重温 Apache Kafka
Posted AI一大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重温 Apache Kafka相关的知识,希望对你有一定的参考价值。
1.核心概念
Kafka最初是由LinkedIn在2011年开发出来的,从那开始,Kafka逐渐发展成为一个完整的平台,允许你冗余存储难以置信的数据量,提供巨大吞吐量的消息总线(百万级/秒),以及对这些消息的实时流处理。
Kafka的核心可概括为:分布式(distributed)、水平扩展(horizontally-scalable)、容错性(fault-tolerant)、持久性日志(commit log)
分布式简单说,就是把运算处理分布到多个机器上,这些机器作为一个集群协同工作,而对终端用户而言,只是面对一个节点,而非一群机器。
水平扩展,简单说就是加多多的机器参与运算,对应的,垂直扩展,是指给一台服务器上加多多的内存 CPU和硬盘,对比来看,水平扩展是可以无限扩展的。
容错性是由分布式的特点决定的,一个5个节点的Kafka集群,即使2个节点down掉,仍然可以正常工作,另外提一句,容错和性能之间存在着一种平衡,你的系统容错性越高,越影响性能(性能越低)。
持久性日志,commit log,也可称之为 write-ahead log(预写日志) 或 transaction log(事务日志)。
从数据库的角度讲,write-ahead log 和 transaction log 的提法比较普遍,WAL机制即指Write-Ahead Logging,是实现事务日志的标准方法。WAL 的中心思想是先写日志,再写数据,数据文件的修改必须发生在这些修改已经记录在日志文件中之后。本质上,是防止数据库崩溃发生数据页不完整的情况。
Kafka的commit log,从机制上讲,与数据库的WAL机制相似,是一种防止节点崩溃的机制,不同的是,对于Kafka来说,需要确保的不是数据页,而是消息的完整,Kafka是一个基于副本的高可靠的消息系统,在消息可用前,Kafka保证消息已经提交到足够多的副本中。
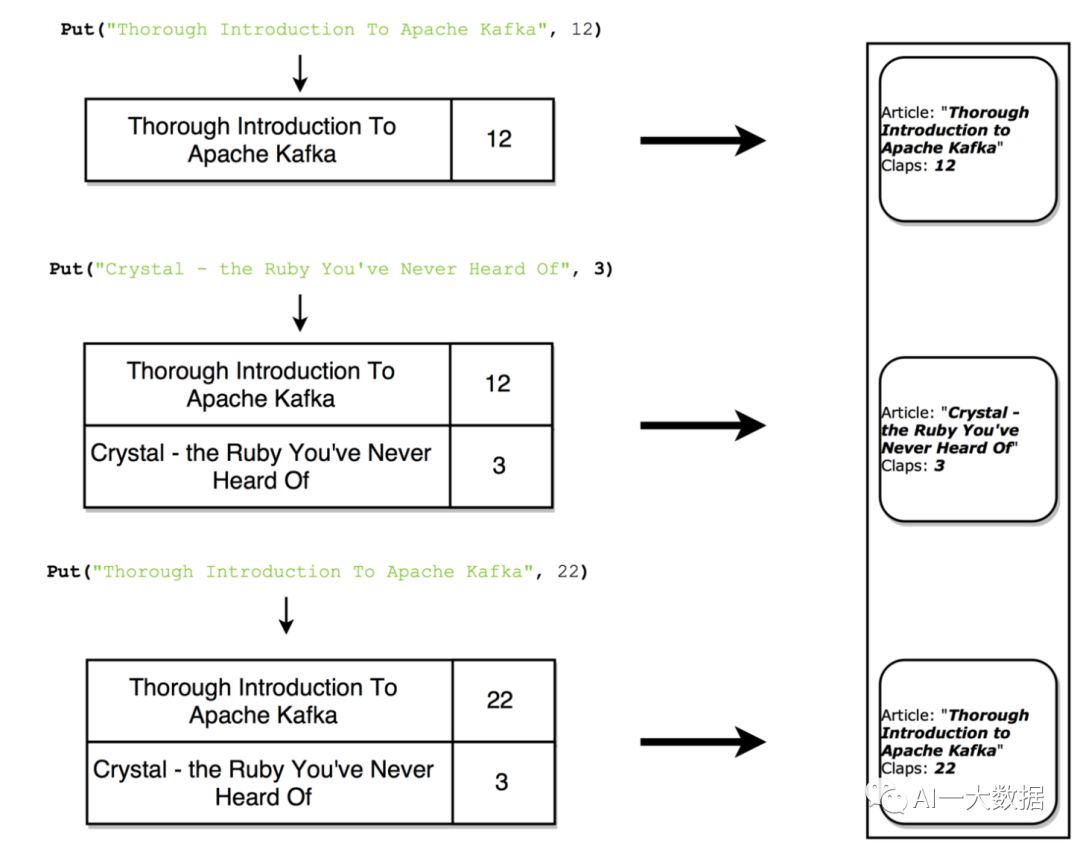
从数据上讲,commit log是指Kafka存储消息的文件,其数据结构式是固定顺序的一组记录(Record),Offset+MessageSize+Message构成日志中的每条记录,日志只支持append操作,且不允许修改和删除
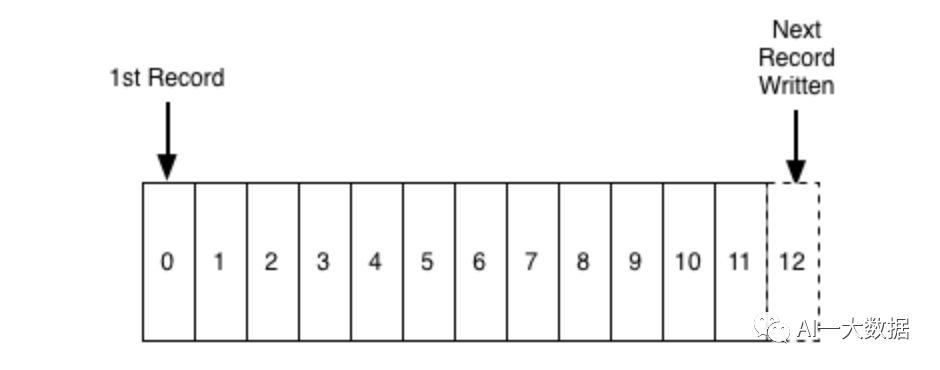
这样存储消息的特点是:读写操作都是O(1)的时间复杂度;读写操作互不干扰。其好处是带来巨大的性能提升,这是因为文件的大小跟文件的读写性能解耦,无论服务器上有100KB或者100TB的数据,Kafka的性能都不会受到影响。
2.工作方式
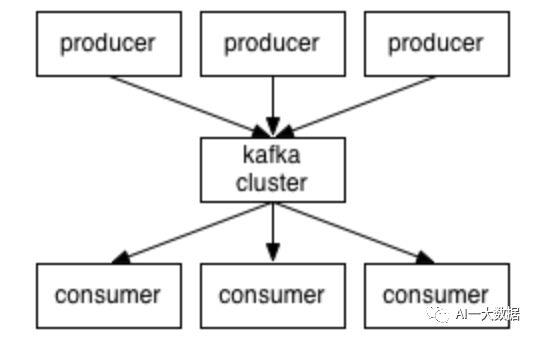
Kafka的工作流程可以解释为:“生产者(producer)”发送“消息(message)”到“broker(Kafka 节点)”,消息存储在某一个“topic(主题)”上,“消费者(consumer)”通过“订阅(subscript)”主题,收到消息并且进行处理。
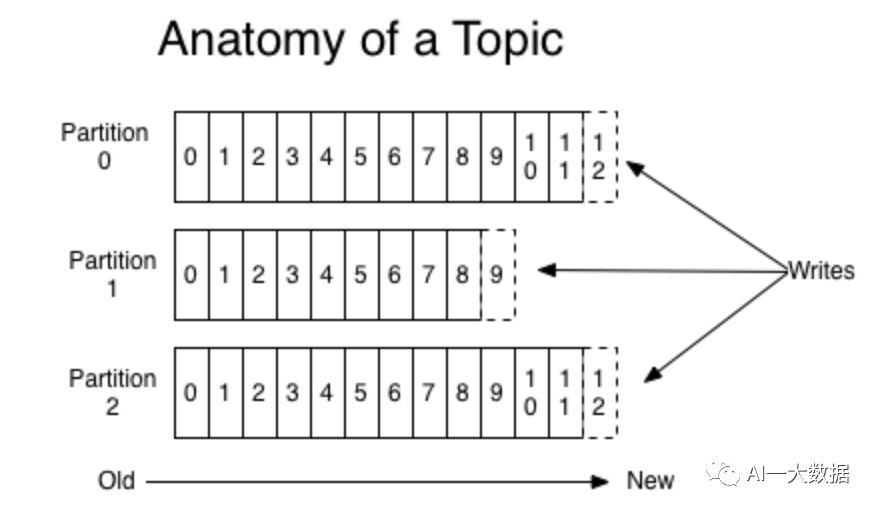
主题topic又分成多个分区(partition),这样可以提高性能和扩展性,消息最终是存储在topic的某一个分区里,每个分区,就是一个commit log 文件,前面说过,日志记录(Record)=Offset+MessageSize+Message
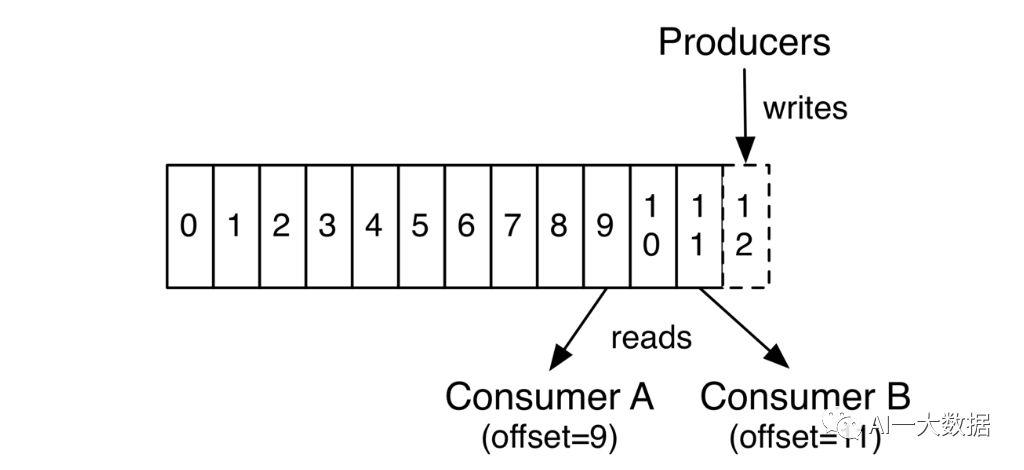
Kafka奉行哑的broker和聪明的consumer的原则,就是说,Kafka不会理会消息是否被消费了,而进一步去决定是否删除消息(一般的消息中间件是处理方式是:消息被消费即删除),Kafka会一直保存消息直到达到某个时间段、或某个上限值,而Kafka留给每个consumer中的唯一的元数据就是Offset,因此consumer可以通过控制offset,多次读取并处理相同的消息。
需要明确的是,comsumer消费者,在Kafka中实际上指的是comsumer groups,消费者组,每个消费者组中包含一个或多个消费者进程或者消费者线程,消费者进程或者消费者线程统一称为消费者实例-consumer instance。消费者实例可以分散到不同机器上。
换个说法,即consumer接收消息,是按照group来接收的,即去订阅主题的是consumer group 而不是单个的消费者实例,并且同一个group中只有一个消费者实例可以消费消息,Kafka提供负载均衡机制在各个消费者实例间分发消息,如下图,Consumer Group A 和 B都订阅了同一个主题,Group A中两个消费者实例,每个消费掉2个消息,而Group B中的四个消费者实例,每个消费一个。
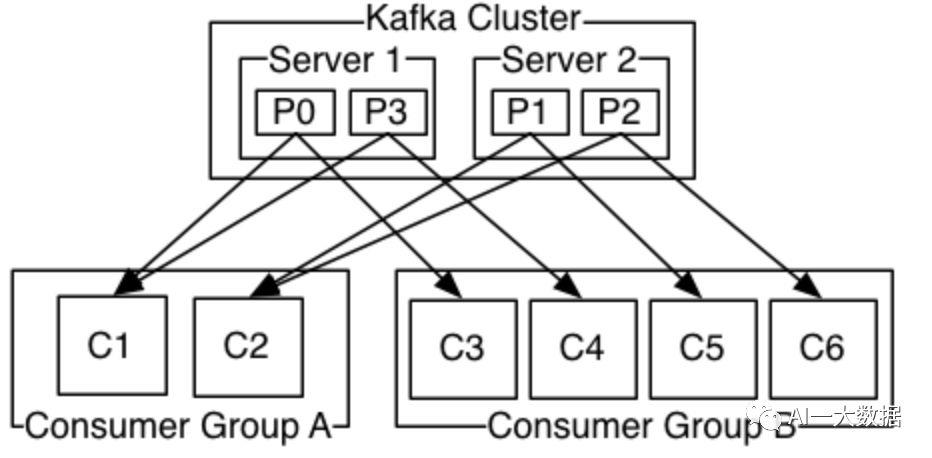
从消息中间件MQ的规范讲,比如传统的JMS规范,消息处理需要支持两种模式:点对点模式和发布订阅模式,点对点模式即每个消息只能有一个消费者消费,多个消费者监听一个消息队列时,处于一种争抢方式,被消费的消息随即删除;发布订阅模式即多个消费者订阅一个主题,消息生产者向主题发送消息,则每个消费者都可以收到消息。
通过Kafka的consumer group的概念,可以实现传统消息的两种模式,同一consumer group中的消费者实例,处于点对点模式之中;而多个consumer group订阅同一个主题,则各个consumer group处于发布订阅模式之中。
3.数据分发与复制
主题Topic的分区数据在Kafka集群的不同节点上保留副本,至于保留多少个副本,可以通过配置文件配置。
副本是怎么分发到各个节点的呢,这里需要引入分区leader和follower的概念:分区leader是生产者和消费者写入和读取数据的地方,当生产者发送消息到分区leader时,leader把消息副本分发给其他节点,这些节点可称为follower
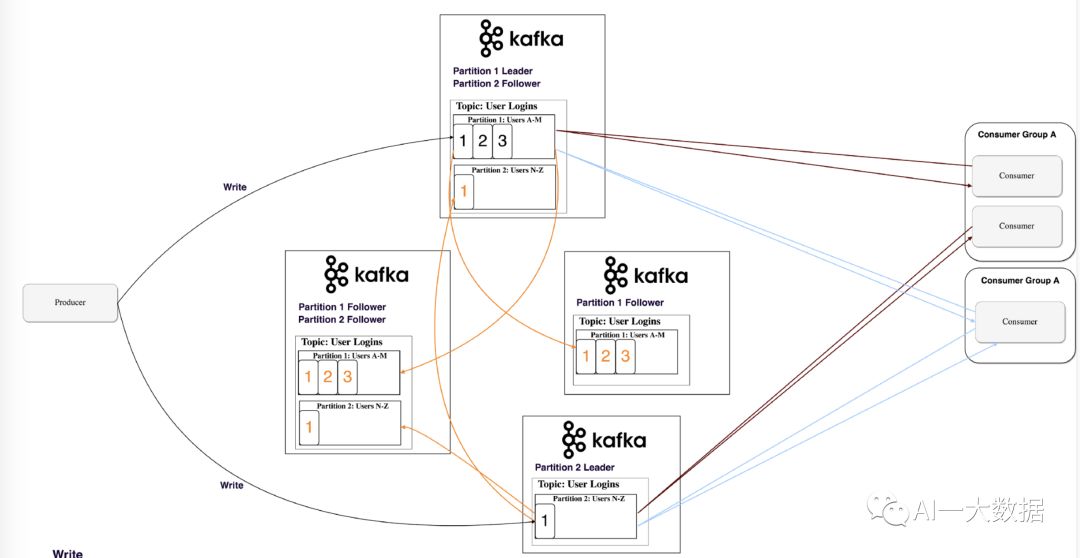
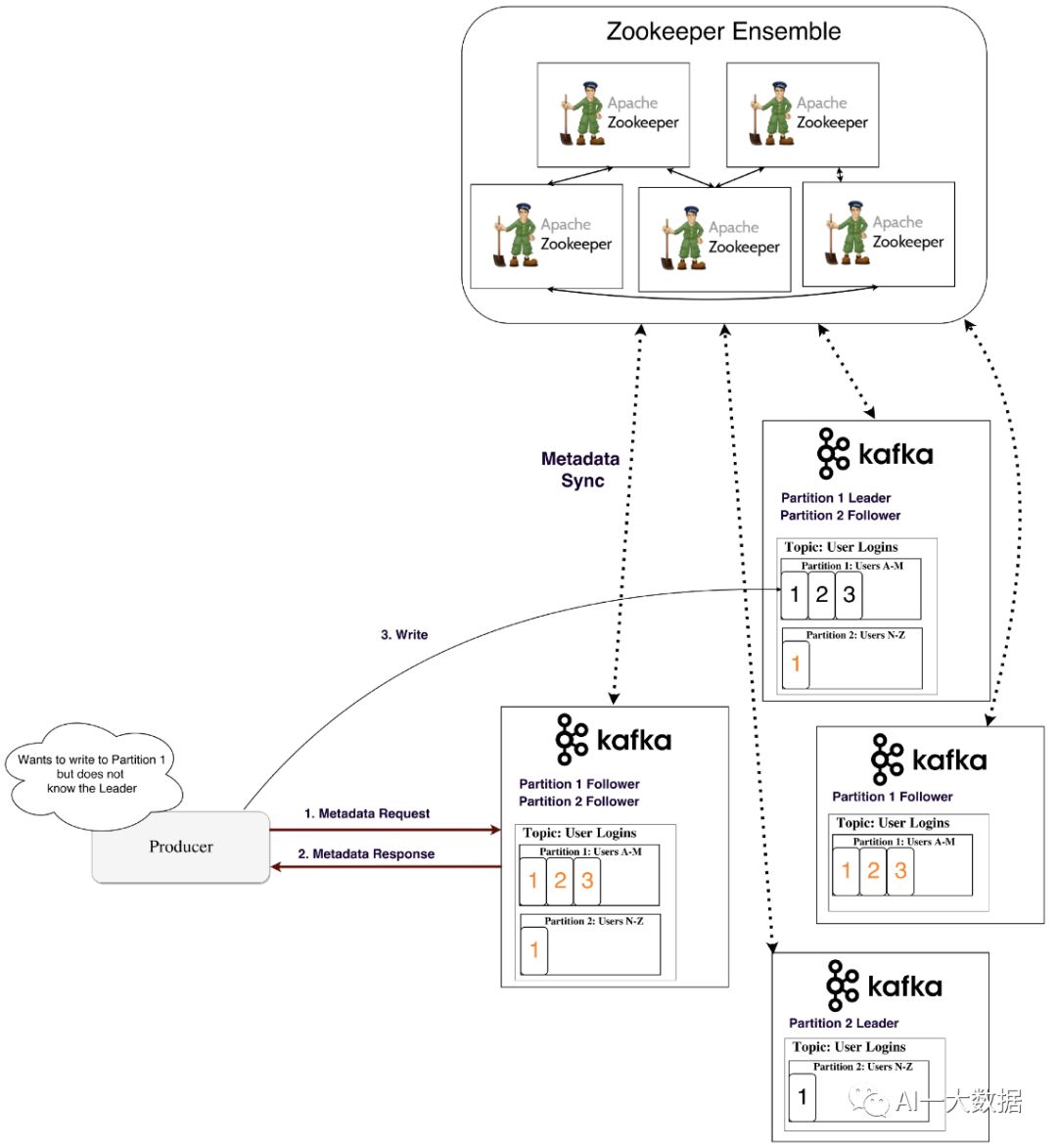
那么生产者和消费者怎么知道哪个分区是leader呢?Kafka把谁是分区leader这些元数据存储在Zookeeper,各个节点去向zookeeper同步元数据,这样集群中每个节点都知道谁是哪个分区的leader了(从Kafka 0.8版本开始,采用这种机制)
4.流式计算
Kafka从0.10版本开始,提供自己的流式计算Library-Kafka Stream,是Library,类库,而不是流式计算框架
对比Spark Streaming和Apache Storm等流式处理框架,Kafka Stream只需要Kafka,不需要任何外部框架或者服务,使用时,可方便的集成到自己的工程中,Kafka Stream不是运行在Kafka节点上的,而是像消费者API一样,可在其他应用上随意扩展。
继续下去之前,先介绍一下窗口的概念
窗口(windowing)是指流式处理过程中执行聚合(aggregation)操作的时间周期。窗口的定义很多,取决于特定的使用场景,基于时间的窗口将特定时间间隔内的事件分组,适合于回答类似于这样的问题“上一分钟产生了多少次交易” (摘自 O’REILLY 《流式架构 kafka与MapR Streams 数据流处理》)
流式计算除了可以充当ETL过程中T的角色,另外一个重要的作用就是回答窗口提出的问题,而回答问题的方式-比如执行聚合(aggregation)操作,又跟数据库求解的方式相似,因此,Stream 和 Table 的概念之间需要引入一些联系
Stream-Table Duality 流和表的对偶性, 即把流视为表,反之亦然,把表视为流
流作为表时,一个流可以认为是一个表的变更日志,这是事件溯源(Event Sourcing)的概念,流中每个数据记录着表每次的变化,表最终体现出流数据聚合的结果,用来回答窗口的提问
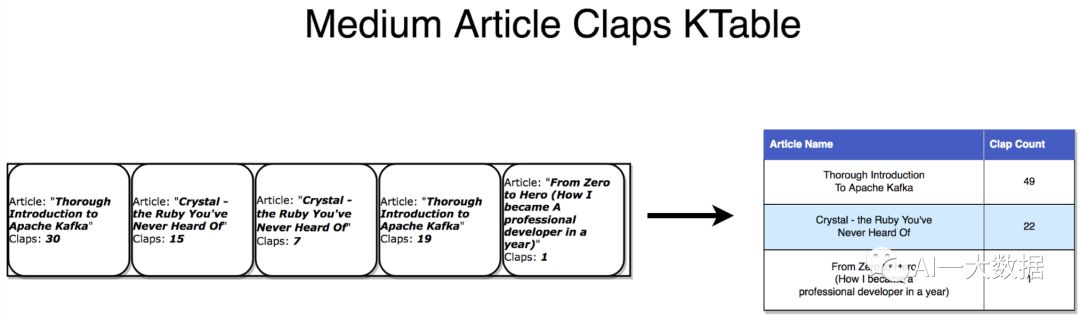
表作为流时,表可以认为是在流中的每个key的最新value的一个时间点的快照
流式计算处理还分为无状态处理和有状态处理,另外KSQL允许你用简单的类SQL语句编写流式计算任务
额外的介绍一下Confluent Platform,https://www.confluent.io/, KSQL正是出自这里
5.Kafka陷阱(陷阱是坑的一种高级说法)
以下陷阱,在版本0.9之前,且摘自 O’REILLY 《流式架构 kafka与MapR Streams 数据流处理》
Kafka单个消息默认最大为1M
Kafka能够处理的主题数目有限,达到1000个主题时,性能开始明显下降
每个主题的分区可以分布在各个节点,但是每个分区必须在一个节点上,分区不能在多个节点上分布存储,这意味着需要考虑磁盘空间大小是否能够满足一个分区的大小
没有固定的序列化机制,Kafka没有偏好的数据结构序列化机制,因此需要尽早约定这个机制,避免混乱
镜像不足,Kafka的镜像系统非常简单,简单的把消息转发给镜像集群,源集群的偏移量在目的集群中不再有效。
相应于上述Kafka的陷阱,MapR Streams提供了更好的解决方案,但未查到实际生产环境使用MapR Streams的相关资料
敬请关注AI一大数据
以上是关于重温 Apache Kafka的主要内容,如果未能解决你的问题,请参考以下文章