多线程环境下的惊群现象
Posted 酣睡中的银酱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多线程环境下的惊群现象相关的知识,希望对你有一定的参考价值。
惊群现象的含义
惊群效应(thundering herd)是指多进程(多线程)在同时阻塞等待同一个事件的时候(休眠状态),如果等待的这个事件发生,那么他就会唤醒等待的所有进程(线程),但是最终却只能有一个进程(线程)获得这个时间的“控制权”,对该事件进行处理,而其他进程(线程)获取“控制权”失败,只能重新进入休眠状态,这种现象和性能浪费就叫做惊群效应。
惊群现象性能风险
Linux 内核对用户进程(线程)频繁地做无效的调度、上下文切换等使系统性能大打折扣。上下文切换(context switch)过高会导致 CPU,频繁地在寄存器和运行队列之间奔波,更多的时间花在了进程(线程)切换,而不是在真正工作的进程(线程)上面。直接的消耗包括 CPU 寄存器要保存和加载(例如程序计数器)、系统调度器的代码需要执行。间接的消耗在于多核 cache 之间的共享数据。
为了确保只有一个进程(线程)得到资源,需要对资源操作进行加锁保护,加大了系统的开销。目前一些常见的服务器软件有的是通过锁机制解决的,比如 nginx(它的锁机制是默认开启的,可以关闭);还有些认为惊群对系统性能影响不大,没有去处理,比如 Lighttpd。
线程的状态
如下图所示,惊群现象发生在线程由阻塞状态到就绪状态。线程的状态:创建 + 就绪 + 运行 + 阻塞(等待) + 退出。
创建:一个新的线程被创建,等待该线程被调用执行;
就绪:时间片已用完,此线程被强制暂停,等待下一个属于他的时间片来
运行:此线程正在执行,正在占用CPU时间片;
阻塞:也叫等待状态,等待某一事件(如IO或另一个线程)执行完;
退出:一个线程完成任务或者其他终止条件发生,该线程终止进入退出状态,退出状态释放该线程所分配的资源。
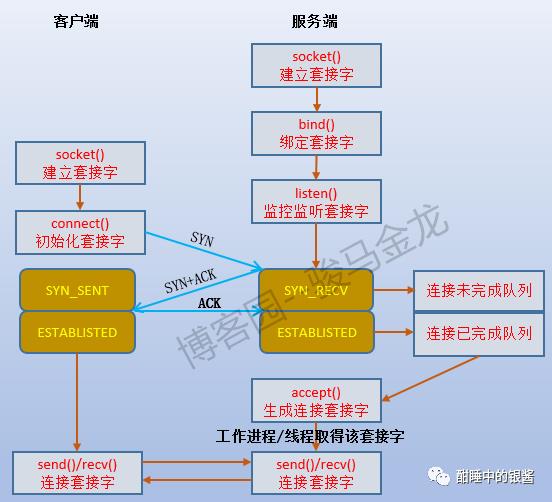
TCP连接过程
如下图所示,
accpet()函数的作用是读取已完成连接队列中的第一项(读完就从队列中移除),并对此项生成一个用于后续连接的套接字描述符,假设使用connfd来表示。有了新的连接套接字,工作进程/线程(称其为工作者)就可以通过这个连接套接字和客户端进行数据传输,而前文所说的监听套接字(sockfd)则仍然被监听者监听。
例如,prefork模式的httpd,每个子进程既是监听者,又是工作者,每个客户端发起连接请求时,子进程在监听时将它接收进来,并释放对监听套接字的监听,使得其他子进程可以去监听这个套接字。多个来回后,终于是通过accpet()函数生成了新的连接套接字,于是这个子进程就可以通过这个套接字专心地和客户端建立交互,当然,中途可能会因为各种io等待而多次被阻塞或睡眠。这种效率真的很低,仅仅考虑从子进程收到SYN消息开始到最后生成新的连接套接字这几个阶段,这个子进程一次又一次地被阻塞。当然,可以将监听套接字设置为非阻塞IO模式,只是即使是非阻塞模式,它也要不断地去检查状态。
再考虑worker/event处理模式,每个子进程中都使用了一个专门的监听线程和N个工作线程。监听线程专门负责监听并建立新的连接套接字描述符,放入apache的套接字队列中。这样监听者和工作者就分开了,在监听的过程中,工作者可以仍然可以自由地工作。如果只从监听这一个角度来说,worker/event模式比prefork模式性能高的不是一点半点。
当监听者发起accept()系统调用的时候,如果已完成连接队列中没有任何数据,那么监听者会被阻塞。当然,可将套接字设置为非阻塞模式,这时accept()在得不到数据时会返回EWOULDBLOCK或EAGAIN的错误。可以使用select()或poll()或epoll来等待已完成连接队列的可读事件。还可以将套接字设置为信号驱动IO模式,让已完成连接队列中新加入的数据通知监听者将数据复制到app buffer中并使用accept()进行处理。
TCP连接与多线程
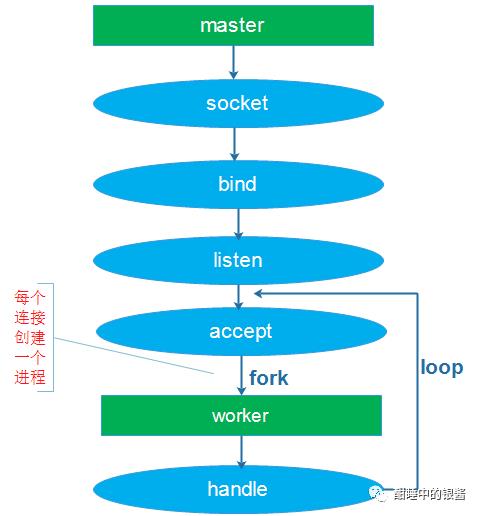
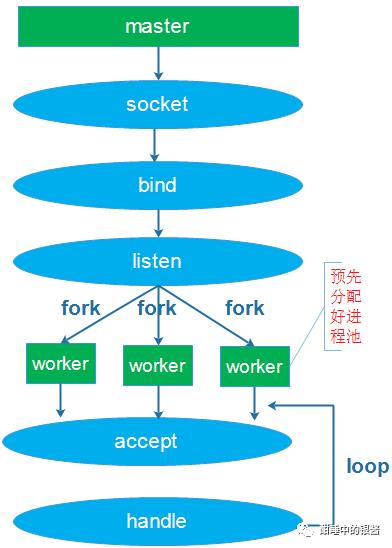
如下图所示
目前常见的网络编程模型就是多进程或多线程,根据accpet的位置,分为如下场景:
(1)单进程或线程创建socket,并进行listen和accept,接收到连接后创建进程和线程处理连接
(2)单进程或线程创建socket,并进行listen,预先创建好多个工作进程或线程accept()在同一个服务器套接字
这两种情况都会触发惊群现象
 |
 |
Linux 解决方案之SO_REUSEPORT
Linux kernel 3.9带来了SO_REUSEPORT特性,SO_REUSEPORT支持多个进程或者线程绑定到同一端口,提高服务器程序的性能,解决的问题:
允许多个套接字 bind()/listen() 同一个TCP/UDP端口
每一个线程拥有自己的服务器套接字
在服务器套接字上没有了锁的竞争
内核层面实现负载均衡
安全层面,监听同一个端口的套接字只能位于同一个用户下面
其核心的实现主要有三点:
扩展 socket option,增加 SO_REUSEPORT 选项,用来设置 reuseport。
修改 bind 系统调用实现,以便支持可以绑定到相同的 IP 和端口
修改处理新建连接的实现,查找 listener 的时候,能够支持在监听相同 IP 和端口的多个 sock 之间均衡选择。
Linux 解决方案之 Accept
Linux 2.6 版本之前,监听同一个 socket 的进程会挂在同一个等待队列上,当请求到来时,会唤醒所有等待的进程。
Linux 2.6 版本之后,通过引入一个标记位 WQ_FLAG_EXCLUSIVE,解决掉了 accept 惊群效应。
Linux 解决方案之 Epoll
如下图所示,先介绍下Epoll执行过程:
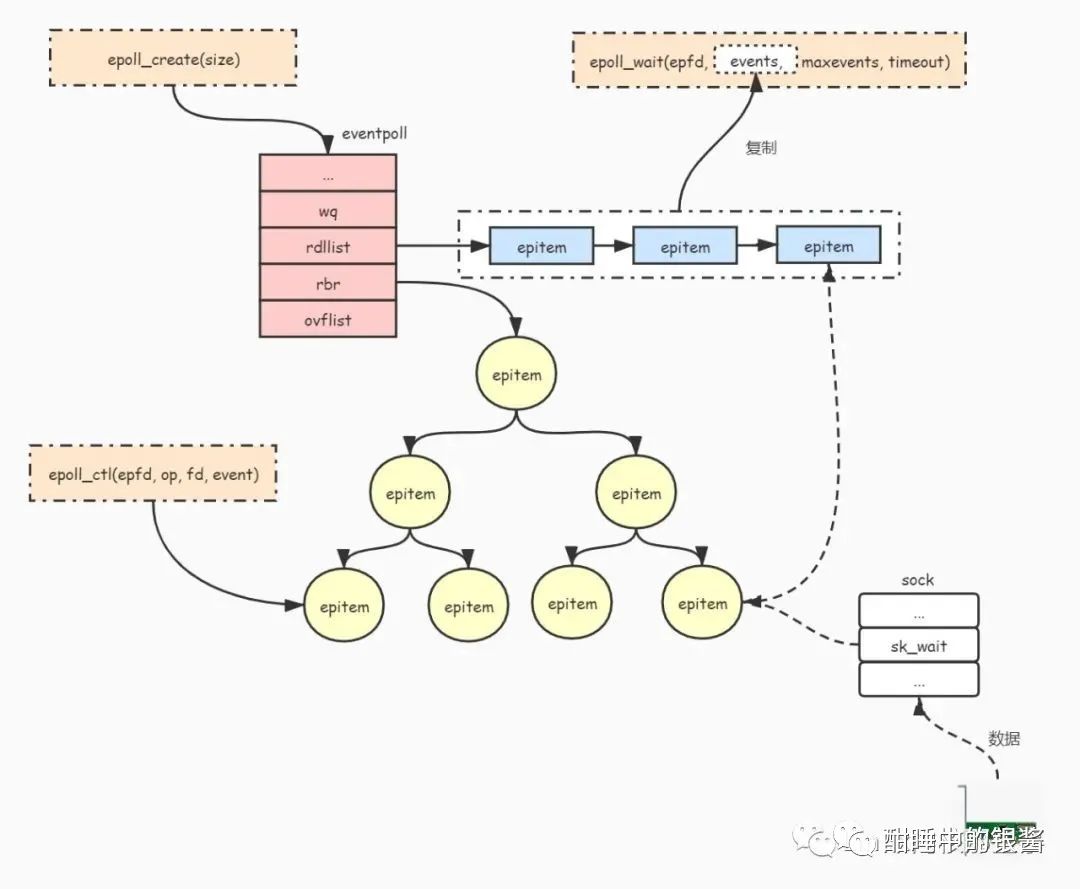
通过调用
epoll_create()函数创建并初始化一个eventpoll对象。通过调用
epoll_ctl()函数把被监听的文件句柄 (如socket句柄) 封装成epitem对象并且添加到eventpoll对象的红黑树中进行管理。通过调用
epoll_wait()函数等待被监听的文件状态发生改变。当被监听的文件状态发生改变时(如socket接收到数据),会把文件句柄对应
epitem对象添加到eventpoll对象的就绪队列rdllist中。并且把就绪队列的文件列表复制到epoll_wait()函数的events参数中。唤醒调用
epoll_wait()函数被阻塞(睡眠)的进程。
在使用 select、poll、epoll、kqueue 等 IO 复用时,多进程(线程)处理链接更加复杂。
在讨论 epoll 的惊群效应时候,需要分为两种情况:
epoll_create 在 fork 之前创建
epoll_create 在 fork 之后创建
epoll_create 在 fork 之前创建
与 accept 惊群的原因类似,当有事件发生时,等待同一个文件描述符的所有进程(线程)都将被唤醒,而且解决思路和 accept 一致。
为什么需要全部唤醒?因为内核不知道,你是否在等待文件描述符来调用 accept() 函数,还是做其他事情(信号处理,定时事件)。
此种情况惊群效应已经被解决。
epoll_create 在 fork 之后创建
epoll_create 在 fork 之前创建的话,所有进程共享一个 epoll 红黑数。
如果我们只需要处理 accept 事件的话,貌似世界一片美好了。但是 epoll 并不是只处理 accept 事件,accept 后续的读写事件都需要处理,还有定时或者信号事件。
当连接到来时,我们需要选择一个进程来 accept,这个时候,任何一个 accept 都是可以的。当连接建立以后,后续的读写事件,却与进程有了关联。一个请求与 a 进程建立连接后,后续的读写也应该由 a 进程来做。
当读写事件发生时,应该通知哪个进程呢?Epoll 并不知道,因此,事件有可能错误通知另一个进程,这是不对的。所以一般在每个进程(线程)里面会再次创建一个 epoll 事件循环机制,每个进程的读写事件只注册在自己进程的 epoll 种。
我们知道 epoll 对惊群效应的修复,是建立在共享在同一个 epoll 结构上的。epoll_create 在 fork 之后执行,每个进程有单独的 epoll 红黑树,等待队列,ready 事件列表。因此,惊群效应再次出现了。有时候唤醒所有进程,有时候唤醒部分进程,可能是因为事件已经被某些进程处理掉了,因此不用在通知另外还未通知到的进程了。
Nginx 解决方案之锁的设计
首先我们要知道在用户空间进程间锁实现的原理,起始原理很简单,就是能弄一个让所有进程共享的东西,比如 mmap 的内存,比如文件,然后通过这个东西来控制进程的互斥。
Nginx 中使用的锁是自己来实现的,这里锁的实现分为两种情况,一种是支持原子操作的情况,也就是由 NGX_HAVE_ATOMIC_OPS 这个宏来进行控制的,一种是不支持原子操作,这是是使用文件锁来实现。
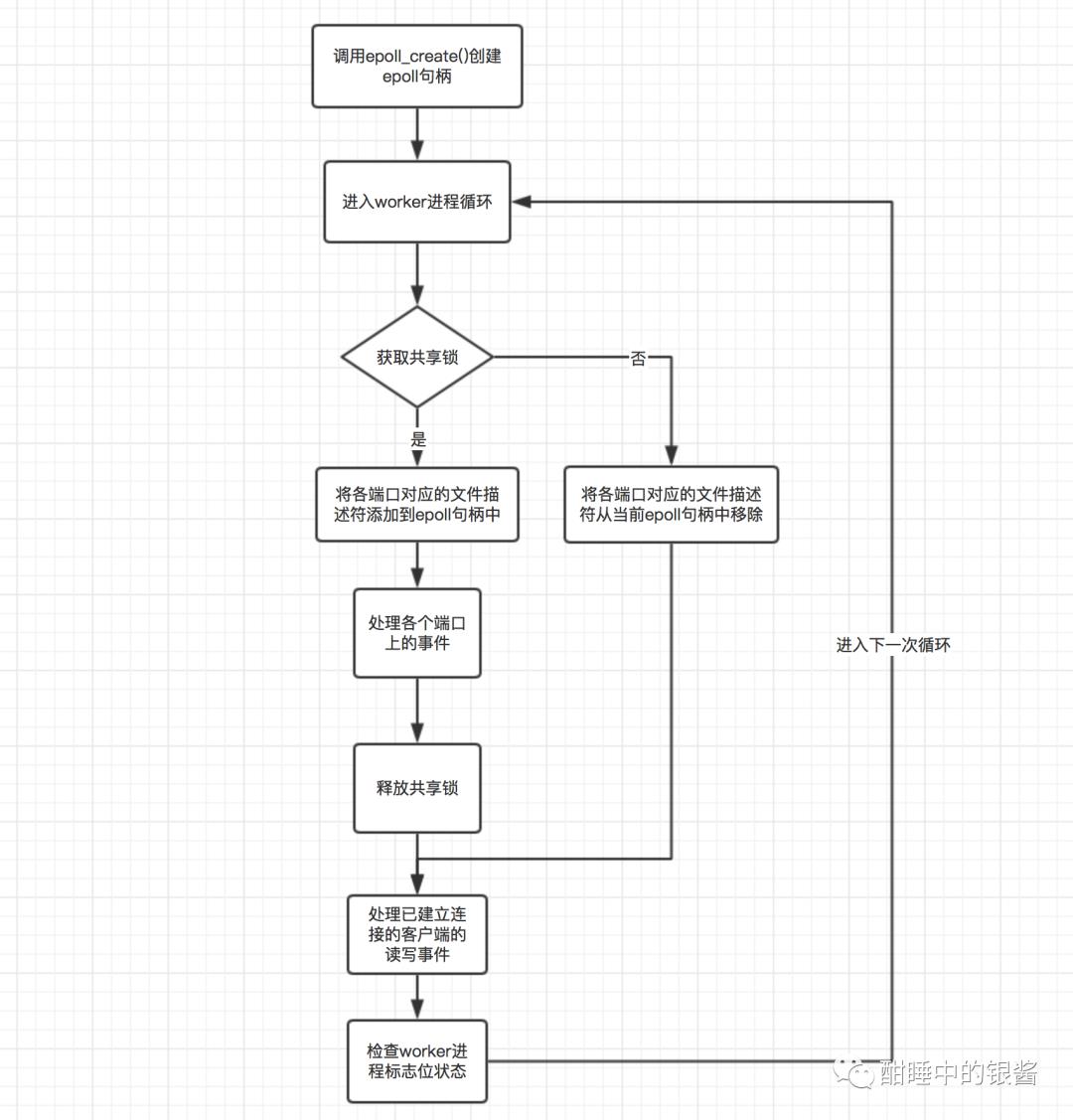
当一个连接来的时候,此时每个进程的 epoll 事件列表里面都是有该 fd 的。抢到该连接的进程先释放锁,在 accept。没有抢到的进程把该 fd 从事件列表里面移除,不必再调用 accept,造成资源浪费。
同时由于锁的控制(以及获得锁的定时器),每个进程都能相对公平的 accept 句柄,也就是比较好的解决了子进程负载均衡。
Libevent事件处理流程
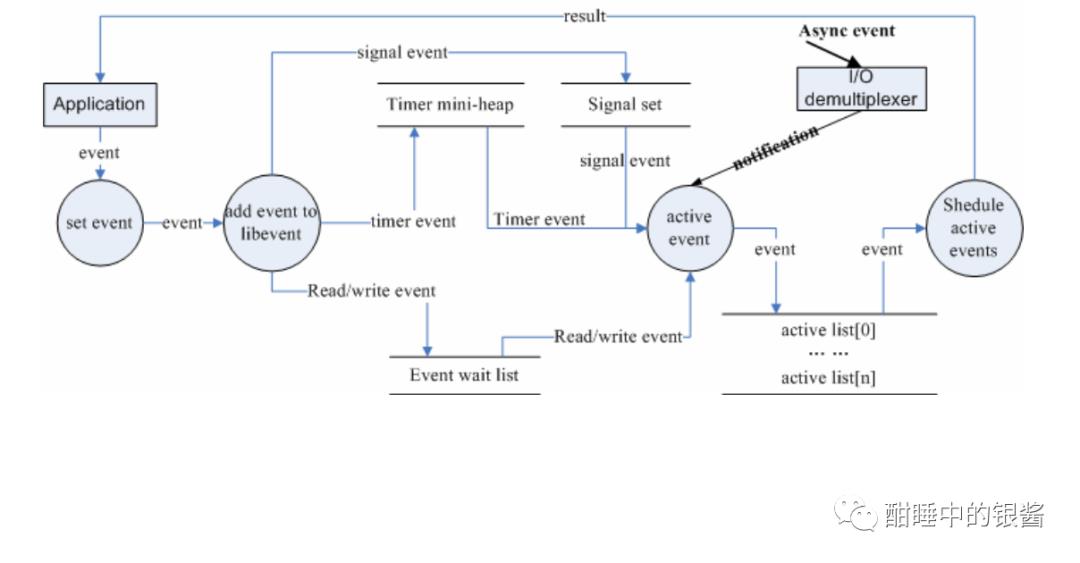
基本使用场景和事件流程:
当应用程序向libevent 注册一个事件后,libevent 内部是怎么样进行处理的呢?下面的图就给出了这一基本流程。
1、首先应用程序准备并初始化event,设置好事件类型和回调函数;这对应于event_set()、event_assign()和event_base_set()两个函数;2、向libevent 添加该事件event。对于定时事件,libevent使用一个小根堆管理,key为超时时间;对于Signal和I/O事件,libevent将其放入到等待链表(wait list)中,这是一个双向链表结构;3、程序调用event_base_dispatch()系列函数进入无限循环,等待事件发生,以epoll函数为例;每次循环前libevent会检查定时事件的最小超时时间tv,根据tv设置epoll的最大等待时间,以便于后面及时处理超时事件;当epoll_wait()返回后,首先检查超时事件,然后检查I/O事件;Libevent将所有的就绪事件,放入到激活链表中;然后对激活链表中的事件,调用事件的回调函数执行事件处理。
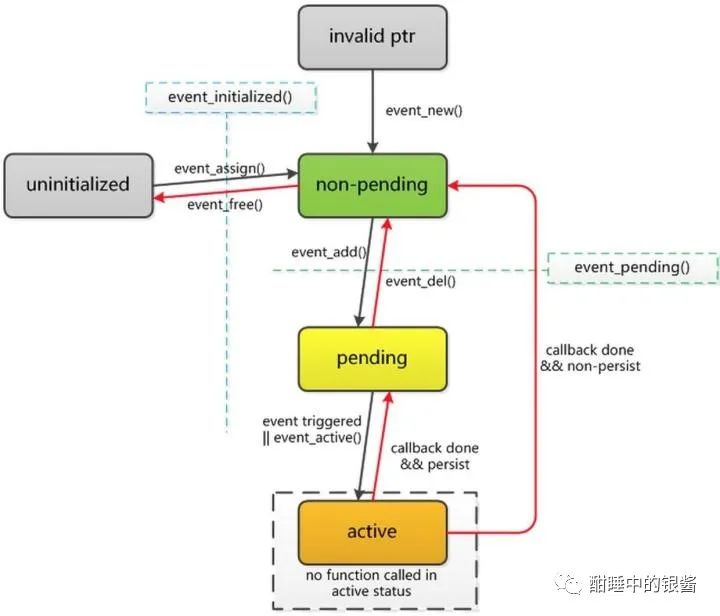
Libevent惊群之memcached
如下图所示,memcached使用Libevent避免了多线程获取accept建立的连接fd,此种情况自然没有惊群现象,其中的多线程模型就是典型的消息通知+同步层机制。
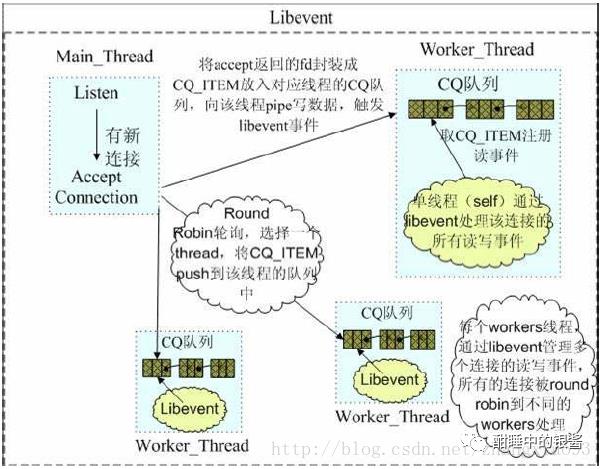
Libevent惊群之Envoy
众所周知,云原生边车代理Envoy使用Libevent来进行异步非阻塞的连接,那么Envoy有没有惊群现象?
libevent函数
evconnlistener_new 把一个 已经bind port 的listening fd和callback注册到eventloop,当accept到新连接的时候会触发callback。Envoy里面采用这个函数把同一个listening fd注册到所有的Worker的eventloop中,当新连接来的时候,由内核选择应该分发给哪个Worker,利用了libevent对连接的读写事件进行监听,同时采用了epoll边缘触发的机制。
event_assign 把一个fd和一个callback注册到eventloop,当read write closed事件触发的时候触发callback
event_active 立即触发一个eventloop中的event,执行callback
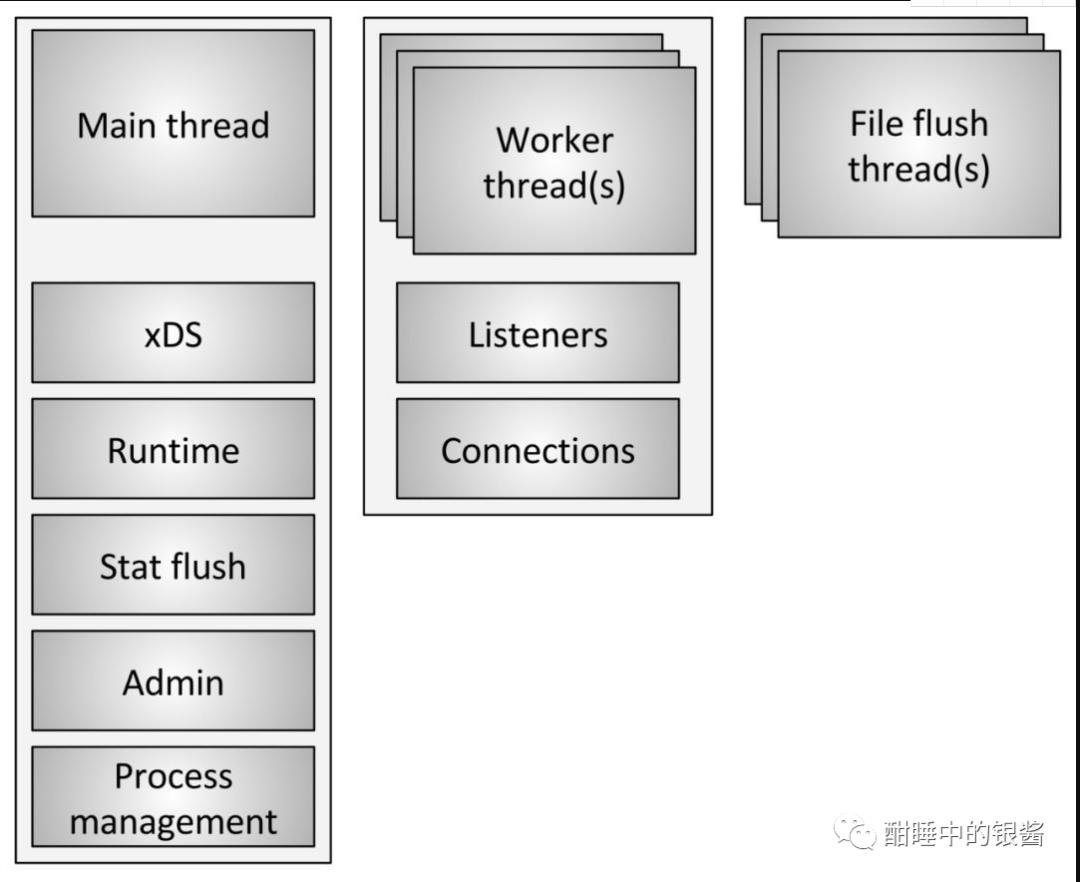
Envoy线程模型
Envoy 使用三种不同类型的线程,如上图所示。
Main:此线程负责服务器启动和关闭,所有 xDS API 处理(包括 DNS,运行状况检查 和常规 集群管理),运行时,统计刷新,管理和一般进程管理(信号,热启动 等)。在此线程上发生的所有事情都是异步的并且是 “非阻塞的”。通常,主线程协调所有不需要大量 CPU 来完成的关键过程功能。这允许将大多数管理代码编写为单线程编写。
Worker:默认情况下,Envoy 为系统中的每个硬件线程生成一个工作线程。(这可以通过 –concurrency 选项 控制)。每个工作线程运行一个 “非阻塞” 事件循环,负责监听每个监听器(当前没有监听器分片),接受新连接,为连接实例化过滤器堆栈,以及处理所有 IO 的生命周期。连接。同样,这允许将大多数连接处理代码写成好像是单线程的。
文件刷新器:Envoy 写入的每个文件(主要是访问日志)当前都有一个独立的阻塞刷新线程。这是因为即使使用 O_NONBLOCK 写入文件系统缓存文件有时也会阻塞(哎)。当工作线程需要写入文件时,数据实际上被移入内存缓冲区,最终通过文件刷新线程刷新。这是代码的一个区域,技术上所有 worker 都可以阻止同一个锁尝试填充内存缓冲区。
如下图所示, Envoy 进程启动时会开启监听端口(listener),一旦监听器接受了客户端的连接,此连接的生命周期就会绑定到 Envoy 内的一个工作线程上。由此可知,Envoy 被设计成多个单线程并行,100% 无阻塞的模式, 默认情况下,Envoy 工作线程之间相互独立且并无联系,这意味着所有工作线程都独立尝试在监听器上接受连接,并依靠内核在线程之间做负载均衡。
所以Envoy也是没有惊群现象的。
每个工作线程会为每个监听器维护各自的监听器实例。每个监听器可能通过SO_REUSEPORT 绑定到相同的端口,或共享绑定到该端口的socket。当接收到一个新的TCP连接,内核会决定哪个工作线程来接收该连接,然后由该工作线程对应的监听器调用Server::ConnectionHandlerImpl::ActiveTcpListener::onAccept()
以上是关于多线程环境下的惊群现象的主要内容,如果未能解决你的问题,请参考以下文章
Redis 利用锁机制来防止缓存过期产生的惊群现象-转载自 http://my.oschina.net/u/1156660/blog/360552