分享吧多线程运行效率初探
Posted 大连飞创
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分享吧多线程运行效率初探相关的知识,希望对你有一定的参考价值。
关于多线程
本篇文章是对多线程运行效率的一些简单的描述。首先简要说明线程的概念。然后简单介绍多线程有哪些优缺点。最后详细介绍影响多线程运行效率的因素有哪些以及有哪些解决方案可以提高运行效率。
(一)、线程概念
进程和进程中的线程—图1
线程最直接的理解就是“轻量级进程”,它是一个基本的CPU执行单元,也是程序执行流的最小单元,由线程ID、程序计数器、寄存器集合和堆栈组成。线程是进程中的一个实体,是被系统独立调度和分派的基本单位,线程自己不拥有系统资源,只拥有一点在运行中必不可少的资源,但它可与同属一个进程的其他线程共享进程所拥有的全部资源。一个线程可以创建和撤销另一个线程,同一进程中的多个线程之间可以并发执行。由于线程之间的相互制约,致使线程在运行中呈现出间断性。线程也有就绪、阻塞和运行三种基本状态。
(二)多线程优缺点

理想中的多线程程序运行情况和实际情况对比图

影响多线程效率的因素以及对应的策略
(一)、创建线程的额外开销

(二)、如何避免线程频繁创建和删除
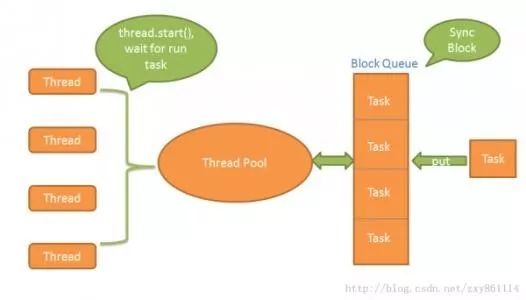
线程池技术说明图
线程池是一种多线程处理形式,处理过程中将任务添加到队列,然后在创建线程后自动启动这些任务。线程池线程都是后台线程。每个线程都使用默认的堆栈大小,以默认的优先级运行,并处于多线程单元中。如果某个线程在托管代码中空闲(如正在等待某个事件),则线程池将插入另一个辅助线程来使所有处理器保持繁忙。如果所有线程池线程都始终保持繁忙,但队列中包含挂起的工作,则线程池将在一段时间后创建另一个辅助线程但线程的数目永远不会超过最大值。超过最大值的线程可以排队,但他们要等到其他线程完成后才启动。(百度百科)
(三)、线程切换的额外开销
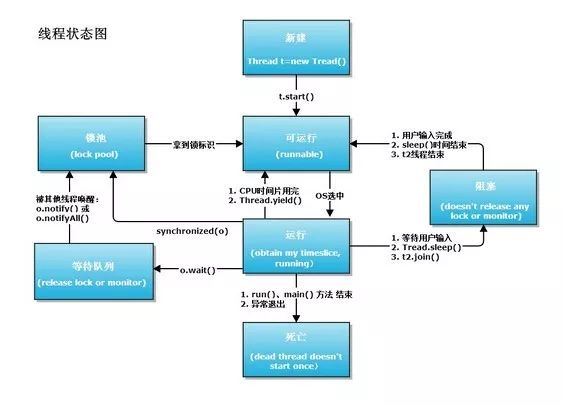
单个CPU一次只能做一件事,所以,OS必须在系统中的所有线程之间共享物理CPU。任何给定的时刻,OS只将一个线程分配给一个CPU。那个线程允许运行一个“时间片”。一旦时间片到期,OS就上下文切换到另一个线程。每次上下文切换都要求OS执行以下操作。

上下文切换完成后,CPU执行所选的线程,知道它的时间片到期。然后,会发生另一次上下文切换。OS大约每30毫秒执行一次上下文切换。上下文切换是净开销,也就说,上下文切换所产生的开销不会带来任何内存或性能上的收益。OS执行上下文切换,向用户提供一个健壮的、响应灵敏的操作系统。
(四)、如何减少线程切换

(五)、资源竞争与锁
在进行并行编程时,我们常常需要使用锁来保护共享变量,以防止多个线程同时对该变量进行更新时产生数据竞跑(Data Race)。所谓数据竞跑,是指两个(或多个)线程同时对某个共享变量进行操作,且这些操作中至少有一个(即>=1)是写操作时所造成的程序错误。
在多线程程序中锁竞争是最主要的性能瓶颈之一。通过使用锁来保护共享变量能防止数据竞跑,保证同一时刻只能有一个线程访问该临界区。但是我们也注意到,正是因为锁造成的对临界区的串行执行导致了并行程序的性能瓶颈。
(六)、如何减少资源竞争的消耗
1、避免使用锁
为了提高程序的并行性,最好的办法自然是不使用锁。从设计角度上来讲,锁的使用无非是为了保护共享资源。如果我们可以避免使用共享资源的话那自然就避免了锁竞争造成的性能损失。幸运的是,在很多情况下我们都可以通过资源复制的方法让每个线程都拥有一份该资源的副本,从而避免资源的共享。如果有需要的话,我们也可以让每个线程先访问自己的资源副本,只在程序最后将各个线程的资源副本合并成一个共享资源。例如,如果我们需要在多线程程序中使用计数器,那么我们可以让每个线程先维护一个自己的计数器,只在程序的最后将各个计数器两两归并(类比二叉树),从而最大程度提高并行度,减少锁竞争。
2、使用读写锁
如果对共享资源的访问多数为读操作,少数为写操作,而且写操作的时间非常短,我们就可以考虑使用读写锁来减少锁竞争。读写锁的基本原则是同一时刻多个读线程可以同时拥有读者锁并进行读操作;另一方面,同一时刻只有一个写进程可以拥有写者锁并进行写操作。读者锁和写者锁各自维护一份等待队列。当拥有写者锁的写进程释放写者锁时,所有正处于读者锁等待队列里的读线程全部被唤醒并被授予读者锁以进行读操作;当这些读线程完成读操作并释放读者锁时,写者锁中的第一个写进程被唤醒并被授予写者锁以进行写操作,如此反复。换句话说,多个读线程和一个写线程将交替拥有读写锁以完成相应操作。这里需要额外补充的一点是锁的公平调度问题。例如,如果在写者锁等待队列中有一个或多个写线程正在等待获得写者锁时,新加入的读线程会被放入读者锁的等待队列。这是因为,尽管这个新加入的读线程能与正在进行读操作的那些读线程并发读取共享资源,但是也不能赋予他们读权限,这样就防止了写线程被新到来的读线程无休止的阻塞。
3、保护数据而不是操作
在实际程序中,有不少程序员在使用锁时图方便而把一些不必要的操作放在临界区中。例如,如果需要对一个共享数据结构进行删除和销毁操作,我们只需要把删除操作放在临界区中即可,资源销毁操作完全可以在临界区之外单独进行,以此增加并行度。
正是因为临界区的执行时间大大影响了并行程序的整体性能,我们必须尽量少在临界区中做耗时的操作,例如函数调用,数据查询,I/O操作等。简而言之,我们需要保护的只是那些共享资源,而不是对这些共享资源的操作,尽可能的把对共享资源的操作放到临界区之外执行有助于减少锁竞争带来的性能损失。
4、尽量使用轻量级的原子操作
例如使用了mutex锁来保护(int)counter++操作。实际上,counter++操作完全可以使用更轻量级的原子操作来实现,根本不需要使用mutex锁这样相对较昂贵的机制来实现。
5、粗粒度锁与细粒度锁
为了减少串行部分的执行时间,我们可以通过把单个锁拆成多个锁的办法来较小临界区的执行时间,从而降低锁竞争的性能损耗,即把“粗粒度锁”转换成“细粒度锁”。但是,细粒度锁并不一定更好。这是因为粗粒度锁编程简单,不易出现死锁等Bug,而细粒度锁编程复杂,容易出错;而且锁的使用是有开销的(例如一个加锁操作一般需要100个CPU时钟周期),使用多个细粒度的锁无疑会增加加锁解锁操作的开销。在实际编程中,我们往往需要从编程复杂度、性能等多个方面来权衡自己的设计方案。事实上,在计算机系统设计领域,没有哪种设计是没有缺点的,只有仔细权衡不同方案的利弊才能得到最适合自己当前需求的解决办法。例如,Linux内核在初期使用了Big Kernel Lock(粗粒度锁)来实现并行化。从性能上来讲,使用一个大锁把所有操作都保护起来无疑带来了很大的性能损失,但是它却极大的简化了并行整个内核的难度。当然,随着Linux内核的发展,Big Kernel Lock已经逐渐消失并被细粒度锁而取代,以取得更好的性能。
(七)、伪共享
伪共享( false sharing ):缓存系统中是以缓存行(cache line)为单位存储的,当多线程修改互相独立的变量时,如果这些变量共享同一个缓存行,就会无意中影响彼此的性能,这就是伪共享。
1、CPU 缓存
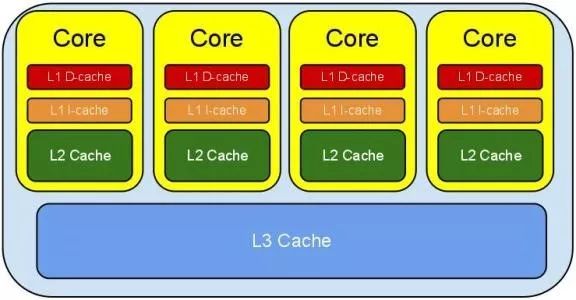
CPU缓存系统
CPU 缓存(Cache Memory)是位于 CPU 与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。(百度百科)
按照数据读取顺序和与 CPU 结合的紧密程度,CPU 缓存可以分为一级缓存,二级缓存,部分高端 CPU 还具有三级缓存。每一级缓存中所储存的全部数据都是下一级缓存的一部分,越靠近 CPU 的缓存越快也越小。所以 L1 缓存很小但很快,并且紧靠着在使用它的 CPU 内核。L2 大一些,也慢一些,并且仍然只能被一个单独的 CPU 核使用。L3 在现代多核机器中更普遍,仍然更大,更慢,并且被单个插槽上的所有 CPU 核共享。最后,你拥有一块主存,由全部插槽上的所有 CPU 核共享。拥有三级缓存的的 CPU,到三级缓存时能够达到 95% 的命中率,只有不到 5% 的数据需要从内存中查询。
当 CPU 执行运算的时候,它先去 L1 查找所需的数据,再去 L2,然后是 L3,最后如果这些缓存中都没有,所需的数据就要去主内存拿。走得越远,运算耗费的时间就越长。所以如果你在做一些很频繁的事,你要确保数据在 L1 缓存中。
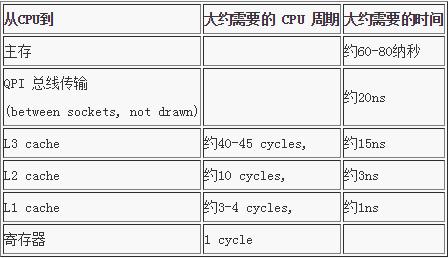
缓存未命中的消耗数据,如下所示:
2、MESI 协议及 RFO 请求
MESI 协议。现在主流的处理器都是用它来保证缓存的相干性和内存的相干性。M、E、S 和 I 代表使用 MESI 协议时缓存行所处的四个状态:
M(修改,Modified):本地处理器已经修改缓存行,即是脏行,它的内容与内存中的内容不一样,并且此 cache 只有本地一个拷贝(专有);
E(专有,Exclusive):缓存行内容和内存中的一样,而且其它处理器都没有这行数据;
S(共享,Shared):缓存行内容和内存中的一样, 有可能其它处理器也存在此缓存行的拷贝;
I(无效,Invalid):缓存行失效, 不能使用。
下面说明这四个状态是如何转换的:
初始:一开始时,缓存行没有加载任何数据,所以它处于 I 状态。
本地写(Local Write):如果本地处理器写数据至处于 I 状态的缓存行,则缓存行的状态变成 M。
本地读(Local Read):如果本地处理器读取处于 I 状态的缓存行,很明显此缓存没有数据给它。此时分两种情况:(1)其它处理器的缓存里也没有此行数据,则从内存加载数据到此缓存行后,再将它设成 E 状态,表示只有我一家有这条数据,其它处理器都没有;(2)其它处理器的缓存有此行数据,则将此缓存行的状态设为 S 状态。(备注:如果处于M状态的缓存行,再由本地处理器写入/读出,状态是不会改变的)
远程读(Remote Read):假设我们有两个处理器 c1 和 c2,如果 c2 需要读另外一个处理器 c1 的缓存行内容,c1 需要把它缓存行的内容通过内存控制器 (Memory Controller) 发送给 c2,c2 接到后将相应的缓存行状态设为 S。在设置之前,内存也得从总线上得到这份数据并保存。
远程写(Remote Write):其实确切地说不是远程写,而是 c2 得到 c1 的数据后,不是为了读,而是为了写。也算是本地写,只是 c1 也拥有这份数据的拷贝,这该怎么办呢?c2 将发出一个 RFO (Request For Owner) 请求,它需要拥有这行数据的权限,其它处理器的相应缓存行设为 I,除了它自已,谁不能动这行数据。这保证了数据的安全,同时处理 RFO 请求以及设置I的过程将给写操作带来很大的性能消耗。
状态转换由下图做个补充:
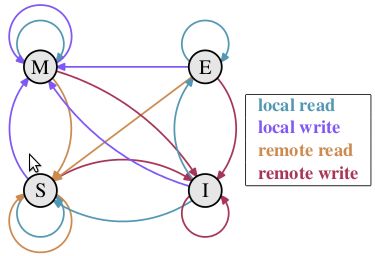
我们从上节知道,写操作的代价很高,特别当需要发送 RFO 消息时。我们编写程序时,什么时候会发生 RFO 请求呢?有以下两种:
1. 线程的工作从一个处理器移到另一个处理器, 它操作的所有缓存行都需要移到新的处理器上。此后如果再写缓存行,则此缓存行在不同核上有多个拷贝,需要发送 RFO 请求了。
2. 两个不同的处理器确实都需要操作相同的缓存行。
3、伪共享
如果存在这样的场景,有多个线程操作不同的成员变量,但是相同的缓存行,这个时候会发生什么?没错,伪共享(False Sharing)问题就发生了!如下:
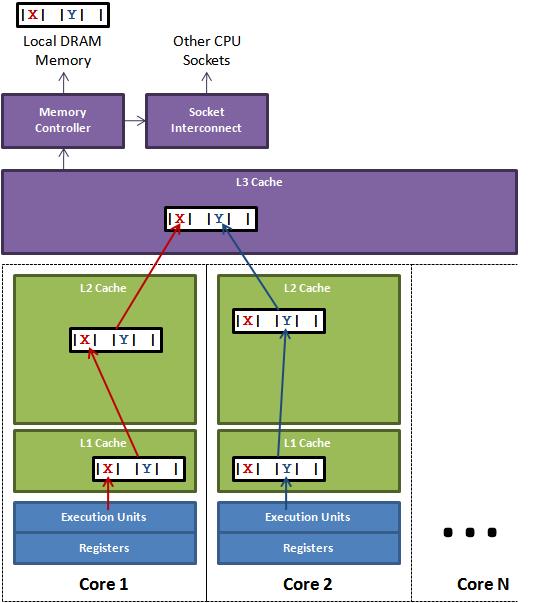
上图中,一个运行在处理器 core1上的线程想要更新变量 X 的值,同时另外一个运行在处理器 core2 上的线程想要更新变量 Y 的值。但是,这两个频繁改动的变量都处于同一条缓存行。两个线程就会轮番发送 RFO 消息,占得此缓存行的拥有权。当 core1 取得了拥有权开始更新 X,则 core2 对应的缓存行需要设为 I 状态。当 core2 取得了拥有权开始更新 Y,则 core1 对应的缓存行需要设为 I 状态(失效态)。轮番夺取拥有权不但带来大量的 RFO 消息,而且如果某个线程需要读此行数据时,L1 和 L2 缓存上都是失效数据,只有 L3 缓存上是同步好的数据。从前一篇我们知道,读 L3 的数据非常影响性能。更坏的情况是跨槽读取,L3 都要 miss,只能从内存上加载。
表面上 X 和 Y 都是被独立线程操作的,而且两操作之间也没有任何关系。只不过它们共享了一个缓存行,但所有竞争冲突都是来源于共享。
(八)、如何避免伪共享
其中一个解决思路,就是让不同线程操作的对象处于不同的缓存行即可。
那么该如何做到呢?其实在我们注释的那行代码中就有答案,那就是缓存行填充(Padding) 。现在分析上面的例子,我们知道一条缓存行有 64 字节,而 Java 程序的对象头固定占 8 字节(32位系统)或 12 字节( 64 位系统默认开启压缩, 不开压缩为 16 字节),所以我们只需要填 6 个无用的长整型补上6*8=48字节,让不同的 VolatileLong 对象处于不同的缓存行,就避免了伪共享( 64 位系统超过缓存行的 64 字节也无所谓,只要保证不同线程不操作同一缓存行就可以)。
伪共享在多核编程中很容易发生,而且非常隐蔽。例如,在 JDK 的 LinkedBlockingQueue 中,存在指向队列头的引用 head 和指向队列尾的引用 tail 。而这种队列经常在异步编程中使有,这两个引用的值经常的被不同的线程修改,但它们却很可能在同一个缓存行,于是就产生了伪共享。线程越多,核越多,对性能产生的负面效果就越大。
由于某些 Java 编译器的优化策略,那些没有使用到的补齐数据可能会在编译期间被优化掉,我们可以在程序中加入一些代码防止被编译优化。如下:

另外一种技术是使用编译指示,来强制使每一个变量对齐。

当使用数组时,在 cache line 尾部填充 padding 来保证数据元素在 cache line 边界开始。如果不能够保证数组按照 cache line 边界对齐,填充数据结构【数组元素】使之是 cache line 大小的两倍。下面的代码显式了填充数据结构使之按照 cache line 对齐。并且通过 __declspec( align(n) ) 语句来保证数组也是对齐的。如果数组是动态分配的,你可以增加分配的大小,并调整指针来对其到 cache line 边界。
参考文章:https://www.cnblogs.com/cyfonly/p/5800758.html
1
END
1
以上是关于分享吧多线程运行效率初探的主要内容,如果未能解决你的问题,请参考以下文章