数据库事务系列-事务模型基础
Posted 数据管理
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库事务系列-事务模型基础相关的知识,希望对你有一定的参考价值。
从这篇文章开始,笔者将会在接下来很长时间里整理记录一个相对独立的知识领域-数据库事务,之所以忽然有这个想法,说来也是一种机缘巧合。本来是单纯计划写写HBase行级事务模型的具体实现的,但是在周末一不小心看了HBasecon2017里面一个talk之后就一发不可收拾了。这个talk的主题是 Transactions In HBase(作者详细介绍了基于HBase实现的3种强一致性分布式事务模型-Tephra | Trafodian | Omid),里面提到了Google的Percolater,刚好这个东东是前些天pingcap团队介绍TiDB时重点提到的一个分布式事务模型(TiDB中的事务模型就是借鉴Percolater实现),就想着好好研究一下这个Percolator,正好也有开源实现可以参考。这两天晚上看着看着,脑子又想起了两件事情,第一件事情是笔者在RDS团队的时候刚好了解记录过mysql的单机跨行事务模型,那会理解其实并不算深入,能不能借这个机会彻底弄懂;第二件事情是在考拉基础组件团队的时候接触过基于消息中间件的最终一致性分布式事务模型,虽然不属于数据库事务,但也是一种分布式事务实现思路。心想是不是可以把这些事务模型整理成一个系列,一方面是对自己知识体系的一次完善,另一方面可以和更多业界朋友从实际工程实现角度进行分享交流,汲取更多营养。于是就卷起袖子开始撸!
这个系列将从行级事务模型(HBase)开始,然后分析MySQL(InnoDB)的单机跨行事务模型,接着聊聊分布式事务模型。分布式事务模型又分为强一致性模型(Percolator、Omid以及TiDB)和基于补偿机制|消息中间件的最终一致性模型。
本篇文章分为两个部分,第一部分主要介绍一下事务ACID的概念,为后续分析各种事务模型奠定一个基础;第二部分主要介绍事务中隔离性的相关概念。事务ACID和隔离性在网上有很多解释版本,笔者接下来的介绍会与网上大体一致,但又不完全相同。如果看官已经了解了相关的概念,可以直接跳过这篇文章。
事务ACID概念
在系统讲解事务模型之前,我们首先要弄清楚两个问题,什么是事务?为什么需要事务?先来看看第二个问题,为什么需要事务,在现实生活中有很多类似于转账的操作(A转1w块钱到B账户,先扣A1w,再给B加1w),比如商品库存操作(销售一件商品,首先用户购物车商品删除,然后销售订单里面增加订单信息,再者需要将销售商品库存减1),再比如评论增加积分操作(首先要在评论表里面增加一条评论信息,再者需要在积分表里面增加相应的积分),这样的行为不胜枚举。分析起来,有两个典型特点,首先这些行为都不是单一操作,都是一系列操作,再者最后对结果的要求是要么全部执行成功,要么完全不执行,不能存在中间状态,比如转账中不能出现A扣减了1w但是B没有增加1w的场景,否则整个系统状态就完全混乱。
如果没有任何机制的保证,计算机在顺序执行多个操作(先扣钱、再加钱)的时候一旦发生异常,比如扣钱成功之后、加钱开始之前抛错,就会出现不可避免的中间状态。这就是事务存在的意义,那什么是事务呢?数据库事务(Database Transaction) ,是指作为单个逻辑工作单元执行的一系列操作,要么完全地执行,要么完全地不执行。这个定义摘自百度百科,简单的说就是,在我们看来扣钱、加钱是两个操作,但在事务看来就是一个操作。虽说看起来简单,但是真要成为事务,却必须满足ACID属性:
A(Atomicity) : 原子性,事务中的一系列操作要么全部完成,要么全部不完成,不能做了一半不做了。这个最好理解,比如转账不能扣完A的钱,不给B加钱。
I(Isolation) : 隔离性,多个事务之间相互隔离的特性。隔离是个很有意思的话题,也是事务模型里面比较复杂的点。首先不同业务对事务的隔离等级要求不一样,有的严格要求隔离,有的并不是那么严格。因此数据库系统都会实现多种隔离级别,从技术角度讲,每种隔离级别都需要不同的技术手段来保证,通常来说涉及各种锁和MVCC机制,后面两篇文章会重点解释隔离性。
D(Durability) : 持久性,事务一旦提交,所修改的数据就会被持久化,后面即使发生任何异常都不会出现数据丢失。这个容易理解,要么数据直接落盘,要么数据操作日志落盘。但是通常情况下数据库系统也一般会根据数据重要性提供多种持久化策略供客户端选择使用,比如对于重要数据,就会要求数据(WAL)同步落盘之后才能算事务完成,这是最严格的持久化策略;而对于部分不重要数据,可能只会要求数据(WAL)异步落盘就算事务完成。
C(Consistency) : 一致性,要求事务必须始终保持系统处于一致的状态。比如A转账给B,转账前账户总额和转账后账户总和需要保持一致。
系统的一致性是事务追求的最终结果,无论是原子性、隔离性或者持久性都是保证系统能够保证一致性的手段。比如一旦原子性无法满足,事务做到一半退出了,系统必然处于不一致的状态;再比如有三个小伙伴A、B和C,分别有100元。现有两个事务分别转账,1号事务从A向B转10元,2号事务从A向C转50元,如果1号事务或者2号事务对A账户不加锁的话,有可能出现1号事务和2号事务同时扣A的钱,1号事务扣完是90,2号事务正常应该在90的基础上扣减,但没有锁的话,有可能2号事务会在100的基础上扣减,A的账户在两次扣减结束后变为80元。这种场景就会出现系统不一致,整个事务结束之后A、B和C的总账户变成了310元。所以后面我们会讨论在事务隔离性实现中存在的各种Write-Write并发控制以及各种锁,其实很大部分原因就是为了保证事务的一致性要求。另外,如果持久化不能满足,事务提交之后数据出现了丢失,那系统也必然不一致。
和隔离性以及持久性一样,一致性也有五花八门的策略:强一致性、最终一致性、session级别一致性、因果一致性等等。强一致性是最容易理解的,在任意时刻整个系统都是一致的;最终一致性是最常见的一种弱一致性模型,简单的可以理解为一段时间之后,整个系统中的数据会最终达成一致,通常见于分布式系统中保持各个节点之间的数据一致。
隔离性概述
本来下半节文章是要讲HBase行级事务模型的,但是构思了一下,发现还是有必要在之前先把隔离性相关的基本概念解释清楚,后面HBase行级事务、MySQL单机跨行事务就可以专注于技术实现。
上文书提过,不同业务对事务的隔离等级要求并不一致,有的要求很严格,有的要求并不是那么严格。那通常实现中有哪些隔离等级?目前比较通用的隔离级别主要有4种:Read Uncommitted,Read Committed,Repeatable Read,Serializable。
1. Read Uncommitted
根据字面意思就可以看出,这种隔离级别下1号事务是可以读到2号事务还没有提交的数据,我们把这种现象称为脏读。脏读有什么问题?问题其实很严重,在很多场景下读到别人没有提交的数据,在此基础上所做的所有假设认知都会是错误的,因为这些数据有可能被回滚掉。生活中有大把大把这样的现象,你以为他订婚快要嫁人了默默转身离开,谁知道后来并没有结婚;你以为他画饼画的不错就死心跟着,谁知道结果没几天PPT就做不下去了~ 上图:
刚开始,1号事务和2号事务看到的A都是A0,接着1号事务将A0更新为A1,再接着2号事务就读到A1新值,岂料1号事务无情的将A1回滚回了A0。要保证绝对的准确,就不能相信忽悠,让别人拿事实说事~
2. Read Committed
很显然,Read Committed是与Read Uncommitted是相对的,意思是说1号事务可以在2号事务提交之后看到2号事务修改的数据。没错,这种隔离级别可以避免脏读,但是又引入了一个新的问题:不可重复读,如下图所示:
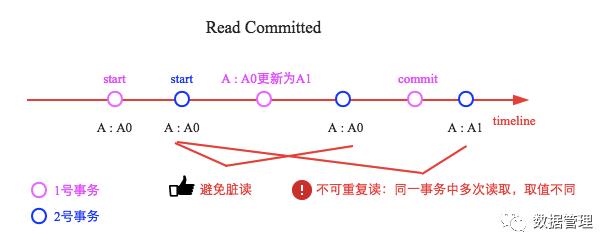
上图中2号事务在1号事务更新完成之后读取A的值依然是A0,避免了脏读;但在1号事务提交之后再次读取时发现读到的值变成了A1,出现了不同时间点对同一数据进行多次读取,会读到不同的值的现象。
这在现实生活中有什么问题吗?其实我觉得并没有什么问题,毕竟读的数据是真实的数据,但前后读到不一致的数据对我们的判断产生很大的影响。比如A同学看了看最近的任务排期,发现没有事情干了,于是就请假陪女朋友去巴厘岛旅游,刚到巴厘岛,扫了一眼邮件再次查看任务排期,发现leader发了一封紧急邮件,说要全员加班临时赶一个项目。A同学看到这封邮件的时候只能对着女友强颜欢笑…然后带女朋友买她最喜欢的LV~
所以最理想的就是我第一次看任务排期和我旅行期间再次看任务排期最好都是一样的,这样就可以保证本次旅行绝对happy。之后的事情之后再看喽。这就是接下来要介绍的可重复读~
3. Repeatable Read
从字面意思来看这种隔离级别修复了不可重复读这样的问题,表现如下图所示:
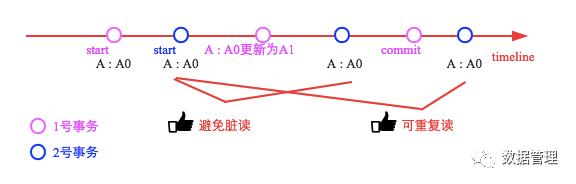
可以看出,无论1号事务如何更新A,2号事务在随后的进程中看到的A值都是事务开始第一次看到的A值(A0)。虽然解决了不可重复读的问题,但是还有一个问题-幻读:
上图中1号事务在事务过程中插入了一个大于B0的新值B2,2号事务在插入操作前后读取B > 0的时候读到的值却不同。那问题来了,幻读会在现实世界中引起什么样的严重后果吗?其实和不可重复读是一样的道理,前后读到的数据不一致会对当前的事情进展产生影响,不过幻读发生的场景相对少一些。
MySQL的童鞋需要注意,此处介绍和MySQL(InnoDB)中RR级别有些许不一样,MySQL中RR级别比较特殊,同时能够保证不可重复读和幻读。具体实现在接下来的文章《数据库事务系列-MySQL跨行事务模型》中会讲到。
4. Serializable
串性化是隔离最严格的一种形式,要求有读写冲突的事务必须严格串行执行。如下图所示,2号事务要读取1号事务修改的记录A,这就导致2号事务必须等待1号事务提交之后才能开启执行。通过这种形式可以避免之前所提到脏读、不可重复读和幻读。虽说如此,几乎所有数据库业务都不会开启这种隔离级别,因为这会带来严重的锁冲突。接下来几篇文章中涉及技术实现会再详细解释。
好了,本文主要介绍了数据库事务系列文章的概括,数据库事务的基本概念和ACID,最后介绍了各种隔离级别。接下来会进入具体数据库系统,分别介绍HBase行级事务模型、MySQL单机跨行事务模型以及其他分布式强一致性事务模型~
以上是关于数据库事务系列-事务模型基础的主要内容,如果未能解决你的问题,请参考以下文章