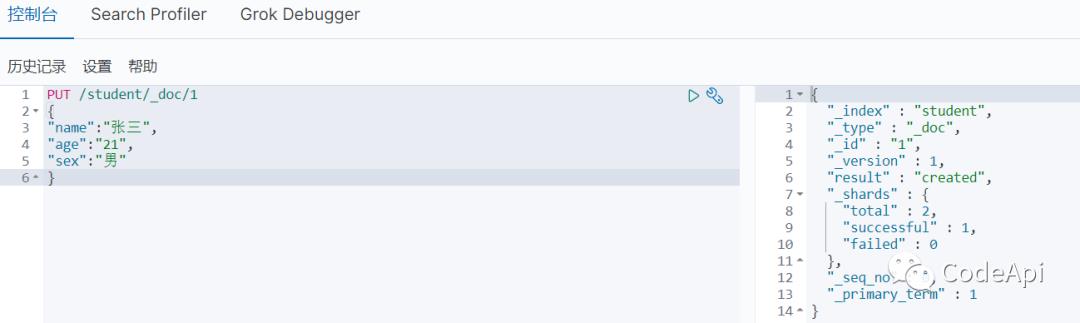
来到elasticsearch-head可以看到数据已经添加成功。
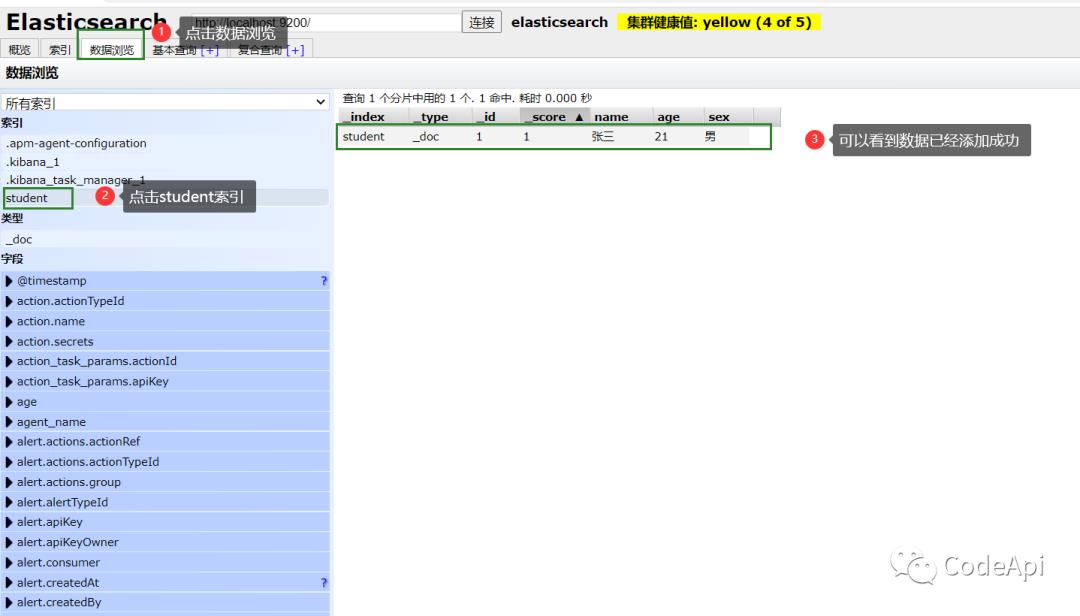
我们也可以通过命令修改内容:
POST /student/_doc/1/_update
{
"doc":{
"name":"张三丰"
}
}
可以看到内容被成功修改:
我们有也可以删除指定内容
DELETE /student/_doc/1
可以看到id为1的记录已经被我们删除。
好了,到这es的简单使用就结束了,后面还会给大家更新在Java项目中如何去使用es,敬请关注!
以上是关于高效搜索引擎ElasticSearch实战篇的主要内容,如果未能解决你的问题,请参考以下文章