技术专栏丨从原理到应用,Elasticsearch详解(下)
Posted TalkingData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术专栏丨从原理到应用,Elasticsearch详解(下)相关的知识,希望对你有一定的参考价值。
原始文档存储(行式存储)
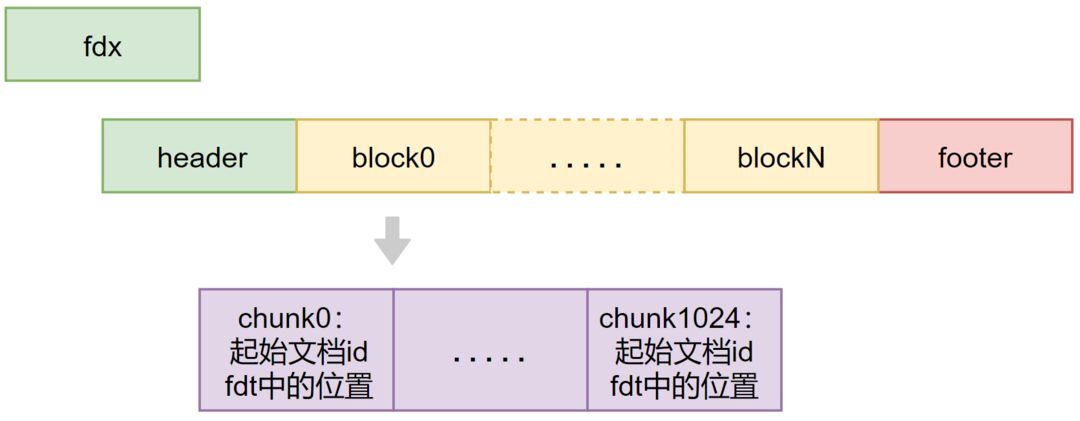
fdt文件
文档内容的物理存储文件,由多个chunk组成,Lucene索引文档时,先缓存文档,缓存大于16KB时,就会把文档压缩存储。
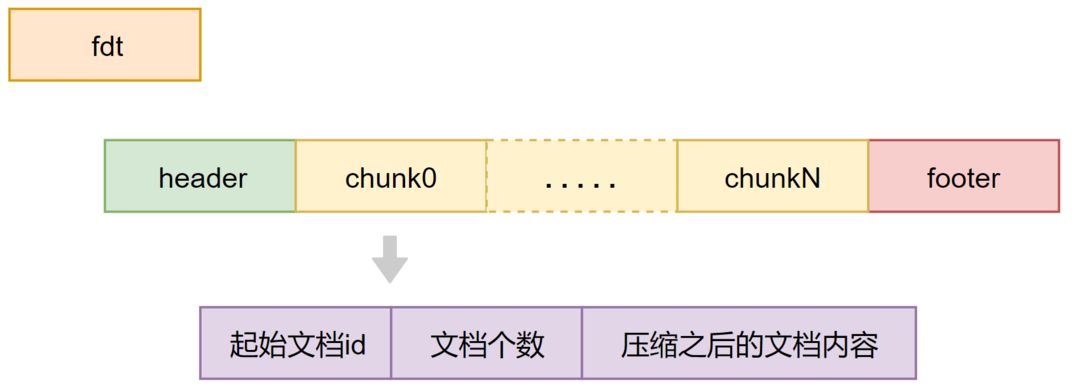
fdx文件
文档内容的位置索引,由多个block组成:
1024个chunk归为一个block
block记录chunk的起始文档ID,以及chunk在fdt中的位置
fnm文件
文档元数据信息,包括文档字段的名称、类型、数量等。
原始文档的查询
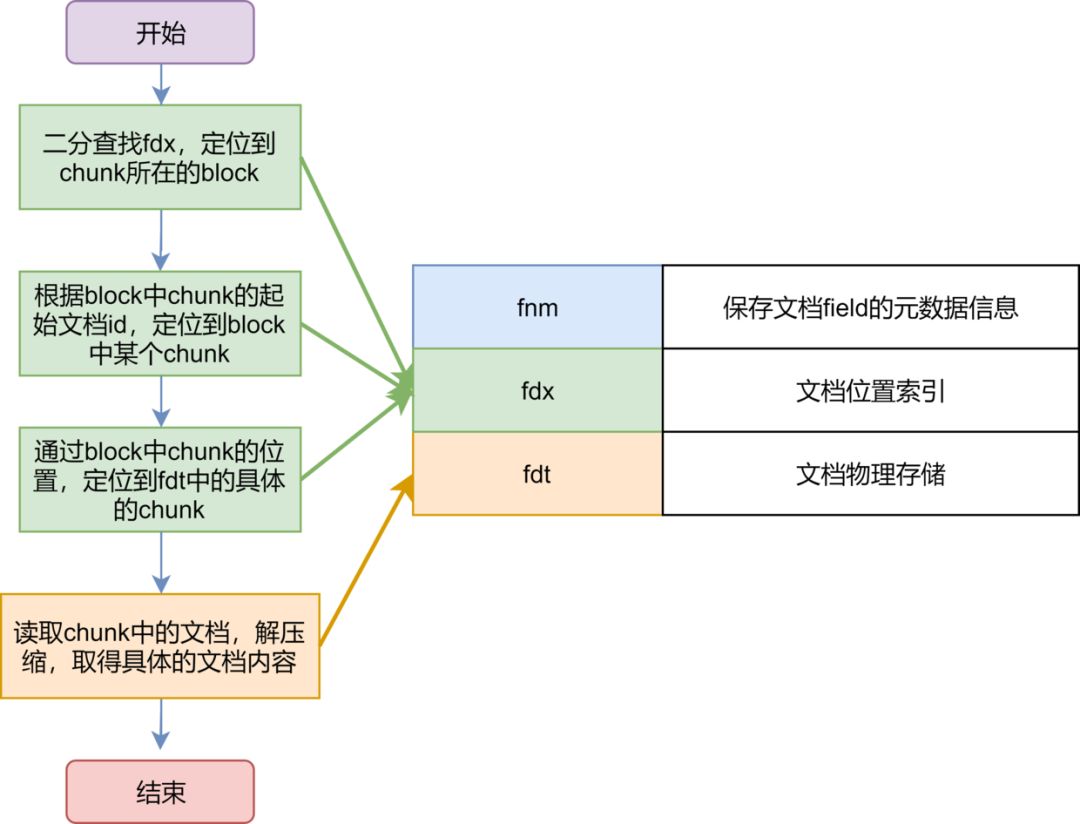
注意问题:lucene对原始文件的存放是行式存储,并且为了提高空间利用率,是多文档一起压缩,因此取文档时需要读入和解压额外文档,因此取文档过程非常依赖CPU以及随机IO。
相关设置
压缩方式的设置
原始文档的存储对应_source字段,是默认开启的,会占用大量的磁盘空间,上面提到的chunk中的文档压缩,ES默认采用的是LZ4,如果想要提高压缩率,可以将设置改成best_compression。
index.codec: best_compression特定字段的内容存储
查询的时候,如果想要获取原始字段,需要在_source中获取,因为所有的字段存储在一起,所以获取完整的文档内容与获取其中某个字段,在资源消耗上几乎相同,只是返回给客户端的时候,减少了一定量的网络IO。
ES提供了特定字段内容存储的设置,在设置mappings的时候可以开启,默认是false。如果你的文档内容很大,而其中某个字段的内容有需要经常获取,可以设置开启,将该字段的内容单独存储。
PUT my_index
{
"mappings": {
"_doc": {
"properties": {
"title": {
"type": "text",
"store": true
}
}
}
}
}
倒排索引
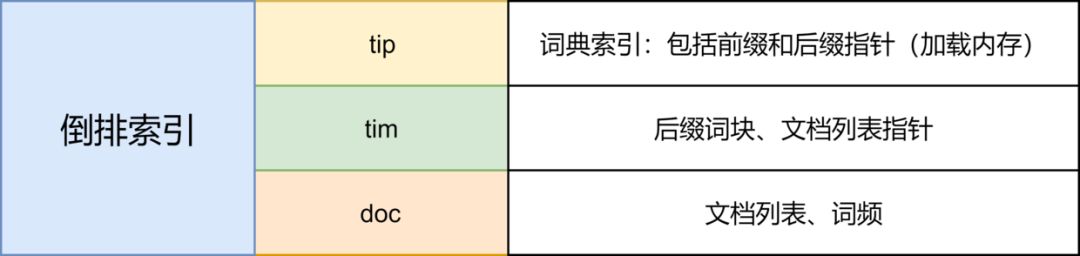
倒排索引中记录的信息主要有:
文档编号:segment内部文档编号从0开始,最大值为int最大值,文档写入之后会分配这样一个顺序号
字典:字段内容经过分词、归一化、还原词根等操作之后,得到的所有单词
单词出现位置:
▫分词字段默认开启,提供对于短语查询的支持
▫对于非常常见的词,例如the,位置信息可能占用很大空间,短语查询需要读取的数据量很大,查询速度慢
单词出现次数:单词在文档中出现的次数,作为评分的依据
单词结束字符到开始字符的偏移量:记录在文档中开始与结束字符的偏移量,提供高亮使用,默认是禁用的
规范因子:对字段长度进行规范化的因子,给予较短字段更多权重
倒排索引的查找过程本质上是通过单词找对应的文档列表的过程,因此倒排索引中字典的设计决定了倒排索引的查询速度,字典主要包括前缀索引(.tip文件)和后缀索引(.tim)文件。
字典前缀索引(.tip文件)
一个合格的词典结构一般有以下特点:
-查询速度快 -内存占用小 -内存+磁盘相结合
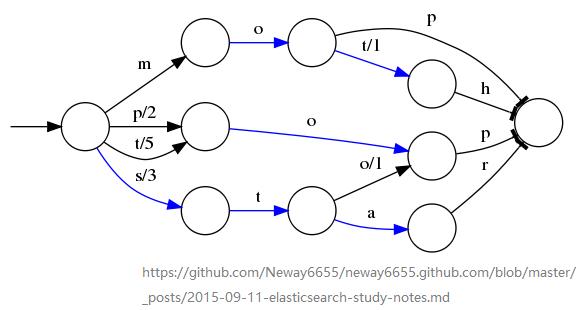
Lucene采用的前缀索引数据结构为FST,它的优点有:
词查找复杂度为O(len(str))
共享前缀、节省空间、内存占用率低,压缩率高,模糊查询支持好
内存存放前缀索引,磁盘存放后缀词块
缺点:结构复杂、输入要求有序、更新不易
字典后缀(.tim文件)
后缀词块主要保存了单词后缀,以及对应的文档列表的位置。
文档列表(.doc文件)
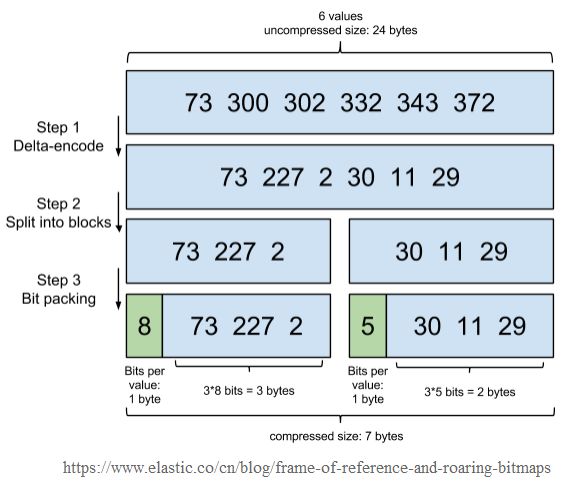
lucene对文档列表存储进行了很好的压缩,来保证缓存友好:
差分压缩:每个ID只记录跟前面的ID的差值
每256个ID放入一个block中
block的头信息存放block中每个ID占用的bit位数,因为经过上面的差分压缩之后,文档列表中的文档ID都变得不大,占用的bit位数变少
上图经过压缩之后将6个数字从原先的24bytes压缩到7bytes。
文档列表的合并
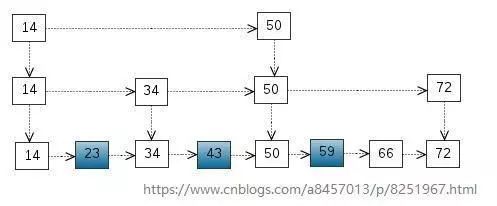
ES的一个重要的查询场景是bool查询,类似于mysql中的and操作,需要将两个条件对应的文档列表进行合并。为了加快文档列表的合并,lucene底层采用了跳表的数据结构,合并过程中,优先遍历较短的链表,去较长的列表中进行查询,如果存在,则该文档符合条件。
倒排索引的查询过程
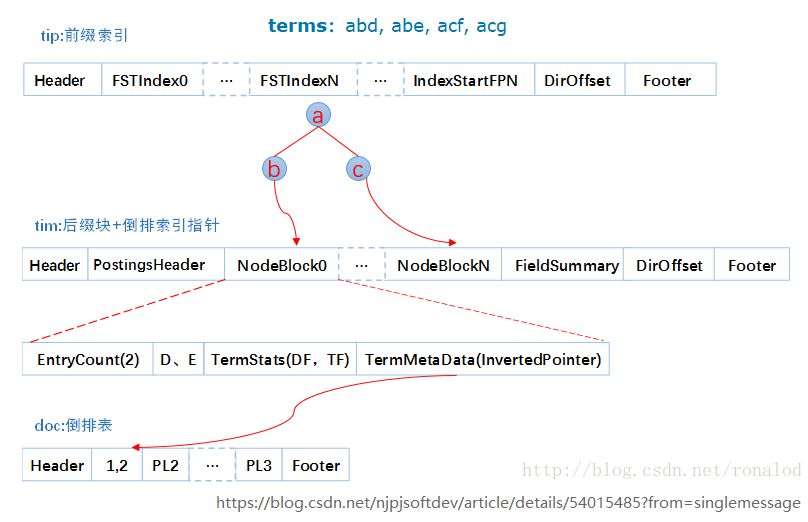
内存加载tip文件,通过FST匹配前缀找到后缀词块位置
根据词块位置,读取磁盘中tim文件中后缀块并找到后缀和相应的倒排表位置信息
根据倒排表位置去doc文件中加载倒排表
借助跳表结构,对多个文档列表进行合并
filter查询的缓存
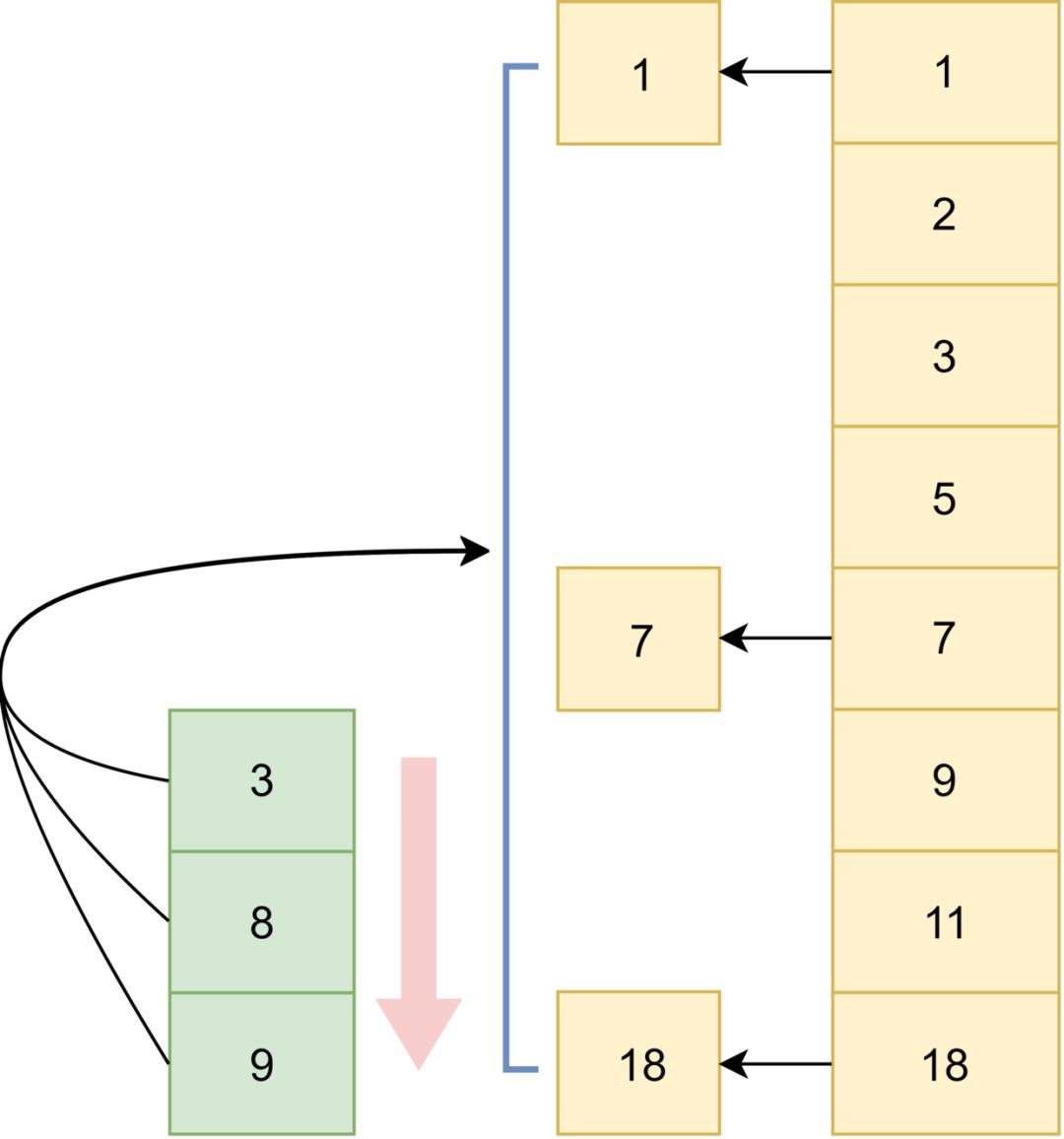
对于filter过滤查询的结果,ES会进行缓存,缓存采用的数据结构是RoaringBitmap,在match查询中配合filter能有效加快查询速度。
普通bitset的缺点:内存占用大,RoaringBitmap有很好的压缩特性
分桶:解决文档列表稀疏的情况下,过多的0占用内存,每65536个docid分到一个桶,桶内只记录docid%65536
桶内压缩:4096作为分界点,小余这个值用short数组,大于这个值用bitset,每个short占两字节,4096个short占用65536bit,所以超过4096个文档id之后,是bitset更节省空间。

DocValues(正排索引&列式存储)

倒排索引保存的是词项到文档的映射,也就是词项存在于哪些文档中,DocValues保存的是文档到词项的映射,也就是文档中有哪些词项。
相关设置
keyword字段默认开启
ES6.0(lucene7.0)之前
DocValues采用的数据结构是bitset,bitset对于稀疏数据的支持不好:
对于稀疏的字段来说,绝大部分的空间都被0填充,浪费空间
由于字段的值之间插入了0,可能本来连续的值被0间隔开来了,不利于数据的压缩
空间被一堆0占用了,缓存中缓存的有效数据减少,查询效率也会降低
查询逻辑很简单,类似于数组通过下标进行索引,因为每个value都是固定长度,所以读取文档id为N的value直接从N*固定长度位置开始读取固定长度即可。
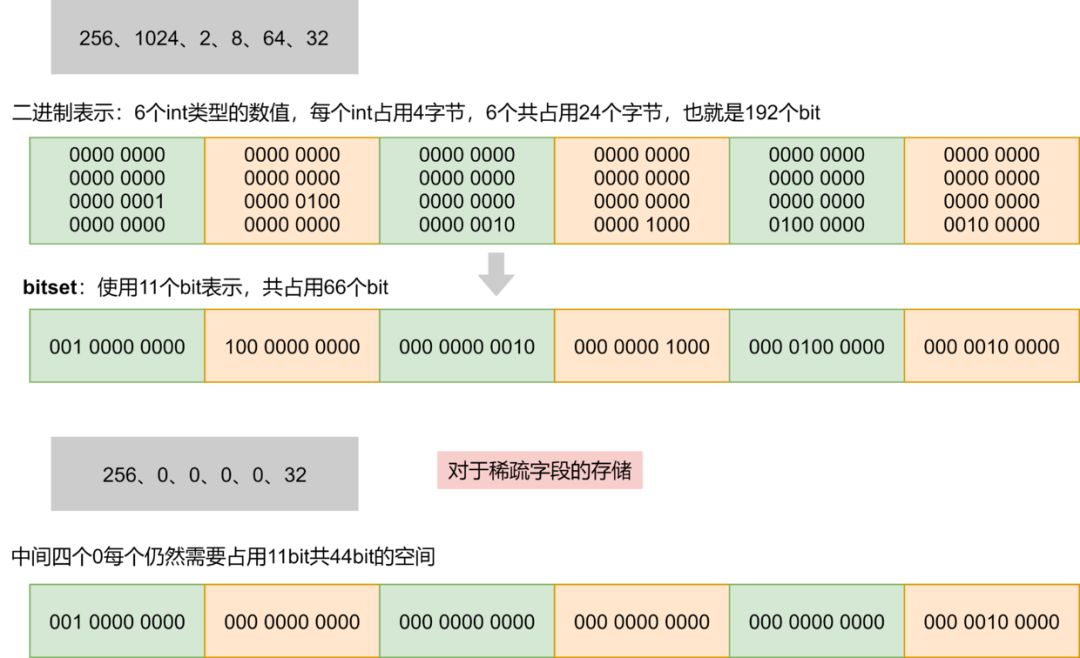
ES6.0(lucene7.0)
docid的存储的通过分片加快映射到value的查询速度
value存储的时候不再给空的值分配空间
因为value存储的时候,空值不再分配空间,所以查询的时候不能通过上述通过文档id直接映射到在bitset中的偏移量来获取对应的value,需要通过获取docid的位置来找到对应的value的位置。
所以对于DocValues的查找,关键在于DocIDSet中ID的查找,如果按照简单的链表的查找逻辑,那么DocID的查找速度将会很慢。lucene7借用了RoaringBitmap的分片的思想来加快DocIDSet的查找速度:
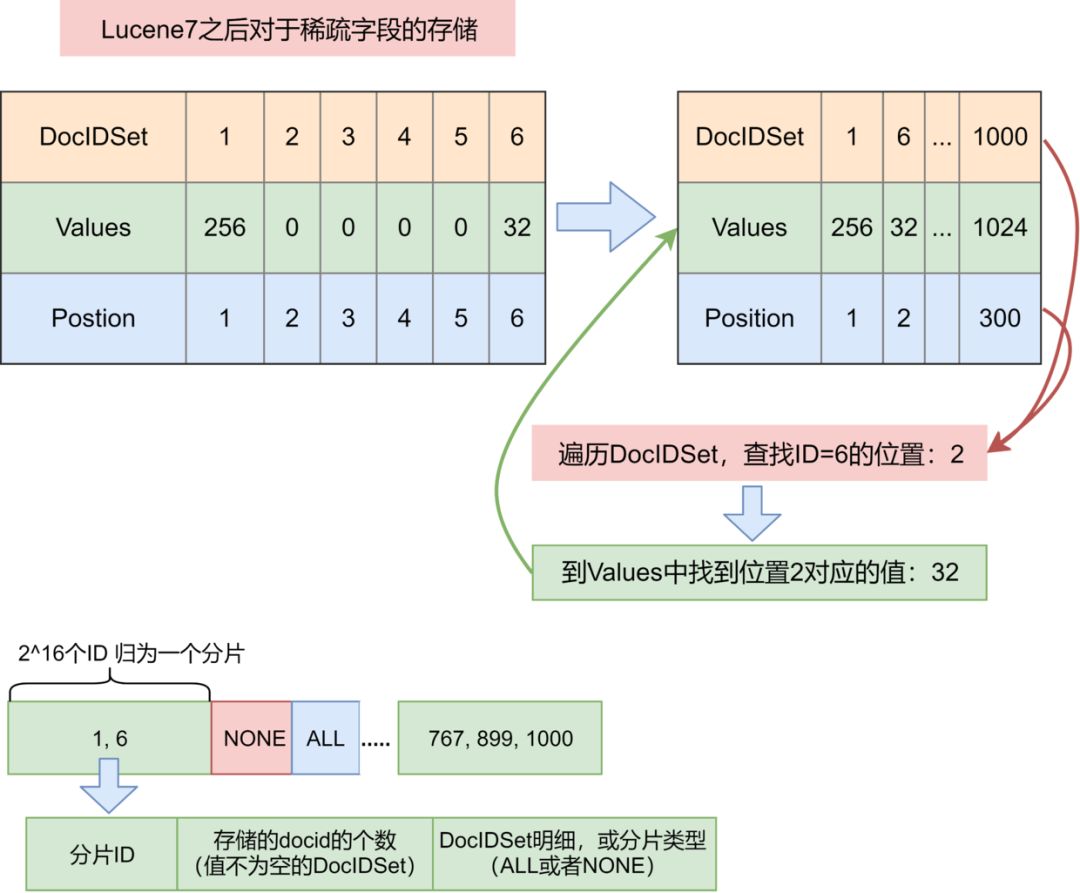
分片容量为2的16次方,最多可以存储65536个docid
分片包含的信息:
▫分片ID
▫存储的docid的个数(值不为空的DocIDSet)
▫DocIDSet明细,或者标记分片类型(ALL或者NONE)
根据分片的容量,将分片分为四种不同的类型,不同类型的查找逻辑不通:
▫ALL:该分片内没有不存在值的DocID
▫NONE:该分片内所有的DocID都不存在值
▫SPARSE:该分片内存在值的DocID的个数不超过4096,DocIDSet以short数组的形式存储,查找的时候,遍历数组,找到对应的ID的位置
▫DENSE:该分片内存在值的DocID的个数超过4096,DocIDSet以bitset的形式存储,ID的偏移量也就是在该分片中的位置
最终DocIDSet的查找逻辑为:
计算DocID/65536,得到所在的分片N
计算前面N-1个分片的DocID的总数
找到DocID在分片N内部的位置,从而找到所在位置之前的DocID个数M
找到N+M位置的value即为该DocID对应的value
数据查询
查询过程(query then fetch)
协调节点将请求发送给对应分片
分片查询,返回from+size数量的文档对应的id以及每个id的得分
汇总所有节点的结果,按照得分获取指定区间的文档id
根据查询需求,像对应分片发送多个get请求,获取文档的信息
返回给客户端
get查询更快
默认根据id对文档进行路由,所以指定id的查询可以定位到文档所在的分片,只对某个分片进行查询即可。当然非get查询,只要写入和查询的时候指定routing,同样可以达到该效果。
主分片与副本分片
ES的分片有主备之分,但是对于查询来说,主备分片的地位完全相同,平等的接收查询请求。这里涉及到一个请求的负载均衡策略,6.0之前采用的是轮询的策略,但是这种策略存在不足,轮询方案只能保证查询数据量在主备分片是均衡的,但是不能保证查询压力在主备分片上是均衡的,可能出现慢查询都路由到了主分片上,导致主分片所在的机器压力过大,影响了整个集群对外提供服务的能力。
新版本中优化了该策略,采用了基于负载的请求路由,基于队列的耗费时间自动调节队列长度,负载高的节点的队列长度将减少,让其他节点分摊更多的压力,搜索和索引都将基于这种机制。
get查询的实时性
ES数据写入之后,要经过一个refresh操作之后,才能够创建索引,进行查询。但是get查询很特殊,数据实时可查。
ES5.0之前translog可以提供实时的CRUD,get查询会首先检查translog中有没有最新的修改,然后再尝试去segment中对id进行查找。5.0之后,为了减少translog设计的负责性以便于再其他更重要的方面对translog进行优化,所以取消了translog的实时查询功能。
get查询的实时性,通过每次get查询的时候,如果发现该id还在内存中没有创建索引,那么首先会触发refresh操作,来让id可查。
查询方式
两种查询上下文:
query:例如全文检索,返回的是文档匹配搜索条件的相关性,常用api:match
filter:例如时间区间的限定,回答的是是否,要么是,要么不是,不存在相似程度的概念,常用api:term、range
过滤(filter)的目标是减少那些需要进行评分查询(scoring queries)的文档数量。
分析器(analyzer)
当索引一个文档时,它的全文域被分析成词条以用来创建倒排索引。当进行分词字段的搜索的时候,同样需要将查询字符串通过相同的分析过程,以保证搜索的词条格式与索引中的词条格式一致。当查询一个不分词字段时,不会分析查询字符串,而是搜索指定的精确值。
可以通过下面的命令查看分词结果:
GET /_analyze
{
"analyzer": "standard",
"text": "Text to analyze"
}相关性
默认情况下,返回结果是按相关性倒序排列的。每个文档都有相关性评分,用一个正浮点数字段score来表示。score的评分越高,相关性越高。
ES的相似度算法被定义为检索词频率/反向文档频率(TF/IDF),包括以下内容:
检索词频率:检索词在该字段出现的频率,出现频率越高,相关性也越高。字段中出现过5次要比只出现过1次的相关性高。
反向文档频率:每个检索词在索引中出现的频率,频率越高,相关性越低。检索词出现在多数文档中会比出现在少数文档中的权重更低。
字段长度准则:字段的长度是多少,长度越长,相关性越低。 检索词出现在一个短的title要比同样的词出现在一个长的content字段权重更大。
查询的时候可以通过添加?explain参数,查看上述各个算法的评分结果。
ES在Ad Tracking的应用
日志查询工具
TalkingData 移动广告监测产品Ad Tracking(简称ADT)的系统会接收媒体发过来的点击数据以及SDK发过来的激活和各种效果点数据,这些数据的处理过程正确与否至关重要。例如,设备的一条激活数据为啥没有归因到点击,这类问题的排查在Ad Tracking中很常见,通过将数据流中的各个处理环节的重要日志统一发送到ES,可以很方便的进行查询,技术支持的同事可以通过拼写简单的查询条件排查客户的问题。
索引按天创建:定时关闭历史索引,释放集群资源
别名查询:数据量增大之后,可以通过拆分索引减轻写入压力,拆分之后的索引采用相同的别名,查询服务不需要修改代码
索引重要的设置:
{
"settings": {
"index": {
"refresh_interval": "120s",
"number_of_shards": "12",
"translog": {
"flush_threshold_size": "2048mb"
},
"merge": {
"scheduler": {
"max_thread_count": "1"
}
},
"unassigned": {
"node_left": {
"delayed_timeout": "180m"
}
}
}
}
}
索引mapping的设置
{
"properties": {
"action_content": {
"type": "string",
"analyzer": "standard"
},
"time": {
"type": "long"
},
"trackid": {
"type": "string",
"index": "not_analyzed"
}
}
}
sql插件,通过拼sql的方式,比起拼json更简单
点击数据存储(kv存储场景)
Ad Tracking收集的点击数据是与广告投放直接相关的数据,应用安装之后,SDK会上报激活事件,系统会去查找这个激活事件是否来自于之前用户点击的某个广告,如果是,那么该激活就是一个推广量,也就是投放的广告带来的激活。激活后续的效果点数据也都会去查找点击,从点击中获取广告投放的一些信息,所以点击查询在Ad Tracking的业务中至关重要。
业务的前期,点击数据是存储在Mysql中的,随着后续点击量的暴增,由于Mysql不能横向扩展,所以需要更换为新的存储。由于ES拥有横向扩展和强悍的搜索能力,并且之前日志查询工具中也一直使用ES,所以决定使用ES来进行点击的存储。
重要的设置
"refresh_interval": "1s"
"translog.flush_threshold_size": "2048mb"
"merge.scheduler.max_thread_count": 1
"unassigned.node_left.delayed_timeout": "180m"
结合业务进行系统优化
结合业务定期关闭索引释放资源:Ad Tracking的点击数据具有有效期的概念,超过有效期的点击,激活不会去归因。点击有效期最长一个月,所以理论上每天创建的索引在一个月之后才能关闭。但是用户配置的点击有效期大部分都是一天,这大部分点击在集群中保存30天是没有意义的,而且会占用大部分的系统资源。所以根据点击的这个业务特点,将每天创建的索引拆分成两个,一个是有效期是一天的点击,一个是超过一天的点击,有效期一天的点击的索引在一天之后就可以关闭,从而保证集群中打开的索引的数据量维持在一个较少的水平。
结合业务将热点数据单独索引:激活和效果点数据都需要去ES中查询点击,但是两者对于点击的查询场景是有差异的,因为效果点事件(例如登录、注册等)归因的时候不是去直接查找点击,而是查找激活进而找到点击,效果点要找的点击一定是之前激活归因到的,所以激活归因到的这部分点击也就是热点数据。激活归因到点击之后,将这部分点击单独存储到单独的索引中,由于这部分点击量少很多,所以效果点查询的时候很快。
索引拆分:Ad Tracking的点击数据按天进行存储,但是随着点击量的增大,单天的索引大小持续增大,尤其是晚上的时候,merge需要合并的segment数量以及大小都很大,造成了很高的IO压力,导致集群的写入受限。后续采用了拆分索引的方案,每天的索引按照上午9点和下午5点两个时间点将索引拆分成三个,由于索引之间的segment合并是相互独立的,只会在一个索引内部进行segment的合并,所以在每个小索引内部,segment合并的压力就会减少。
其他调优
分片的数量
经验值:
每个节点的分片数量保持在低于每1GB堆内存对应集群的分片在20-25之间。
分片大小为50GB通常被界定为适用于各种用例的限制。
JVM设置
堆内存设置:不要超过32G,在Java中,对象实例都分配在堆上,并通过一个指针进行引用。对于64位操作系统而言,默认使用64位指针,指针本身对于空间的占用很大,Java使用一个叫作内存指针压缩(compressed oops)的技术来解决这个问题,简单理解,使用32位指针也可以对对象进行引用,但是一旦堆内存超过32G,这个压缩技术不再生效,实际上失去了更多的内存。
预留一半内存空间给lucene用,lucene会使用大量的堆外内存空间。
如果你有一台128G的机器,一半内存也是64G,超过了32G,可以通过一台机器上启动多个ES实例来保证ES的堆内存小于32G。
ES的配置文件中加入bootstrap.mlockall: true,关闭内存交换。
通过_cat api获取任务执行情况
GET http://localhost:9201/_cat/thread_pool?v&h=host,search.active,search.rejected,search.completed
完成(completed)
进行中(active)
被拒绝(rejected):需要特别注意,说明已经出现查询请求被拒绝的情况,可能是线程池大小配置的太小,也可能是集群性能瓶颈,需要扩容。
小技巧
重建索引或者批量想ES写历史数据的时候,写之前先关闭副本,写入完成之后,再开启副本。
ES默认用文档id进行路由,所以通过文档id进行查询会更快,因为能直接定位到文档所在的分片,否则需要查询所有的分片。
使用ES自己生成的文档id写入更快,因为ES不需要验证一次自定义的文档id是否存在。
参考资料
https://www.elastic.co/guide/cn/elasticsearch/guide/current/index.html
https://github.com/Neway6655/neway6655.github.com/blob/master/_posts/2015-09-11-elasticsearch-study-notes.md
https://www.elastic.co/blog/frame-of-reference-and-roaring-bitmaps
https://blog.csdn.net/zteny/article/details/85245967
https://www.elastic.co/blog/minimize-index-storage-size-elasticsearch-6-0封面图来源于网络,如有侵权,请联系删除
推荐阅读:
好看就给点下呗 以上是关于技术专栏丨从原理到应用,Elasticsearch详解(下)的主要内容,如果未能解决你的问题,请参考以下文章 技术专栏 | 利用HDFS备份实现Elasticsearch容灾 TiDB 在平安科技丨从 Oracle 迁移到 UbiSQL 的实践 Elasticsearch技术专栏 | 利用HDFS备份实现Elasticsearch容灾