LuceneElasticsearchKibana 入门教程和环境搭建
Posted Coding Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LuceneElasticsearchKibana 入门教程和环境搭建相关的知识,希望对你有一定的参考价值。
信息检索模型
信息检索模型最重要的概念就是 倒排索引,倒排索引是搜索引擎中常见的索引方法,用来存储在全文搜索下某个单词在一个文档中存储位置的映射。通过倒排索引,我们输入一个关键词,可以非常快地获取包含这个关键词的文档列表。
Lucene
Lucene 是一个基于 Java 的全文信息检索工具包,它不是一个完整的搜索应用程序,而是为你的应用程序提供索引和搜索功能。Lucene 目前是 Apache Jakarta 家族中的一个开源项目。也是目前最为流行的基于 Java 开源全文检索工具包。
Elasticsearch 就是基于 Lucene 的。
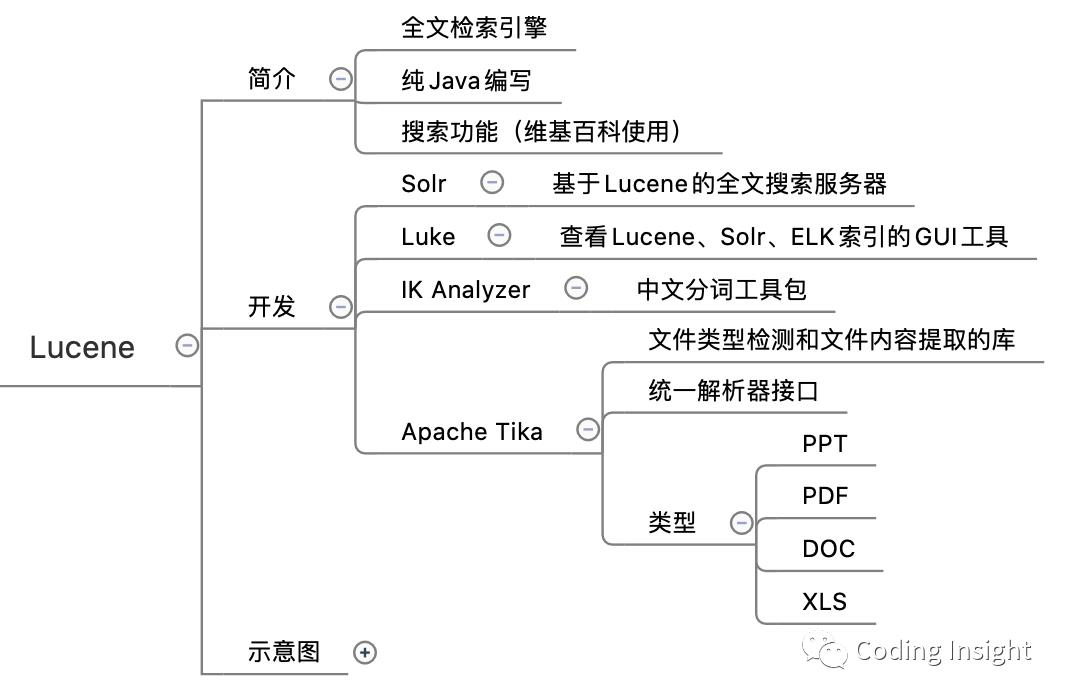
demo
官网:https://lucene.apache.org/core/downloads.html
可以使用国内镜像下载:https://mirrors.tuna.tsinghua.edu.cn/apache/lucene/java/8.5.2/lucene-8.5.2.zip
下面是 Java 代码的简单例子,Maven 配置文件:
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>8.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>8.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>8.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>8.5.2</version>
</dependency>
测试分词
注意下面使用的 SmartChineseAnalyzer 是包 lucene-analyzers-smartcn。
@Testpublic void testAnalyzer() throws IOException {String chinese = "中华人民共和国简称中国,是一个有13亿人口的国家";Analyzer analyzer = new SmartChineseAnalyzer();TokenStream tokenStream = analyzer.tokenStream(chinese, new StringReader(chinese));tokenStream.reset();CharTermAttribute attribute = tokenStream.getAttribute(CharTermAttribute.class);System.out.println("分词结果:");while (tokenStream.incrementToken()) {System.out.print(attribute.toString() + "|");}analyzer.close();}
程序输出:
分词结果:中华人民共和国|简称|中国|是|一个|有|13|亿|人口|的|国家|
测试索引
下面程序创建了3个包含 id, title, content 的文档,其中每个类型都是 FieldType,使用 SmartChineseAnalyzer。索引目录是 web 根目录下的 indexDir 文件夹。
@Testpublic void testIndex() throws IOException {List<String> titleList = Lists.newArrayList("中国房企洛杉矶丑闻:百万美元行贿案遭曝光", "2025年之前美国不会退出WTO了","特朗普退出总统竞选?");List<String> contentList = Lists.newArrayList("据调查,惠泽尔从中国房企手里收取了超过150万美元的现金贿赂,合人民币超过1000万元。","美国特朗普政府上台以来,每隔几月,便总要传出有关“美国要退出世贸组织(WTO)”的消息。那么究竟美国能不能退出WTO?","“共和党的操盘手首次提出了这样的可能性”,即川普总统可能会退出2020年总统竞选");Path indexPath = Paths.get("indexDir");Directory dir = FSDirectory.open(indexPath);// 设置新闻ID索引并存储FieldType idType = new FieldType();idType.setIndexOptions(IndexOptions.DOCS);idType.setStored(true);// 设置新闻标题索引文档、此项频率、位移信息、偏移量,存储并词条化FieldType titleType = new FieldType();titleType.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS);titleType.setStored(true);titleType.setTokenized(true);FieldType contentType = new FieldType();contentType.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS);contentType.setStored(true);contentType.setTokenized(true);contentType.setStoreTermVectors(true);contentType.setStoreTermVectorOffsets(true);contentType.setStoreTermVectorPayloads(true);contentType.setStoreTermVectorPositions(true);Analyzer analyzer = new SmartChineseAnalyzer();IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);indexWriterConfig.setOpenMode(IndexWriterConfig.OpenMode.CREATE);IndexWriter indexWriter = new IndexWriter(dir, indexWriterConfig);for (int i = 0; i < titleList.size(); i++) {Document doc = new Document();doc.add(new Field("id", Integer.toString(i + 1), idType));doc.add(new Field("title", titleList.get(i), titleType));doc.add(new Field("content", contentList.get(i), contentType));indexWriter.addDocument(doc);}indexWriter.commit();indexWriter.close();dir.close();}
在运行代码后,会在根目录生成 indexDir 文件夹(代码中指定),如下图所示。

搜索索引
@Testpublic void testSearch() throws Exception {Path indexPath = Paths.get("indexDir");Directory dir = FSDirectory.open(indexPath);IndexReader reader = DirectoryReader.open(dir);IndexSearcher searcher = new IndexSearcher(reader);Analyzer analyzer = new SmartChineseAnalyzer();QueryParser parser = new QueryParser("title", analyzer);parser.setDefaultOperator(QueryParser.Operator.AND);Query query = parser.parse("房企");System.out.println("query : " + query.toString());TopDocs topDocs = searcher.search(query, 10);for (ScoreDoc sd : topDocs.scoreDocs) {Document doc = searcher.doc(sd.doc);System.out.println("docId: " + sd.doc);System.out.println("id: " + doc.get("id"));System.out.println("title: " + doc.get("title"));System.out.println("content: " + doc.get("content"));System.out.println("文档评分:" + sd.score);}}
会搜出关于房企的信息。
Elasticsearch
全文搜索属于最常见的需求,开源的 Elasticsearch (以下简称 Elastic)是目前全文搜索引擎的首选。
它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它。
Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
入门教程推荐阮一峰的《全文搜索引擎 Elasticsearch 入门教程》
官网是:https://www.elastic.co/cn/,上面内容很全面,感觉直接看官网最好。
Elastic Stack
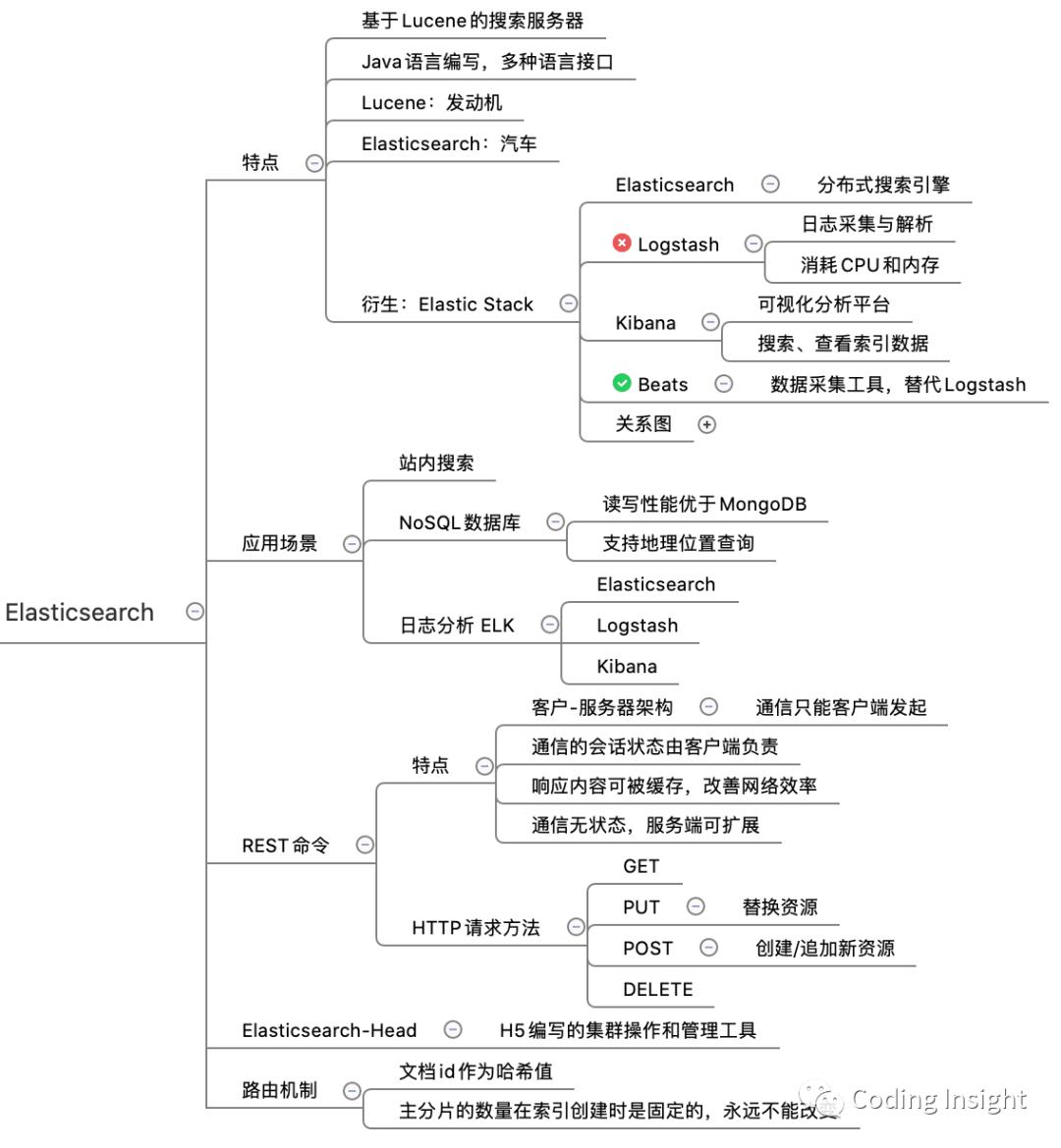
原来是通过 Logstash 进行日志收集与解析,Elasticsearch 作为搜索引擎,Kibana 作为可视化分析平台。但是 Logstash 有CPU和内存性能问题,官方开发了 Beats 数据采集工具。本文通过一个例子使用 Java 直接向 Elasticsearch 发送消息,并搭建 Kibana 数据可视化查询。
Docker 搭建 Elasticsearch
说明:经过试验,本文不使用最新版本,而是使用 Elasticsearch 6.8.4 版本,因为 Spring boot data 2.3 集成的版本就是 6.8.4,同时 Kibana 也要和 Elasticsearch 版本完全一致,否则会出各种奇葩问题。
docker 拉取 6.8.4 版本镜像:
docker pull elasticsearch:6.8.4
启动镜像:
docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" elasticsearch:6.8.4这里使用简单模式,9200是 HTTP rest 协议,9300 是 tcp 协议。启动完成后,可以在浏览器中输入网址 0.0.0.0:9200,返回一下内容说明启动成功:
{
"name": "_jhdsik",
"cluster_name": "docker-cluster",
"cluster_uuid": "mpaTnrRaSY2_e3LFPz4QXw",
"version": {
"number": "6.8.4",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "bca0c8d",
"build_date": "2019-10-16T06:19:49.319352Z",
"build_snapshot": false,
"lucene_version": "7.7.2",
"minimum_wire_compatibility_version": "5.6.0",
"minimum_index_compatibility_version": "5.0.0"
},
"tagline": "You Know, for Search"
}
如果要看 log,可以使用命令:
docker logs -f 44afc4738685
其中 44afc4738685 是 CONTAINER ID(可通过 docker ps 查看)。
修改 Elasticsearch 配置:
docker exec -it epic_beaver /bin/bash
其中 epic_beaver 是我的 docker Elasticsearch 容器名称。进入 config 目录修改 elasticsearch.yml 文件。
cluster.name: "docker-cluster"
network.host: 0.0.0.0
# xpack.security.enabled: true
其中 xpack.security.enabled 在设置密码时使用,暂时不做设置。
修改完配置文件,重启容器。
Docker 搭建 Kibana
由于 Elasticsearch 使用的是 6.8.4 版本,Kibana 也要使用这个版本。
docker 下载 Kibana 镜像:
docker pull kebana:6.8.4
修改配置文件(本例是 /root/etc/kibana.yml)
server.name: kibana
server.host: "0"
elasticsearch.hosts: [ "http://0.0.0.0:9200" ]
# xpack.monitoring.ui.container.elasticsearch.enabled: true
注:这里的 elasticsearch.hosts 配置跟 docker 网络模式有关,因为 elasticsearch 和 kibana 是 2 个独立的 docker 容器,直接设置 http://0.0.0.0:9200 可能不通,需要额外配置。本例使用的是阿里云的服务器,配置成了公网 IP,配置中改成了 0.0.0.0,读者需要自行替换。
docker 启动 Kibana:
docker run -d --restart=always --log-driver json-file --log-opt max-size=100m --log-opt max-file=2 --name kibana -p 5601:5601 -v /root/etc/kibana.yml:/usr/share/kibana/config/kibana.yml kibana:6.8.4在浏览器输入 0.0.0.0:5601,如果出现下面的界面,则表示启动成功。
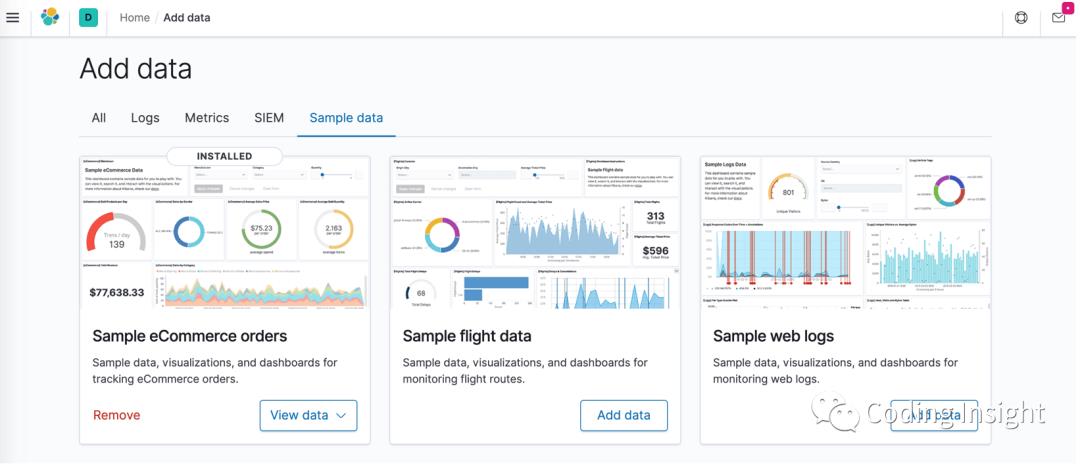
启动失败可以通过 docker logs-f kibana_container_id 查看日志。
demo
本例使用 Spring boot,Maven pom 引入:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
在 application.yml 中增加:
data:
elasticsearch:
cluster-nodes: 0.0.0.0:9300
cluster-name: docker-cluster
写一个实体类 EsNewsEntity,indexName 设置为 news_test:
@Data
@Builder
@Document(indexName = "news_test")
public class EsNewsEntity {
@Id
private String id;
private String title;
private String content;
@DateTimeFormat(pattern = "yyyy-MM-dd")
@JsonFormat(pattern = "yyyy-MM-dd", timezone = "GMT+8")
private Date time;
}
整体查询使用 ElasticsearchRepository,里面有 CRUD 的操作,还有分页和排序,Spring data 使各种数据查询有了统一的操作接口,使用起来也很方便。
本例中只是想 ES 中简单插入一些数据,repository 如下:
public interface EsNewsRepository extends ElasticsearchRepository<EsNewsEntity, String> {}
插入数据的代码如下,其中插入了2条 title 为 “韩国男星” 的文章,1条 title 为 “特大暴雨”的文章:
@Testpublic void testEs() {EsNewsEntity newsEntity = EsNewsEntity.builder().id("1").title("韩国男星").content("我很喜欢大神、金钟国、光洙").time(DateTime.now().toDate()).build();esNewsRepository.save(newsEntity);newsEntity = EsNewsEntity.builder().id("2").title("特大暴雨").content("特大暴雨夜袭四川冕宁:山洪摧毁村庄 一家5口遇难").time(DateTime.now().toDate()).build();esNewsRepository.save(newsEntity);newsEntity = EsNewsEntity.builder().id("3").title("韩国男星").content("韩国男星身材管理多严格?金秀贤 Rain有八块腹肌").time(DateTime.now().toDate()).build();esNewsRepository.save(newsEntity);System.out.println("es save ...");}
运行之后,在 Kibana->Management->Create index pattern,输入上面 News 的 indexName:news_test,设置 Date 为时间索引。
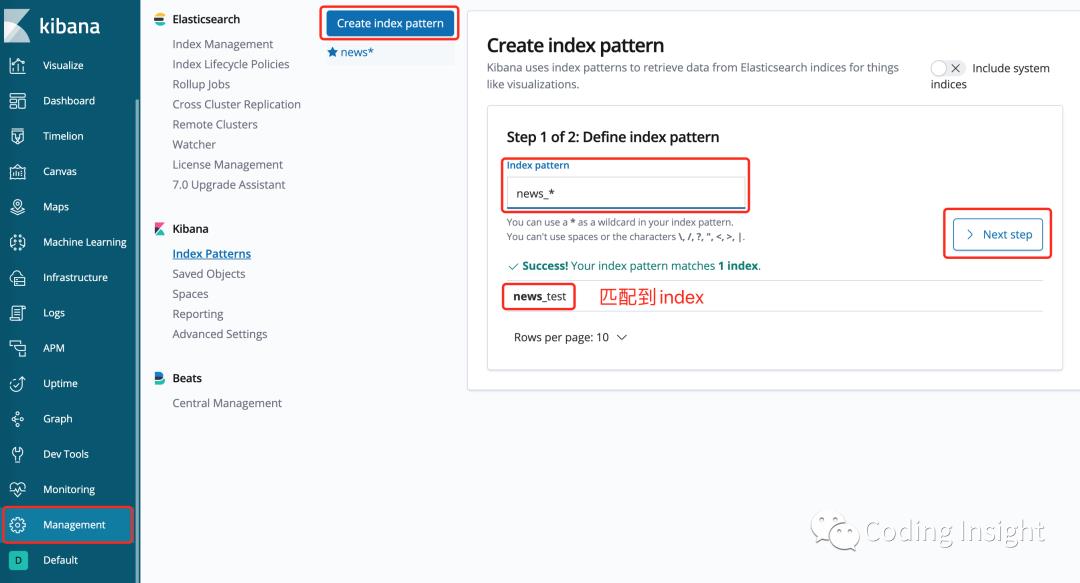
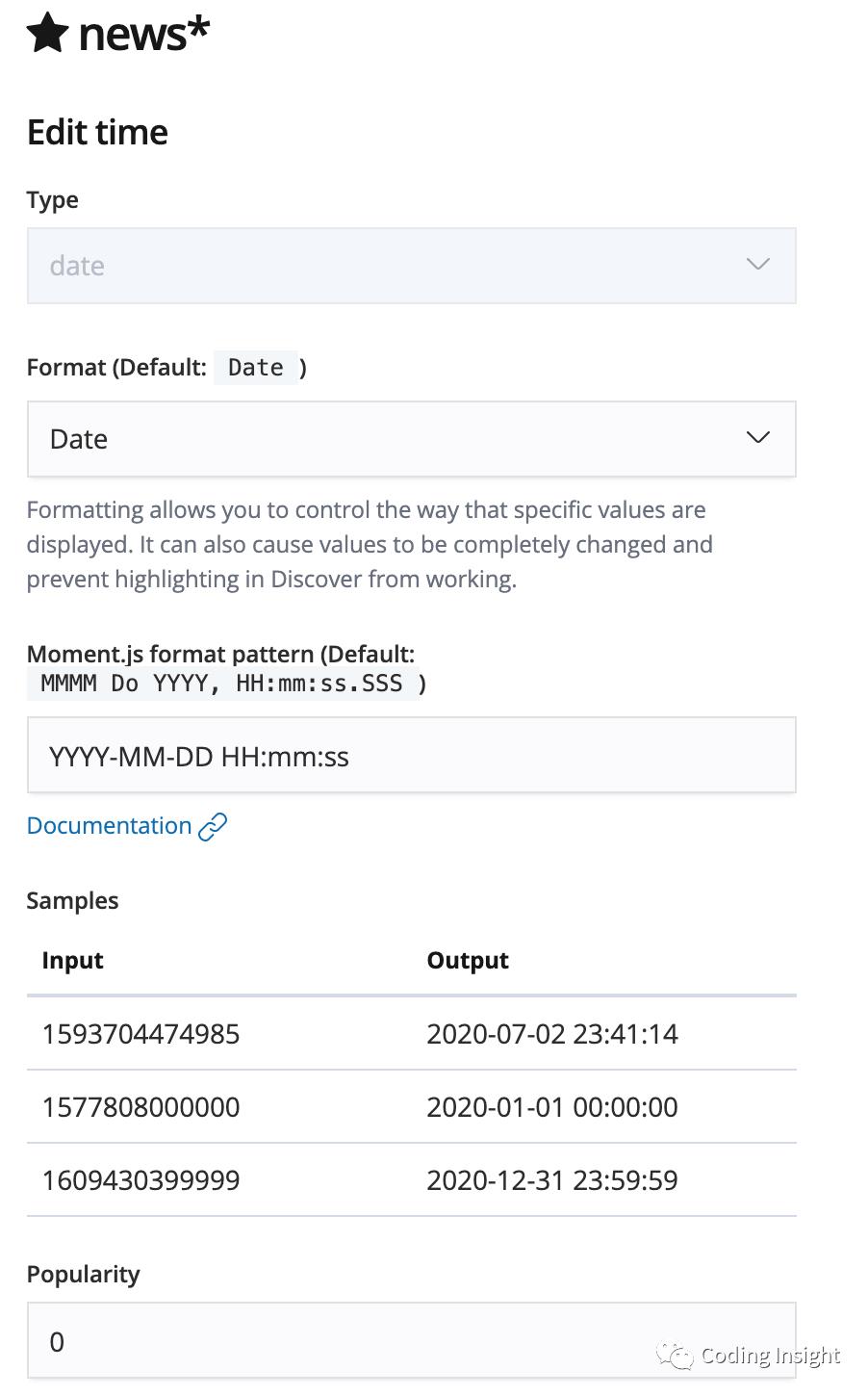
之后刷新页面,可以根据时间搜索新插入的几条数据。
问题总结
本例的 es 和 Kibana 没有使用密码登录,在实际应用过程中 es 可以限制 ip 访问。我在研究的过程中,设置好 es 和 Kibana 的密码后,没法使用 Spring data 直接与 es 通信,暂时放弃。
es 和 Kibana 的版本一定要一致!
spring-boot-starter-data-elasticsearch 的 es 版本并不高,最新版本已经是 7.8,但是 spring-boot-starter-data-elasticsearch 集成的仍然是 6.8,需要注意。如果必须使用最新版,需要额外配置。
Kibana 在分析日志、数据分析时很强大。
本示例是 demo 演示,不要在生产环境中使用。
可以直接在腾讯云、阿里云上购买 es 服务,不过真心贵……小站点或个人开发者还是自行搭建比较划算。
《Lucene Elasticsearch 全文检索实战》这本书不建议买,书的内容浅显,排版和内容问题很多。比如有的代码分隔符是中文标点,书的前几章代码是深色背景,后几章代码没有背景……
公众号
以上是关于LuceneElasticsearchKibana 入门教程和环境搭建的主要内容,如果未能解决你的问题,请参考以下文章