用Apache MXNet构建一个循环神经网络
Posted OReillyData
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了用Apache MXNet构建一个循环神经网络相关的知识,希望对你有一定的参考价值。
编者注:文中超链接如果不能访问可以点击“阅读原文”访问本文原页面。
在之前的教程里,我们使用一种叫卷积神经网络(CNN)的深度学习技术来对文本和图片进行分类。尽管CNN是一种强大的技术,但它却不能从序列型输入(如语音和文字)中学习到时间性的特征。另外,CNN使用一个固定长度的卷积核来学习空间的特征。这种类型的神经网络被叫做前馈神经网络。而循环神经网络(RNN)则可以学习到时间特征,而且比前馈神经网络有更广泛的应用。
在本教程里,我们将会开发一个循环神经网络,用它来在给定一个前置词或字符的情况下预测下一个词或字符是什么的概率。几乎我们所有人的智能手机上都有一个预测键盘,它能在我们快速输入的时候建议下一个词。循环神经网络就能让我们构建一个像SwiftKey这样的非常先进的预测系统。
我们会先讲解一下前馈神经网络的一些局限。接着,我们会用前馈神经网络实现一个基本的RNN模型。这个模型可以提供RNN工作机理的一个很好的展示。在这之后,我们会用MXNet的Gluon API提供的LSTM和GRU层来构建一个非常强大的RNN模型。我们会用这个模型来生成文字。
我们将介绍下面这些内容:
1. 前馈神经网络的局限;
2.RNN和LSTM背后的原理;
3.安装带有Gluon API的MXNet;
4.准备用于训练的数据集;
5.使用前馈神经网络实现一个基本RNN;
6.使用Gluon API实现一个能自动生成文本的RNN。
为了能更好地理解本教程,你需要对循环神经网络(RNN)、激活函数、梯度下降和反向传播有基本的了解。你还应该了解Python以及NumPy库。
前馈神经网络和循环神经网络的比较
虽然诸如卷积神经网络这样的前馈神经网络在语句和文本分类上有很好的准确度,但它还是没法记忆长间距依赖(即隐藏层状态)。记忆可以被看成是随着时间更新的时间性状态。前馈神经网络没法解释上下文,因为它没有存储时间性状态,也就是它没有记忆。CNN只能从它卷积核范围附近的邻居(图片或文字)那里学习到空间特征。图1显示了在相同的样本数据里,卷积神经网络提取的空间特征和RNN提取的时间上下文。在CNN里,字符O和V的联系被丢掉了。因为他们在不同的卷积空间上下文里。而在RNN里,字符L、O、V、E之间的联系被捕捉到了。
图1 CNN的空间上下文和RNN的时间上下文。图片由Manu Jeevan提供
前馈网络无法理解上下文,因为它没有“记忆”状态。所以它无法对于序列性或时间性的数据(像语言这种有明确顺序的数据)进行建模。对前馈神经网络的一个抽象表示如图2所示。
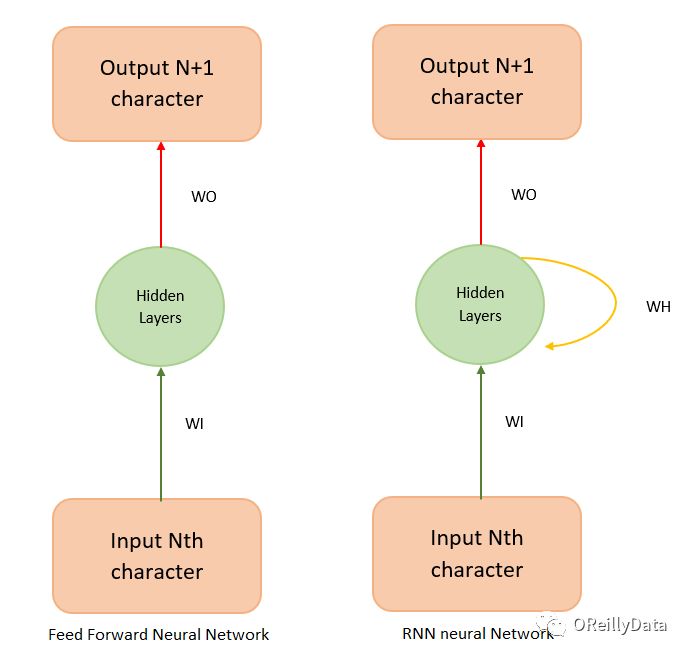
图2 前馈神经网络。图片由Manu Jeevan提供
RNN背后的原理
在这一节,我们将会通过用前馈神经网络构建一个展开版的基本RNN,来解释一下前馈神经网络和RNN的相似性。这个基本RNN只有一个简单的隐藏状态矩阵(记忆),很容易理解和实现。
假定我们必须根据前3个字符去预测一串字符的第4个字符。为了这一目的,我们设计一个如图3所示的简单的前馈神经网络。
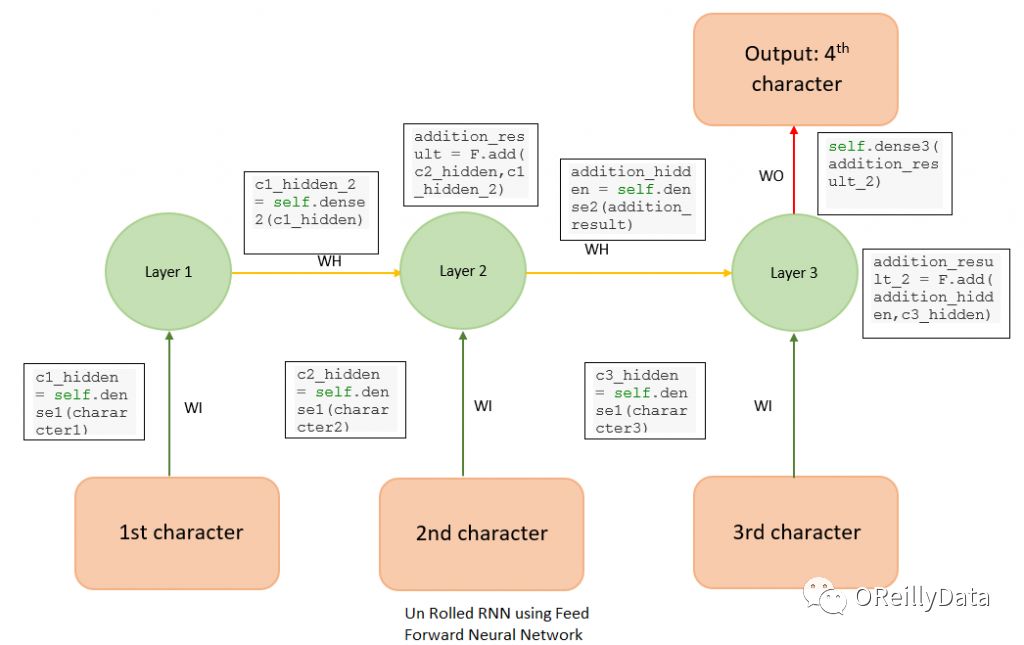
图3 展开的RNN。图片由Manu Jeevan提供
这是一个简单的前馈神经网络。其中,权重WI(绿色箭头)和WH(红色箭头)在一些层间共享同一组值。这是一个展开版的基本RNN,通常针对多对一的RNN应用场景,因为它是用多条输入(本例中,前3个字符)来预测1个字符。这个RNN可以用下面的MXNet代码来设计实现。
class UnRolledRNN_Model(Block):
def __init__(self, vocab_size, num_embed, num_hidden, **kwargs):
super(UnRolledRNN_Model, self).__init__(**kwargs)
self.num_embed = num_embed
self.vocab_size = vocab_size
# use name_scope to give child Blocks appropriate names.
# It also allows sharing Parameters between Blocks recursively.
with self.name_scope():
self.encoder = nn.Embedding(self.vocab_size, self.num_embed)
self.dense1 = nn.Dense(num_hidden, activation=’relu’, flatten=True)
self.dense2 = nn.Dense(num_hidden, activation=’relu’, flatten=True)
self.dense3 = nn.Dense(vocab_size, flatten=True)
def forward(self, inputs):
emd = self.encoder(inputs)
# print( emd.shape )
# since the input is shape (batch_size, input(3 characters) )
# we need to extract 0th, 1st, 2nd character from each batch
character1 = emd[:, 0, :]
character2 = emd[:, 1, :]
character3 = emd[:, 2, :]
# green arrow in diagram for character 1
c1_hidden = self.dense1(character1)
# green arrow in diagram for character 2
c2_hidden = self.dense1(character2)
# green arrow in diagram for character 3
c3_hidden = self.dense1(character3)
# yellow arrow in diagram
c1_hidden_2 = self.dense2(c1_hidden)
addition_result = F.add(c2_hidden, c1_hidden_2) # Total c1 + c2
addition_hidden = self.dense2(addition_result) # the yellow arrow
addition_result_2 = F.add(addition_hidden, c3_hidden) # Total c1 + c2
final_output = self.dense3(addition_result_2)
return final_output
vocab_size = len(chars) + 1 # the vocabsize
num_embed = 30
num_hidden = 256
# model creation
simple_model = UnRolledRNN_Model(vocab_size, num_embed, num_hidden)
# model initilisation
simple_model.collect_params().initialize(mx.init.Xavier(), ctx=context)
trainer = gluon.Trainer(simple_model.collect_params(), ‘adam’)
loss = gluon.loss.SoftmaxCrossEntropyLoss()
基本上,这个神经网络是一个词向量层(emb),后面接着3个全连接层:
1.全连接层1(带有权重WI),它接收输入;
2.全连接层2(带有权重WH),中间层;
3.全连接层3(带有权重WO),这一层产生输出。其中也用了MXNet的数组加法来把产生的输出与输入进行组合。
你可以查看这个博客来了解词向量层以及它的功能。全连接层1、2和3学到了一套权重,并用它来根据给出的前3个字符预测第4个字符。
我们在这个模型里使用二元交叉熵损失函数。这个模型可以被折叠回来,用图4所示的方式来简洁地表示。
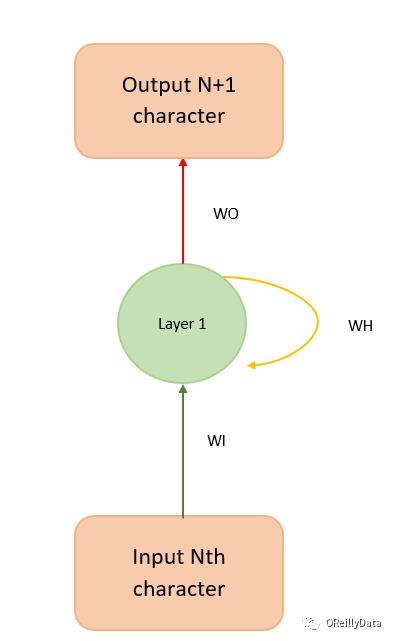
图4 RNN的简洁版表示。图片由Manu Jeevan提供
图4可以帮助解释模型背后的数学部分,如下所示:
hidden_state_at_t = tanh(WI x input + WH x previous_hidden_state + bias)
基本RNN有一些缺陷。例如,我们有下面一个很长的文档,其中包含下面这些句子:“我出生在法国,在世界大战期间”,“所以我会说法语”。基本RNN就无法理解“出生在法国”是“我会说法语”的上下文,因为这两个部分在这个句子里相隔很远。
RNN也没有能力(至少实际是如此)忘记语句之间的不相关的上下文。基本RNN对越靠近的隐藏状态给予更多的重要性,因为它无法给指定的(t-k)步隐藏状态更多的偏好。其中,t是当前的时间步,而k是一个大于0的数。这是因为用一个很长的句子来训练基本RNN可能会在反向传播时导致梯度消失(即梯度很小)或梯度爆炸(即梯度非常大)。
基本上,反向传播算法会沿着神经网络计算图的相反方向上对梯度进行连乘。因此当隐藏层矩阵的特征值非常小或非常大的时候,梯度就会变得非常不稳定。可以在这里找到对RNN里这个问题的更详细的解释。
除了多对一的RNN之外,还有其他类型的RNN可以实现基于记忆的应用,包括非常流行的序列到序列的RNN(见图5)。在这个序列到序列的RNN模型里,序列的长度是3,每个输入都对应到一个单独的输出。这可以帮助让模型的训练更快,因为我们在每个时间步都计算损失值(预测值和真实值之间的差距)。和上文只在最终计算一个损失不同,我们可以看到损失1、2等。因此训练模型时就能得到更好的反馈(反向传播)。
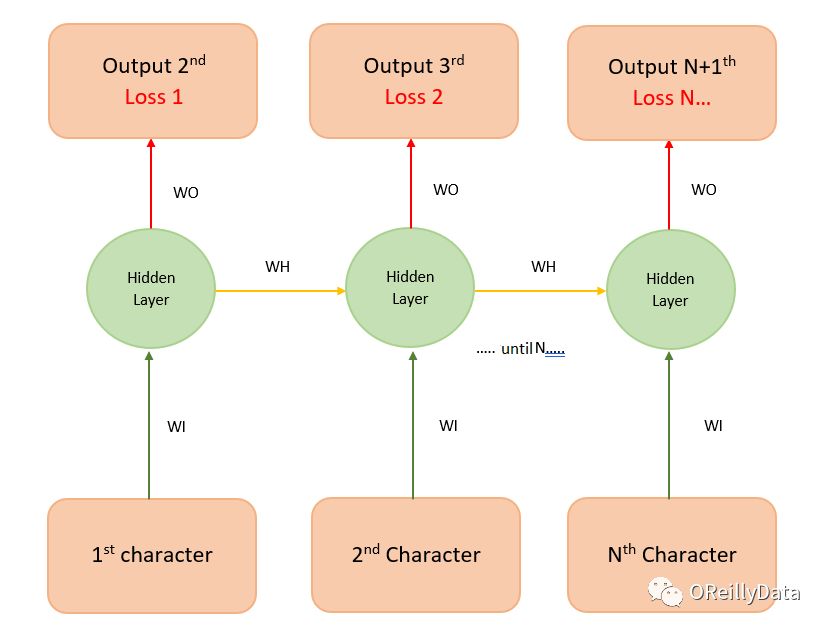
图5 序列到序列RNN。图片由Manu Jeevan提供
长短期记忆模型(LSTM)
为了解决基本RNN的这些问题,两位德国学者(Sepp Hochreiter和Juergen Schmidhuber)提出了长短期记忆模型(LSTM, Long Short-Term Memory)。这是一个更复杂的模型,可以解决基本RNN的梯度消失或爆炸的问题。可以在这里和这里看到对于基本版LSTM的非常漂亮的演示图。从更高层面看,我们可以把一个LSTM单元看成一个小型的神经网络。它可以决定需要保留(记忆)前面哪些时间步里的信息量。
实现一个LSTM
现在让我们试着构建一个简单的字符预测器。
准备环境
如果你能使用AWS云,那么可以省掉很多安装的工作。只要使用Amazon SageMaker的预配置的深度学习环境即可。如果能这样做,你可以直接跳过下面的步骤1到5。
如果你使用一个Conda的环境,记得要先在conda环境里安装pip工具。在激活你的conda环境后输入:conda install pip。这会帮你在后面的步骤里避免很多坑。
下面是安装和设置的方法:
安装Anaconda这个Python库管理器。用Anaconda来安装Python的各种库会非常容易。你可以用这个curl命令来下载Anaconda并安装:curl -O https://repo.continuum.io/archive/Anaconda3-4.2.0-Linux-x86_64.sh chmod 777 Anaconda3-4.2.0-Linux-x86_64.sh ./Anaconda3-4.2.0-Linux-x86_64.sh
安装scikit-learn。这是一个通用的科学计算库。我们会用它来对我们的数据进行预处理。可以用这个命令来安装:conda install scikit-learn
安装Jupyter Notebook,命令是:conda install jupyter
获取MXNet,这是一个开源的深度学习库。这里用的Python notebook在MXNet的0.12.0版本上通过了测试。可以用下面的命令安装MXNet:pip install mxnet-cu90(如果你有GPU)。没有GPU的话,就用pip install mxnet –pre来安装。可以在这里看到MXNet的文档。
在激活anaconda的环境后,在里面运行下面的命令:source activate mxnet。
上面的命令汇总如下:
curl -O https://repo.continuum.io/archive/Anaconda3-4.2.0-Linux-x86_64.sh
chmod 777 Anaconda3-4.2.0-Linux-x86_64.sh
./Anaconda3-4.2.0-Linux-x86_64.sh
conda install pip
pip install opencv-python
conda install scikit-learn
conda install jupyter
pip install mxnet-cu90
你可以在这里下载本文教程的MXNet notebook。里面有我们写好并测试通过的代码。你可以调整超参数并尝试不同的神经网络架构,好好玩一下吧!
准备数据集
我们会用Friedrich Nietzsche的工作成果作为我们的数据集。
你可以在这里下载此数据集。当然你也可以用其他的数据集,比如你自己的聊天记录,或是你从这个地方下载的数据集。如果是用你自己的聊天记录,你就可以为你自己的风格写一个定制化的可预测的文本编辑器了。在这里,我们还是用Nietzche的数据集。
数据集文件 (nietzsche.txt)包括600901个字符,来自86个唯一的字符。我们需要把这个文本转换成一系列的数字串。
# total of characters in dataset
chars = sorted(list(set(text)))
vocab_size = len(chars)+1
print(‘total chars:’, vocab_size)
# maps character to unique index e.g. {a:1,b:2….}
char_indices = dict((c, i) for i, c in enumerate(chars))
# maps indices to character (1:a,2:b ….)
indices_char = dict((i, c) for i, c in enumerate(chars))
# mapping the dataset into index
idx = [char_indices for c in text]
针对展开版的RNN准备数据
转换的目的是把数据转换成一系列的输入和输出组。来自输入串的每3个字符串都会被存下来作为模型的3字符输入,而第4个字符作为输出,从而能用来训练我们的预测模型。例如,我们把字符串I_love_mxnet转换成如图6所示的输入和输出组。
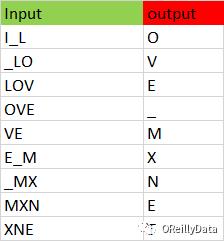
图6 “I_love_mxnet”的输入和输出组。图片由Manu Jeevan提供
做这个转换的代码如下:
# input for neural network(our basic rnn has 3 inputs, n samples)
cs = 3
c1_dat = [idx[i] for i in range(0, len(idx)-1-cs, cs)]
c2_dat = [idx[i+1] for i in range(0, len(idx)-1-cs, cs)]
c3_dat = [idx[i+2] for i in range(0, len(idx)-1-cs, cs)]
# the output of rnn network (single vector)
c4_dat = [idx[i+3] for i in range(0, len(idx)-1-cs, cs)]
# stacking the inputs to form (3 input features )
x1 = np.stack(c1_dat[:-2])
x2 = np.stack(c2_dat[:-2])
x3 = np.stack(c3_dat[:-2])
# the output (1 X N data points)
y = np.stack(c4_dat[:-2])
col_concat = np.array([x1, x2, x3])
t_col_concat = col_concat.T
print(t_col_concat.shape)
我们还要把训练数据分成32组一批的批次。这样每个训练输入实例的尺寸就是32 X 3。批次化可以帮助加速模型的训练。
# Set the batchsize as 32, so input is of form 32 X 3
# output is 32 X 1
batch_size = 32
def get_batch(source, label_data, i, batch_size=32):
bb_size = min(batch_size, source.shape[0] – 1 – i)
data = source[i: i + bb_size]
target = label_data[i: i + bb_size]
# print(target.shape)
return data, target.reshape((-1, ))
为Gluon RNN准备数据
上一节我们为给定前3个字符来预测第4个字符做的模型准备了数据。这一节里,我们会扩展这个算法,为给定的任意前n-1个字符,预测第n个字符。要做的和为展开版的RNN准备数据差不多,除了要改变输入的大小。此数据集也应该被转化成这个形状(输入X的长度,批次大小)。现在让我们把样本数据分成如图7所示的多个批次。
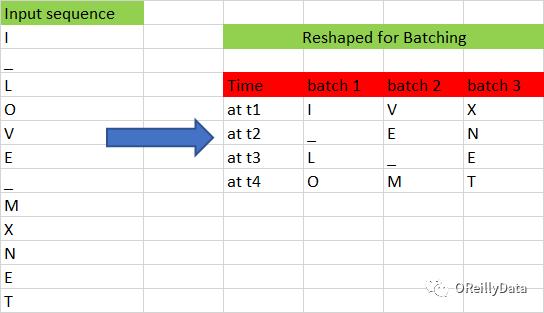
图7 批次化输入。图片由Manu Jeevan提供
我们把输入的串转化成了每批次3个输入,每个输入长度为4。经过这个转换后,我们丢失了一些相邻字符间的时间关系。比如,字符O和V、M和X。其中字符V是在O后面的,但是它们被分到了不同的批次里面。我们对数据进行批次化的唯一目的就是加快训练的过程。下面是实现批次化的代码:
# prepares rnn batches
# The batch will be of shape is (num_example * batch_size) because of RNN uses sequences of input x
# for example if we use (a1,a2,a3) as one input sequence , (b1,b2,b3) as another input sequence and (c1,c2,c3)
# if we have batch of 3, then at timestep ‘1’ we only have (a1,b1.c1) as input, at timestep ‘2’ we have (a2,b2,c2) as input…
# hence the batchsize is of order
# In feedforward we use (batch_size, num_example)
def rnn_batch(data, batch_size):
“””Reshape data into (num_example, batch_size)”””
nbatch = data.shape[0] // batch_size
data = data[:nbatch * batch_size]
data = data.reshape((batch_size, nbatch)).T
return data
图8显示了另外一个批次的例子,其中批次里的样本数为2个,每个长度是6。
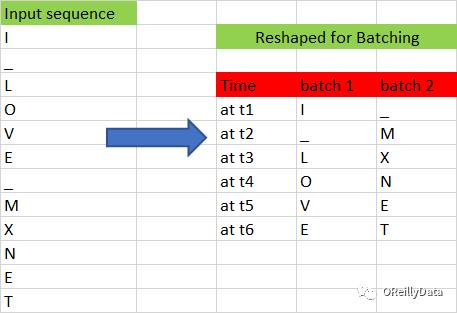
图8 批次的形状转换。图片由Manu Jeevan提供
在给定批次里改变输入的长度是非常简单的。例如,如果想从一个批次大小为2的批次里生成一个长度为3的输入,用下面的代码就能实现。
#get the batch
def get_batch(source, i, seq):
seq_len = min(seq, source.shape[0] – 1 – i)
data = source[i: i + seq_len]
target = source[i + 1: i + 1 + seq_len]
return data, target.reshape((-1,))
在这里的训练里,我们会使用输入长度为100,并把它作为超参数。可以更进一步地调优这个超参数来得到更好的结果。
用Gluon来定义RNN模型
接下来,我们定义一个类,其中可以构造两种RNN模型,用于我们的样本。一种是GRU(门控循环单元模型,Gated Recurrent Unit)和LSTM(长短期记忆单元模型)。GRU是一个简化版的LSTM,且性能差不多。你能在这里看到一个对它们的比较研究。下面的代码片就是这些模型的定义。
class GluonRNNModel(gluon.Block):
“””A model with an encoder, recurrent layer, and a decoder.”””
def __init__(self, mode, vocab_size, num_embed, num_hidden,
num_layers, dropout=0.5, **kwargs):
super(GluonRNNModel, self).__init__(**kwargs)
with self.name_scope():
self.drop = nn.Dropout(dropout)
self.encoder = nn.Embedding(vocab_size, num_embed,
weight_initializer=mx.init.Uniform(0.1))
if mode == ‘lstm’:
# we create a LSTM layer with certain number of hidden LSTM cell and layers
# in our example num_hidden is 1000 and num of layers is 2
# The input to the LSTM will only be passed during the forward pass (see forward function below)
self.rnn = rnn.LSTM(num_hidden, num_layers, dropout=dropout,
input_size=num_embed)
elif mode == ‘gru’:
# we create a GRU layer with certain number of hidden GRU cell and layers
# in our example num_hidden is 1000 and num of layers is 2
# The input to the GRU will only be passed during the forward pass (see forward function below)
self.rnn = rnn.GRU(num_hidden, num_layers, dropout=dropout,
input_size=num_embed)
else:
# we create a vanilla RNN layer with certain number of hidden vanilla RNN cell and layers
# in our example num_hidden is 1000 and num of layers is 2
# The input to the vanilla will only be passed during the forward pass (see forward function below)
self.rnn = rnn.RNN(num_hidden, num_layers, activation=’relu’, dropout=dropout,
input_size=num_embed)
self.decoder = nn.Dense(vocab_size, in_units=num_hidden)
self.num_hidden = num_hidden
# define the forward pass of the neural network
def forward(self, inputs, hidden):
emb = self.encoder(inputs)
# emb, hidden are the inputs to the hidden
output, hidden = self.rnn(emb, hidden)
# the ouput from the hidden layer to passed to drop out layer
output = self.drop(output)
# print(‘output forward’,output.shape)
# Then the output is flattened to a shape for the dense layer
decoded = self.decoder(output.reshape((-1, self.num_hidden)))
return decoded, hidden
# Initial state of RNN layer
def begin_state(self, *args, **kwargs):
return self.rnn.begin_state(*args, **kwargs)
这个类的构造函数里面创建了用于前向传播的神经元们。这个构造函数接收三种类型RNN层的参数:LSTM、GRU和基本RNN。前向传播方法会在训练时被使用,生成训练数据的损失值。
前向传播函数开始时会为输入的字符创建一个词向量层。 你可以看一下我们之前的这篇博客来更多的了解词向量的知识。词向量层的输出则作为RNN的输入。RNN层会返回一个输出层以及隐藏层的状态。中间的dropout层则会防止模型完全记住输入和输出的映射关系,从而避免过拟合。RNN的输出再经过一个解码器(全连接层)完成下一个字符的预测,并在训练阶段计算损失值。
我们定义了一个“开始状态”函数,它可以为模型初始化隐藏层的状态。
训练这个网络
在定义完网络后,我们就开始训练这个网络,让它进行学习。
def trainGluonRNN(epochs, train_data, seq=seq_length):
for epoch in range(epochs):
total_L = 0.0
hidden = model.begin_state(func=mx.nd.zeros, batch_size=batch_size, ctx=context)
for ibatch, i in enumerate(range(0, train_data.shape[0] – 1, seq_length)):
data, target = get_batch(train_data, i, seq)
hidden = detach(hidden)
with autograd.record():
output, hidden = model(data, hidden)
L = loss(output, target) # this is total loss associated with seq_length
L.backward()
grads = [i.grad(context) for i in model.collect_params().values()]
# Here gradient is for the whole batch.
# So we multiply max_norm by batch_size and seq_length to balance it.
gluon.utils.clip_global_norm(grads, clip * seq_length * batch_size)
trainer.step(batch_size)
total_L += mx.nd.sum(L).asscalar()
if ibatch % log_interval == 0 and ibatch > 0:
cur_L = total_L / seq_length / batch_size / log_interval
print(‘[Epoch %d Batch %d] loss %.2f’, epoch + 1, ibatch, cur_L)
total_L = 0.0
model.save_params(rnn_save)
每个周期的开始都是对隐藏单元初始化成零。在对批次训练时,我们会把这个隐藏单元从计算图里分割出来,这样在反向传播进行梯度计算时,就不会在超过序列长度时(我们这里是100)还进行梯度计算。如果我们不进行分割,梯度就会被传送到这个开始的隐藏层状态(t=0)。在分割后,我们计算了损失值,并用反向传播函数来进行损失值的反向传播,从而进行权重的调优。我们还通过把梯度和输入长度和批次大小相乘来对梯度进行正规化。
文本生成
在模型用数据进行训练后,我们就能生成与训练数据类似的随机文本。针对输入长度100进行200个周期训练后的模型的权重文件可以在这里下载。下载后,你可以用model.load_params函数导入这些模型权重。
下面,我们使用这个模型来生成类似于nietzsche的文字。为了生成任意长度的文本,我们使用模型的输出作为下一次生成的输入。
为了生成文本,我们先初始化隐藏层的状态。
hidden = model.begin_state(func=mx.nd.zeros, batch_size=batch_size, ctx=context)
这里我们没必要在分割这个初始隐藏层状态了,因为我们不会再通过反向传播来调整权重。
接着我们把输入的向量改变一下尺寸再传给这个RNN模型。
sample_input = mx.nd.array(np.array([idx[0:seq_length]]).T, ctx=context)
随后使用argmax来计算网络的输出,生成输出字符“c”。
output, hidden = model(sample_input, hidden)
index = mx.nd.argmax(output, axis=1)
index = index.asnumpy()
count = count + 1
再把生成的字符“c”添加到输入串的最后,并把输入串的第一个字符删掉。
new_string = new_string + indices_char[index[-1]]
input_string = input_string[1:] + indices_char[index[-1]]
下面是生成任意长度的类似nietzsche的文本的全部代码。
import sys
# a nietzsche like text generator
def generate_random_text(model, input_string, seq_length, batch_size, sentence_length):
count = 0
new_string = ”
cp_input_string = input_string
hidden = model.begin_state(func=mx.nd.zeros, batch_size=batch_size, ctx=context)
while count < sentence_length:
idx = [char_indices for c in input_string]
if(len(input_string) != seq_length):
print(len(input_string))
raise ValueError(‘there was a error in the input ‘)
sample_input = mx.nd.array(np.array([idx[0:seq_length]]).T, ctx=context)
output, hidden = model(sample_input, hidden)
index = mx.nd.argmax(output, axis=1)
index = index.asnumpy()
count = count + 1
new_string = new_string + indices_char[index[-1]]
input_string = input_string[1:] + indices_char[index[-1]]
print(cp_input_string + new_string)
如果你查看生成的文本,你就会发现模型已经学到使用开闭引号(“”)。模型学到了有限的文本结构,看起来比较像nietzsche了。
你还可以用你自己的聊天记录来训练模型,然后预测你会敲出的下一个字符。
在下一篇文章里,我们会学习生成模型,特别是生成对抗网络。这是一个从给定的数据集学习,并能生成新数据的强大的模型。
注意:虽然RNN模型可以被用来生成文本,但严格意义上它并不是一个好的生成模型。这个PDF文档清晰地展示了用于文本分类的生成模型和判别模型的区别。
这篇博文是O’Reilly和Amazon的合作产物。请阅读我们的编辑独立声明。

Suresh Rathnaraj是人工智能公司AI Solutions的联合创始人,该公司为企业构建AI解决方案。 他是一名机器学习工程师,拥有计算机科学硕士学位。 他非常热衷于深度学习,并认为它可以彻底改变整个科技行业。 业余时间里他会打橄榄球并练习瑜伽。可以在LinkedIn上找到他。
Manu Jeevan是人工智能公司AI Solutions的联合创始人,该公司为企业构建人工智能解决方案。他是一名自学成才的数据科学家,喜欢用人工智能和机器学习来解决复杂的业务问题。 可以在LinkedIn上找到他。
This article originally appeared in English: "Build a recurrent neural network using Apache MXNet".
以上是关于用Apache MXNet构建一个循环神经网络的主要内容,如果未能解决你的问题,请参考以下文章
资源 | 一张速查表实现Apache MXNet深度学习框架五大特征的开发利用
MXNet中使用双向循环神经网络BiRNN对文本进行情感分类