因为游戏业务本身的日志数据量非常大(写入峰值在 100w qps ),在服务客户的几个月中,我们踩了不少坑。经过数次优化与调整,最后将客户的 ES 集群调整得比较稳定,避免了在业务高峰时客户集群的读写异常,并且降低了客户的资金成本和使用成本。
与客户的初次交锋
解决方案架构师A:bellen, XX公司要上线一款新游戏,日志存储决定用 ELK 架构,他们决定在 XX云和我们之间二选一,我们首先去他们公司和他们交流一下,争取拿下!bellen: 好,随时有空!随后和架构师一起前往该公司,跟负责底层组件的运维部门的负责人进行沟通。XX公司运维老大:不要讲你们的PPT了,先告诉我你们能给我们带来什么!bellen:呃,我们有很多优势,比如可以灵活扩缩容集群,还可以一键平滑升级集群版本,并且提供有跨机房容灾的集群从而实现高可用......XX公司运维老大:你说的这些别的厂商也有,我就问一个问题,我们现在要存储一年的游戏日志,不能删除数据,每天就按 10TB 的数据量算,一年也得有个 3PB 多的数据,这么大的数量,都放在SSD云盘上,成本太高了。你们有什么方案既能够满足我们存储这么大数据量的需求,同时能够降低我们的成本吗?bellen:我们本身提供的有冷热模式的集群,热节点采用 SSD 云硬盘,冷节点采用 SATA 盘,采用 ES 自带的 ILM 索引生命周期管理功能,定期把较老的索引从热节点迁移到冷节点上,这样从整体上可以降低成本。另外,也可以定期把更老的索引通过 snapshot 快照备份到 COS 对象存储中,然后删除索引,这样成本就更低了。XX公司运维老大:存储到 COS 就是冷存储呗,我们需要查询 COS 里的数据时,还得再把数据恢复到 ES 里?这样不行,速度太慢了,业务等不了那么长时间。我们的数据不能删除,只能放在 ES 里!你们能不能给我们提供一个 API , 让老的索引数据虽然存储在 COS 里,但是通过这个 API 依然可以查询到数据,而不是先恢复到 ES , 再进行查询?bellen:呃,这个可以做,但是需要时间。是否可以采用 hadoop on COS 的架构,把存量的老的索引数据通过工具导入到 COS,通过 hive 去查询,这样成本会非常低,数据依然是随时可查的。XX公司运维老大:那不行,我们只想用成熟的 ELK 架构来做,再增加 hadoop 那一套东西,我们没那么多人力搞这个事。bellen: 好吧,那可以先搞一个集群测试起来,看看性能怎么样。关于存量数据放在 COS 里但是也需要查询的问题,我们可以先制定方案,尽快实施起来。XX公司运维老大:行吧,我们现在按每天 10TB 数据量预估,先购买一个集群,能撑 3 个月的数据量就行,能给一个集群配置的建议吗?bellen: 目前支持单节点磁盘最大 6TB , cpu 和内存的话可以放到 8 核 32G 单节点,单节点跑 2w qps 写入没有问题,后面也可以进行纵向扩容和横向扩容。
XX公司运维老大:好,我们先测试一下。
集群顶不住压力了
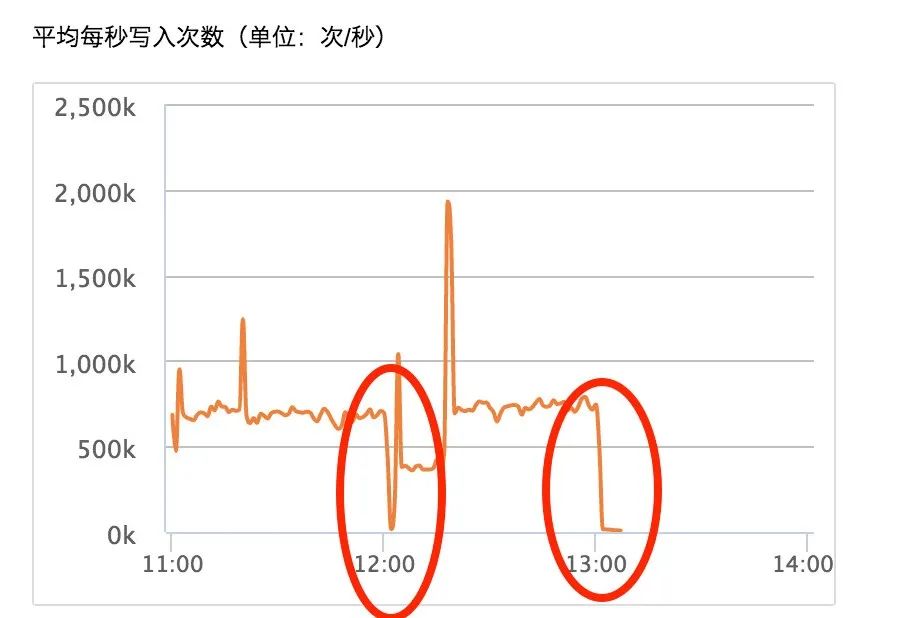
N 天后,架构师 A 直接在微信群里反馈:bellen, 客户反馈这边的 ES 集群性能不行啊,使用 logstash 消费 kafka 中的日志数据,跑了快一天了数据还没追平,这是线上的集群,麻烦紧急看一下吧。我一看,一脸懵,什么时候已经上线了啊,不是还在测试中吗?XX公司运维B: 我们购买了 8 核 32G*10 节点的集群,单节点磁盘 6TB , 索引设置的10 分片 1 副本,现在使用 logstash 消费 kafka 中的数据,一直没有追平,kafka 中还有很多数据积压,感觉是 ES 的写入性能有问题。随后我立即查看了集群的监控数据,发现 cpu 和 load 都很高,jvm 堆内存使用率平均都到了 90% ,节点 jvm gc 非常频繁了,部分节点因为响应缓慢,不停的离线又上线。经过沟通,发现用户的使用姿势是 filebeat+kafka+logstash+elasticsearch , 当前已经在 kafka 中存储了有10天的日志数据,启动了 20 台 logstash 进行消费,logstash 的 batch size 也调到了 5000,性能瓶颈是在 ES 这一侧。客户 8 核 32G*10 节点的集群,理论上跑 10w qps 没有问题,但是 logstash 消费积压的数据往 ES 写入的 qps 远不止10w,所以是 ES 扛不住写入压力了,只能对 ES 集群进行扩容。为了加快存量数据的消费速度,先纵向扩容单节点的配置到 32 核 64GB,之后再横向增加节点,以保证 ES 集群能够最大支持 100w qps 的写入(这里需要注意的是,增加节点后索引的分片数量也需要调整)。所以一般新客户接入使用 ES 时,必须要事先评估好节点配置和集群规模,可以从以下几个方面进行评估:
"deciders" : [ {"decider" : "same_shard","decision" : "NO","explanation" : "the shard cannot be allocated to the same node on which a copy of the shard already exists [[x-2020.06.19-13][58], node[LKsSwrDsSrSPRZa-EPBJPg], [P], s[STARTED], a[id=iRiG6mZsQUm5Z_xLiEtKqg]]" }, {"decider" : "awareness","decision" : "NO","explanation" : "there are too many copies of the shard allocated to nodes with attribute [ip], there are [2] total configured shard copies for this shard id and [130] total attribute values, expected the allocated shard count per attribute [2] to be less than or equal to the upper bound of the required number of shards per attribute [1]" }
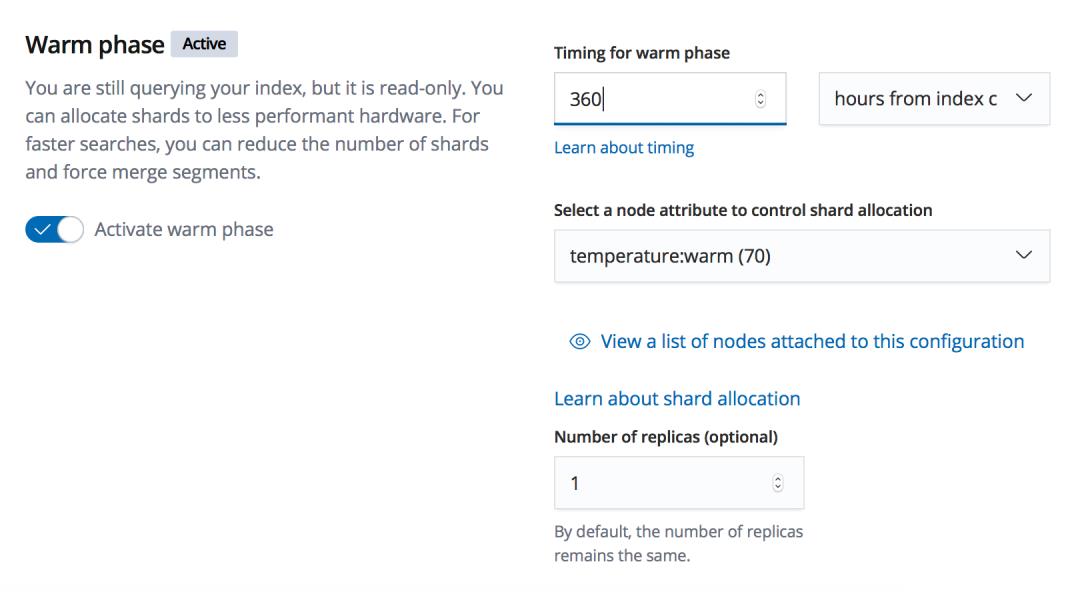
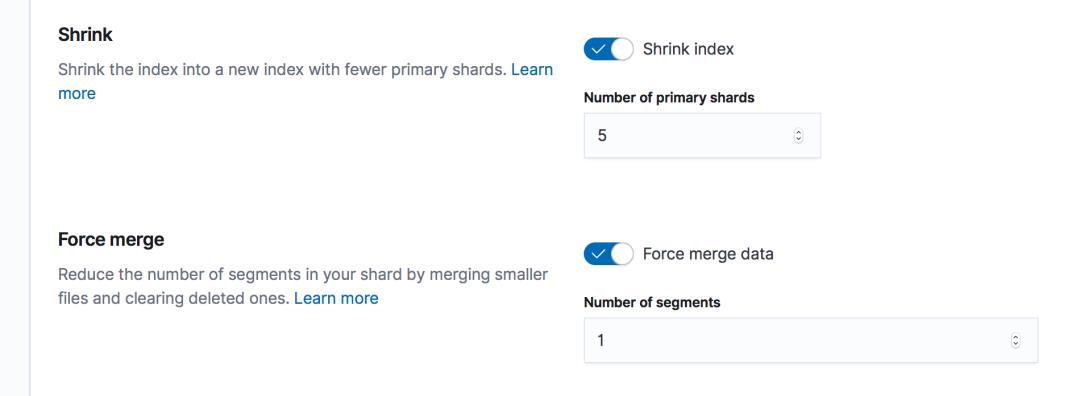
这是因为 shrink 操作需要新把索引完整的一份数据都迁移到一个节点上,然后在内存中构建新的分片元数据,把新的分片通过软链接指向到几个老的分片的数据,在 ILM 中执行 shrink 时, ILM 会对索引进行如下配置:
而这正是目前ES开源社区正在开发中的 Searchable Snapshots 功能。从 Searchable Snapshots API [1] 的官方文档上可以看到,我们可以创建一个索引,将其挂载到一个指定的快照中,这个新的索引是可查询的,虽然查询时间可能会慢点,但是在日志场景中,对一些较老的索引进行查询时,延迟大点一般都是可以接受的。
所以我认为,Searchable Snapshots 解决了很多痛点,将会给 ES 带了新的繁荣!
结语
经历过上述运维和优化 ES 集群的实践,我们总结了如下经验分享给大家:第一:新集群上线前务必做好集群规模和节点规格的评估。第二:集群整体的分片数量不能太多,可以通过调整使用方式并且借助 ES 本身的能力不断进行优化,使得集群总体的分片数维持在一个较低的水位,保证集群的稳定性。第三:Searchable Snapshots 利器会给 ES 带来新的生命力,需要重点关注并研究其实现原理。从一开始和客户进行接触,了解客户诉求,逐步解决 ES 集群的问题,最终使得 ES 集群能够保持稳定,这中间的经历让我真真正正的领悟到"实践出真知"这句话的真谛。只有不断实践,才能对异常情况迅速做出反应,以及对客户提的优化需求迅速反馈。参考资料:[1] Searchable Snapshots API :https://www.elastic.co/guide/en/elasticsearch/reference/master/searchable-snapshots-apis.html