论如何提升格调——多线程网络爬虫了解一下?
Posted 北京数据科学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论如何提升格调——多线程网络爬虫了解一下?相关的知识,希望对你有一定的参考价值。


对于网络爬虫,相比大家已经并不陌生了,大家时常写的都是串行爬虫,已经烂大街了,平庸而缓慢的爬虫可能不足以满足聪明的你,所以,今天想给大家简单介绍一下更“高大上”的爬虫——多线程网络爬虫。

多线程网络爬虫

何为进程、线程、多线程?
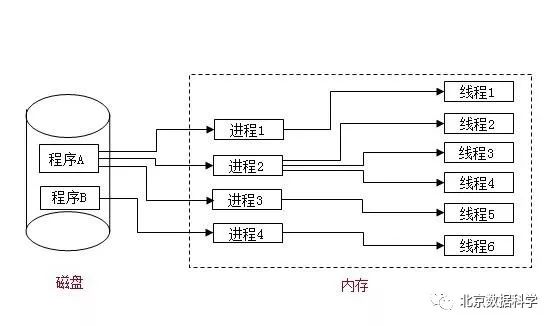
进程:进程是一个具有一定独立功能的程序关于某个数据集合的一次运行活动。它是操作系统动态执行的基本单元,在传统的操作系统中,进程既是基本的分配单元,也是基本的执行单元。
线程:不拥有系统资源,故对它的调度所付出的开销就会小得多,能更高效的提高系统多个程序间并发执行的程度。
多线程:在一个程序中,这些独立运行的程序片段叫作“线程”(Thread),利用它编程的概念就叫作“多线程处理”。多线程是为了同步完成多项任务,不是为了提高运行效率,而是为了提高资源使用效率来提高系统的效率。线程是在同一时间需要完成多项任务的时候实现的。
举个例子就是:我打开了QQ,此时,启动了一个进程(即QQ),给郑爽发了一条语音,启动了该进程中的一个线程;然后又给迪丽热巴发了一个表情,此时我又启动了一个线程。这就是进程、线程、多线程的一个最简单的例子。如下图所示。
Python中的多线程
多线程类似于同时执行多个不同程序,多线程运行有如下优点:
使用线程可以把占据长时间的程序中的任务放到后台去处理。
用户界面可以更加吸引人,这样比如用户点击了一个按钮去触发某些事件的处理,可以弹出一个进度条来显示处理的进度
程序的运行速度可能加快
在一些等待的任务实现上如用户输入、文件读写和网络收发数据等,线程就比较有用了。在这种情况下我们可以释放一些珍贵的资源如内存占用等等。
Python3中处理多线程的模块是threading模块,提供一些简单的方法,如:
threading.currentThread(): 返回当前的线程变量。
threading.enumerate(): 返回一个包含正在运行的线程的list。正在运行指线程启动后、结束前,不包括启动前和终止后的线程。
threading.activeCount(): 返回正在运行的线程数量,与len(threading.enumerate())有相同的结果。
除了使用方法外,线程模块同样提供了Thread类来处理线程,Thread类提供了以下方法:
run(): 用以表示线程活动的方法。
start():启动线程活动。
join([time]): 等待至线程中止。这阻塞调用线程直至线程的join() 方法被调用中止-正常退出或者抛出未处理的异常-或者是可选的超时发生。
isAlive(): 返回线程是否活动的。
getName(): 返回线程名。
setName(): 设置线程名。
下面看一个简单的例子:定义了两个很简单的函数,一个负责让程序休眠3秒,然后打印函数启动和终止的时间;另一个让程序休眠8秒,然后打印函数启动和终止的时间。先用常规方式运行两个函数。
import threading
import time
def doWaiting():
''' 该函数用于让程序休眠3秒,并打印相关信息 '''
print('start waiting1: ' + time.strftime('%H:%M:%S'))
time.sleep(3)
print('stop waiting1: ' + time.strftime('%H:%M:%S'))
def doWaiting1():
''' 该函数用于让程序休眠8秒,并打印相关信息 '''
print('start waiting2: ' + time.strftime('%H:%M:%S'))
time.sleep(8)
print('stop waiting2: ', time.strftime('%H:%M:%S'))
if __name__ == '__main__':
doWaiting()
doWaiting1() 输出结果如下:可以看到第一个函数doWaiting()在14:52:47开始运行,打印启动时间,然后休眠3秒,三秒后,也就是14:52:50,函数运行完成,打印该函数终止运行的时间,同时,第二个函数doWaiting1()启动,打印该函数启动时间,8秒后,函数运行完成,打印结束时间。
start waiting1: 14:52:47
stop waiting1: 14:52:50
start waiting2: 14:52:50
stop waiting2: 14:52:58
可以看到,程序是自上而下串行执行的,如果用并行的方式呢?函数定义不变,只将主函数修改如下所示:用threading.Thread()类构造线程thread1和thread2,target参数接受的是某个函数,对每个线程使用start()方法启动线程。让我们来看一看输出结果。
if __name__ == '__main__':
thread1 = threading.Thread(target=doWaiting)
thread1.start()
thread2 = threading.Thread(target = doWaiting1)
thread2.start()start waiting1: 15:02:21
start waiting2: 15:02:21
stop waiting1: 15:02:24
stop waiting2: 15:02:29
可以看到两个函数的启动时间为同一时刻,然后分别运行了3秒和8秒,这就是并行,程序没有自上而下的执行函数,而是将两个函数同时执行。
当然,更常用的多线程构造方式是继承threading.Thread()类,如下所示,背景与前一段程序相同,无非是让程序休眠:
import threading
import time
class mythread(threading.Thread):
''' 继承自threading.Thread类,修改类中的run方法,使 程序的功能为,休眠若干时间,并打印相关时间信息。 name:str型,代表线程的名称; sleep:int or float,但本例控制了时间的输出格式精确到秒, 故推荐使用int(用float并没有什么实质性的卵用。。) '''
def __init__(self,name,sleep):
threading.Thread.__init__(self)
self.name = name
self.sleep = sleep def run(self):
print('开始%s线程,开始时间:%s'%(self.name,time.strftime('%H:%M:%S')))
time.sleep(self.sleep)
print('线程%s结束,结束时间:%s'%(self.name,time.strftime('%H:%M:%S')))
thread1 = mythread("Thread1",3)
thread2 = mythread("Thread2",8)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print('程序结束',time.strftime('%H:%M:%S')) 程序的输出如下所示(嗯。。。和之前间隔了两个多小时,这段时间我午休了一会儿,不想让头发过早掉光 ),这个我就不用多解释了对吧,两个线程同时启动,3秒和8秒后分别停止:
),这个我就不用多解释了对吧,两个线程同时启动,3秒和8秒后分别停止:
开始Thread1线程,开始时间:17:32:06
开始Thread2线程,开始时间:17:32:06
线程Thread1结束,结束时间:17:32:09
线程Thread2结束,结束时间:17:32:14
程序结束 17:32:14
关于多线程还有最后一点知识,就是有关线程同步和队列的内容。
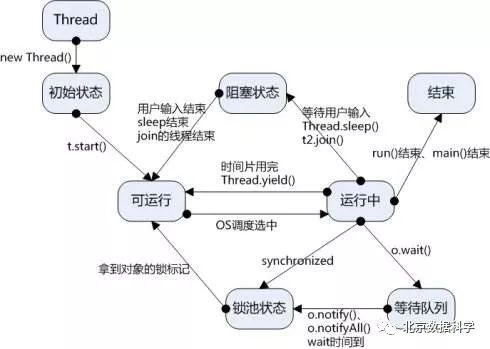
所谓线程同步,举个例子:考虑这样一种情况:一个列表里所有元素都是0,线程"set"从后向前把所有元素改成1,而线程"print"负责从前往后读取列表并打印。那么,可能线程"set"开始改的时候,线程"print"便来打印列表了,输出就成了一半0一半1,这就是数据的不同步。为了避免这种情况,引入了锁的概念。锁有两种状态——锁定和未锁定。每当一个线程比如"set"要访问共享数据时,必须先获得锁定;如果已经有别的线程比如"print"获得锁定了,那么就让线程"set"暂停,也就是同步阻塞;等到线程"print"访问完毕,释放锁以后,再让线程"set"继续。经过这样的处理,打印列表时要么全部输出0,要么全部输出1。使用Thread对象的Lock和Rlock以实现简单的线程同步,这两个对象都有acquire方法和release方法,对于那些需要每次只允许一个线程操作的数据,可以将其操作放到acquire和release方法之间。
如下所示,将上面的例子稍作修改:
import threading
import time
class mythread(threading.Thread):
''' 继承自threading.Thread类,修改类中的run方法,使 程序的功能为,休眠若干时间,并打印相关时间信息。 name:str型,代表线程的名称; sleep:int or float,但本例控制了时间的输出格式精确到秒, 故推荐使用int(用float并没有什么实质性的卵用。。) '''
def __init__(self,name,sleep):
threading.Thread.__init__(self)
self.name = name
self.sleep = sleep def run(self):
# 获取锁,用于线程同步
print('开始%s线程,开始时间:%s'%(self.name,time.strftime('%H:%M:%S')))
threadLock.acquire()
# 将实际需要进行的处理放在acquire()与release()之间,实际,咱们的睡眠功能,
# 每次只需要一个线程操作他,对吧?
time.sleep(self.sleep)
print('线程%s结束,结束时间:%s'%(self.name,time.strftime('%H:%M:%S')))
# 释放锁,开启下一个线程
threadLock.release()
threadLock = threading.Lock()
thread1 = mythread("Thread1",3)
thread2 = mythread("Thread2",8)
thread1.start()
thread2.start()
thread1.join()
thread2.join()
print('程序结束',time.strftime('%H:%M:%S')) 输出结果如下所示,两个线程同时启动,3秒后,线程1结束,又8秒后(也就是距离程序开始后的11秒)线程2结束,这个结局有些类似于串行执行的程序,但是要记住,我们的两个线程,即休眠3秒和休眠8秒是同时启动的,只是,我不让它俩同时做休眠操作(还想一起睡???):
开始Thread1线程,开始时间:17:39:03
开始Thread2线程,开始时间:17:39:03
线程Thread1结束,结束时间:17:39:06
线程Thread2结束,结束时间:17:39:14
程序结束 17:39:14
最后就是有关队列的内容了。包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue,和优先级队列 PriorityQueue。这些队列都实现了锁原语,能够在多线程中直接使用,可以使用队列来实现线程间的同步。Python中queue模块可以良好的实现队列,简单的队列如下所示:
import threading
import time
import queue
# queue.Queue类中的参数maxsize指定了队列中能包含最大元素个数
# maxsize小于等于0时则队列最大长度为无穷,其默认值为0
q1= queue.Queue(maxsize=10)
q1.put(2)
q1.put(1)
q1.put(3)
q2 = queue.LifoQueue(maxsize=10)
q2.put(2)
q2.put(1)
q2.put(3)
q3 = queue.PriorityQueue(maxsize=10)
q3.put(2)
q3.put(1)
q3.put(3)if __name__=='__main__':
# 先进先出
print("先进先出")
while not q1.empty():
print(q1.get())
# 后进先出
print("后进先出")
while not q2.empty():
print(q2.get())
# 优先级队列
print("优先级队列")
while not q3.empty():
print(q3.get()) 输出结果如下所示:
先进先出
2
1
3
后进先出
3
1
2
优先级队列
1
2
3
关于多线程,基本就这么多基础知识了,接下来进入多线程爬虫!
串行爬虫与多线程爬虫
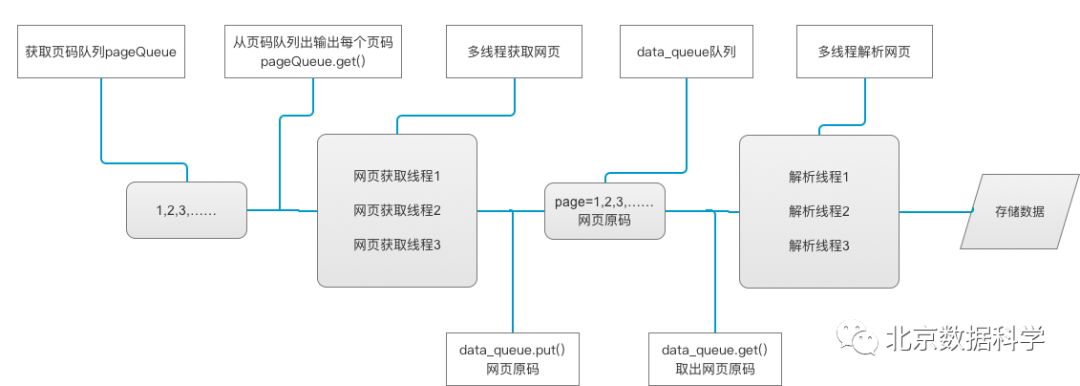
import requests
from lxml
import etree
from queue import Queue
import threading
import time
import json
class thread_crawl(threading.Thread):
''''' 抓取线程类 '''
def __init__(self, threadID, q):
threading.Thread.__init__(self)
self.threadID = threadID # q是页面编号的队列
self.q = q def run(self):
print("抓取网页线程启动" + self.threadID)
self.qiushi_spider()
print("抓取网页线程结束", self.threadID)
def qiushi_spider(self):
while True:
if self.q.empty():
break
else:
page = self.q.get()
print('网页获取线程', self.threadID ,',第', str(page),'页')
url = 'http://www.qiushibaike.com/hot/page/' + str(page) + '/'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/52.0.2743.116 Safari/537.36','Accept-Language': 'zh-CN,zh;q=0.8'}
# 多次尝试失败结束、防止死循环
timeout = 4
while timeout > 0:
timeout -= 1
try:
content = requests.get(url, headers=headers)
data_queue.put(content.text)
break
except Exception as e:
print('糗事百科爬虫', e)
if timeout < 0:
print('请求超时', url)
class Thread_Parser(threading.Thread):
''''' 页面解析线程类 '''
def __init__(self, threadID, queue, lock, f):
threading.Thread.__init__(self)
self.threadID = threadID
self.queue = queue
self.lock = lock
self.f = f
def run(self):
print('解析线程启动:', self.threadID)
global total, exitFlag_Parser
while not exitFlag_Parser:
try:
''' 调用队列对象的get()方法从队头删除并返回一个项目。可选参数为block,默认为True。 如果队列为空且block为True,get()就使调用线程暂停,直至有项目可用。 如果队列为空且block为False,队列将引发Empty异常。 '''
item = self.queue.get(False)
if not item:
pass
self.parse_data(item)
self.queue.task_done()
print('解析线程:', self.threadID, ',total=', total)
except:
pass
print('线程', self.threadID,'结束')
def parse_data(self, item):
''''' 解析网页函数 :param item: 网页内容 '''
global total
try:
# 这里的item实际上就是之前抓取每页html代码得到的content.text
html = etree.HTML(item)
result = html.xpath('//div[contains(@id,"qiushi_tag")]')
for site in result:
try:
# 图片地址
imgUrl = site.xpath('.//img/@src')[0]
# 标题(发布者名字)
name = site.xpath('.//h2')[0].text
name = name.strip().replace('
','')
# 注意,分享内容中存在<br>标签,用xpath抽取出来是list,
# 需要处理一下,合为一个字符串content
content = ''
content_list = site.xpath
('.//div[@class="content"]//span/text()')
for contents in content_list:
contents = contents.strip().replace('
','')
content = content + contents
# 好笑数
vote = None
# 评论数
comments = None
try:
vote = site.xpath('.//i')[0].text
comments = site.xpath('.//i')[1].text
except:
pass
result = {'imgUrl': imgUrl,
'title': name,
'content': content,
'vote': vote,
'comments': comments,
}
with self.lock:
self.f.write(json.dumps(result, ensure_ascii=False) + "
")
except Exception as e:
print('获取每页下各条内容错误', e)
except Exception as e:
print('解析错误', e)
with self.lock:
total += 1
data_queue = Queue()
exitFlag_Parser = False
lock = threading.Lock()
total = 0
def main():
# 生成一个json文件用来存储所爬取得数据
output = open('糗事百科.json', 'a')
# 初始化网页页码page从1-10个页面
# (你也可以爬更多页面,不过这个网址也没多少页)
pageQueue = Queue(50)
for page in range(1, 11):
pageQueue.put(page)
# 初始化采集线程(抓取每页内容的线程初始化为三个)
crawlthreads = []
crawlList = ["1", "2", "3"]
for threadID in crawlList:
thread = thread_crawl(threadID, pageQueue)
thread.start()
crawlthreads.append(thread)
# 初始化解析线程parserList,解析线程也为三个
parserthreads = []
parserList = ["parser-1", "parser-2", "parser-3"]
# 分别启动parserList
for threadID in parserList:
thread = Thread_Parser(threadID, data_queue, lock, output)
thread.start()
parserthreads.append(thread)
# 等待队列清空
while not pageQueue.empty():
pass
# 等待所有线程完成
for t in crawlthreads:
t.join()
while not data_queue.empty():
pass
# 通知线程退出
global exitFlag_Parser
exitFlag_Parser = True
for t in parserthreads:
t.join()
print("退出主线程")
with lock:
output.close()
if __name__ == '__main__':
main()运行结果如下所示:
抓取网页线程启动1
网页获取线程 1 ,第 1 页
抓取网页线程启动2
网页获取线程 2 ,第 2 页
抓取网页线程启动3
网页获取线程 3 ,第 3 页
解析线程启动: parser-1
解析线程启动: parser-2
解析线程启动: parser-3
网页获取线程 3 ,第 4 页
网页获取线程 1 ,第 5 页
网页获取线程 2 ,第 6 页
网页获取线程 1 ,第 7 页
网页获取线程 3 ,第 8 页
网页获取线程 2 ,第 9 页
解析线程: parser-1 ,total= 1
解析线程: parser-2 ,total= 2
网页获取线程 1 ,第 10 页
抓取网页线程结束 2
解析线程: parser-3 ,total= 3
解析线程: parser-1 ,total= 4
抓取网页线程结束 3
解析线程: parser-2 ,total= 5
解析线程: parser-3 ,total= 6
解析线程: parser-1 ,total= 7
抓取网页线程结束 1
解析线程: parser-2 ,total= 8
线程 parser-2 结束
解析线程: parser-3 ,total= 9
线程 parser-3 结束
解析线程: parser-1 ,total= 10
线程 parser-1 结束
退出主线程
结尾
好了,呕心沥血终于是把多线程网络爬虫的基础给大家介绍了~希望可以和大家一起提升逼格!
点点关注吧~~
以上是关于论如何提升格调——多线程网络爬虫了解一下?的主要内容,如果未能解决你的问题,请参考以下文章