这样讲API网关,你应该能明白了吧!
Posted Java编程
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这样讲API网关,你应该能明白了吧!相关的知识,希望对你有一定的参考价值。
来自公众号: 51CTO技术栈
随着互联网技术的飞速发展,各类线上业务蓬勃发展,软件系统如雨后春笋般呈现在我们面前。
为了提高系统的性能和可靠性,将应用服务进行拆分微服务化。作为系统入口的 API 网关也逐渐成为了标配。
今天我们一起来看看 API 网关的设计思路,需要承载了哪些功能?以及如何选择流行的 API 网关?
什么是 API 网关
既然需要 API 网关为我所用,首先就让我们来了解一下什么是 API 网关。
什么是 API 网关
网关一词最早出现在网络设备,比如两个相互独立的局域网之间通过路由器进行通信,中间的路由被称之为网关。
任何一个应用系统如果需要被其他系统调用,就需要暴露 API,这些 API 代表着一个一个的功能点。
对接两个系统的 API 网关
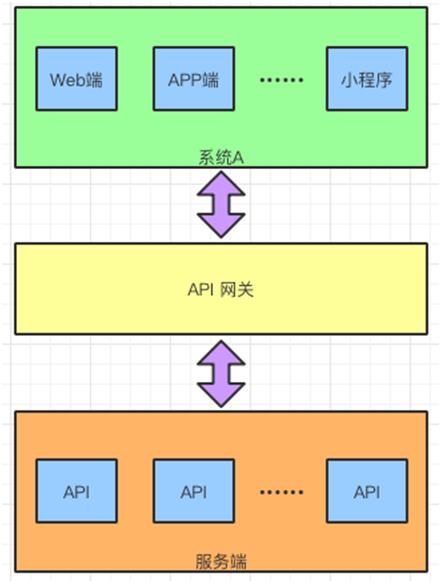
对接客户端和服务端的 API 网关
知道了 API 网关的基本定义,再来看看为什么我们要使用它。
为何要使用 API 网关
网关作为系统的唯一入口,也就是说,进入系统的所有请求都需要经过 API 网关。
当系统外部的应用或者客户端访问系统的时候,都会遇到这样的情况:
系统要判断它们的权限
如果传输协议不一致,需要对协议进行转换
如果调用水平扩展的服务,需要做负载均衡
一旦请求流量超出系统承受的范围,需要做限流操作
针对每个请求以及回复,系统会记录响应的日志
也就是说,只要是涉及到对系统的请求,并且能够从业务中抽离出来的功能,都有可能在网关上实现。
例如:协议转换,负载均衡,请求路由,流量控制等等。后面我们会一一给大家介绍这些功能。
在了解 API 网关有哪些基本功能以后,来看看它可以服务于哪些系统或者客户端。
API 网关服务定位
API 网关拥有处理请求的能力,从定位来看分为 5 类:
①面向 WebApp,这部分的系统以网站和 H5 应用为主。通过前后端分离的设计,将大部分的业务功能都放在了后端,前面的 Web App 只展示页面的内容。
②MobileApp,这里的 Mobile 指的是 ios 和 android,设计思路和 WebApp 基本相同。
区别是 API 网关需要做一些移动设备管理的工作(MDM)。例如:设备的注册,激活,使用,淘汰等,全生命周期的管理。
由于移动设备的特殊性,导致了我们在考虑移动设备请求的时候,需要考虑请求,设备,使用者之间的关系。
③面向合作伙伴的 OpenAPI,通常系统会给合作伙伴提供接口。这些接口会全部开放或者部分开发,在有条件限制(时间,流量)的情况下给合作伙伴访问。因此需要更多考虑 API 网关的流量和安全以及协议转换的管理。
④企业内部可扩展 API,给企业内部的其他部门或者项目使用,也可以作为中台输出的一部分,支持其他系统。这里需要更多地考虑划分功能边界,认证和授权问题。
⑤面向 IOT 设备,会接收来自 IOT 设备的请求,特别是工业传感器等设备。这里需要考虑协议转换和数据过滤。
API 网关架构
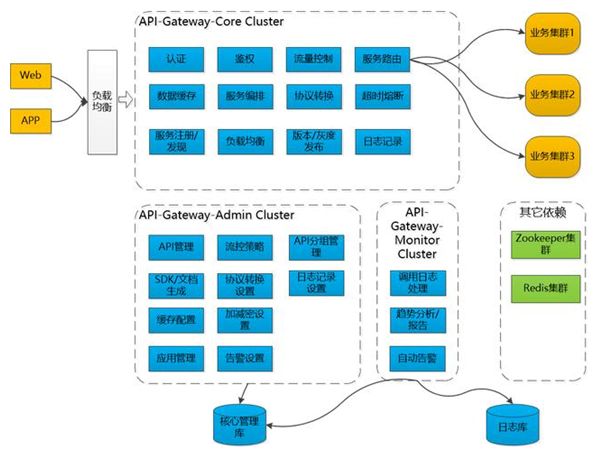
API 网关系统架构图
API 网关拆分成为 3 个系统:
Gateway-Core(核心)
Gateway-Admin(管理)
Gateway-Monitor(监控)
Gateway-Core 核心网关,负责接收客户端请求,调度、加载和执行组件,将请求路由到上游服务端,并处理其返回的结果。
大多数的功能都在这一层完成,例如:验证,鉴权,负载均衡,协议转换,服务路由,数据缓存。如果没有其他两个子系统,它也是可以单独运行的。
Gateway-Admin 网关管理界面,可以进行 API、组件等系统基础信息的配置;例如:限流的策略,缓存配置,告警设置。
Gateway-Monitor 监控日志、生成各种运维管理报表、自动告警等;管理和监控系统主要是为核心系统服务的,起到支撑的作用。
API 网关技术原理
上面谈到了网关的架构思路,这里谈几点技术原理。平时我们在使用网关的时候,多注重其实现的功能。例如:路由,负载均衡,限流,缓存,日志,发布等等。
实际上这些功能的背后有一些原理我们可以了解,这样在应用功能的时候会更加笃定。下面是几个原理分享给大家。
协议转换
每个系统内部服务之间的调用,可以统一使用一种协议,例如:HTTP,GRPC。
假设每个系统使用的协议不同,那么系统之间的调用或者数据传输,就存在协议转换的问题了。如果解决这个问题呢?API 网关通过泛化调用的方式实现协议之间的转化。
实际上就是将不同的协议转换成“通用协议”,然后再将通用协议转化成本地系统能够识别的协议。
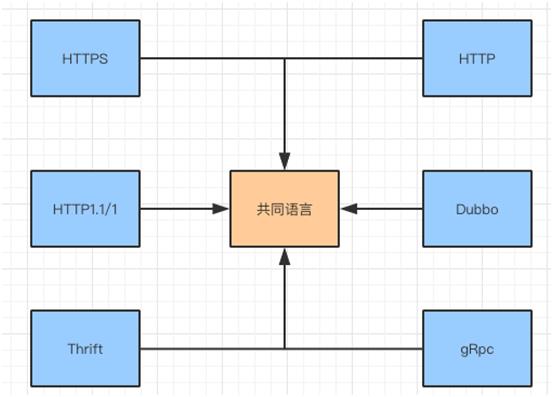
不同的协议需要转化成共同语言进行传输
链式处理
设计模式中有一种责任链模式,它将“处理请求”和“处理步骤”分开。每个处理步骤,只关心这个步骤上需要做的处理操作,处理步骤存在先后顺序。
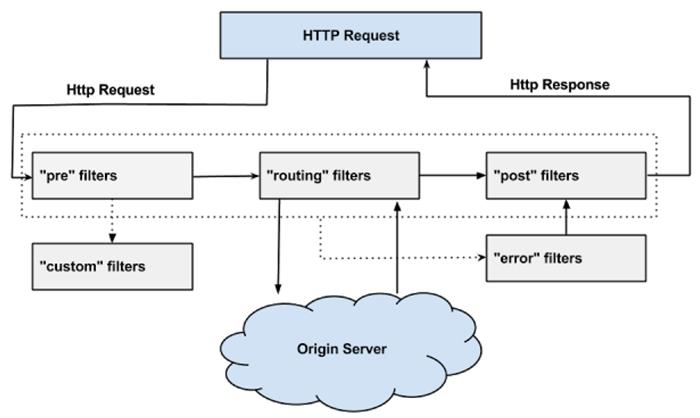
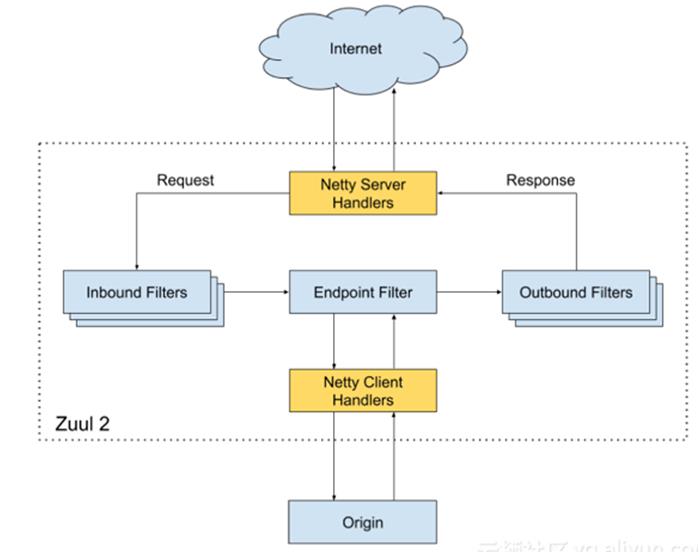
Zuul 网关过滤器链式处理
下面以 Zuul 为例,当消息出入网关需要经历一系列的过滤器。这些过滤器之间是有先后顺序的,并且在每个过滤器需要进行的工作也是各不一样:
PRE:前置过滤器,用来处理通用事务,比如鉴权,限流,熔断降级,缓存。并且可以通过 Custom 过滤器进行扩展。
ROUTING:路由过滤器,在这种过滤器中把用户请求发送给 Origin Server。它主要负责:协议转化和路由的工作。
POST:后置过滤器,从 Origin Server 返回的响应信息会经过它,再返回给调用者。在返回的 Response 上加入 Response Header,同时可以做 Response 的统计和日志记录。
ERROR:错误过滤器,当上面三个过滤器发生异常时,错误信息会进到这里,并对错误进行处理。
异步请求
同时,如果多个线程都处在这种状态,会导致系统缓慢。因为每个网关能够开启的线程数量是有限的,特别是在访问的高峰期。
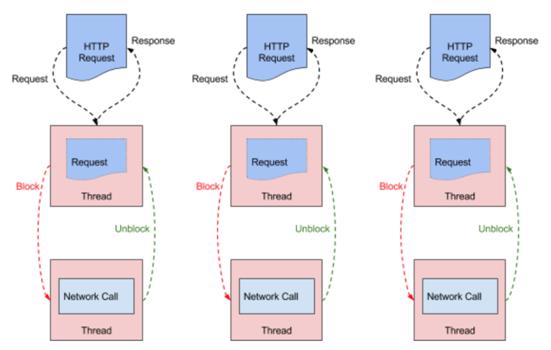
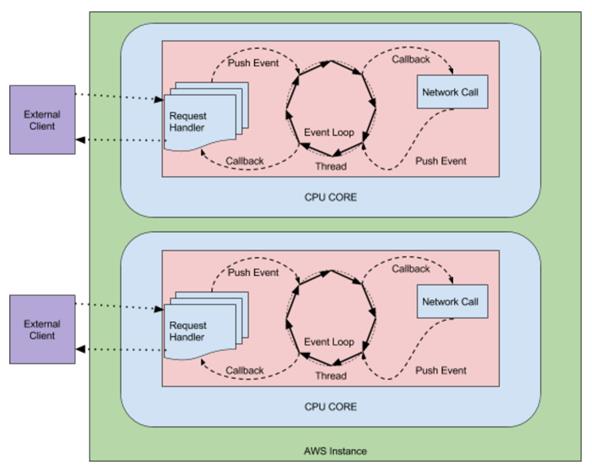
当请求数据被 CPU 内核获取,并且发送到指定的数据缓冲区时,请求的线程会接到“数据返回”的通知,然后就直接使用数据,不用自己去做取数据的操作。
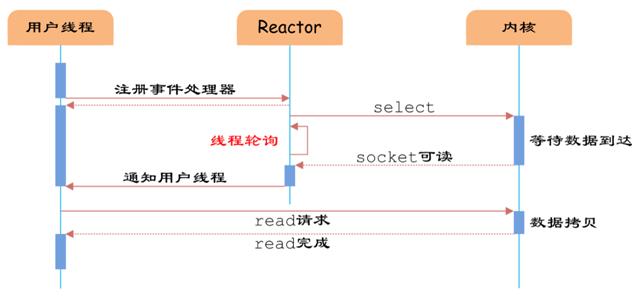
Reactor
Proactor
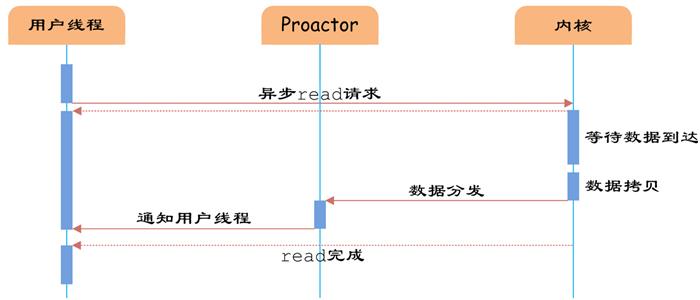
Proactor 工作原理流水图
API 网关实现功能
负载均衡
当微服务动态挂载(动态扩容)的时候,可以通过服务注册中心获取微服务的注册信息,从而实现负载均衡。
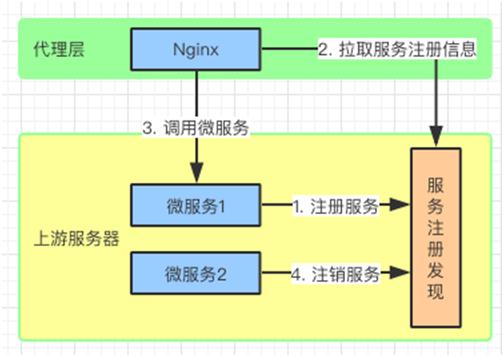
路由选择
有时候因为网络原因,服务可能会暂时的不可用,这个时候我们希望可以再次对服务进行重试。
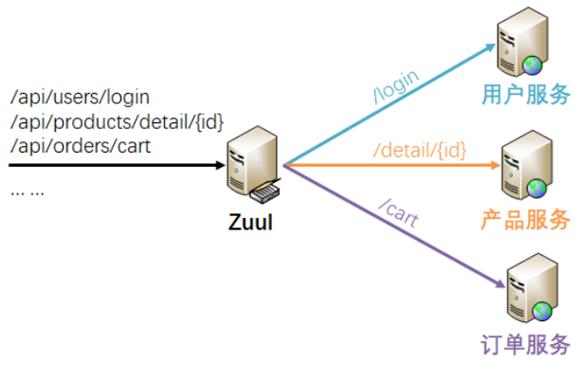
例如:Zuul 与 Spring Retry 合作完成路由重试。
#是否开启重试功能
zuul.retryable=true
#对当前服务的重试次数
ribbon.MaxAutoRetries=2
流量控制
限流实际上就是限制流入请求的数量,其算法不少,有令牌桶算法,漏桶算法,连接数限制等等。这里我们就介绍三个常用的,一般通过 Nginx+Lua 来实现。
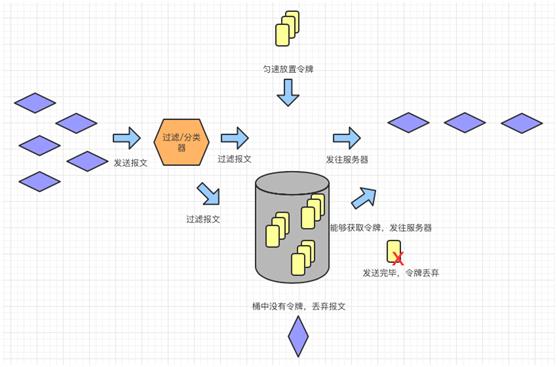
统一鉴权
熔断降级
例如:Zuul 中提供了 ZuulFallbackProvider 接口来实现熔断,它提供两个方法,一个指明熔断拦截的服务 getRoute,一个指定返回内容 ClientHttpResponse。
public interface ZuulFallbackProvider {
/**
* The route this fallback will be used for.
* @return The route the fallback will be used for.
*/
public String getRoute();
/**
* Provides a fallback response.
* @return The fallback response.
*/
public ClientHttpResponsefallbackResponse();
}
主要继承 ZuulFallbackProvider 接口来实现,ZuulFallbackProvider 默认有两个方法,一个用来指明熔断拦截哪个服务,一个定制返回内容。
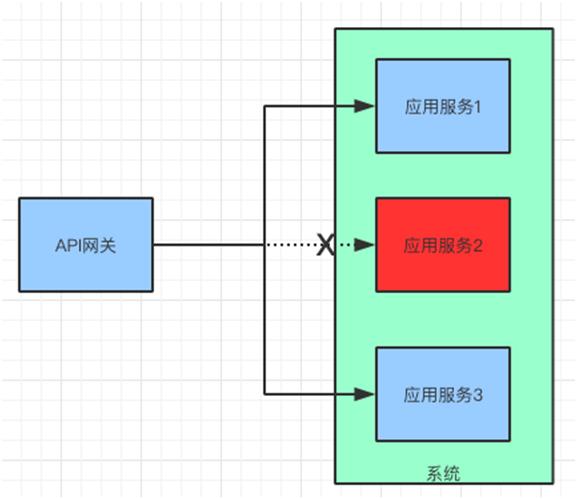
发布测试
假设将 4 个服务从 V1 更新到 V2 版本,这 4 个服务的流量请求由 1 个 API 网关管理。
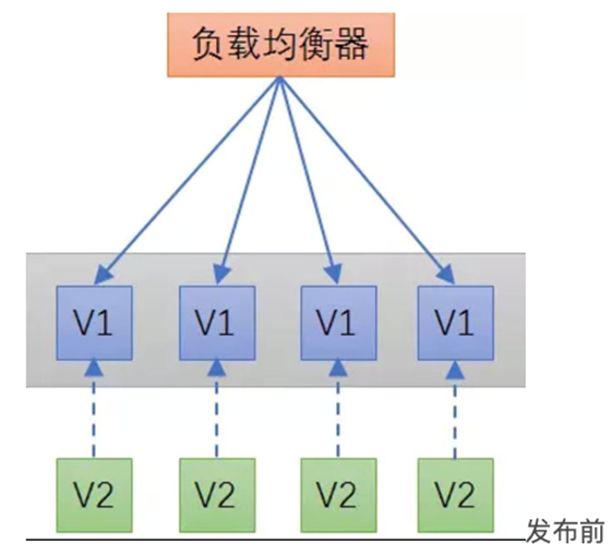
那么先将一台服务与 API 网关断开,部署 V2 版本的服务,然后 API 网关再将流量导入到 V2 版本的服务上。
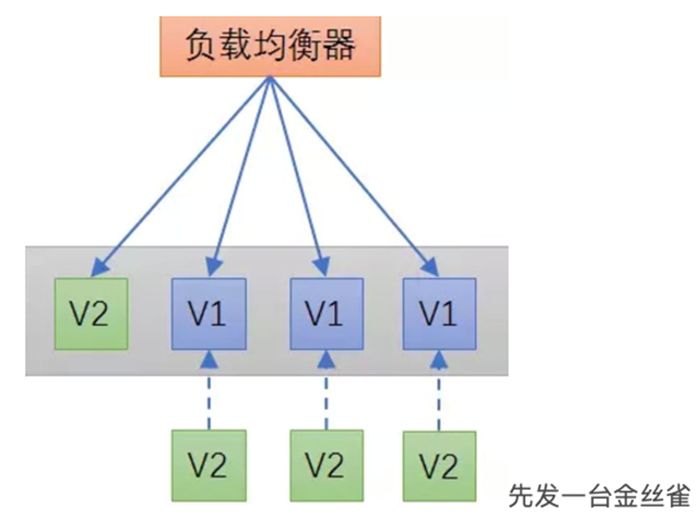
这里流量的导入可以是逐步进行的,一旦 V2 版本的服务趋于稳定。再如法炮制,将其他服务替换成 V2 版本。
金丝雀发布一般先发 1 台,或者一个小比例,例如 2% 的服务器,主要做流量验证用,也称为金丝雀(Canary)测试(灰度测试)。
其来历是,旷工下矿洞前,先放一只金丝雀探查是否有毒气,金丝雀发布由此得名。
金丝雀测试需要完善的监控设施配合,通过监控指标反馈,观察金丝雀的健康状况,作为后续发布或回滚的依据。
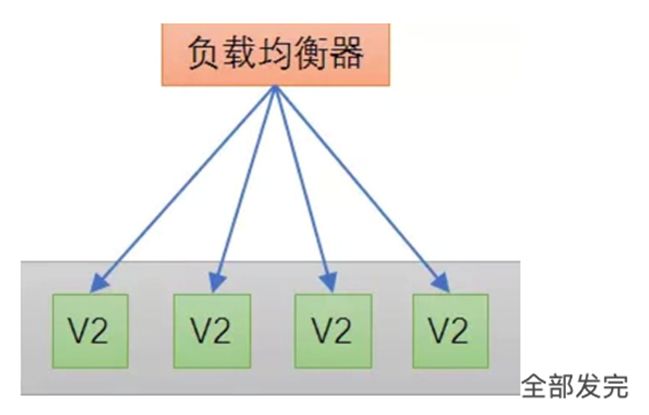
如果金丝测试通过,则把剩余的 V1 版本全部升级为 V2 版本。如果金丝雀测试失败,则直接回退金丝雀,发布失败。
缓存数据
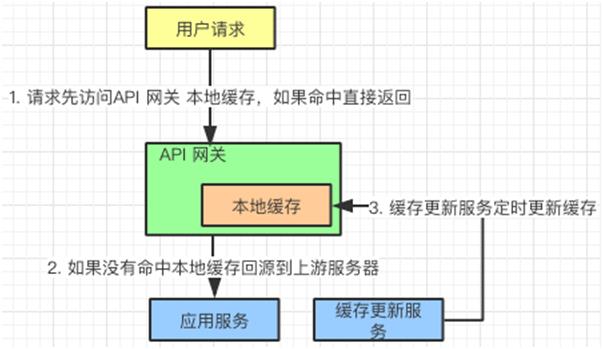
用户请求先访问 API 网关,如果发现有缓存信息,直接返回给用户。
如果没有发现缓存信息,回源到应用服务器获取信息。
另外,有一个缓存更新服务,定期把应用服务器中的信息更新到网关本地缓存中。
日志记录
通过 API 网关上的过滤器我们可以加入日志服务,记录请求和返回信息。同时可以建立一个管理员的界面去监控这些数据。
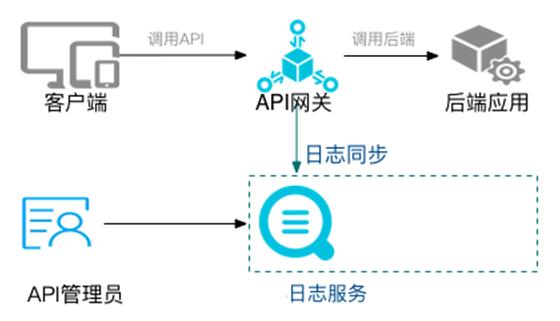
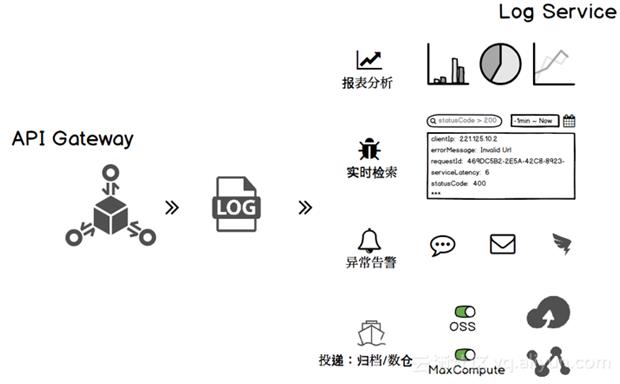
报表分析:针对服务访问情况,提供可视化展示。
实时查询:了解实时关键信息,例如:吞吐量,并发数。在秒杀活动的时候,会特别关注。
异常告警:针对关键参数进行监控,对于统计结果支持阈值报警,对接阿里云通知中心、短信、钉钉进行告警。
日志投递:将日志进行归档,存放到文件库或者数据仓库中,以便后期分析。
流行 API 网关对比
Kong
由于是基于 Nginx 的,所以可以对网关进行水平扩展,来应对大批量的网络请求。
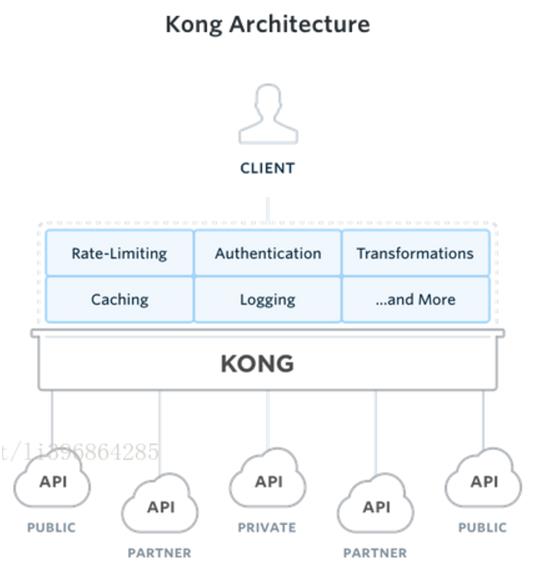
KongServer :基于 Nginx 的服务器,用来接收 API 请求。
ApacheCassandra/PostgreSQL:用来存储操作数据。
Kongdashboard:UI 管理工具。
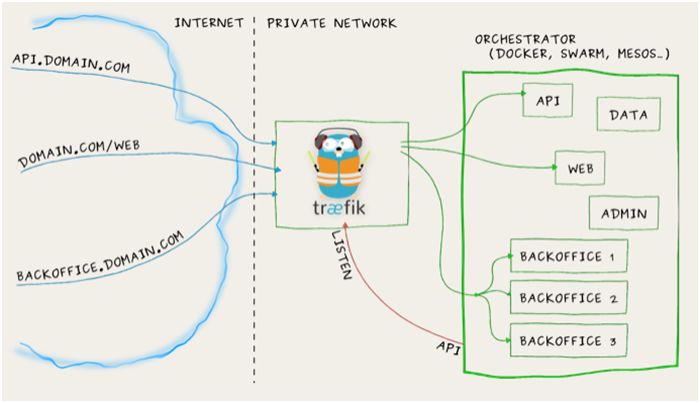
Traefik
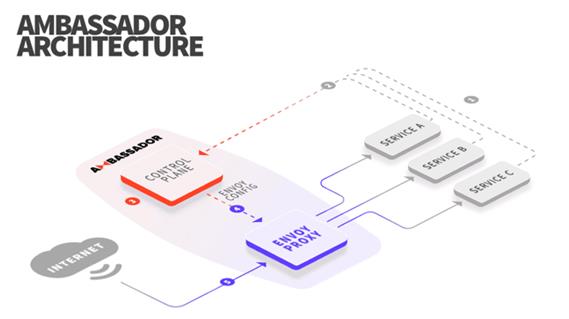
Ambassador
Zuul
介绍了几个开源 API 网关的基本信息以后,我们从几个维度对他们进行比较:
总结
作者:崔皓
简介:十六年开发和架构经验,曾担任过惠普武汉交付中心技术专家,需求分析师,项目经理,后在创业公司担任技术/产品经理。善于学习,乐于分享。目前专注于技术架构与研发管理。
●编号1107,输入编号直达本文
●输入m获取文章目录
Web开发
以上是关于这样讲API网关,你应该能明白了吧!的主要内容,如果未能解决你的问题,请参考以下文章
这样讲 SpringBoot 自动配置原理,你应该能明白了吧