小猪教你搭建ES ELK(Elasticsearch/Logstash/Kibana)
Posted 小猪实验室
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小猪教你搭建ES ELK(Elasticsearch/Logstash/Kibana)相关的知识,希望对你有一定的参考价值。
Elasticsearch 是一个分布式、可扩展、实时的搜索与数据分析引擎。它不仅仅只是全文搜索,还支持结构化搜索、数据分析、复杂的语言处理、地理位置和对象间关联关系等,同时具备水平伸缩性和集群监控等完备的功能。
ES常见组合被称为ELK(F),他们分别是:
(1)Elasticsearch:开源分布式搜索引擎,提供搜集、分析、存储数据三大功能。它的特点有:分布式,零配置,自动发现,索引自动分片,索引副本机制,restful风格接口,多数据源,自动搜索负载等。
(2)Logstash :主要是用来日志的搜集、分析、过滤日志的工具,支持大量的数据获取方式。一般工作方式为c/s架构,client端安装在需要收集日志的主机上,server端负责将收到的各节点日志进行过滤、修改等操作在一并发往elasticsearch上去。Logstash事件处理有三个阶段:inputs → filters → outputs。是一个接收,处理,转发日志的工具。支持系统日志,webserver日志,错误日志,应用日志,总之包括所有可以抛出来的日志类型。
(3)Kibana:用于为 Logstash 和 ElasticSearch 提供友好的日志分析 Web 界面,可以帮助汇总、分析和搜索重要数据日志。
(4)Filebeat:搜集文件数据的工具。Filebeat由两个主要组件组Prospectors 和 Harvesters。Prospector(勘测者)负责管理Harvester并找到所有读取源文件。Harvester(收割机):负责读取单个文件内容。
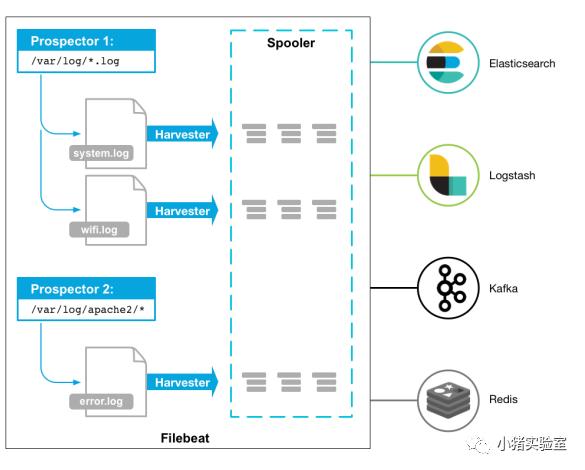
官方文档:
Filebeat:
https://www.elastic.co/cn/products/beats/filebeat
https://www.elastic.co/guide/en/beats/filebeat/5.6/index.html
Logstash:
https://www.elastic.co/cn/products/logstash
https://www.elastic.co/guide/en/logstash/5.6/index.html
Kibana:
https://www.elastic.co/cn/products/kibana
https://www.elastic.co/guide/en/kibana/5.5/index.html
Elasticsearch:
https://www.elastic.co/cn/products/elasticsearch
https://www.elastic.co/guide/en/elasticsearch/reference/5.6/index.html
elasticsearch中文社区:
https://elasticsearch.cn/
常见的ELK架构:
架构图一:
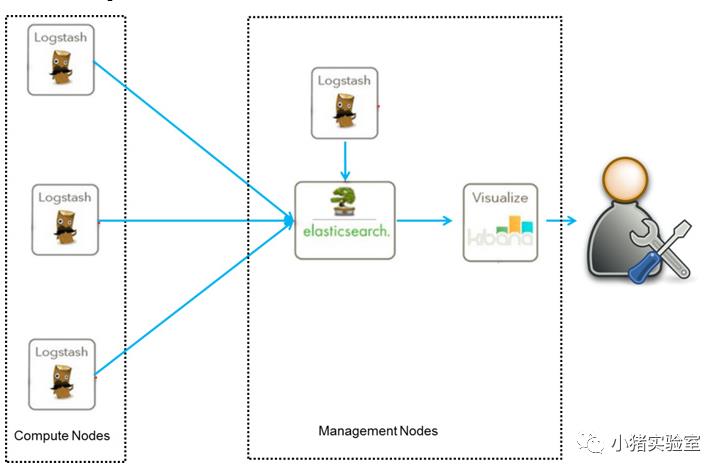
这是最简单的一种ELK架构方式。优点是搭建简单,易于上手。缺点是Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。
此架构由Logstash分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。Elasticsearch将数据以分片的形式压缩存储并提供多种API供用户查询,操作。用户亦可以更直观的通过配置Kibana Web方便的对日志查询,并根据数据生成报表。
架构图二:
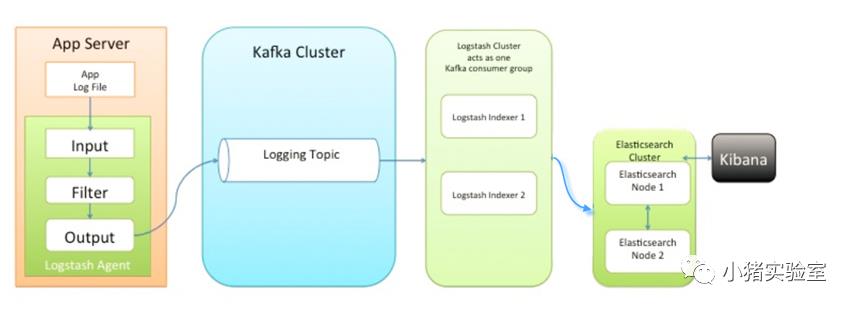
此种架构引入了消息队列机制,位于各个节点上的Logstash Agent先将数据/日志传递给Kafka(或者Redis),并将队列中消息或数据间接传递给Logstash,Logstash过滤、分析后将数据传递给Elasticsearch存储。最后由Kibana将日志和数据呈现给用户。因为引入了Kafka(或者Redis),所以即使远端Logstash server因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
架构图三:
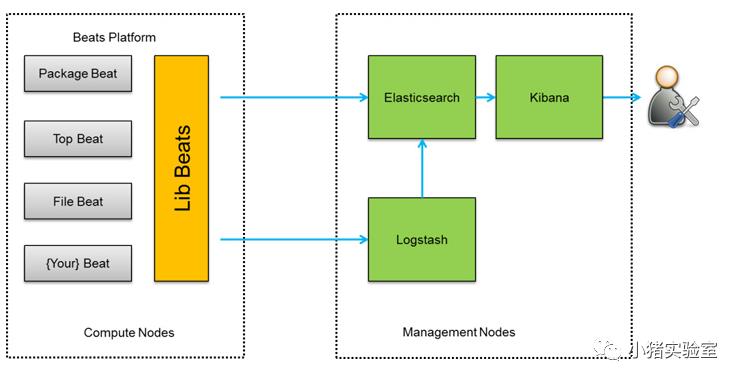
此种架构将收集端logstash替换为beats,更灵活,消耗资源更少,扩展性更强。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询。
beats包含:
Filebeat(搜集文件数据)
Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据)
Packetbeat(搜集网络流量数据)
Winlogbeat(搜集 Windows 事件日志数据)
下面使用“架构图一”的架构方式给大家讲解一下搭建和使用单个es节点的过程。
一、安装ELK
官网:https://www.elastic.co/cn/downloads/
1.通过yum安装ES
sudo vim /etc/yum.repos.d/elasticsearch.repo
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
sudo yum install elasticsearch kibana logstash
2.通过手工安装
# elasticsearch
wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.2.0-linux-x86_64.tar.gz
tar zxvf elasticsearch-7.2.0-linux-x86_64.tar.gz
mv elasticsearch-7.2.0 elasticsearch
cd elasticsearch
# logstash: 一个开源的日志收集管理工具
wget https://artifacts.elastic.co/downloads/logstash/logstash-7.2.0.tar.gz
tar zxvf logstash-7.2.0.tar.gz
mv logstash-7.2.0 logstash
# kibana: 一个开源的分析和可视化平台
wget https://artifacts.elastic.co/downloads/kibana/kibana-7.2.0-linux-x86_64.tar.gz
tar zxvf kibana-7.2.0-linux-x86_64.tar.gz
mv kibana-7.2.0-linux-x86_64 kibana
# filebeat: 搜集文件数据的工具
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.2.1-linux-x86_64.tar.gz
tar zxvf filebeat-7.2.1-linux-x86_64.tar.gz
mv filebeat-7.2.1-linux-x86_64 filebeat
二、配置/启动ES
1.设置
cd elasticsearch
vim config/elasticsearch.yml
cluster.name: mars #集群名
node.name: node-1 #节点名
network.host: 0.0.0.0 #对外ip
cluster.initial_master_nodes: ["node-1"] #节点发现
http.port: 9200 #http端口
sudo vim /etc/sysctl.conf
vm.max_map_count=262144 #jvm最大线程数(默认为65530)
sudo vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 65536
sudo vim /etc/security/limits.d/90-nproc.conf
* soft nproc 4096
sysctl -p #重新加载内核配置
2.启动
./bin/elasticsearch -d
*注:如果启动不成功,查看tail logs/mars.log
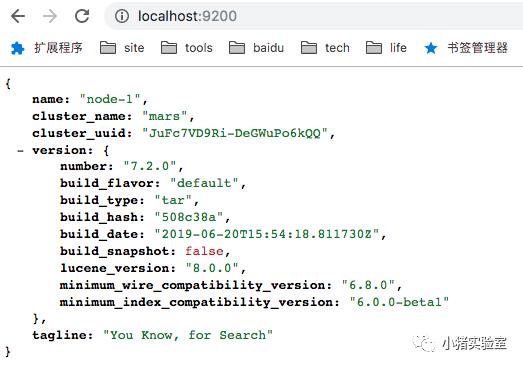
3.测试
curl 127.0.0.1:9200 # 或curl 47.92.25.83:9200
{
"name" : "node-1",
"cluster_name" : "mars",
"cluster_uuid" : "-w0zaSbWTweFFQiL4aYnIA",
"version" : {
"number" : "7.2.0",
"build_flavor" : "default",
"build_type" : "tar",
"build_hash" : "508c38a",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
4.设置密码
vim config/elasticsearch.yml
xpack.security.enabled: true #开启安全认证
xpack.security.transport.ssl.enabled: true #开启ssl
./bin/elasticsearch-setup-passwords interactive
Initiating the setup of passwords for reserved users elastic,apm_system,kibana,logstash_system,beats_system,remote_monitoring_user.
You will be prompted to enter passwords as the process progresses.
Please confirm that you would like to continue [y/N]y
Enter password for [elastic]:
Reenter password for [elastic]:
Enter password for [apm_system]:
Reenter password for [apm_system]:
Enter password for [kibana]:
Reenter password for [kibana]:
Enter password for [logstash_system]:
Reenter password for [logstash_system]:
Enter password for [beats_system]:
Reenter password for [beats_system]:
Enter password for [remote_monitoring_user]:
Reenter password for [remote_monitoring_user]:
Changed password for user [apm_system]
Changed password for user [kibana]
Changed password for user [logstash_system]
Changed password for user [beats_system]
Changed password for user [remote_monitoring_user]
Changed password for user [elastic]
*注:这里统一设置成了r1
5.重启
ps aux | grep elasticsearch |grep -v grep| cut -c 9-15 | xargs kill -9
./bin/elasticsearch -d
*注:如果启动不成功,查看tail logs/mars.log
6.用浏览器访问会提示输入用户名和密码
http://yanjingang.com:9200/
elastic/r1
三、配置/启动Kibana
1.配置
vim kibana/config/kibana.yml
server.port: 5601
server.host: "0.0.0.0"
elasticsearch.hosts: ["http://localhost:9200"]
elasticsearch.username: "elastic"
elasticsearch.password: "r1"
2.启动kibana
nohup ./kibana/bin/kibana > logs/kibana.log &
3.访问
http://yanjingang.com:5601/
elastic/ri
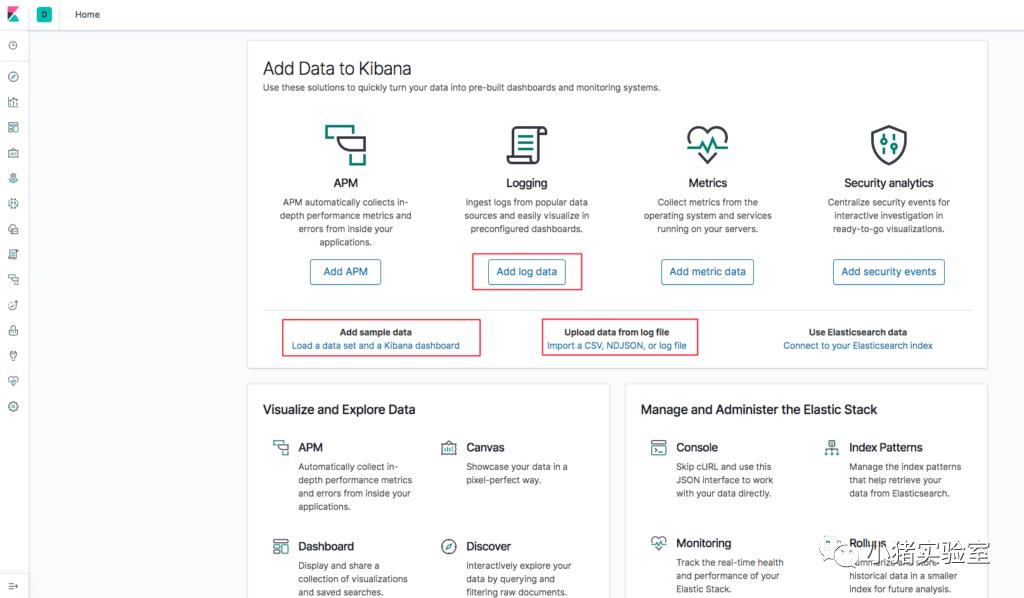
四、测试EK
主面板,可以通过监听nginx/apache/mysql/pgsql/kafka/redis日志(通过Filebeat tail send)、上传csv/json文件、添加示例数据等灌入数据:
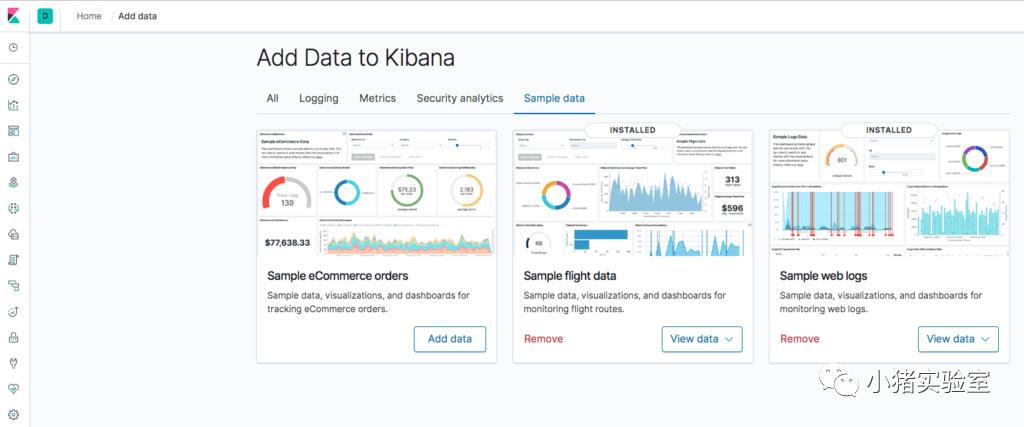
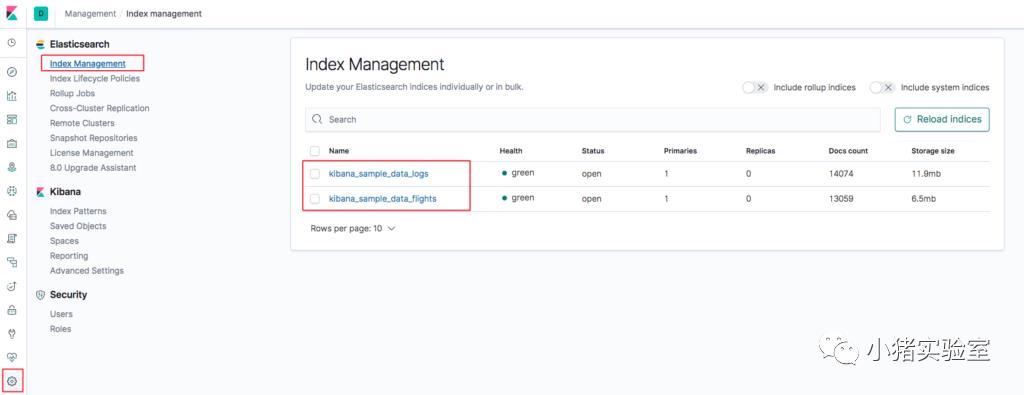
1.添加了飞行数据和web日志示例数据用于测试:
2.检索目的地是晴天且机票价格<200的中国航班:
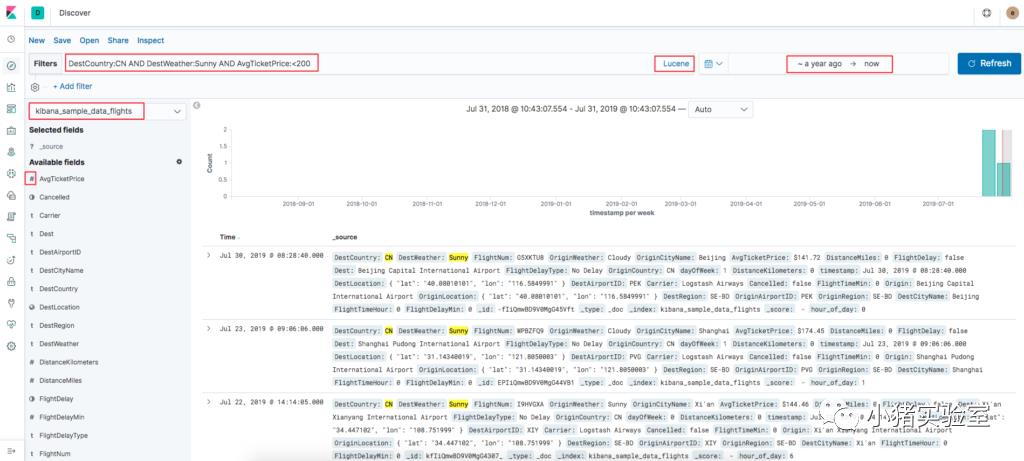
*注:查询表达式用Lucene格式,KQL太不灵活。
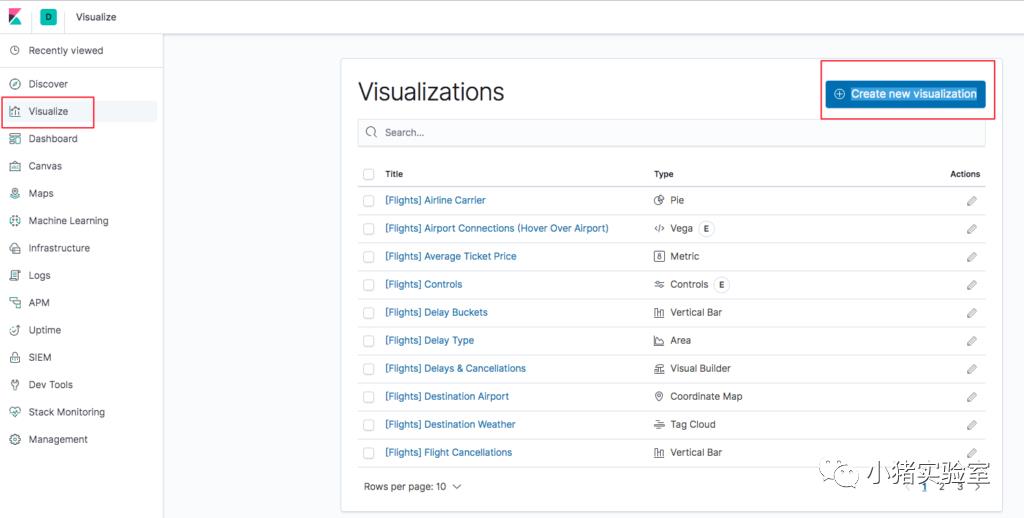
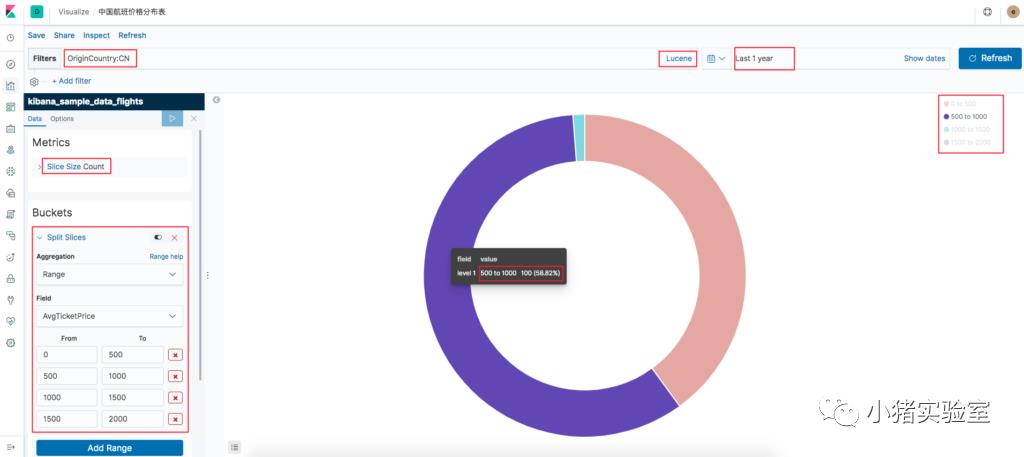
3.创建中国航班价格区间分析报表:
点击“Visualize->Create new visualization”,在弹出的报表类型上选择“Pie”饼图,并选择“kibana_sample_data_flights”飞行数据源
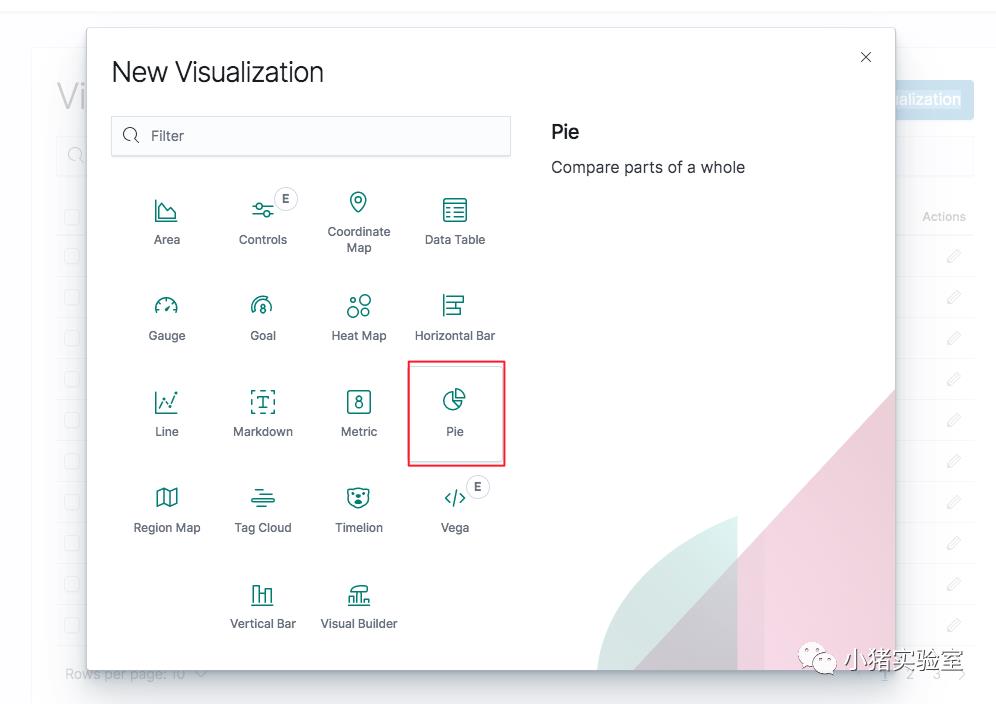
输入查询CN条件,添加要分析的价格分割区间,点击三角播放箭头,即可看到分析报表,点击save保存即可。
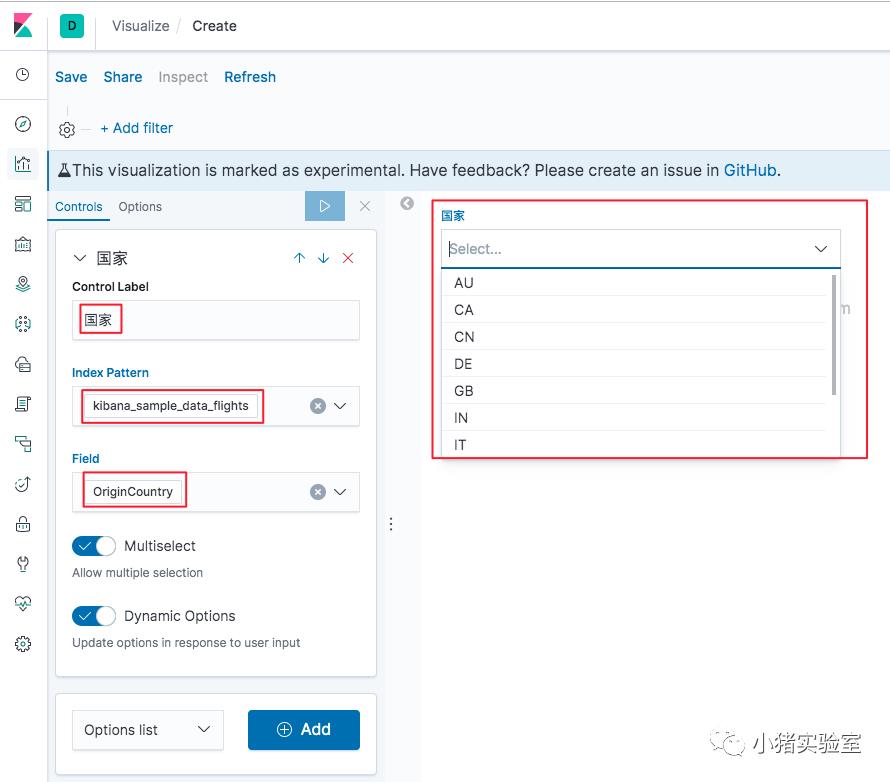
4.为航班价格报表添加国家筛选条件:
4.1 创建下拉控件:
点击“Visualize->Create new visualization”,在弹出的报表类型上选择“Controls”控件,在控件编辑界面选择“Options list”后点击“Add”,选择对应的数据源和字段后刷新即可看到效果,然后保存即可。
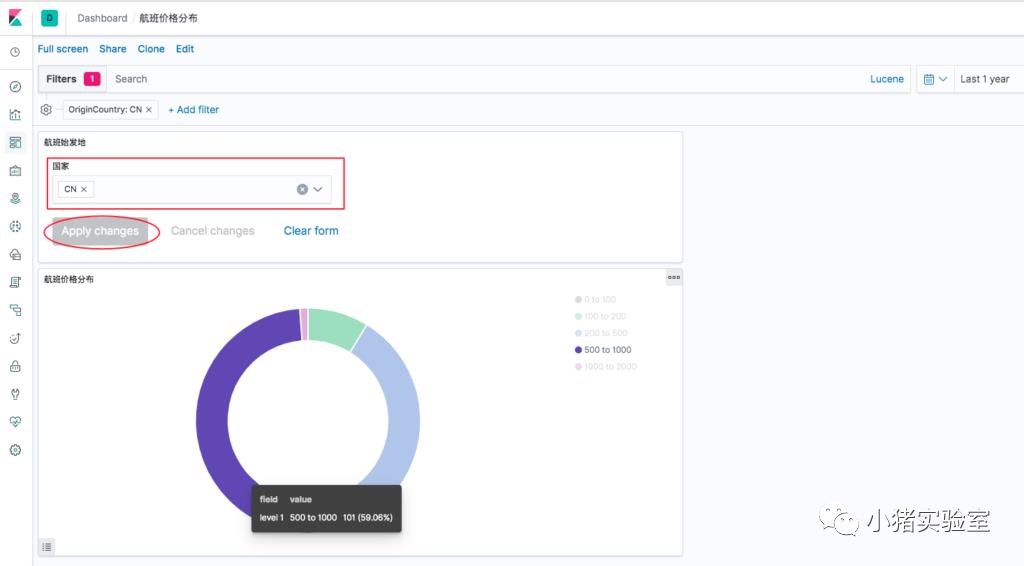
4.2 把Controls下拉控件和Pie报表放到一个Dashboard看板里:
点击“Dashboard->Create new dashboard”,点击“Add”按钮选择Visualize(航班始发地国家下拉控件 、航班价格分布表),在看板页面编辑样式,然后保存即可。
4.3 其他
添加示例数据后会有很多示例报表,可以支持表格、坐标地图、热图、柱状图、折线图、饼图、标签云等,也支持人工筛选条件、报表数据下载等,可以用来参考着实现自己的分析报表,还是非常方便的。
五、灌入数据->创建索引->检索
1.配置filebeat并导入操作系统日志
cd /home/work/filebeat
# 配置filebeat
vim filebeat.yml
output.elasticsearch:
hosts: ["localhost:9200"] #es配置
username: "elastic"
password: "r1"
setup.kibana:
host: "localhost:5601" #kibana配置
# 开启filebeat模块
./filebeat modules enable system #打开系统日志传输
#./filebeat modules enable nginx #打开nginx日志传输
./filebeat modules list #查看当前开启和关闭的模块
Enabled:
system
Disabled:
apache
auditd
cisco
coredns
elasticsearch
envoyproxy
haproxy
icinga
iis
iptables
kafka
kibana
logstash
mongodb
mysql
nats
netflow
nginx
osquery
panw
postgresql
rabbitmq
redis
santa
suricata
traefik
zeek
# 加载kibana看板
./filebeat setup
Index setup finished.
Loading dashboards (Kibana must be running and reachable)
Loaded dashboards
Loaded machine learning job configurations
Loaded Ingest pipelines
# 启动
su root #系统日志需要root权限才能访问
chown root:root /home/work/filebeat/ -R
./filebeat -e

系统日志已经被监控并自动导入es并在kibana里创建了对应一系列的报表和看板:
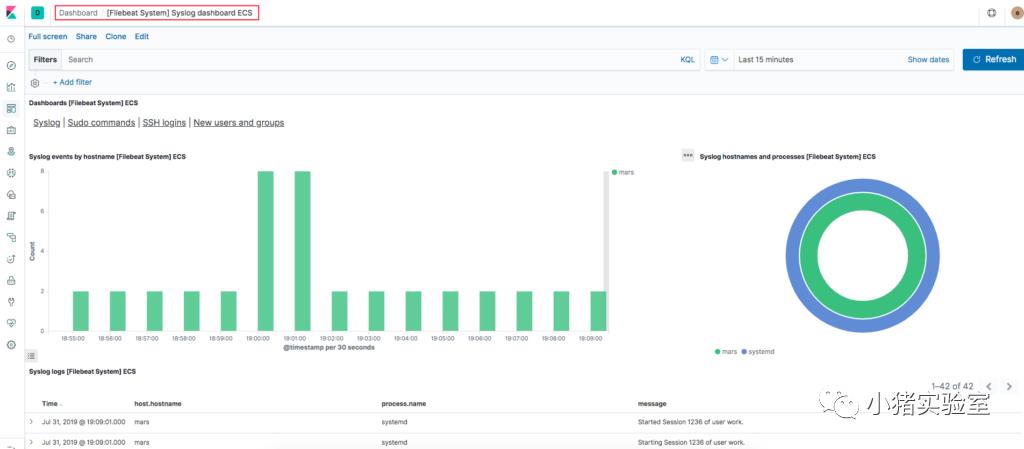
检索原始日志:
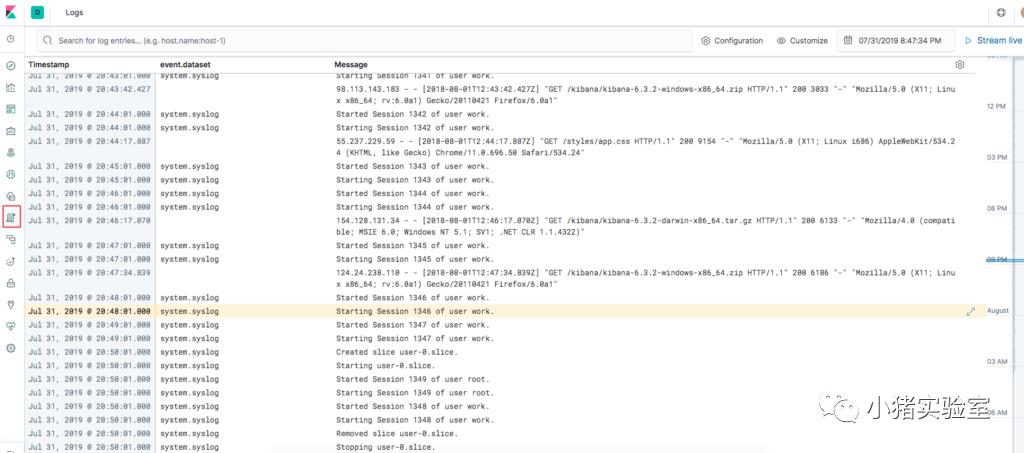
2.使用logstash监控并导入自定义json数据
2.1 创建json数据文件

*注:json值格式在导入es时会被自动识别设置,所以尽量按正式索引格式设置,例如int的别生成str。
2.2 配置/启动logstash
# 配置logstash读取json数据文件
vim config/logstash-tts.conf
input {
file {
path => ["/home/work/project/bumblebee_tts/data/music/split.data"]
start_position => "beginning" #从日志头部开始读取
codec => "json" #json格式
}
}
# output to es
output {
elasticsearch {
hosts => ["http://localhost:9200"] #es服务
index => "tts" #es索引名
document_id => "%{id}" #doc唯一id,索引更新用
# document_type => "tts" #用于filter等(7.x后将移除type,不推荐配置)
user => "elastic"
password => "r1"
}
}
# 启动logstash
./bin/logstash -f ./config/logstash-tts.conf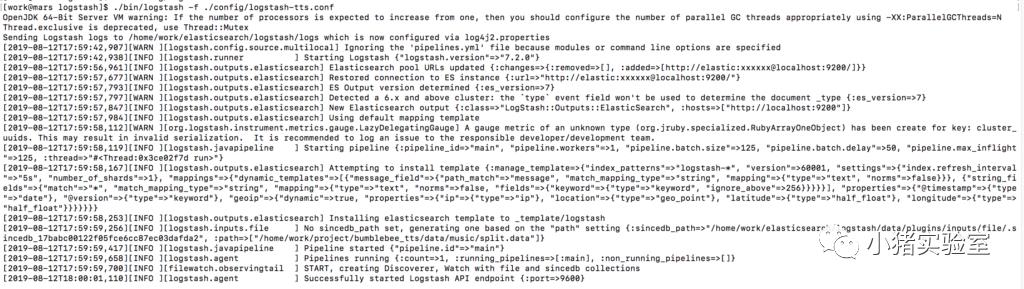
2.3 检查es index 索引是否成功创建
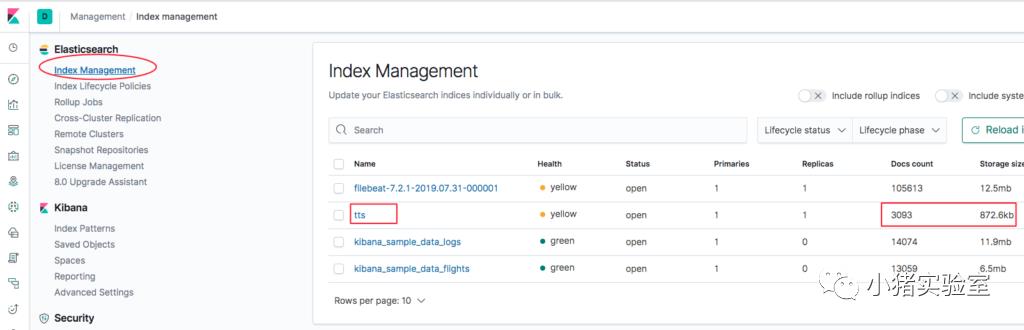
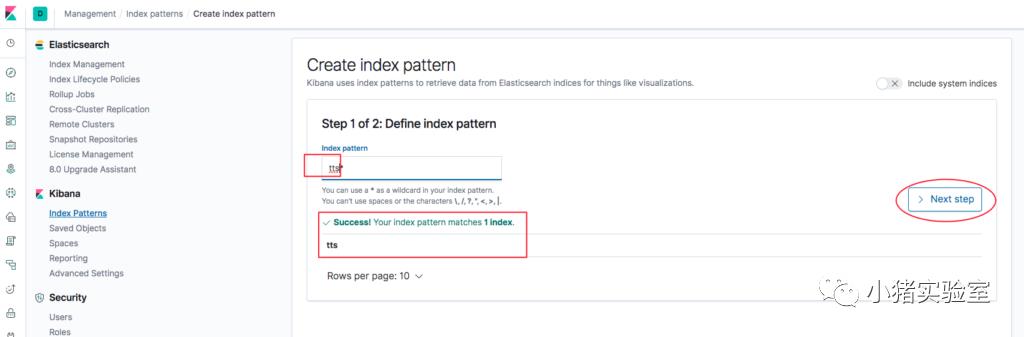
2.4 创建kibana Index patterns
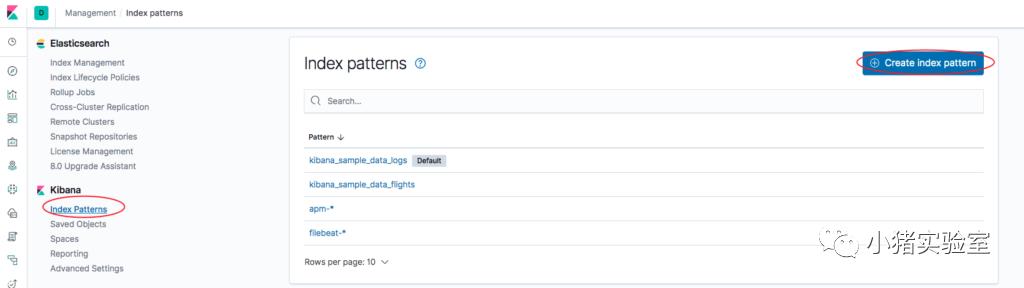
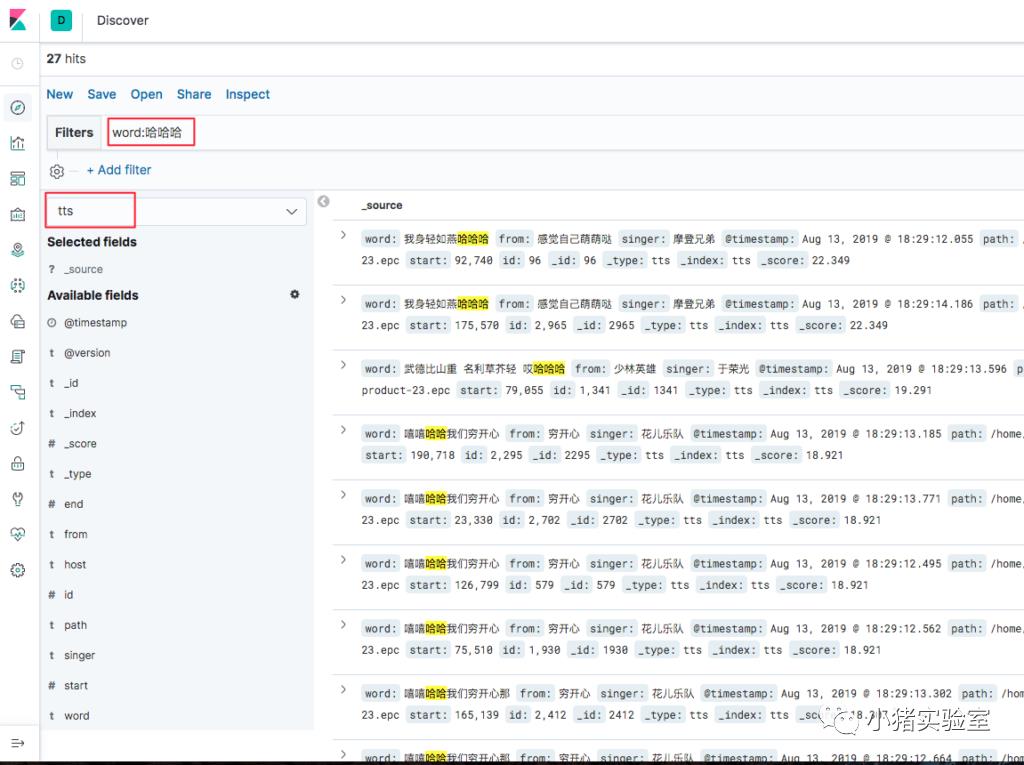
2.5 kibana检索测试
六、Useful APIs
1. api检索测试
# 查询tt索引中word:go的记录
curl --user elastic:r1 -X GET "http://yanjingang.com:9200/tts/_search?q=word:go&pretty"http://yanjingang.com:9200/tts/_search?q=word:哈哈哈

2. api删除tts索引下的所有数据
# 删除指定索引下的所有数据
curl --user elastic:r1 -X POST "http://yanjingang.com:9200/tts/_delete_by_query" -H 'Content-Type: application/json' -d '{"query":{"match_all": {}}}'
# 删除指定索引下符合条件的数据
curl --user elastic:r1 -X POST "http://yanjingang.com:9200/tts/_delete_by_query" -H 'Content-Type: application/json' -d '{"query":{"term": {"id":27}}}'
3. api插入数据
# 向tts索引插入_id=0的的测试记录
curl --user elastic:r1 -X PUT "http://yanjingang.com:9200/tts/_doc/0" -H 'Content-Type: application/json' -d '{"id":0,"word":"test"}'
# 检查_id=0的记录
curl --user elastic:r1 -X GET "http://yanjingang.com:9200/tts/_search?q=_id:0&pretty"
九、其他
节点资源监控
以上是关于小猪教你搭建ES ELK(Elasticsearch/Logstash/Kibana)的主要内容,如果未能解决你的问题,请参考以下文章
五分钟带你玩转docker实战elk环境——kibana搭建
五分钟带你玩转docker实战elk环境——kibana搭建
资深架构师教你如何使用elk+redis搭建nginx日志分析平台!
图文详解Docker搭建 ELK Stack (elk) [使用es-logstash-filebeat-kibana]