这样的API网关查询接口优化,我是被迫的
Posted JavaQ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了这样的API网关查询接口优化,我是被迫的相关的知识,希望对你有一定的参考价值。
好记性不如烂笔头,记录下来的才是永恒!这里是JavaQ大本营,诚邀关注。笔者,不断反思的年轻人。
今天的内容聊一下刚参加工作时遇到的一个查询接口优化的内容。
先聊背景
线上某系统的用户中心页面展示了用户基本信息(包括会员昵称、姓名、性别、年龄、证件号码、手机号、等级、头像图片)、信用信息(信用等级、可授信额度、已授信额度)、银行卡信息(借记卡卡号、银行名称、支行名称),还有其它信息不一一罗列了,这里以这三个为例。
需求是根据产品经理的解说,这个页面上的信息加载太慢了,特别是随着业务的快速发展,数据量大增后更慢,需要对查询接口的性能做优化。
简单描述一下系统架构,采用前后端分离结构,上面说的用户中心页面属于前端系统,由前端系统发起HTTP请求到后端的API网关系统,再由API网关和各个后端的子系统通讯获取数据,上述的基本信息由客户中心子系统提供,信用信息由授信中心子系统提供,银行卡信息由支付中心子系统提供,子系统使用微服务架构+分布式部署。
我想多了
需求到手开始干吧!本以我刚入行的宏观设想来说,“这种前后端分离系统的查询接口优化,也就是对各查询子接口查询使用缓存、SQL调优、代码逻辑调整优化”。当我看到祖传的原系统代码时,我涨姿势了。就一个接口?!是的,我翻看了几遍后端代码确认没看错,上述页面上的信息是通过API网关系统中的一个查询接口得到的,并且接口的处理逻辑使用了单线程线性处理,也就是下面这样的。
难道不应该通过多个查询接口分别获取数据吗?于是找负责前端的大佬沟通沟通,我提供三个接口分别用于查询不同的数据,前端系统请求不同的接口查询不同的数据,这样查询结果会更快,用户体验会更好,没想到大佬一句话就把我怼回来了“项目排期都满了,没人手配合你了”。
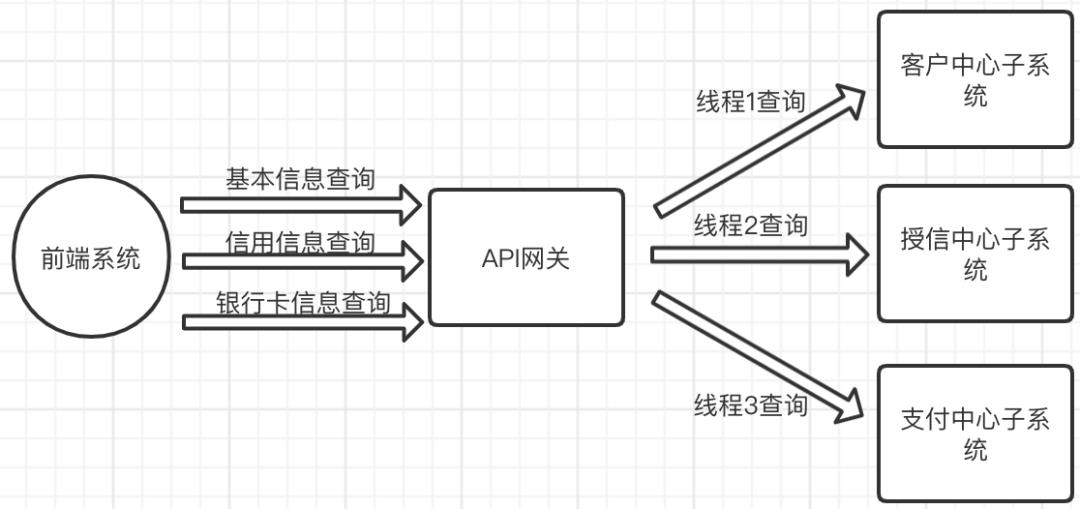
优化方案
既然前端没时间配合这次优化,只能由后端系统自己想办法了。一个接口就一个接口吧,单线程依次处理太不靠谱了,前端系统一次查询请求的总耗时是后端系统多个查询处理时间的累加和,不慢才怪!
是时候考虑使用多线程处理方案了,三个线程分别查询不同的子系统,最后将查询结果整合到一起返回给前端系统(不能影响原接口的返回值),前端系统一次查询请求的总耗时是由耗时最长的那个线程决定。
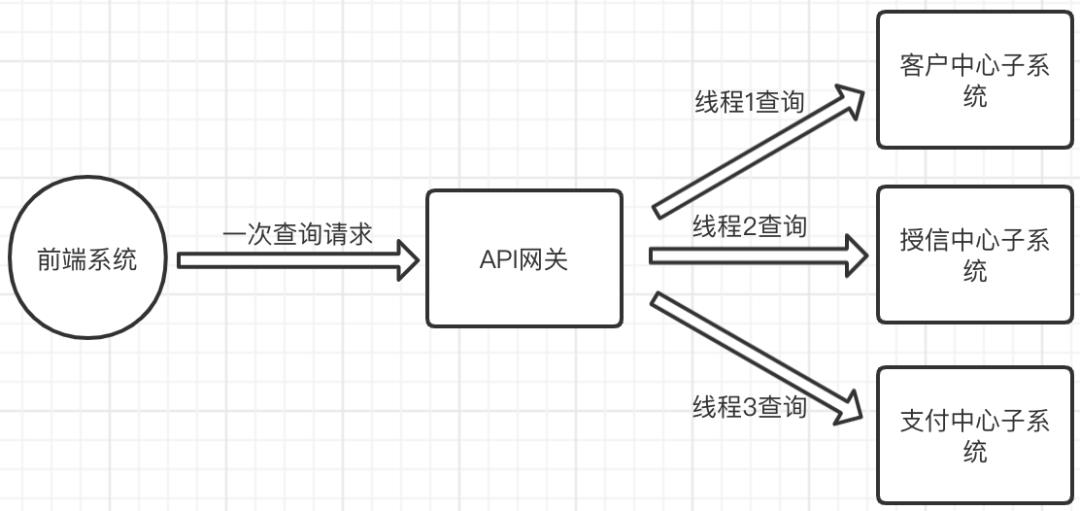
既然使用多线程,那就必须要使用线程池,至于理由,说再多都不如借鉴一下权威阿里《Java开发手册》里一段关于线程使用的强制规定。

还有线程池的创建不要使用Executors,至于原因嘛,还是引用阿里权威手册《Java开发手册》中的描述。

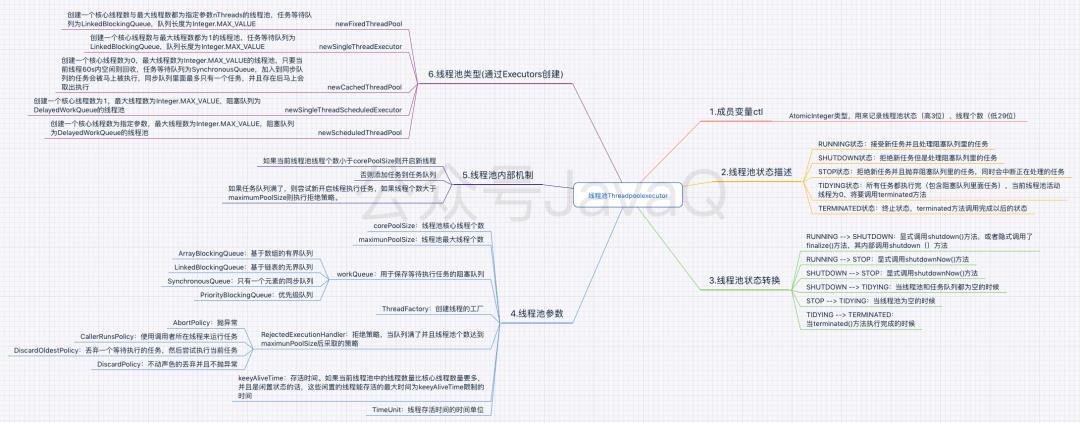
关于线程池的深入解说放到后续文章,这里先放张图透露一下,有兴趣的持续关注一下。
有了线程池,接下来就是定义线程要执行的任务。一般情况下,使用线程池对象的execute方法提交任务给线程池执行,而任务只要实现Runnable接口就行。但是,我这里是需要获取线程执行结果的,所以这个任务需要同时实现Runnable接口和Future接口,而java.util.concurrent.FutureTask正好满足,直接上代码。
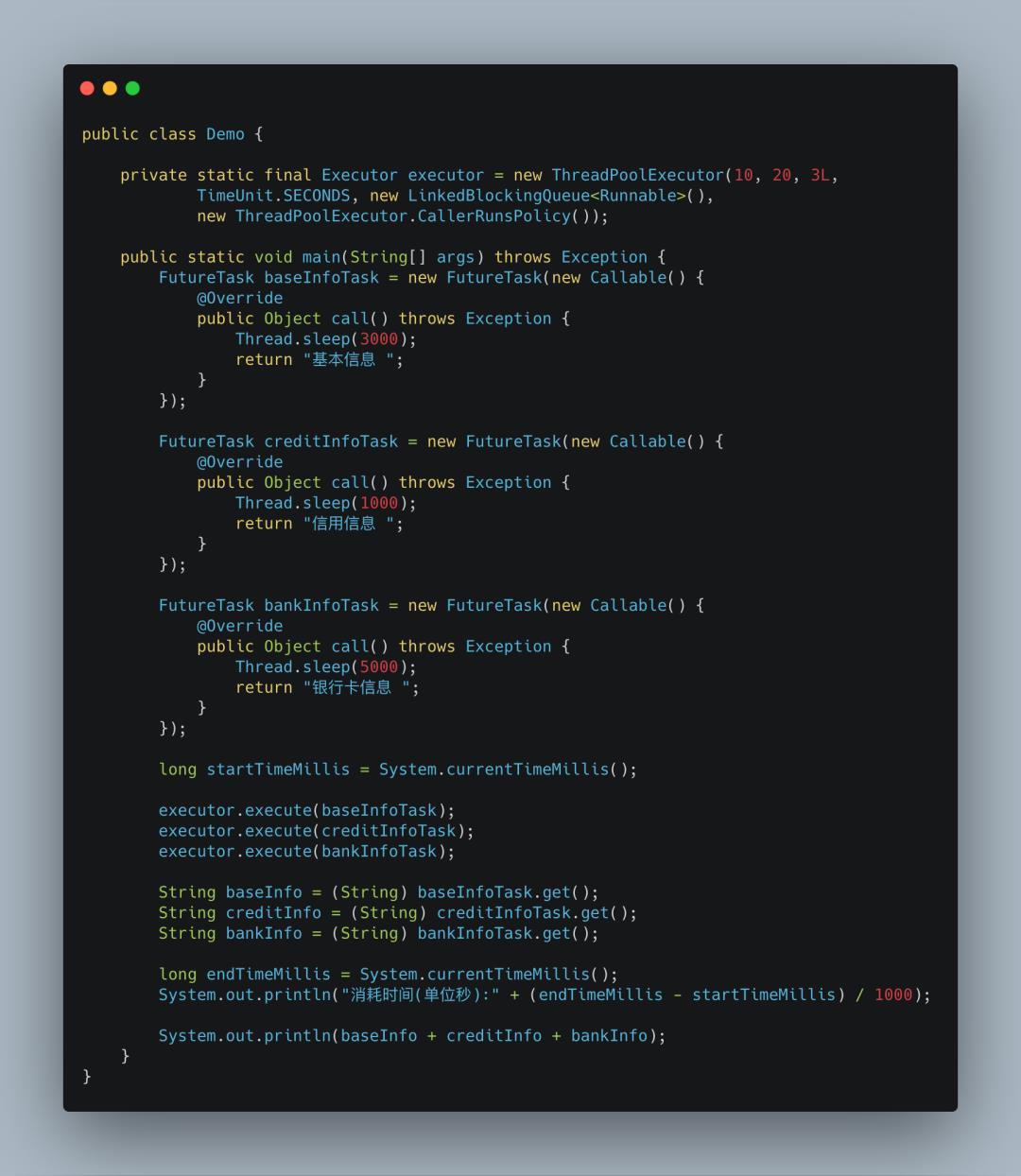
上面的代码,你会发现还有继续优化的点,FutureTask#get方法是阻塞的,也就是说如果对应的任务还没有执行完成,调用get方法会被阻塞在那里,直到线程执行完成。再设想一下,如果baseInfoTask.get()执行后还有其它数据转换的行为,那么它后面的creditInfoTask.get()和bankInfoTask.get()就会延后执行,所以最好的办法是随机,谁先执行完成就先获取谁的结果并执行其它任务,使用java.util.concurrent.ExecutorCompletionService继续优化,撸代码。
关于ExecutorCompletionService的原理解析,请阅读我的这篇文章。
小结
上面使用多线程优化的方案是当时迫不得已的办法,如果可以分为多个网关接口,会方便很多,这样优化的重点就可以放在SQL调优和代码逻辑调整上面,并且也不用考虑单线程处理异常如何组装返回数据。
学之多,而后知之少!朋友们点【在看】是我持续更新的最大动力,我们下期见!
以上是关于这样的API网关查询接口优化,我是被迫的的主要内容,如果未能解决你的问题,请参考以下文章