多线程渲染
Posted Unity3D游戏开发精华教程干货
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多线程渲染相关的知识,希望对你有一定的参考价值。
一、引言
性能开销历来都是游戏中关注的重点,随着游戏开发的不断迭代,游戏资源的不断累加,游戏的整体性能开销也会变得越来越高;评价游戏性能的主要指标之一是帧率,而影响帧最大的因素是图形渲染;一般来说,图形渲染是在主线程中调用图形API来完成,而图形API的操作开销往往是CPU的瓶颈。近些年来,不管是在PC平台还是移动平台,CPU的处理能力变得越来越强大,核心变得越来越多,因此可以将图形API的调用从主线程中抽离出来,单独放到另一个线程中执行。
本文将讲述多线程渲染的动机,实现方法及遇到的问题
二、多线程渲染背景介绍
(图一)展示的是单线程渲染的流程,一般情况下,在游戏每一帧运行过程中,主线程(CPU1)先执行Update,在这里做大量的逻辑更新,例如AI、碰撞检测和动画更新等,然后执行Render,在这里做渲染相关的指令调用。在渲染时,主线程需要调用图形API更新渲染状态,例如设置shader、纹理、矩阵和alpha融合等,然后再执行DrawCall,所有的这些图形API调用都是与驱动层交互的,而驱动层维护着所有的渲染状态,这些API的调用有可能会触发驱动层的渲染状态的改变,从而发生卡顿。由于驱动层的状态对于上层调用是透明的,因此卡顿是否会发生以及卡顿发生的时间长短对于API的调用者(CPU1)来说都是未知的。而此时其它CPU有可能处于空闲的状态,因此可以将渲染部分抽离出来,放到其它的CPU中,以减少主线程卡顿。
关于图形API的调用卡顿情况,我们在实际项目中做过一些统计,(图二)展示的是我们项目在实际运行两万次的过程中,Unity渲染指令调用耗时峰值发生次数TOP5统计详情:
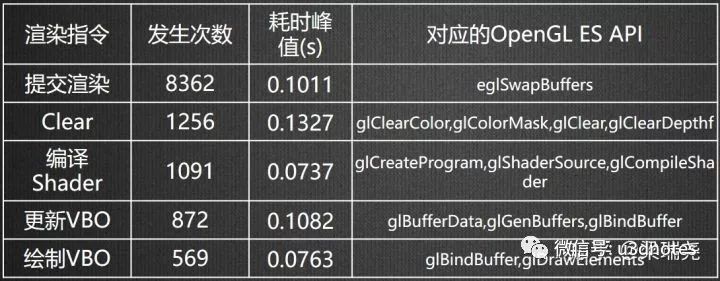
表格的第一列对应的是Unity的渲染指令,第二列是这些指令发生峰值的次数,第三列是指令峰值的平均值,第四列是对应的OpenES的API。从表中数据可以得出两个结论:首先、部分渲染指令的耗时峰值比较高,例如Clear的调用竟然高达0.13秒,也就是说在发生该次峰值时,游戏的帧率会发生剧烈的抖动,瞬间会下降到10帧以下;其次、发生峰值频率最高的是提交渲染,即OpenES的eglSwapbuffers。我们对提交渲染的Top5峰值的机型做了详细的统计,如(图三)
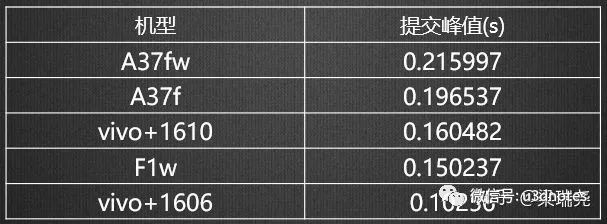
从(图三)中我们可以看到到,个别机型提交渲染时,耗时峰值竟然高达0.21秒。那么为什么提交渲染的耗时会如此之高呢?原来,提交渲染(eglSwapBuffers)会导致驱动层中缓存的渲染指令立即执行,此时CPU被阻塞。如果在提交渲染时驱动层缓存了大量的指令,CPU就会被阻塞很长时间。
在引言中我们提到,现在CPU的运算能力变得越来越强,核心数变得越来越多,关于移动设备的CPU核心数量,我们也做了一些统计,(图四)展示的是在不同国家我们游戏用户手机的CPU核心数量:
(图四上有公司的水印,我先下架了,明天找时间补上新的)
从(图四)可以看到,大多数用户的手机核心都在4核及以上,所以即使在在手机上,多线程渲染也是可行的。
三、多线程渲染框架介绍
在第二节,我们介绍了为什么需要多线程渲染以及多线程渲染的可行性,接下来我们介绍多线程渲染的框架。(这里的多线程渲染其实是指将渲染单独放到一个线程,理论上可以开启不止一个线程来执行渲染指令,但是Opengl并不支持多个线程同时操作同一个Context)
多线程渲染实现方式有很多种,但是大体框架图如(图五)所示:
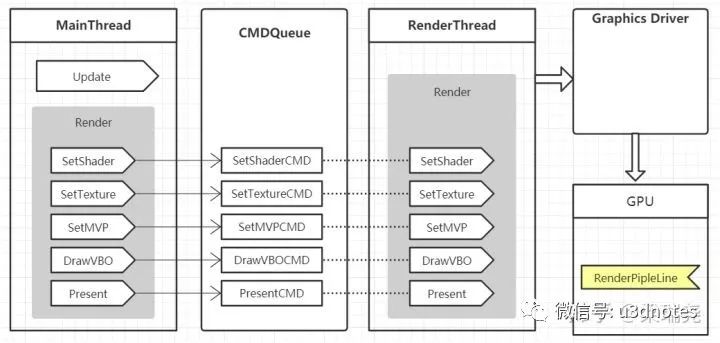
在主线程中调用的图形API被封装成命令,提交到渲染队列,这样就可以节省在主线程中调用图形API的开销,从而提高帧率
渲染线程从渲染队列获取渲染指令并执行调用图形API与驱动层交互,这部分交互耗时从主线程转到渲染线程
四、多线程渲染通信模型
主线程与渲染线程数据传递类似于传统的生产者与消费者模型,即主线程是产生者,不断的生成渲染指令,提交到队列;渲染线程是消费者,不断的从队列获取渲染指令并执行。这种模式最简单的实现方式就是使用一个队列,然后对这个队列的入队和出队加锁保证线程安全即可,但是频繁的加锁会导致两个线程相互阻塞,降低运行效率,因此这种方法在这里就不做介绍。
4.1、双队列+帧同步方案
接下来先介绍第一种方案,双队列+帧同步方案, 其框架图如(图六)所示:
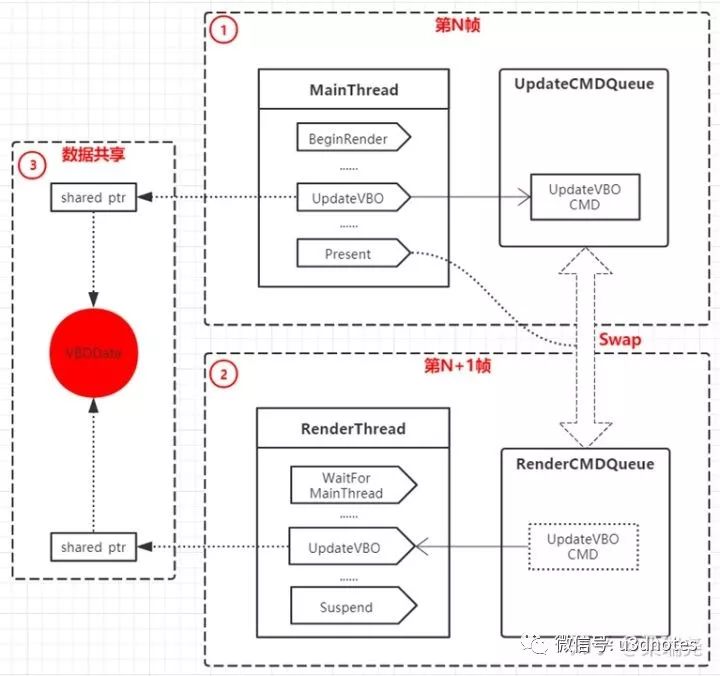
每一帧开始时,主线程调用BeginRender唤醒渲染线程,让渲染线程执行上一帧的渲染指令,此时主线程执行更新逻辑,然后提交本帧的所有渲染指令到更新队列
每一帧主线程在将所有渲染指令放入更新队列后,执行提交命令,此时主线程会同步等待渲染线程执行完渲染队列中上一帧的所有渲染指令直到挂起,然后交换更新队列和渲染队列
每一帧渲染线程执行完渲染队列中的指令后挂起,等待主线程交换队列。在下一帧开始时,会被主线程唤醒执行队列中渲染指令
这种双队列+帧同步的好处主线程与渲染线程分别操作自己的队列,不用考虑由于两个线程同时访问同一队列数据引起的资源竞争问题
缺点是相对于1个队列,2个队列会多一些额外的存储空间,并且由于每一帧结束时才交换队列的内容,渲染相对于逻辑会延迟一帧
线程之间的数据传递使用智能指针,即主线程和渲染线程共享一份资源,因此智能指针必须是线程安全的;另外还有一个潜在的问题——如果资源在渲染线程中被析构,并且析构函数中调用了主线程的方法(比如将某个资源从主线程的队列中移除),可能会发生一些不确定的线程安全问题。
对于上述出现的线程安全问题有两种解决方案,第一种方案是禁止在资源析构函数中调用主线程的函数。第二种方法是使用资源GC,即资源的分配和释放完全在主线程中完成,分配资源时,将资源放到主线程的资源管理器中,引用计数为1,在每一帧结束时,将资源管理器中引用计数为1的资源删除
4.2、管道方案
第二种方案是管道,这也是Unity的多线程渲染采用的方案,其框架图如(图七):
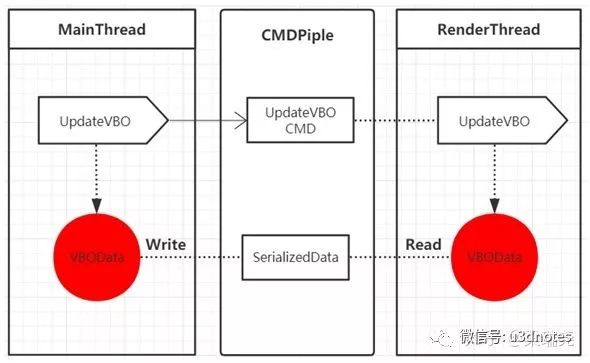
管道可以采用环形buffer来实现,主线程将渲染指令系列化为二进制数据,不断的往buffer里写入,当buffer被填满时,主线程被阻塞;渲染线程不断的从buffer中读取数据,反系列化为渲染指令,当buffer中无数据时,渲染线程被阻塞.
采用环形buffer的优点是读写buffer只需要移动读写点的位置,在只有一个生产者和消费者前提下,环形buffer的读写可以做到无锁(读写点用int32表示,如果32位的int读写是原子操作,那么只需要采用内存屏障来保证在读写点变更时,相应的内存是可用的即可)
采用管道的优点是,不用考虑资源分配与释放的线程安全,因为同一份资源在主线程和渲染线程分别有自己不同的实例,两个线程分别维护自己资源的生命周期
采用管道的缺点是面向数据,它要求所有渲染指令必须能被系列化,因此不能采用抽象度过高的实现方式。比如一个抽象度比较高的渲染指令是传入一个相机、场景和renderTarget,这种级别的抽象使用管道来实现就会比较麻烦。因为它要求相机、场景和renderTarget必须是可系列化的。
采用管道的另一个缺点是为了能读写大容量的资源,需要预先分配一块比较大的内存,而且相对于直接传递资源的指针来说,读取耗时会相对高一些
4.3、环形队列方案
第三种方案是环形队列,这种方案结合和方案一和方案二的优点,其框架图如(图八)所示:
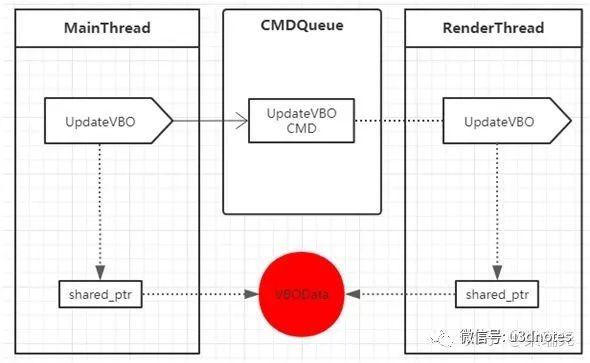
类似于管道方案,主线程不断的将渲染指令加入到队列(但是不用系列化),如果队列被填满,主线程被阻塞;渲染线程不断的从队列中取出数据执行,如果队列为空,渲染线程被阻塞
不用像双队列一样每一帧去同步主线程与渲染线程,渲染虽然会有延迟,但是延迟时长比双队列要短
和管道类似,环形队列的读写操作也可以做到无锁(由于每次读或写只移动一个位置)
与双队列类似,主线程与渲染线程采用智能指针共享资源,资源的线程安全可以采用方案一相同的处理方法
4.4、三种方案的帧率对比
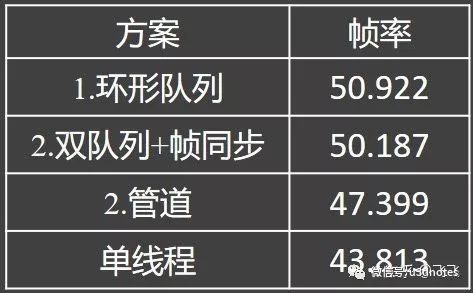
从(图十)中可以看到,环形队列的帧率最高,双队列+帧同步的帧率其次,管道的帧率最低,但是比单线程渲染还是要高出许多。
五、主线程与渲染线程同步策略
第四节主要描述了主线程与渲染线程的通信模型,三种模型在实现的细节上略有不同,但大体的框架上是一致的,即主线程提交渲染指令到缓冲区,渲染线程从缓冲区取出这些数据处理,这是经典的生产者与消费者模式。经典的生产者消费者模式在缓冲区被填满时生产者进入休眠,同样,在缓冲区空时消费者进入休眠,当然多线程渲染也可以采用这种休眠和唤醒的模式,但是这里有一个小问题,当瓶颈在消费者(渲染线程,GPU)时,缓冲区会长时间处于填满的状态,生产者(主线程)可能频繁被休眠和唤醒从而影响帧率;另外在缓冲区被填满时,渲染线程的帧可能会落后主线程多帧,导致画面出现比较高的延迟。
为了解决上术问题,我们需要采取相应的策略来保持主线程与渲染线程同步,对于方案一(双队列+帧同步),在第四节已经描述了同步方案,这里在通过图形来进一步的描述细节,在理想的状态下,主线程与渲染线程的协同如(图十一):

也就是说在每一帧率主线程将渲染指令放后队列后,上一帧的渲染已经完成进入休眠状态,这时候主线程将更新队列与渲染队列交换,在下一帧开始时再唤醒渲染线程执行渲染。如果渲染线程出现瓶颈时,主线程在每一帧结束时会同步的等待渲染线程的上一帧渲染结束,协同如(图十二):

主线程在第2帧执行结束时,渲染线程第1帧渲染还未结束,些时主线程会等待第1帧的渲染执行完毕直到休眠,才会交换更新队列与渲染队列,然后开始第3帧的逻辑更新,同时唤醒渲染线程,执行第二帧的渲染。
对于方案二和方案三,我们可以采取相同的同步策略,第一种同步方案是在主线程在每一帧更新与往队列中提交渲染指令之间同步,如(图十三):

具体同步流程如(图十四):
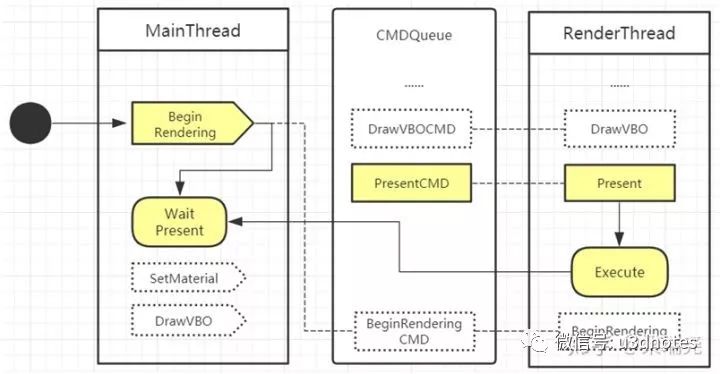
在开始每一帧的渲染时,主线程提交BeginRendering指令,在每一帧渲染结束时,主线程提交Present指令
在提交BeginRendering指令时,如果渲染线程上一帧的渲染指令未结束,主线程会阻塞等待渲染线程直执行完成才会开始这一帧的渲染指令提交
这是Unity多线程渲染采用的同步策略,其实这里还有一些优化空间,假设游戏的瓶颈不在GPU端,但是偶尔因为图形驱动层的状态变更导致某一帧的渲染耗时较高,这种等待策略可能会让主线程在这一帧等待较长的时间,造成帧率的抖动(在这一帧帧率突然下降很多)。比如我们在某次性能的Profiler中就抓到了这样一个热点(如图十五):

其实这时指令队列可能有还大部分剩余空间,如果让主线程将渲染指令提交到队列继续下一帧的更新,会让帧率变得更平滑,因此我们可以采用延时一帧的等待策略,具体等待策略如(图十六):

只有在主线程第3帧Render时,如果发现渲染线程第1帧的渲染指令未处理完成时才会去等待,这样做的好处是,主线程第二帧的渲染指令可以及时提交到队列,然后执行第三帧的Update,不会影响第二帧的帧率。在GPU无瓶颈的情况下,如果第3帧渲染耗时过长只是因为图形驱动层的状态变更而引起的,那么有可能在第四帧的Update过程中,渲染线程已经将第2、3帧的渲染指令处理完成了。
六、渲染API返回值封装
在前面我们提到,多线程渲染是主线程将图形API的调用直接封装成渲染指令,提到到渲染队列,对于调用没有返回值的API来说,这是没问题的,但是对于那些有返回值的图形API,在主线程将渲染指令提交到队列时,应该返回什么值?比如,我们在主线程中创建Sahder(如图十七):此时主线程的CreateShader应该返回什么值?
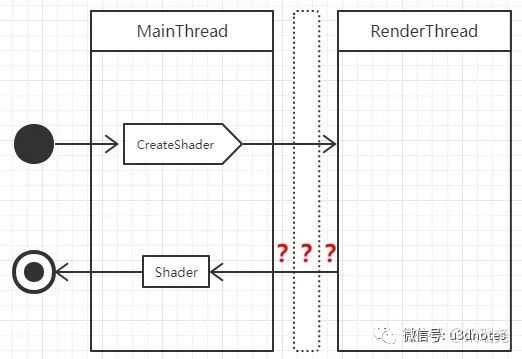
有两种方案可以解决这个问题,第一种方案是阻塞方案,即在调用有返回值的渲染API时,先阻塞主线程,等待渲染线程将队列中指令全部指令完毕返回时,再唤醒主线程,流程如(图十八):
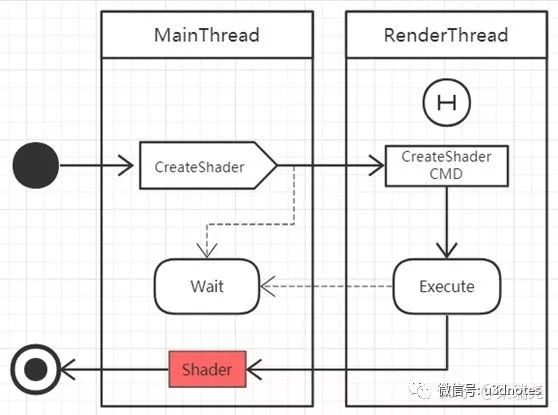
这种方案的优点是实现比较简单,而且保证返回值一定可用,但是由于阻塞了主线程,帧率也会降低。不过大多数有返回值的图形API都是与资源加载相关的,我们可以预先加载好这些资源,避免在Update中频繁的调用。
第二种方案是封装返回值,在主线程调用有返回值的图形API时,在主线程先创建一个被封装的对象直接返回,再将将这个对象作为渲染指令的参数传递到队列,等到渲染线程执行到该指令后创建好正真的对象,再将真正的对象赋值给封装的对象,流程如(图十九):
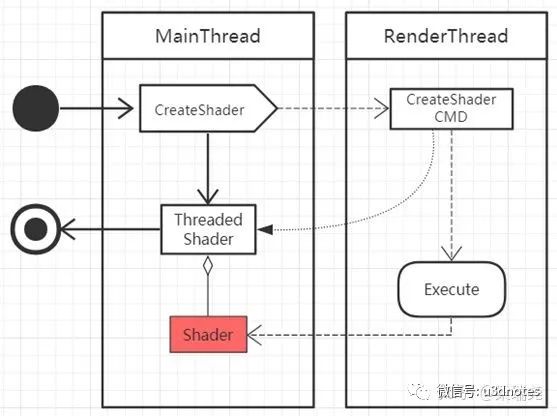
这种方案的优点是非阻塞,对主线程的帧率影响比阻塞方案低;缺点是实现相对复杂,首先,由于对象在主线程与渲染线程之间传递,生命周期维护起来也比较麻烦,比如在主线程中创建的封装对象后,刚好提交到队列时就在主线程中删除了该对象,那么渲染线程指令到这条指令时,有可能会引进崩溃;对于这种情况一种简单的解决办法是在主线程中不直接删除对象,而是将删除对象调用封装成一条指令,提交到队列,让渲染线程来执行删除。其次,由于返回的封装的对象,主线程在调用这个对象具有返回值的函数时,这些函数返回的对象还要做进一步的封装。
void DemoBase::Render()
{
_device->BeginRender();
_device->Clear();
auto program = _device->CreateGPUProgram(vStr, fStr);
_device->UseGPUProgram(program);
auto mvpParam = program->GetParam("MVP");
_device->SetGPUProgramParamAsMat4(mvpParam, _mvp);
_device->DrawVBO(_vbo);
_device->DeletGPUProgram(program);
_device->Present();
}为了突出对比,每一帧的渲染开始时动态加载一个shader,然后使用这个shader渲染vbo,渲染完成后删除这个shader(在每一帧的更新函数中,主线程做5000次矩阵乘法(耗时20毫秒左右)以模拟主线程的繁忙状态),测试结果如(图二十)
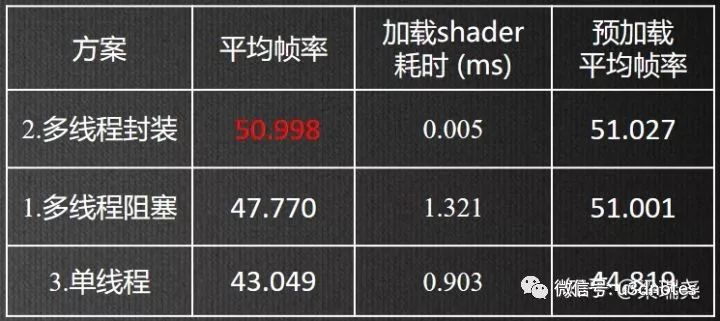
采用阻塞方案时,加载Shader主线程平均被阻塞时长为1.3毫秒,平均帧率为47.7帧
采用封装方案时,加载shader主线程平均被阻塞时长为5微秒,基本可以忽略不计,平均帧最高达50.9帧
采用单线程方案时,加载shader主线程平均被阻塞时长虽然只有0.9毫秒,但是平均帧率最低只有43帧,原因每一次调用opengl的api时,主线程都会被阻塞
在采用预加载后(将创建Shader的代码放到初始化中),阻塞和封装的平均帧率基本上相同,单线程的帧率也有所提高
七、真正的多线程渲染
前面所提到的多线程渲染方案严格意义上来讲并不是多线程渲染,因为我们并没有开启多个线程来执行渲染,主要原因是目前主流的OpenGL、DirectX9,DirecX10并不支持多线程同时访问图形API(或者说多个线程同时访问图形API时有很多限制),所以只能开一个渲染线程来与渲染指令交互。目前,微软的DirectX11已经从架构上支持了真正的多线程渲, 其多线程渲染模型如(图二一):
DirectX11支持两种类型的渲染——立即渲染和延迟渲染(这个和传统意义上的延迟渲染是不同的),这两种渲染模式是基于两种设备的Context的,即immediate context和deferred context,立即渲染的draw call是与immediate context交互,所有的Draw Call被立即提交到图形驱动层,而延迟渲染的draw call调用会先缓存在deferred context的Command list中,在合适的时间通过immediate context提交到图形驱动层。DirectX11支持在多线程中使用不同的deferred context,这样我们可以将复杂的渲染划分成到不同的deferred context中,从而实现多线程渲染。
微软最新的Directx12、苹果的Metal及Khronos的Vulkan对多线程渲染已经有了很好的支持,更弱化了驱动层,它们都有一个Command List的概念,Command List可以并行执行而并不会太多的依赖图形驱动层的优化,将不同的渲染指令提交到不同的Command List,能更充分的利用多核CPU,提高渲染效率,在后续的学习过程中,我也会做进一步的分享。
More:www.u3dnotes.com
以上是关于多线程渲染的主要内容,如果未能解决你的问题,请参考以下文章