第一个国人主导的开源项目——Apache Kylin成长之路
Posted IT大咖说
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第一个国人主导的开源项目——Apache Kylin成长之路相关的知识,希望对你有一定的参考价值。

内容来源:2017 年 11 月 18 日,Kyligence高级架构师史少锋在“2017中国开源年会 China Open Source Conference 2017”进行《Apache Kylin成长之路》演讲分享。IT 大咖说(微信id:itdakashuo)作为独家视频合作方,经主办方和讲者审阅授权发布。
阅读字数:2003 | 6分钟阅读
摘要
从第一个由国人主导并贡献到Apache基金会的开源项目,到今天得到国内外众多公司使用,Apache Kylin一路走来遇到过不少困难,也得到许多人的支持和帮助,本次演讲将带领大家一起来了解其中的心路历程。
嘉宾演讲视频及PPT回顾:http://suo.im/4AnKOA
什么是Apache Kylin
Kylin诞生于ebay,是完全由ebay上海的开发人员开发和贡献的项目,也是国内较早加入Apache的。所属大数据生态项目,主要解决在海量数据上查询难的问题。之所以诞生在ebay是因为ebay有海量的数据并且有迫切的分析需求。目前国内较大的互联网厂商基本上都在用Kylin,同时kylin也慢慢的向制造业、金融业渗透。

Kylin本质上是连接业务分析和底层Hadoop平台的引擎,下层调用的是Hadoop的分布式计算能力,上层使用标准SQL接口,Kylin会接收BI工具生成的SQL,并将它转换成对分布式集群的调用。
Kylin集成了Hadoop上的一些主流技术,比如HDFS、Hive、HBase等。
Kylin是唯一在Hadoop上做查询预计算的开源项目,其他SQL on Hadoop项目都是通过一定索引或集群并发将任务转换成现算获取结果,但是当数据量达到一定峰值时线算总会遇到瓶颈,因此我们借鉴了传统数仓领域的预计算技术并将它移植到Kylin上。
Kylin有着两大特性,其一是超高性能,能够在万亿条数据上达到亚秒级查询响应 ,以今日头条为例,它单个Cube有3万亿数据,90% 的查询都能在1秒以内完成。其二是高并发,能够在海量数据上支撑高并发量查询,美团点评每日130万次查询,99% 查询都能在1秒内完成。
Kylin的架构和核心
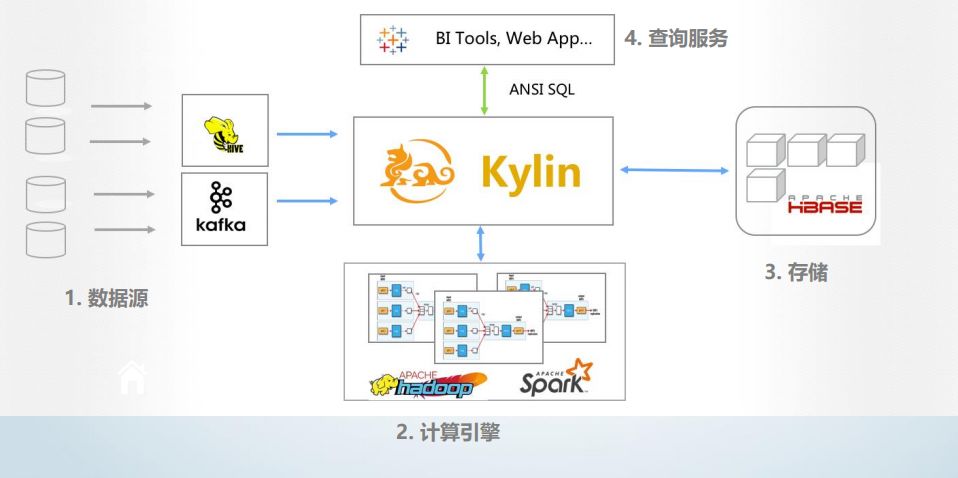
批数据(Hive)和流数据(Kafka)是Kylin主要支持的数据源,通过这两个数据源Kylin可以抽取出海量的数据。接下来会由MapReduce或Spark根据建立的模型并发地对数据进行预先的计算处理编码。 最后计算好的cube会被存储在HBase里,但是Kylin对外暴露的依旧是SQL接口,使用时会将SQL转换成HBasede查询,同时将预计算的逻辑下压到HBase中,从而基于预计算的结果再次后计算。
Kylin的核心理论是Cube理论,了解数据仓库理论的人应该都知道Cube是其中非常核心的部分。Cube其实是个数据立方体,三维的立方体有长宽高三个因素,通过它们能够定位到数据格进而快速获取数据。在线分析领域往往会按照维度去分析特定指标,这样就可以基于维度建立多维的向量空间,查询时只需要根据查询维度或过滤条件就能直接定位到预计算处理的结果。
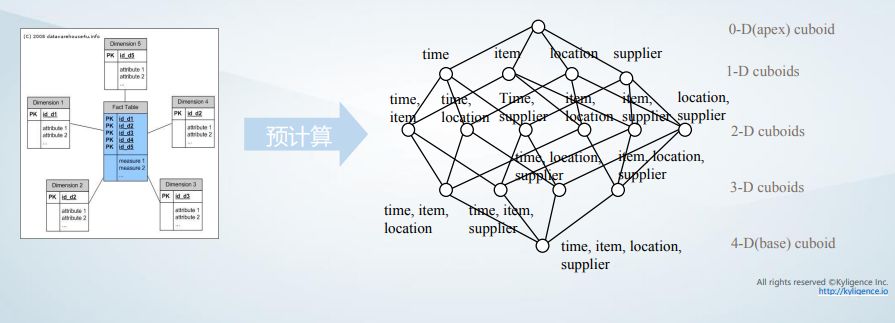
Kylin会将多维的数据模型打平继而转换成多维Cube,根据需求会对多种维度组合进行计算。Cube可以让查询相比以前快很多倍,一般的SQL查询随着数据量的增长计算量和查询时间也会增长。
计算Cube时会预先对表做join以及聚合,再转换成Cube。Cube内由众多Cuboid组成,这些Cuboid不仅有聚合的结果还有每个维度的索引。最终原先的SQL执行流程被转换成Cube的执行计划,以Cube为起点根据条件进行过滤以及少量排序。由于Cube中数据已经被压缩,所以查询时响应会非常迅速,这时数据量的规模已无关紧要,更重要的是数据模型的复杂度,而一般业务的模型复杂度是基本不变的。
Kylin的重要里程碑
2014年10月的Kylin第一个版本还是比较简陋粗糙的,1.0版本时兼容性有了很大提高,基本上用户解压后就能运行起来。后来的1.5版本有了新的sharded存储引擎和新的inmem cubing算法,带来了2倍以上性能提升,随后的1.6又加入了对消费流数据的支持,检索时间得以大幅缩减。
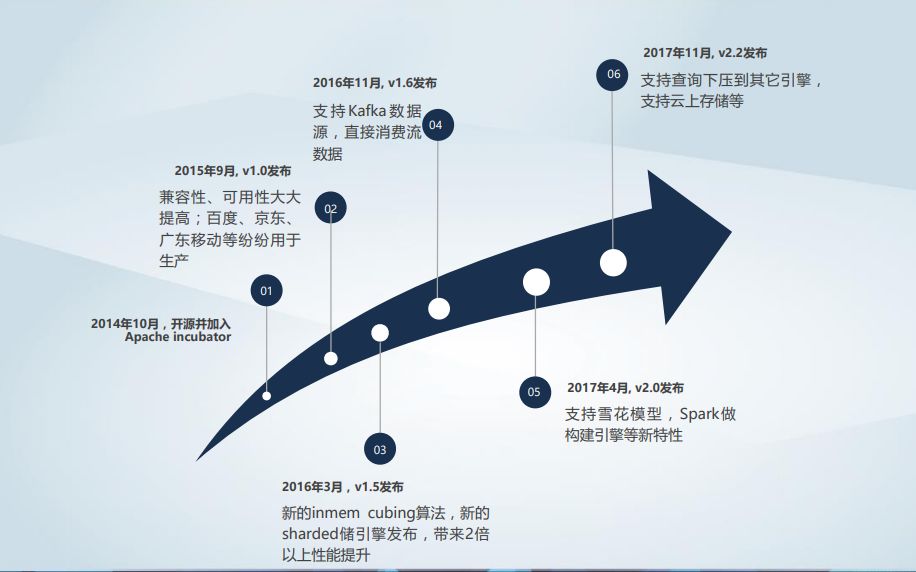
作为大版本的2.0主要的变化是支持了雪花模型,另外可以利用spark来构建Cube,使得构建时间再减少二分之一。现在的2.1版本进一步支持了查询下压,不仅能够使用Cube回答查询,在Cube不命中的时候还可以下压给Hive或Spark SQL来完成查询。
以上为今天的分享内容,谢谢大家!
相关推荐
推荐文章
近期活动
点击【阅读原文】回顾嘉宾演讲视频及PPT
以上是关于第一个国人主导的开源项目——Apache Kylin成长之路的主要内容,如果未能解决你的问题,请参考以下文章