JDK 源码解析 — 集合HashMap
Posted 上山打卤面
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了JDK 源码解析 — 集合HashMap相关的知识,希望对你有一定的参考价值。
HashMap ,是一种散列表,用于存储 key-value 键值对的数据结构,一般翻译为“哈希表”,提供平均时间复杂度为 O(1) 的、基于 key 级别的 get/put 等操作。
之前我们在 ArrayList码分析中提到过,“在前些年,实习或初级工程师的面试,可能最爱问的就是 ArrayList 和 LinkedList 的区别与使用场景或者是HashMap 的实现原理是什么“。
在日常的业务开发中,HashMap 可以说是和 ArrayList 一样常用的集合类,特别是考虑到数据库的性能,又或者服务的拆分后,我们把关联数据的拼接,放到了内存中,这就需要使用到 HashMap 做本地缓存等等。
类图
实现
java.util.Map接口,继承
java.util.AbstractMap抽像类。实现
java.io.Serializable接口。实现
java.lang.Cloneable接口。
属性
在开始看 HashMap 的具体属性之前,我们先来简单说说 HashMap 的实现原理
HashMap 有 O(1) 的 get 操作的时间复杂度 在我们已知的数据结构中,只有基于下标访问数组时,才能提供 O(1) get 操作的时间复杂度。
实际上,HashMap 所提供的 O(1) 是平均时间复杂度,大多数情况下保证 O(1) 极端情况下,有可能退化为 O(N) 的时间复杂度,这又是为什么呢?下面的代码会给你解释:
HashMap 其实是在数组的基础上实现的,一个“加强版”的数组。如下图所示:
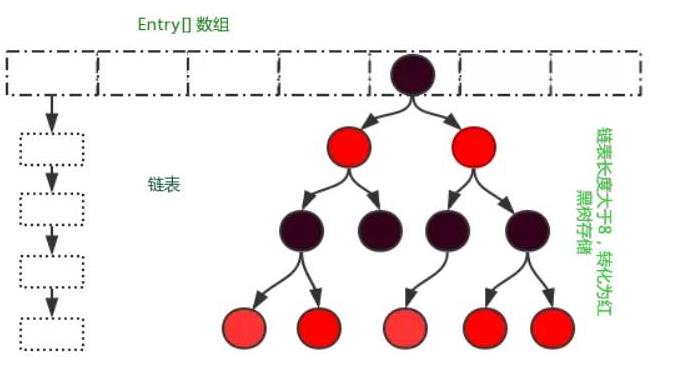
第一次看到这个节点可能会不理解这个是什么结构:是数组 链表 还有红黑树?你可能会脱口而出WDNMD,其实这就是hash结构,通过 hash(key) 的过程,我们可以将 key 成功的转成一个整数。但是,hash(key) 可能会超过数组的容量,所以我们需要 hash(key) % size 作为下标,放入数组的对应位置。至此,我们是不是已经可以通过 O(1) 的方式,快速的从 HashMap 中进行 get 读取操作了。
注意,一般每个数组的“位置”,比较专业的说法,叫做“槽位”(slot)或者“桶”。因为代码注释里,已经都使用了“位置”,所以我们就暂时不进行修正了。
使用上面的形式就能保证O(1)的时间复杂度?答案是不是的原因有两点:
1、hash(key) 计算出来的哈希值,并不能保证唯一;
2、hash(key) % size 的操作后,即使不同的哈希值,也可能变成相同的结果
这样,就导致我们常说的“哈希冲突”。那么怎么解决呢?方法有两种:
1、开放寻址法 由于HashMap使用的不是这种方式,本文暂时不展开关于开放寻址法的内容,等到ThreadLocalMap 的时候,在进行详细的解释。
但是如果我们放入的 N 个 key-value 键值对到 HashMap 的情况:
每个 key 经过
hash(key) % size对应唯一下标,则 get 时间复杂度是 O(1) 。k 个 key 经过
hash(key) % size对应唯一下标,那么在 get 这 k 个 key 的时间复杂度是 O(k) 。在情况 2 的极端情况下,k 恰好等于 N ,那么是不是就出现我们在上面说的 O(N) 的时间复杂度的情况。
所以,为了解决最差 O(N) 的时间复杂度的情况,我们可以将数组的每个元素对应成其它数据结构,例如说:1)红黑树;2)跳表。它们两者的时间复杂度是 O(logN) ,这样 O(N) 就可以缓解成 O(logN) 的时间复杂度。
红黑树通过自身的左旋或者是右旋来防止退化成链表,是相对复杂的数据结构,所以本文关于 HashMap 红黑树部分的源码不会进行太多的分析(主要是我也不会)另外,跳表是我们一定要掌握甚至必须能够手写代码的数据结构,在 Redis Zset 数据结果,就采用了改造过的跳表 实现起来相对于红黑树简单 却有相同的时间复杂度。
在 JDK7 的版本中,HashMap 采用“数组 + 链表”的形式实现。
在 JDK8 开始的版本,HashMap 采用“数组 + 链表 + 红黑树”的形式实现,在空间和时间复杂度中做取舍。
这一点和 Redis 是相似的,即使是一个数据结构,可能内部采用多种数据结构,混合实现,为了平衡空间和时间复杂度。毕竟,时间不是唯一的因素,我们还需要考虑内存的情况,也就是时间和空间的平衡考量。
HashMap:属性其中比较重要的就是四个:
table、size、threshold、loadFactor四个属性。
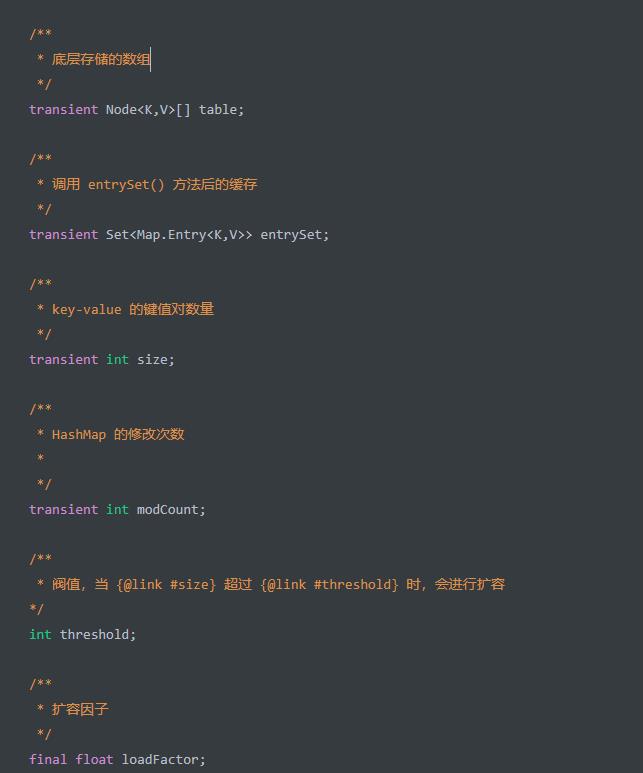
首先看看table 中的Node 中的属性:
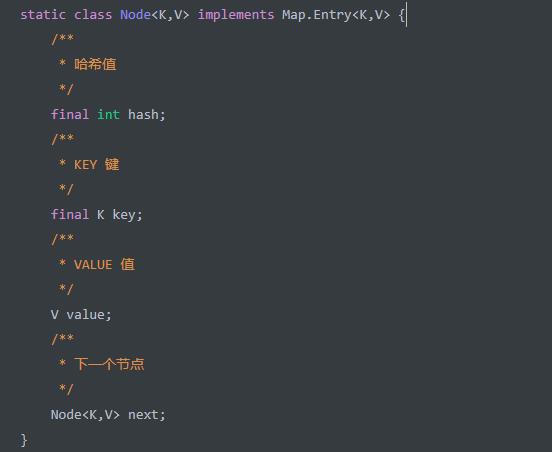
实现了 Map.Entry 接口,该接口定义在
java.util.Map接口中。hash+key+value属性,定义了 Node 节点的 3 个重要属性。next属性,指向下一个节点。通过它可以实现table数组的每一个位置可以形成链表。
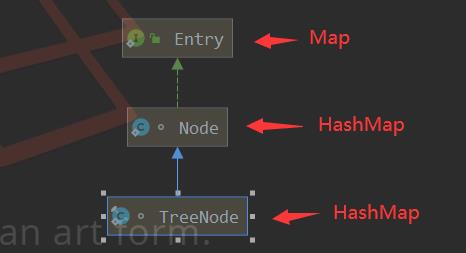
TreeNode ,定义在 HashMap 中,红黑树节点。通过它可以实现 table 数组的每一个位置可以形成红黑树
构造方法
HashMap 一共有四个构造方法,我们分别来看看:
HashMap() 构造方法,创建一个初始化容量为 16 的 HashMap 对象。代码如下:
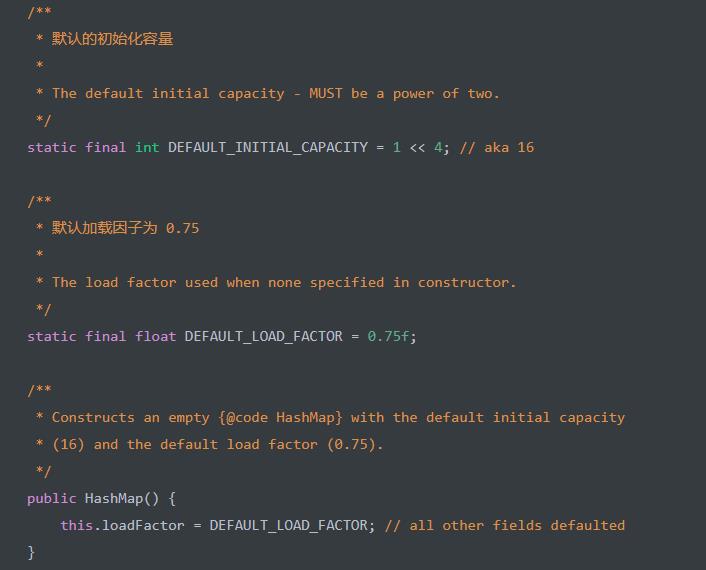
初始化
loadFactor为DEFAULT_LOAD_FACTOR = 0.75。在该构造方法上,我们并没有看到
table数组的初始化。它是延迟初始化,在我们开始往 HashMap 中添加 key-value 键值对时,在resize()方法中才真正初始化
HashMap(int initialCapacity) 方法,初始化容量为 initialCapacity 的 HashMap 对象。代码如下:

内部调用 #HashMap(int initialCapacity, float loadFactor) 构造方法 所以我们直接看第三个构造方法:
HashMap(int initialCapacity, float loadFactor) 构造方法,初始化容量为 initialCapacity 、加载因子为 loadFactor 的 HashMap 对象。代码如下:
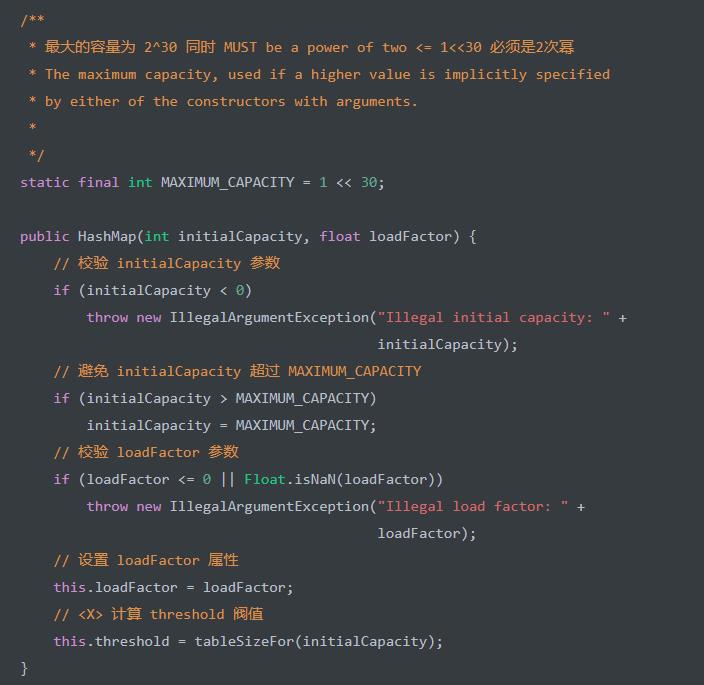
<X> 处,调用 tableSizeFor(int cap) 方法,返回大于 cap 的最小 2 的 N 次方 是一个经典的方式,也就是所,cap = 10 时返回 16 ,cap = 28 时返回 32 。代码如下:
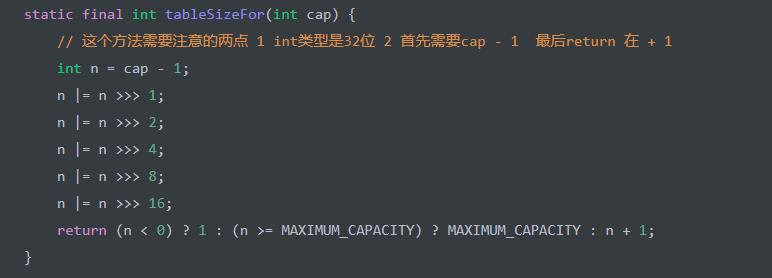
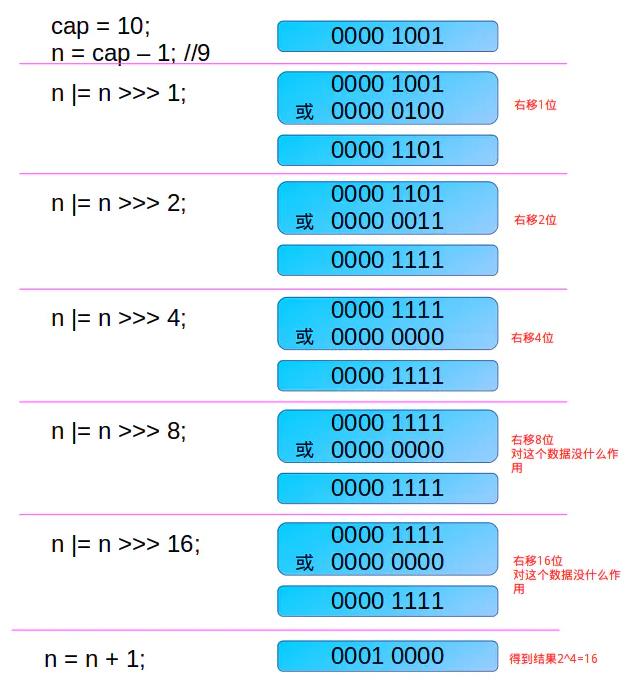
这里解释注释中的两点:
int类型是32位,可能会觉得是一句废话,但是却是这个算法的关键所在,该算法让最高位的1后面的位全变为1,int是32位,所以>>>16便能满足
cap-1再赋值给n的目的是另找到的目标值大于或等于原值。例如二进制1000,十进制数值为8。如果不对它减1而直接操作,将得到答案10000,即16,结果错误。减1后二进制为111,再进行操作则会得到原来的数值1000,即8
HashMap(Map<? extends K, ? extends V> m) 构造方法,创建 HashMap 对象,并将 c 集合添加到其中。代码如下:
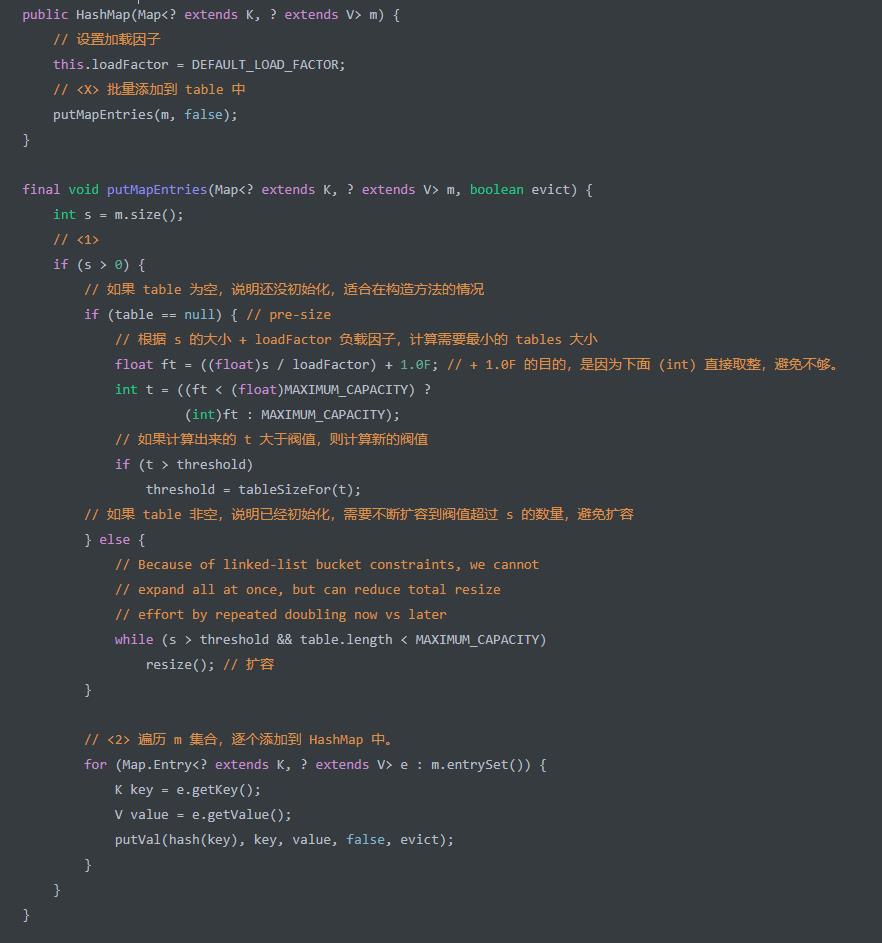
<1>处,保证table容量足够,分成了table是否为空有不同的处理。table为空那么此时table未初始化,我们只需要保证threshold大于数组大小即可,在 put key-value 键值的时候,在去真正的初始化table就好咧。<2>处,遍历m集合,逐个调用putVal(hash, key, val, onlyIfAbsent, evict)方法,添加到 HashMap 中。关于这块的逻辑,我们本文的后面再来详细解析
哈希函数
对于哈希函数来说,有两个方面特别重要:
性能足够高。因为基本 HashMap 所有的操作,都需要用到哈希函数。
对于计算出来的哈希值足够离散,保证哈希冲突的概率更小。
在 HashMap 中,hash(Object key) 静态方法,计算 key 的哈希值。代码如下:
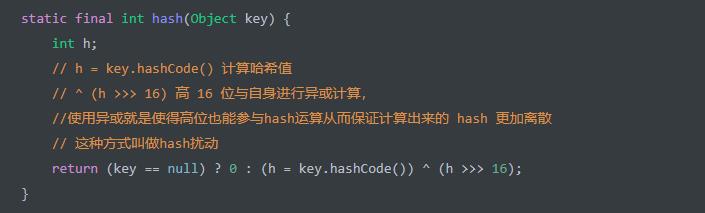
高效性:从整个计算过程上来说,
^ (h >>> 16)只有这一块的逻辑,两个位操作,性能肯定是有保障的。那么,如果想要保证哈希函数的高效性,就需要传入的key自身的hashCode()方法的高效即可。离散型:这里hash函数还没有确定在table中的index在面会详细的解释。
添加单个元素
put(K key, V value) 方法,添加单个元素。内部调用的是 putVal 方法,也是HashMap中最重要出题频率最高的方法,代码如下:
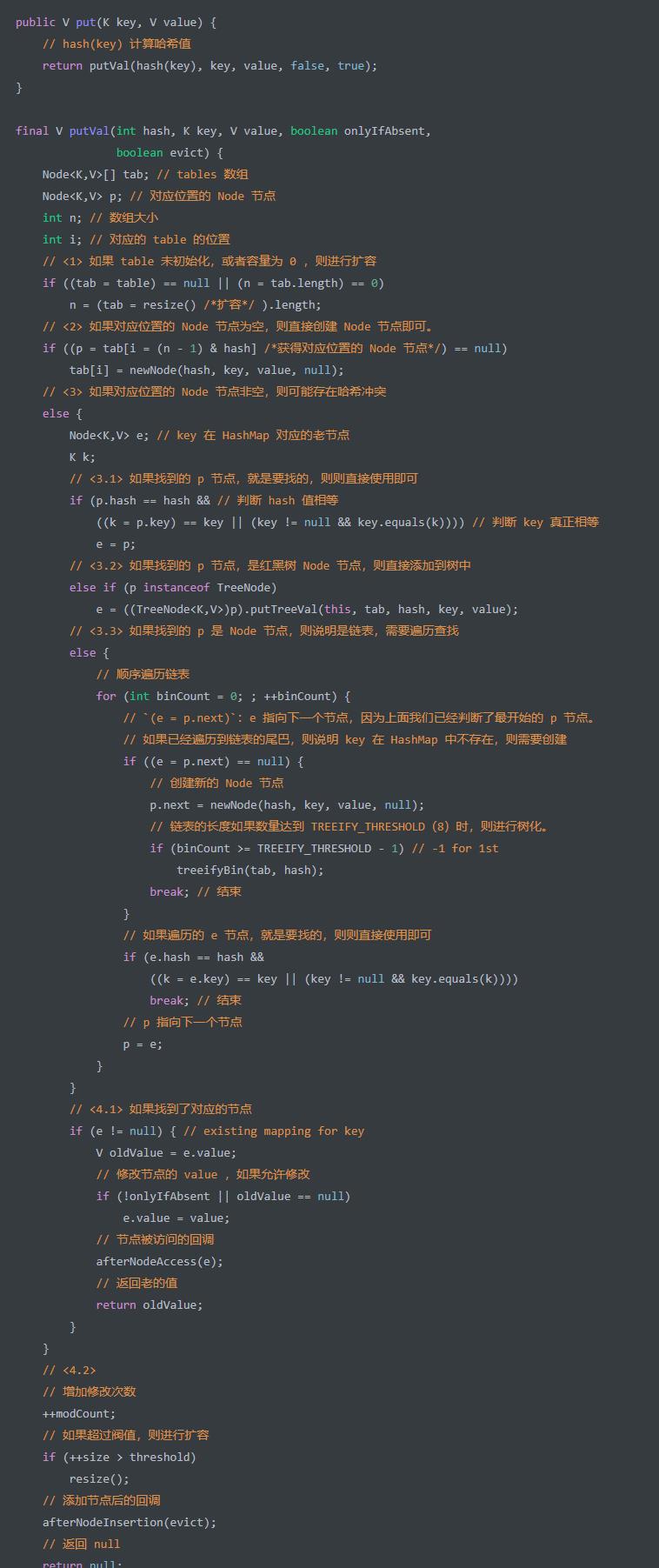
<1>处,如果table未初始化,或者容量为 0 ,则调用resize()方法,进行扩容 说是扩容其实就是初始化(懒加载)<2>处,如果对应位置的 Node 节点为空,则直接创建 Node 节点即可。这样,一个新的链表就出现了。当然,此处的
next肯定是null。i = (n - 1) & hash代码段,计算table所在对应位置的下标,这里才是为什么要使用hash扰动的原因调用
newNode(int hash, K key, V value, Node<K,V> next)方法,创建 Node 节点即可。<3>处,如果对应位置的 Node 节点非空,则可能存在哈希冲突。需要分成 Node 节点是链表(<3.3>),还是红黑树(<3.2>)的情况。<3.1>处,如果找到的p节点,就是要找的,则则直接使用即可。这是一个优化操作,无论 Node 节点是链表还是红黑树。<3.2>处,如果找到的p节点,是红黑树 Node 节点,则调用TreeNode#putTreeVal(HashMap<K,V> map, Node<K,V>[] tab, int h, K k, V v)方法,直接添加到树中。<3.3>处,如果找到的p是 Node 节点,则说明是链表,需要遍历查找。比较简单。其中,binCount >= TREEIFY_THRESHOLD - 1代码段,在链表的长度超过TREEIFY_THRESHOLD = 8的时候,会调用treeifyBin(Node<K,V>[] tab, int hash)方法,将链表进行树化。当然,树化还有一个条件,即(n = tab.length) >= MIN_TREEIFY_CAPACITY 也就是64<4>处,根据是否在 HashMap 中已经存在 key 对应的节点,有不同的处理<4.1>处,如果存在的情况,会有如下处理:
如果满足需要修改节点,则进行修改。
如果节点被访问时,调用
afterNodeAccess((Node<K,V> p)方法,节点被访问的回调。目前这是个一个空方法,用于 HashMap 的子类 LinkedHashMap 需要做的拓展逻辑。返回老的值。
<4.2>处,如果不存在的情况,会有如下处理:
增加修改次数。
增加 key-value 键值对
size数。并且size如果超过阀值,则调用resize()方法,进行扩容。调用
afterNodeInsertion(boolean evict)方法,添加节点后的回调。目前这是个一个空方法,用于 HashMap 的子类 LinkedHashMap 需要做的拓展逻辑。返回
null,因为老值不存在

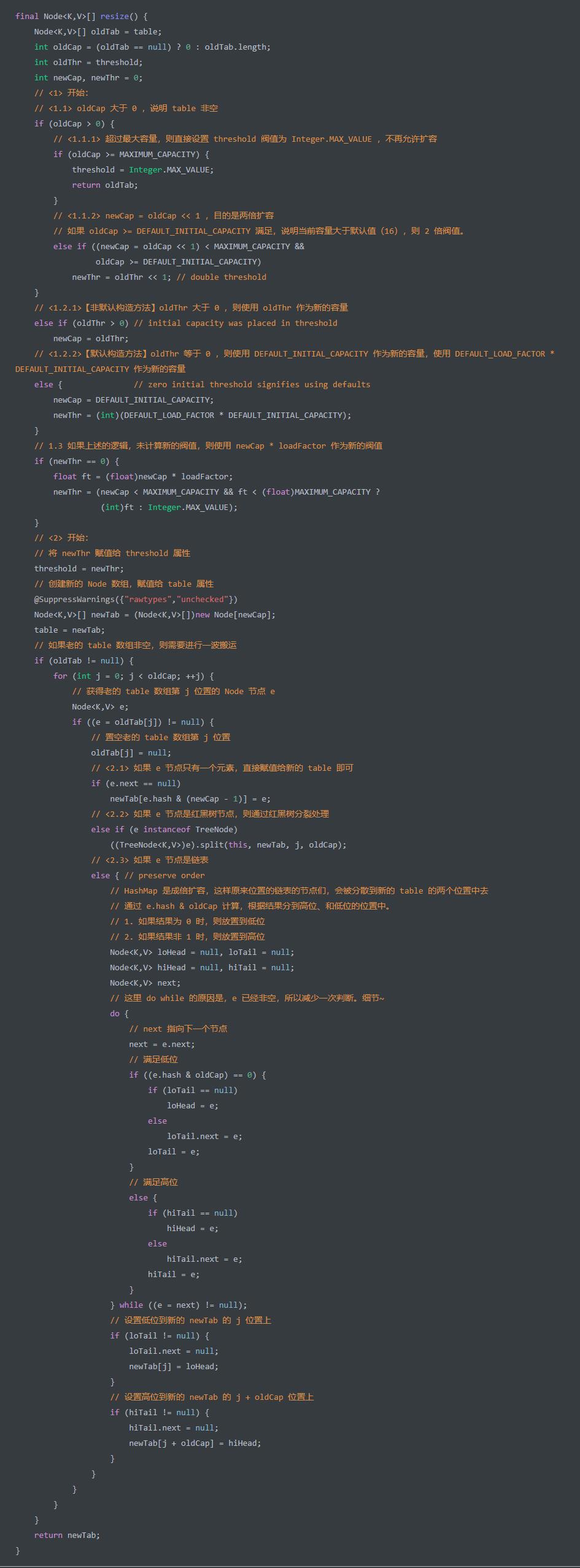
扩容
resize() 方法,两倍扩容 HashMap 。实际上,我们在 「4. 构造方法」 中,看到 table 数组并未初始化,它是在 resize() 方法中进行初始化,所以这是该方法的另外一个作用:初始化数组。代码如下:
链表转成树
treeifyBin(Node<K,V>[] tab, int hash) 方法,将 hash 对应 table 位置的链表,转换成红黑树。代码如下:
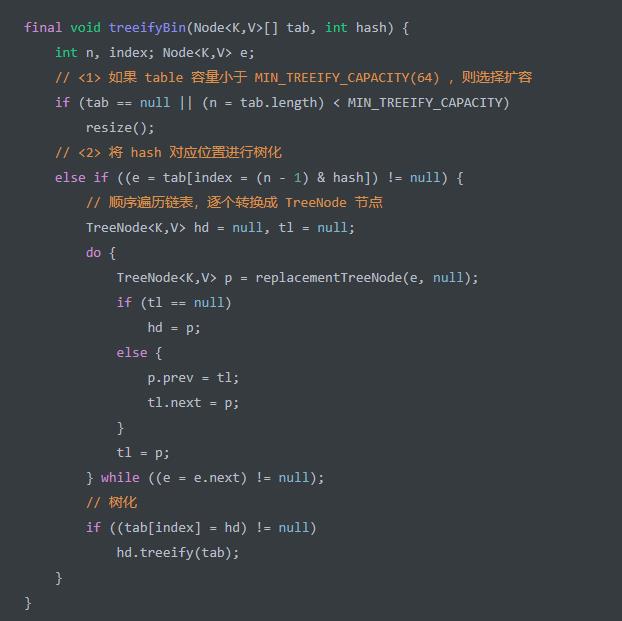
想要链表长度大于等于 TREEIFY_THRESHOLD = 8 。那么可能胖友会疑惑,为什么是 8 呢?
首先,参考 泊松概率函数(Poisson distribution) ,当链表长度到达 8 的概率是 0.00000006 ,不到千万分之一。所以绝大多数情况下,在 hash 算法正常的时,不太会出现链表转红黑树的情况。
其次,TreeNode 相比普通的 Node 来说,会有两倍的空间占用。并且在长度比较小的情况下,红黑树的查找性能和链表是差别不大的,但是空间占用的较大,所以没有一开始就是用红黑树节点。
HashMap 是 JDK 提供的基础数据结构,必须在空间和时间做抉择。所以,选择链表是空间复杂度优先,选择红黑树是时间复杂度优化。在绝大多数情况下,不会出现需要红黑树的情况。
有树化,必然有取消树化。当 HashMap 因为移除 key 时,导致对应
table位置的红黑树的内部节点数小于等于UNTREEIFY_THRESHOLD = 6时,则将红黑树退化成链表 使用6就是为了防止过于频繁的链表和红黑树的转换。
添加多个元素
putAll(Map<? extends K, ? extends V> m) 方法,添加多个元素到 HashMap 中,和HashMap(Map<? extends K, ? extends V> m) 构造方法一样,都调用 #putMapEntries(Map<? extends K, ? extends V> m, boolean evict) 方法,代码如下:

移除单个元素
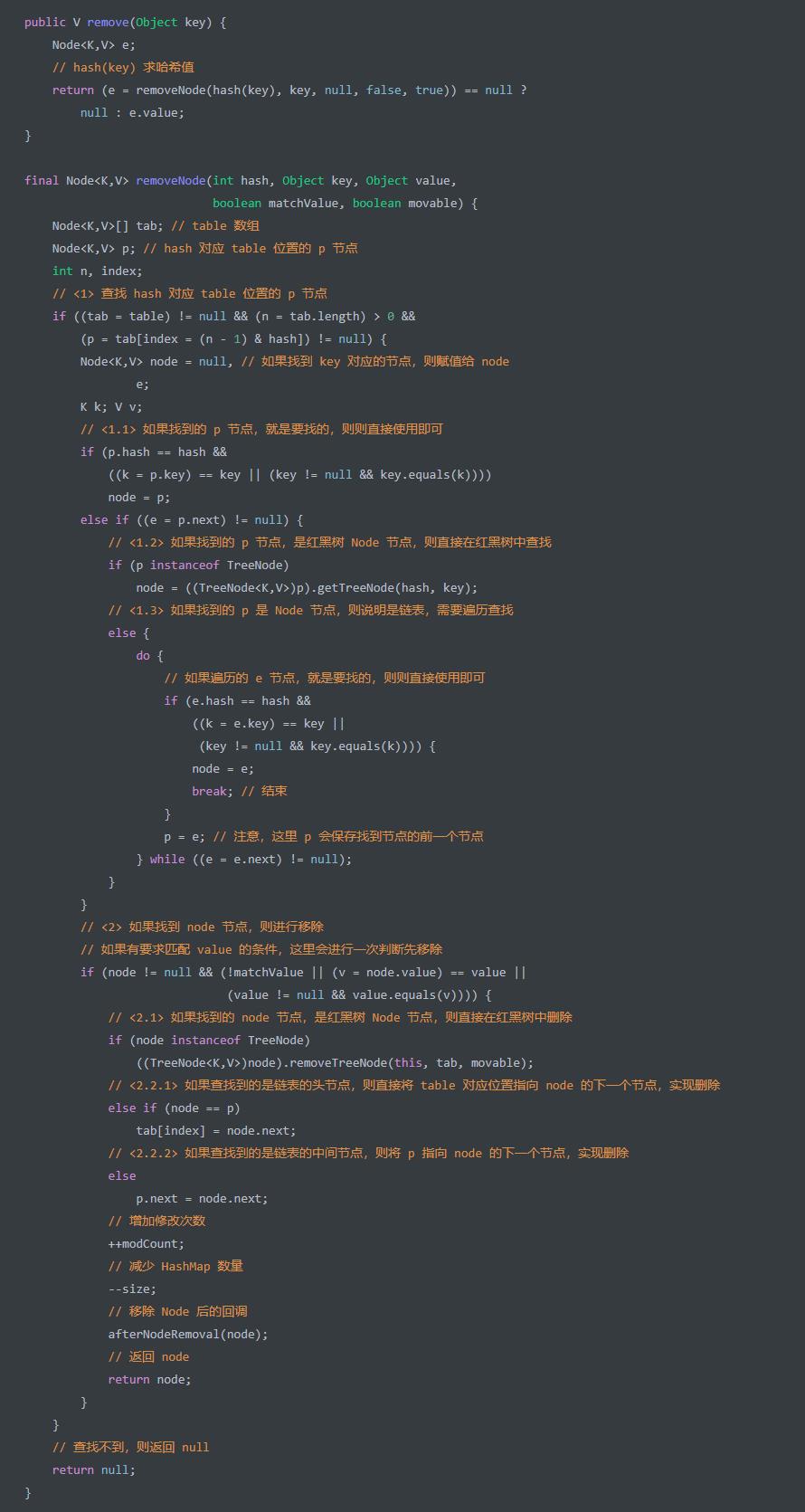
remove(Object key) 方法,移除 key 对应的 value ,并返回该 value ,移除的代码流程是和put时候几乎相同的,代码如下:
查找单个元素
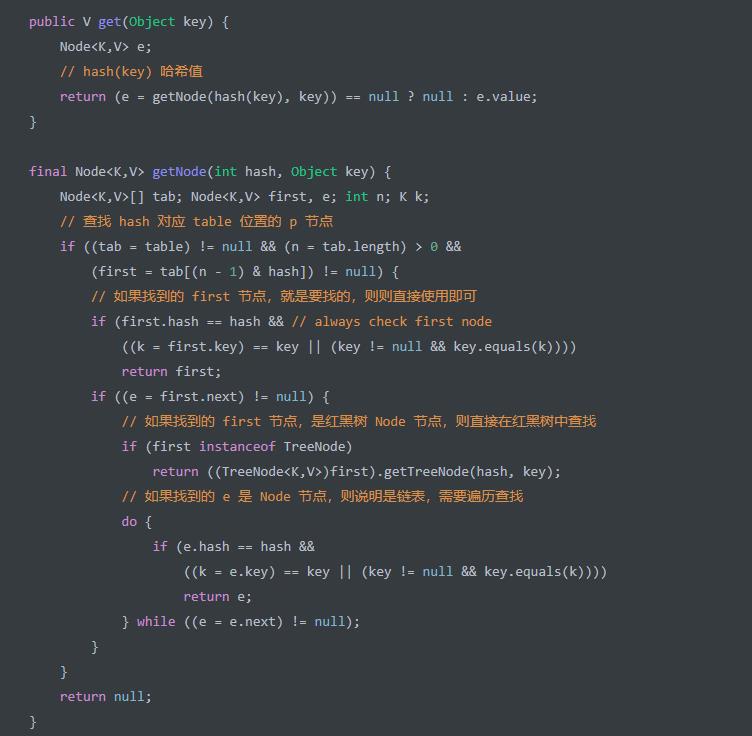
get(Object key) 方法,查找单个元素。代码如下
转换成数组
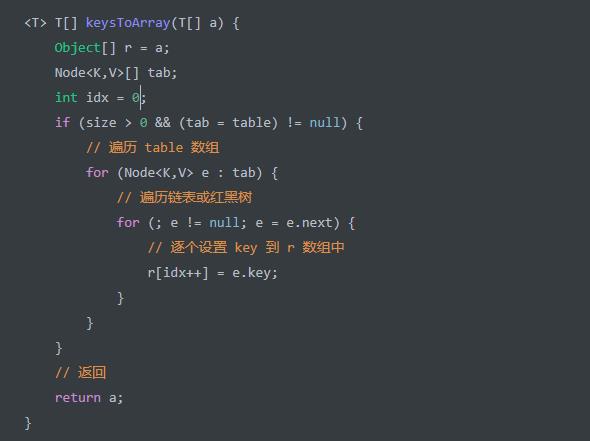
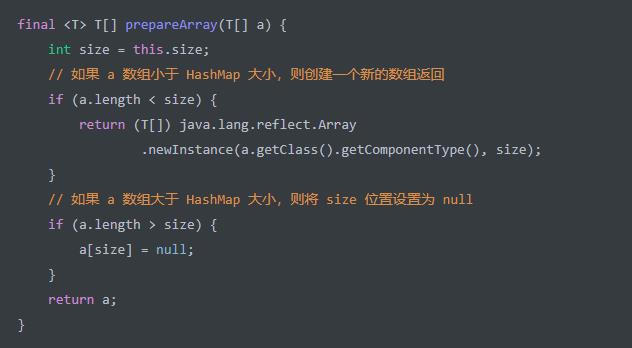
keysToArray(T[] a) 方法,转换出 key 数组返回。代码如下:
如果 a 数组的大小不够放下 HashMap 的所有 key 怎么办?答案是可以通过 prepareArray(T[] a) 方法来保证。代码如下:
清空
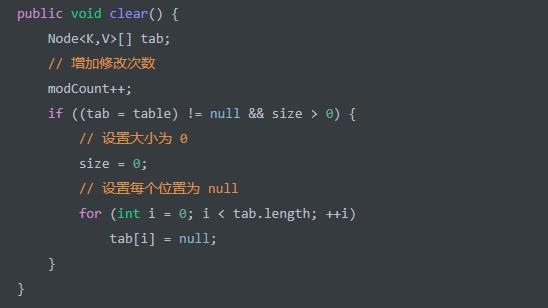
clear() 方法,清空 HashMap 。代码如下:
HashMap 做一个简单的小结:
HashMap 是一种散列表的数据结构,底层采用数组 + 链表 + 红黑树来实现存储。
Redis Hash 数据结构,采用数组 + 链表实现。
Redis Zset 数据结构,采用跳表实现。
因为红黑树实现起来相对复杂,我们自己在实现 HashMap 可以考虑采用数组 + 链表 + 跳表来实现存储。
HashMap 默认容量为 16(
1 << 4),每次超过阀值时,按照两倍大小进行自动扩容,所以容量总是 2^N 次方。并且,底层的table数组是延迟初始化,在首次添加 key-value 键值对才进行初始化。HashMap 默认加载因子是 0.75 ,如果我们已知 HashMap 的大小,需要正确设置容量和加载因子。
HashMap 每个槽位在满足如下两个条件时,可以进行树化成红黑树,避免槽位是链表数据结构时,链表过长,导致查找性能过慢。
条件一,HashMap 的
table数组大于等于 64条件二,槽位链表长度大于等于 8 时。选择 8 作为阀值的原因是,参考 泊松概率函数(Poisson distribution) ,概率不足千万分之一
在槽位的红黑树的节点数量小于等于 6 时,会退化回链表。
HashMap 的查找和添加 key-value 键值对的
平均时间复杂度为 O(1) 。
对于槽位是链表的节点,平均时间复杂度为 O(n) 。其中 n 为链表长度。
对于槽位是红黑树的节点,平均时间复杂度为 O(logn) 。其中n 为红黑树节点数量。
HashSet 源码分析

以上是关于JDK 源码解析 — 集合HashMap的主要内容,如果未能解决你的问题,请参考以下文章