剖析Apache HAWQ存储系统
Posted 大数据社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了剖析Apache HAWQ存储系统相关的知识,希望对你有一定的参考价值。
作为与计算并驾齐驱的重要成分,存储是设计一个数据库系统必须要考虑的问题,包括数据表数据文件的存放位置、数据文件自身的格式、数据压缩的方式等。另外,能否很好地与外部数据源交互也是衡量一个数据库可扩展性的重要评价指标。
本文即将介绍Apache HAWQ的存储部分,主要从HAWQ内置的文件组织方式及格式和与外部生态系统的数据交互两大方面进行展开。
HAWQ内置数据存储
总体而言,HAWQ的数据分为两部分:实际数据和元信息。元信息描述数据库相应对象的信息,比如表信息,表属性信息、表对应的存储文件等等。HAWQ内部表的存储类型包括以下三种。
Heap表 存放在postgres中。HAWQ的元信息均以Heap表的方式存储。
Row-Oriented行式存储 HAWQ自己提出的一种存储格式。元信息存放在HAWQ master上,实际数据存放在HDFS上。Row行存表将数据以block为单位逐次写出或者读入内存。
Parquet列式存储 Parquet是Hadoop生态系统开源的数据文件格式,被多种数据引擎支持,包括Hive、Impala、Storm等。Parquet同Row一样,元信息存储在HAWQ master上,实际数据存放在HDFS上。在Parquet表中,目前HAWQ支持的压缩方式包括Snappy和Gzip。Parquet表将数据以rowgroup为单位写出或者读入内存。如果只需要读取几列数据,仅会读出rowgroup中这几列对应的数据。
目前,以非utility模式连接HAWQ,只能创建Row和Parquet类型的表。因为HAWQ的用户场景是进行大规模数据分析,我们下面对Row行存和Parquet存储进行概要介绍。
建表语句
可以通过以下语句创建一张Parquet表。
create table test(a int, b varchar(20))with(appendonly=true, orientation=parquet, compresstype=gzip, compresslevel=8, rowgroupsize=8388608, pagesize=1048576);
创建Parquet表时,必须指定的两个参数为appendonly和orientation。下面为具体的参数描述。
appendonly 描述存储文件是否只支持append操作,不允许修改和删除。因为Row和Parquet表都是存储在HDFS上,所以建表时均需将appendonly参数置为true。
orientation 描述表的存储类型。可设置为row或者parquet。row表示行式存储,parquet表示列式存储。
compresstype 描述parquet文件存储时的压缩类型。
compresslevel 描述压缩的级别,只针对gzip压缩有效,范围为0-9,默认值为1。
rowgroupsize 描述Parquet文件中row group的大小,可配置范围为 [1KB,1GB) 默认为8MB。
pagesize 描述parquet文件中每一列对应的page大小,可配置范围为[1KB,1GB),默认为1MB。
表对应的元信息
成功建表后,在HAWQ的几张元信息表中会有相应的体现,包括pg_class, pg_attribute, pg_type, pg_appendonly, pg_aoseg.pg_paqseg_$relfilenode, gp_persistent_relation_node, gp_persistent_relfile_node等。
pg_class
pg_class元信息表描述了所有表的信息,每新建一张表都会在pg_class中添加一条关于该表的记录。主要字段包括oid描述表的id,relname描述表的名称,relfilenode描述表在HDFS文件系统中存储的文件id。
pg_appendonly
pg_appendonly描述appendonly表的信息,每新建一张Row或者Parquet表,都会在pg_appendonly表中插入一条记录。主要字段relid描述对应表在pg_class元信息表中的oid,blocksize描述Row表中每个block的大小或者Parquet表中每个rowgroup的大小,compresstype描述压缩类型,compresslevel描述压缩级别,columnstore字段描述是否为列存,pagesize描述Parquet表对应的列的page大小。

在pg_appendonly表中值得注意的是segrelid字段,在新建一张Row或者Parquet表时,同时会在pg_aoseg 命名空间下建立一张新的元信息表,用来描述该表每个文件的相应信息,segrelid描述的即是新建的元信息表在pg_class中的oid。可以从pg_class中查找该表的相应信息。Parquet表对应的表名前缀时pg_paqseg_,Row行存表对应的表名前缀为pg_aoseg_。
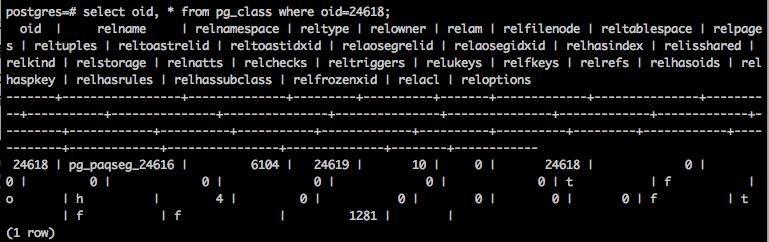
pg_aoseg.pg_paqseg_$relfilenode
pg_aoseg.pg_paqseg_$relfilenode 描述了parquet表对应的数据文件信息。主要字段segno描述文件的名字,eof描述文件在HAWQ系统里的有效长度,tupcount描述该文件包含的元组数,eofuncompressed描述文件中的数据压缩前的大小。如果建表时compresstype和compresslevel未设置,eof和eofuncompressed值应该相同。由于新建的Parquet表没有数据,所以该表为空。

执行insert操作的每个virtual segment会在HDFS上生成一个文件,并会将文件的信息以一条记录存储在该表中。由于执行insert操作时只有一个virtual segment,该表中只插入了一条记录。由于我们建表时指定了compresstype为gzip,compresslevel为8,该记录的eof和eofuncompressed值并不相同,压缩比率大约为9.36%。

gp_persistent_relation_node
gp_persistent_relation_node 描述需要持久化到HDFS存储的relation的元信息,用来进行catalog元信息和文件系统之间的同步。字段tablespace_oid描述relation对应的表空间的oid,database_oid描述relation对应的数据库的oid,relfilenode_oid描述该realtion对应存储目录的oid,persistent_state描述持久化的状态,值为2表示表已经在文件系统中创建成功。

gp_persistent_relfile_node
gp_persistent_relfile_node描述持久化到外地存储的relation文件的元信息。字段segment_file_num描述生成该文件的virtual segment的id,同时也作为文件的名字。

此外,创建表的同时也会向pg_attribute, pg_type等元信息表中加入相应的记录信息。因为行为与postgres相似,本文不再赘述。
定位表在HDFS上的文件
当我们创建表并插入数据后,如何去HDFS上查看对应的文件信息呢?可以遵循以下步骤:
HAWQ在HDFS上的数据是以目录 tablespace/database/table/segfile的方式组织的,给定表名,去pg_class里查到表的oid。
依据表的oid,查找元信息表gp_persistent_relation_node,得到tablespace_oid, database_oid。
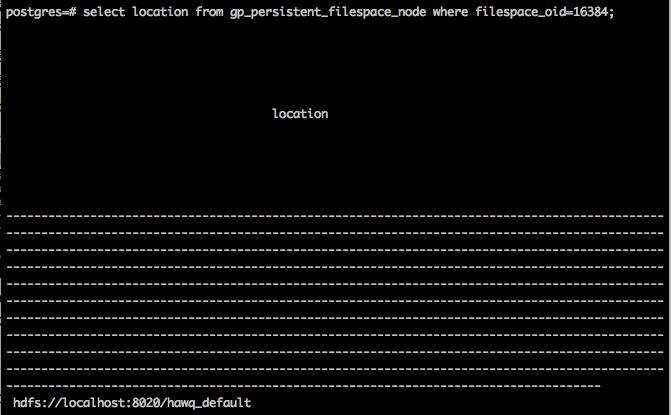
依据tablespace_oid,查找元信息表gp_persistent_tablespace_node,得到filespace_oid。此例为13684。
依据filespace_oid, 查找元信息表gp_persistent_filespace_node,得到location。此例为 "hdfs://localhost:8020/hawq_default"。此外,关于hdfs的url路径是在hawq-site.xml里配置的,配置项为 hawq_dfs_url,默认值为 localhost:8020/hawq_default 。所以也可以直接查阅hawq-site.xml得到location信息。
上述步骤1-4可以通过执行下面的sql命令得到相应的信息:
select location, gp_persistent_tablespace_node.
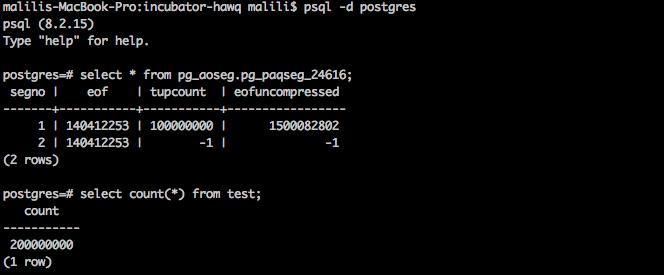
tablespace_oid, database_oid, relfilenode from pg_class, gp_persistent_relation_node, gp_persistent_tablespace_node, gp_persistent_filespace_node where relname = '$relname' and pg_class.relfilenode = gp_persistent_relation_node. relfilenode_oid and gp_persistent_relation_node. tablespace_oid = gp_persistent_tablespace_node. tablespace_oid and gp_persistent_filespace_node. filespace_oid = gp_persistent_filespace_node. filespace_oid; 依照前面的几项信息去HDFS上查看相应文件。我们可以看到test表对应的HDFS文件信息,大小为140412253,与pg_aoseg.pg_paqseg_24616中的eof字段相一致。

这里需要提及的一点是表在HDFS上的大小不一定与元信息表的eof时刻一致。如果我们在insert过程中进行了cancel操作,这时HDFS文件已经写了一部分脏数据,HAWQ在cancel的过程中并没有把已经写出的数据truncate掉。因为eof并没有更新,所以不影响后续的读操作。HAWQ会在下次执行insert操作的时候判断HDFS文件大小与eof是否一致,如果不一致,先truncate掉多余的数据,再进行插入。这样可以减少cancel操作的响应延迟。
HAWQ与外部生态系统数据交互
外部表
除了自带数据存储格式,HAWQ还提供了与外部数据系统交互的功能。通过创建外部表,HAWQ可以访问外部生态系统以及其它格式的数据,生态系统包括Hive、Hbase等,文件格式包括csv等。HAWQ在访问外部表时可依照多种协议,比如file,gpfdist,gphdfs,http以及pxf。
外部数据源注册到内部表
与创建外部表相比,如果能把外部数据源的文件直接注册到HAWQ内部表,这样就能直接应用HAWQ内部表的统计信息,性能会有更大的提升。HAWQ Register就是基于这一目的实现的。现有版本的HAWQ Register支持将Parquet文件注册到HAWQ内部表中。下面我们对其展开介绍。
语法
HAWQ Register的语法介绍可以通过运行hawq register help来获得。
hawq register [-h hostname] [-p port] [-U username] <databasename> <tablename> <hdfspath>
必须输入的参数databasename描述待注册的表所在数据库,tablename描述待注册的数据表名称,hdfspath描述待注册的文件路径。hostname、port和username为可选项,默认值为$PGHOST、$PGPORT和$PGUSER。
目前我们支持将HDFS上的文件或者文件夹注册到已经创建的HAWQ数据表中。对于其它存储介质的支持,会在后续版本中进行考虑。由于注册时采用的操作时将待注册的文件直接移动到HAWQ表的HDFS存储路径下,对于hash分布的表数据文件的个数事先已固定,因此现阶段的注册只支持对random分布表的注册。
实例
下图是使用Hawq Register的一个实例。将HDFS路径为 "hdfs://localhost:8020/tmpData"的文件注册到上文所建的test表中。这里需要注意的一点是,待注册的文件或文件夹必须与HAWQ在同一个HDFS集群上。

注册成功后,查看pg_aoseg.pg_paqseg_$relfilenode元信息表,我们看到元信息表中增加了一条记录,segno为2表示对应的文件名为2,eof即为我们待注册的文件的大小,tupcount和eofcuncompressed的填写我们会后期进行支持。因为我们注册的是一个文件,元信息表中增加了一条记录。如果注册的是一个文件夹,那么增加的记录数是该文件夹下的有效文件个数。
注册完毕后,test表可以继续作为普通的表使用。注册的文件就成为表的一个普通的存储文件,可以支持insert操作等,与HAWQ自身生成的文件并没有任何差异。
HAWQ数据类型到Parquet数据类型的映射
作为一个数据库,HAWQ支持的数据类型与Parquet所支持的数据类型不尽相同,因此在进行数据存储和读取时,需要有数据类型的映射。下表枚举出了HAWQ数据类型到Parquet数据类型的映射关系。
总结
本文从内置数据存储和与外部数据系统的交互两大方面介绍了HAWQ的存储系统。由于篇幅所限,有些内容没有详细展开。更多具体信息,可以参阅HAWQ的文档或者邮件我们进行询问。欢迎加入HAWQ开源项目!
文档: http://hdb.docs.pivotal.io/hdb20/index.html
邮件: dev@hawq.incubator.apache.org
JIRA: https://issues.apache.org/jira/browse/HAWQ
github: https://github.com/apache/incubator-hawq
更多精彩内容,请关注大数据社区公共账号!
长按识别图片二维码
以上是关于剖析Apache HAWQ存储系统的主要内容,如果未能解决你的问题,请参考以下文章