实践篇 |Apache Flume
Posted 5ithink
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实践篇 |Apache Flume相关的知识,希望对你有一定的参考价值。
Apache Flume is a distributed, reliable, and available system for efficiently collecting, aggregating and moving large amounts of log data from many different sources to a centralized data store.
Components
Agent是Flume NG最小独立运行单位。一个Agent是一个JVM进程,由Source/Channel/Sink组成,也可以包含多个Source和Sink。Event包含日志数据(字节数组形式)+携带头部信息,是Flume NG 传输数据以及事务的基本单位。
1.Source
从Client收集数据,传递给Channel支持Avro/log4j/syslog/http post(body为json格式)

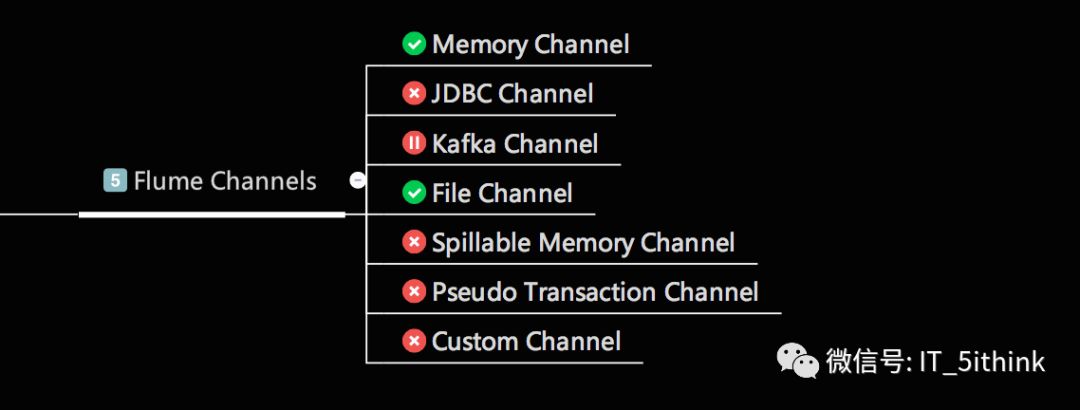
2.Channel
接收Source的输出,直到有Sink消费掉Channel中的数据。
Memory Channel:实现高速的吞吐,无法保证数据的完整性
File Channel :保证数据的完整性和一致性,写入Sink失败,会重发不回造成数据丢失
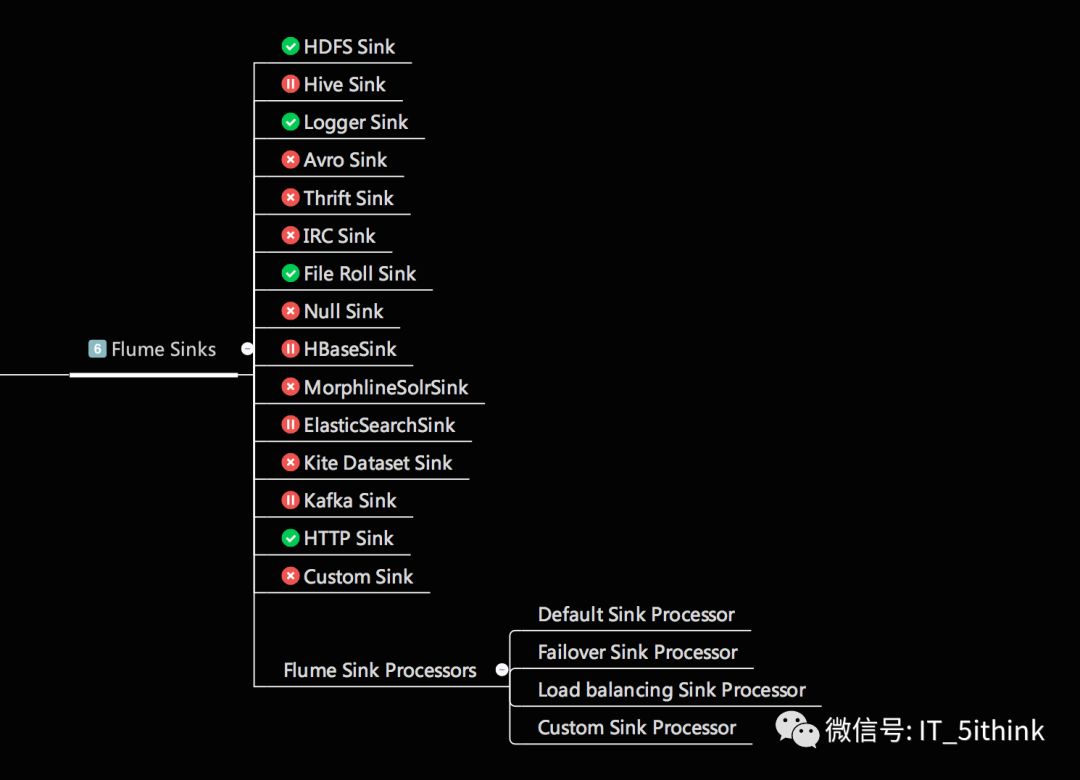
3.Sink
消费Channel中的数据,发送给外部源[其他Source/文件系统/数据库/HDFS/HBase]
3.Interceptor

Architecture
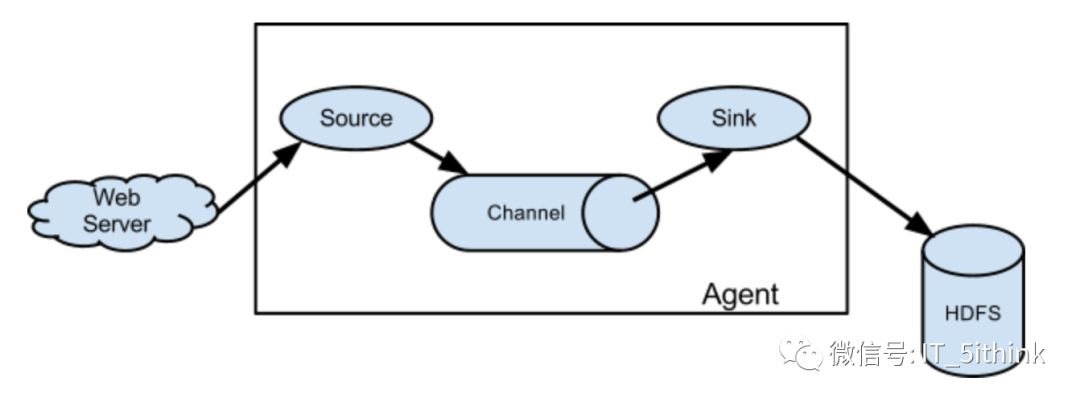
data flow model
A Flume event is defined as a unit of data flow having a byte payload and an optional set of string attributes. A Flume agent is a (JVM) process that hosts the components through which events flow from an external source to the next destination (hop).
Complex flows
Flume allows a user to build multi-hop flows where events travel through multiple agents before reaching the final destination. It also allows fan-in and fan-out flows, contextual routing and backup routes (fail-over) for failed hops.
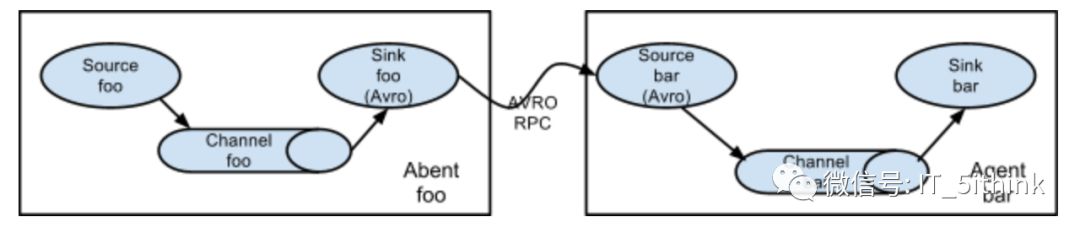
multi-agent flow
In order to flow the data across multiple agents or hops, the sink of the previous agent and source of the current hop need to be avro type with the sink pointing to the hostname (or IP address) and port of the source.
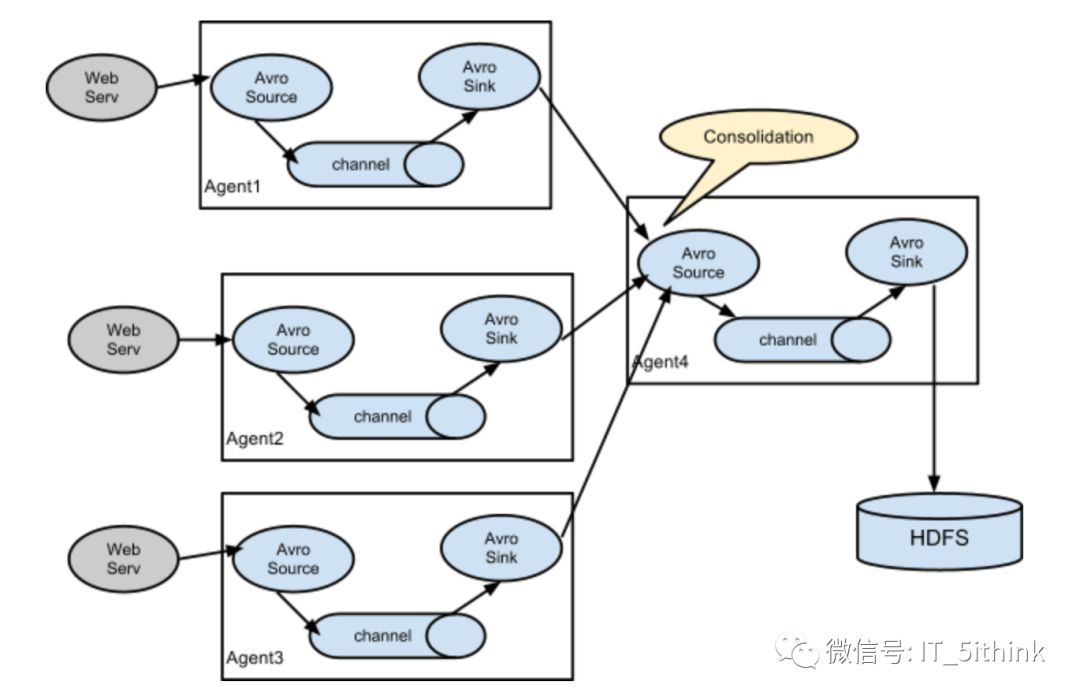
Consolidation
This can be achieved in Flume by configuring a number of first tier agents with an avro sink, all pointing to an avro source of single agent . This source on the second tier agent consolidates the received events into a single channel which is consumed by a sink to its final destination.
Multiplexing the flow
Flume supports multiplexing the event flow to one or more destinations. This is achieved by defining a flow multiplexer that can replicate or selectively route an event to one or more channels.The example shows a source from agent “foo” fanning out the flow to three different channels. This fan out can be replicating or multiplexing. In case of replicating flow, each event is sent to all three channels. For the multiplexing case, an event is delivered to a subset of available channels when an event’s attribute matches a preconfigured value.
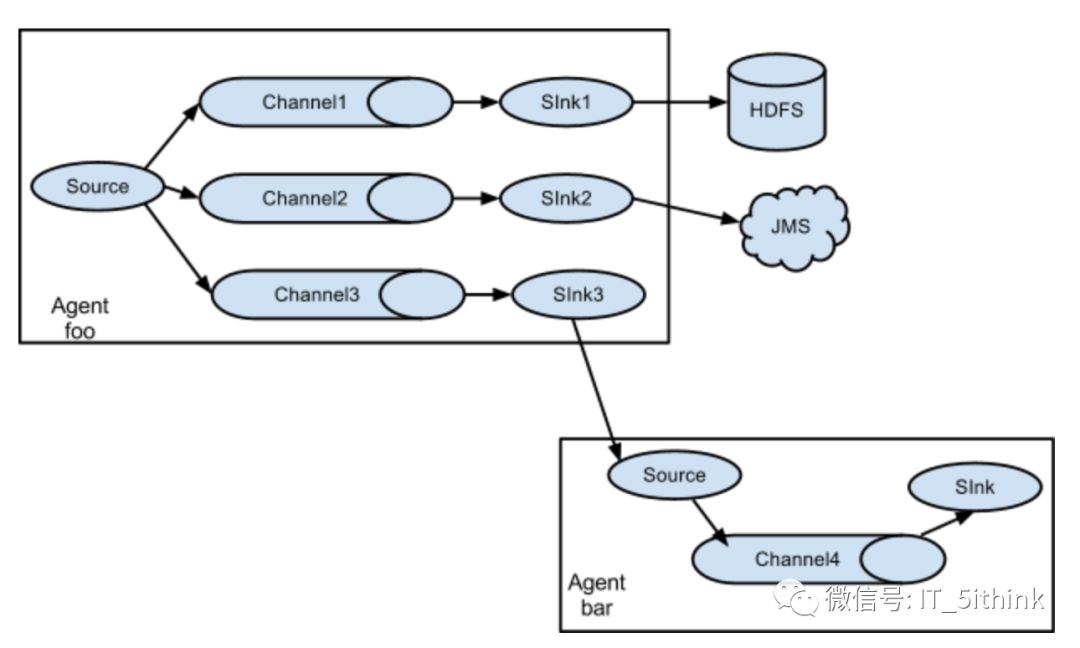
Fan out flow
As discussed in previous section, Flume supports fanning out the flow from one source to multiple channels. There are two modes of fan out, replicating and multiplexing. In the replicating flow, the event is sent to all the configured channels. In case of multiplexing, the event is sent to only a subset of qualifying channels.Flume Channel Selectors
Reliability
The events are staged in a channel on each agent. The events are then delivered to the next agent or terminal repository (like HDFS) in the flow. The events are removed from a channel only after they are stored in the channel of next agent or in the terminal repository. This is a how the single-hop message delivery semantics in Flume provide end-to-end reliability of the flow.
Flume uses a transactional approach to guarantee the reliable delivery of the events. The sources and sinks encapsulate in a transaction the storage/retrieval, respectively, of the events placed in or provided by a transaction provided by the channel. This ensures that the set of events are reliably passed from point to point in the flow. In the case of a multi-hop flow, the sink from the previous hop and the source from the next hop both have their transactions running to ensure that the data is safely stored in the channel of the next hop.
Recoverability
The events are staged in the channel, which manages recovery from failure. Flume supports a durable file channel which is backed by the local file system. There’s also a memory channel which simply stores the events in an in-memory queue, which is faster but any events still left in the memory channel when an agent process dies can’t be recovered.
Flume环境搭建及部署
1.环境要求
Java Runtime Environment - Java 1.8 or later
Memory - Sufficient memory for configurations used by sources, channels or sinks
Disk Space - Sufficient disk space for configurations used by channels or sinks
Directory Permissions - Read/Write permissions for directories used by agent
2.安装组件
JDK1.8
Flume1.8
hadoop-3.0.0
3.下载安装
wget http://mirrors.hust.edu.cn/apache/flume/1.8.0/apache-flume-1.8.0-bin.tar.gz
tar -zxvf apache-flume-1.8.0-bin.tar.gz
4.配置环境
cd apache-flume-1.8.0-bin
cp conf/flume-conf.properties.template conf/flume.conf
cp conf/flume-env.sh.template conf/flume-env.sh
demo_1:Avro RPC Source
1.requirement
This example creates a memory channel, an Avro RPC source, and a logger sink and connects them together. Any events received by the Avro source are routed to the channel ch1 and delivered to the logger sink.
2.Data Flow
Avro RPC source—>memory channel—>logger sink
3.configure
vi conf/flume.conf
4.运行agent
bin/flume-ng agent --conf ./conf/ -f conf/flume.conf -Dflume.root.logger=DEBUG,console -n agent1
The Avro client treats each line (terminated by
,
, or
) as an event. Think of the avro-client command as cat for Flume. For instance, the following creates one event per Linux user and sends it to Flume's avro source on localhost:41414.
5.发送数据
bin/flume-ng avro-client --conf conf -H localhost -p 41414 -F /etc/passwd -Dflume.root.logger=DEBUG,console

6.验证数据传输
Demo2:NetCat TCP Source
1.requirement
This example configuration file, describing a single-node Flume deployment lets a user generate events and subsequently logs them to the console.This configuration defines a single agent named a1. a1 has a source that listens for data on port 41414, a channel that buffers event data in memory, and a sink that logs event data to the console.
2.Date Flow
NetCat TCP Source—> memory channel—>logger sink
3.configure
vi conf/flume-netcat.conf
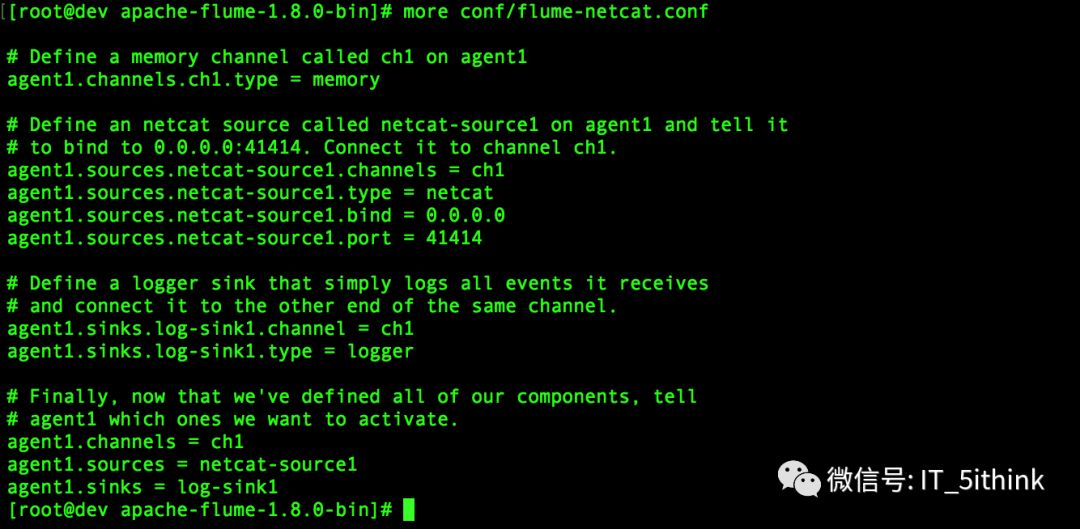
4.启动
bin/flume-ng agent --conf ./conf/ -f conf/flume-netcat.conf -Dflume.root.logger=DEBUG,console -n agent1
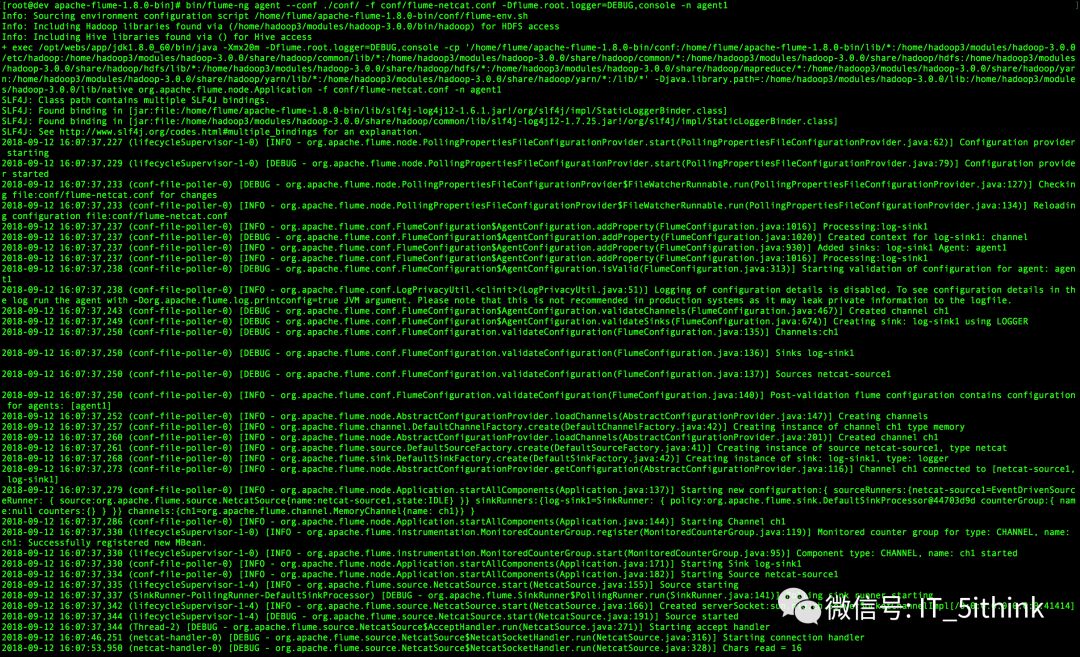
5.发送数据

6.验证数据传输
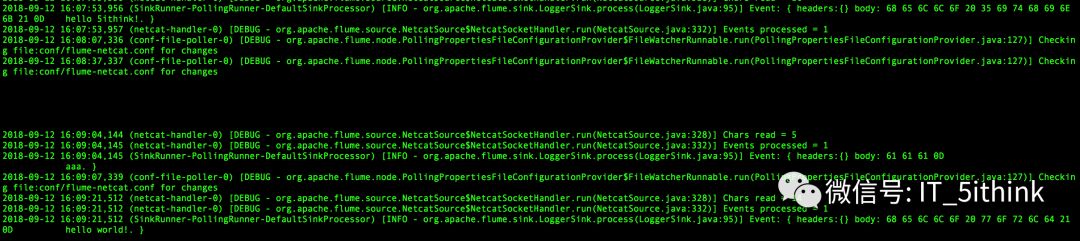
demo_3:Exec Source
1.Data Flow
Exec Source—> memory channel—>logger sink
2.配置
vi conf/exec.conf
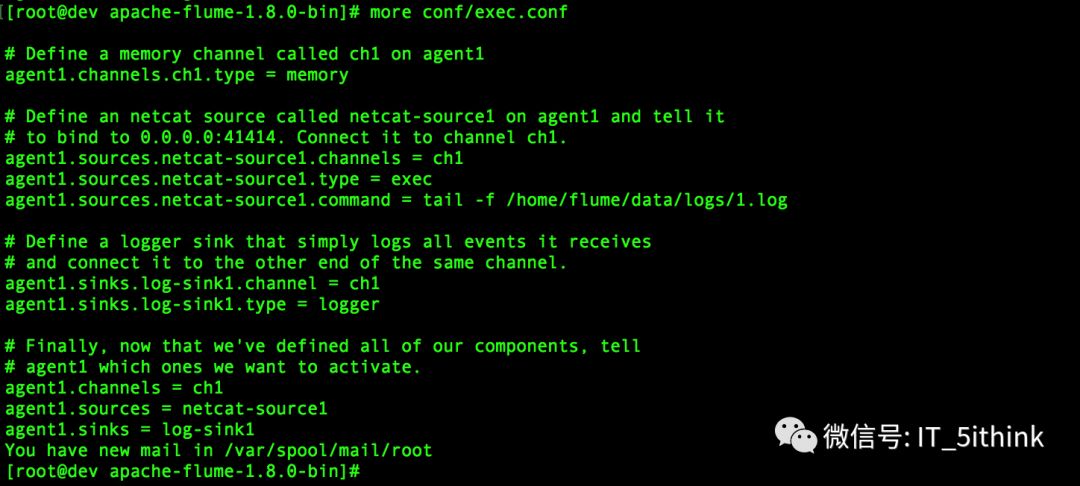
3.启动
bin/flume-ng agent --conf ./conf/ -f conf/exec.conf -Dflume.root.logger=DEBUG,console -n agent1
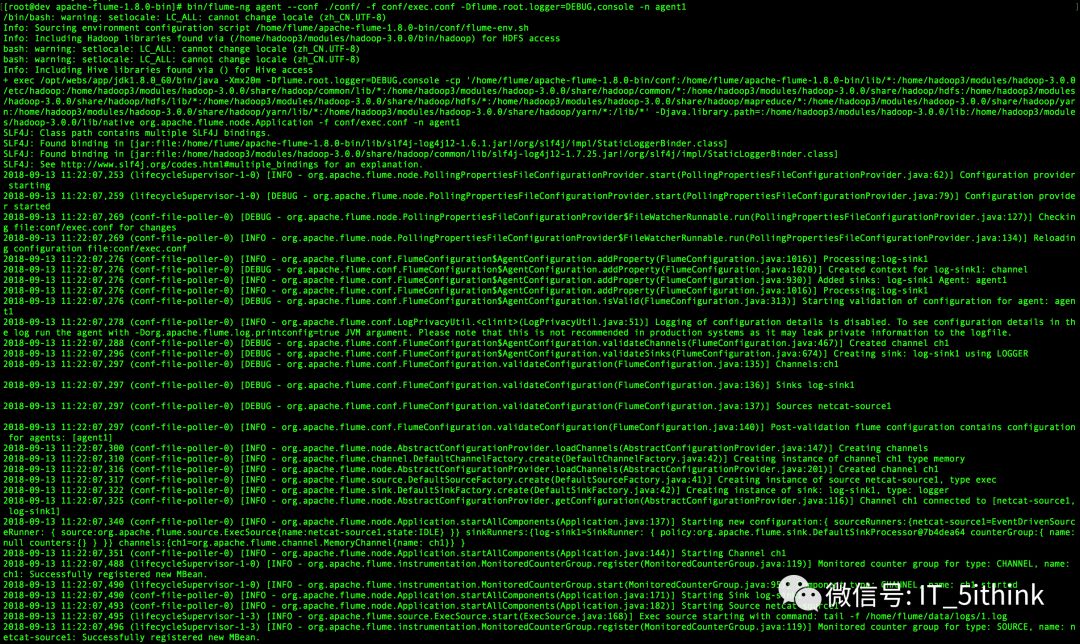
4.发送数据
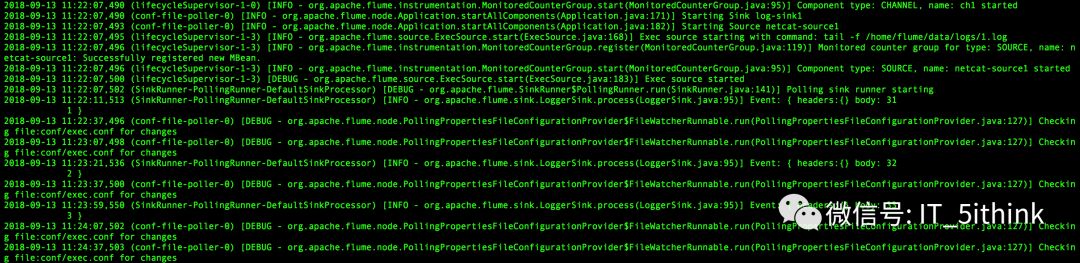
echo 2 >> /home/flume/datalogs/1.log
echo 3 >> /home/flume/datalogs/1.log
echo 4 >> /home/flume/datalogs/1.log
5.验证数据传输
Demo4:Spooling Directory Source
1.Data Flow
1.Spooling Directory Source—>file channel—>avro Sink
2.Avro Source—>file channel—>avro Sink
3.Avro Source—>file channel—>hdfs Sink
2.配置
vi conf/sc1-flume.conf
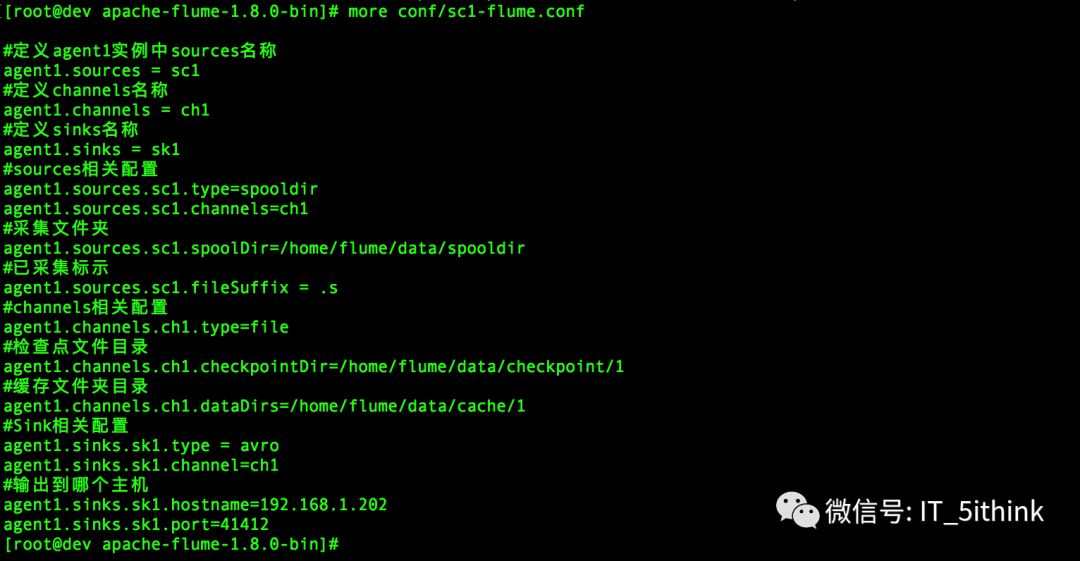
vi conf/ch1-flume.conf
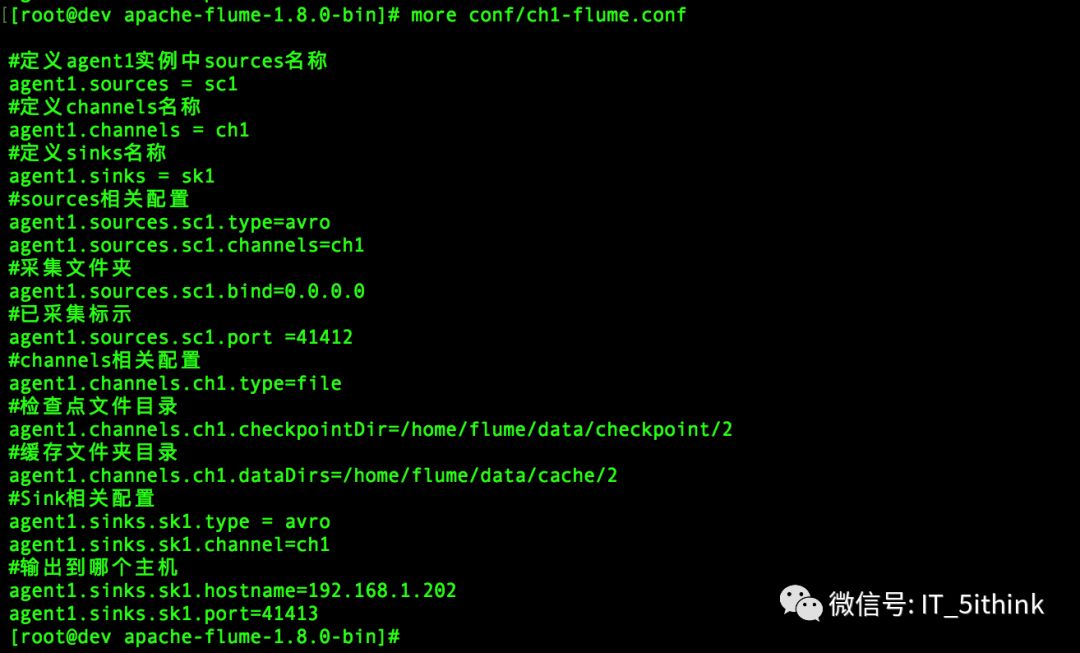
vi conf/sk1-flume.conf
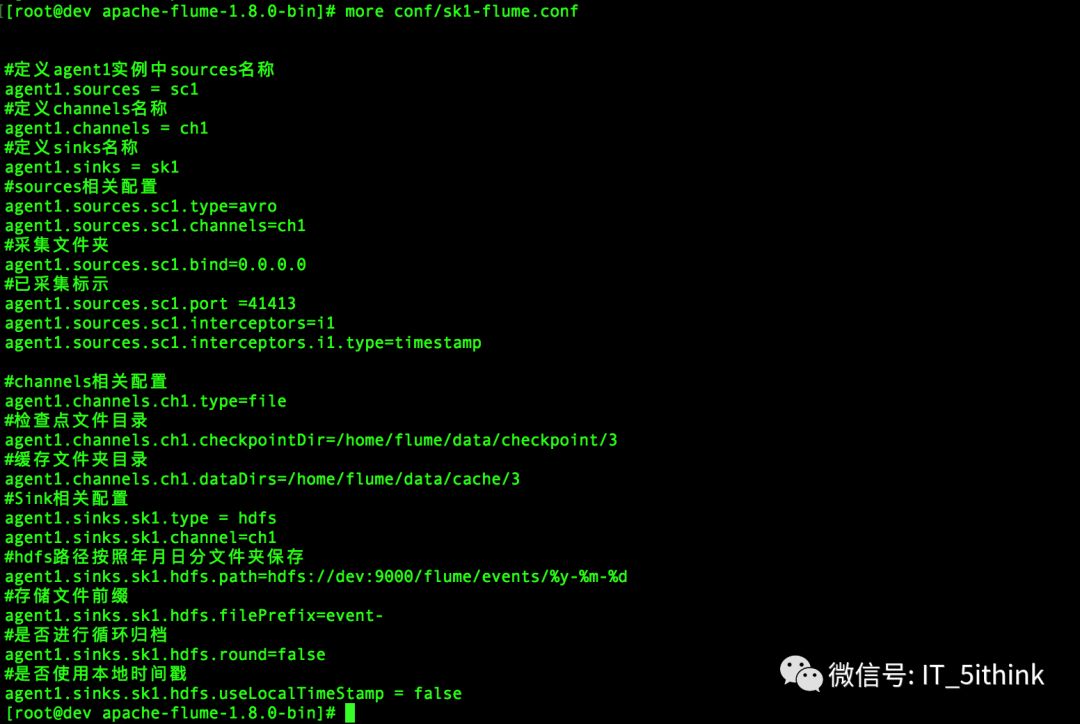
3.hadoop安装配置
参考
4.启动hadoop
a.切换用户
cd /home/hadoop3/modules/hadoop-3.0.0/bin
su hadoop
启动namenode:./hdfs --daemon start namenode
启动datanode:./hdfs --daemon start datanode
启动nodemanager:./yarn --daemon start nodemanager
启动resourcemanager:./yarn --daemon start resourcemanager
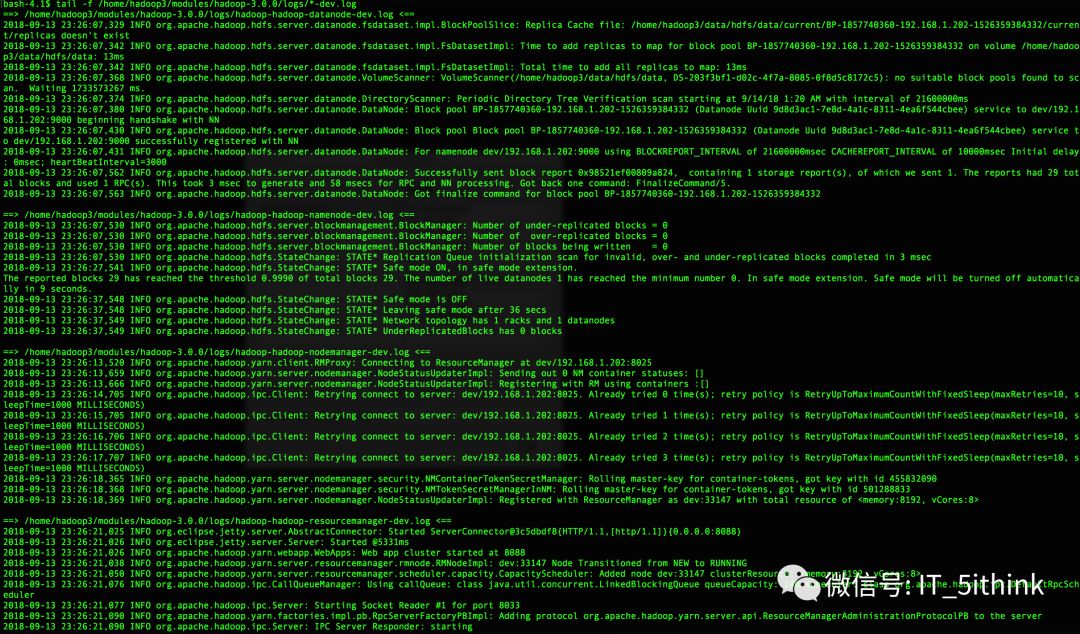
b.查看启动日志
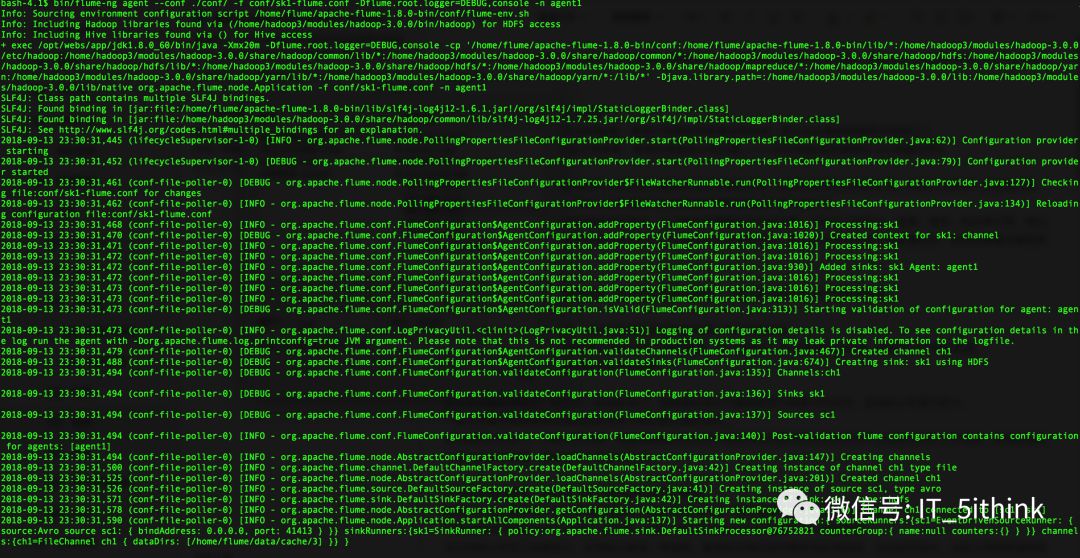
5.启动Sink Agent
a.文件目录操作权限设置
cd /home/flume/data
chmod -R o+rw ./*
b.以hadoop用户启动sink agent
su hadoop
bin/flume-ng agent --conf ./conf/ -f conf/sk1-flume.conf -Dflume.root.logger=DEBUG,console -n agent1
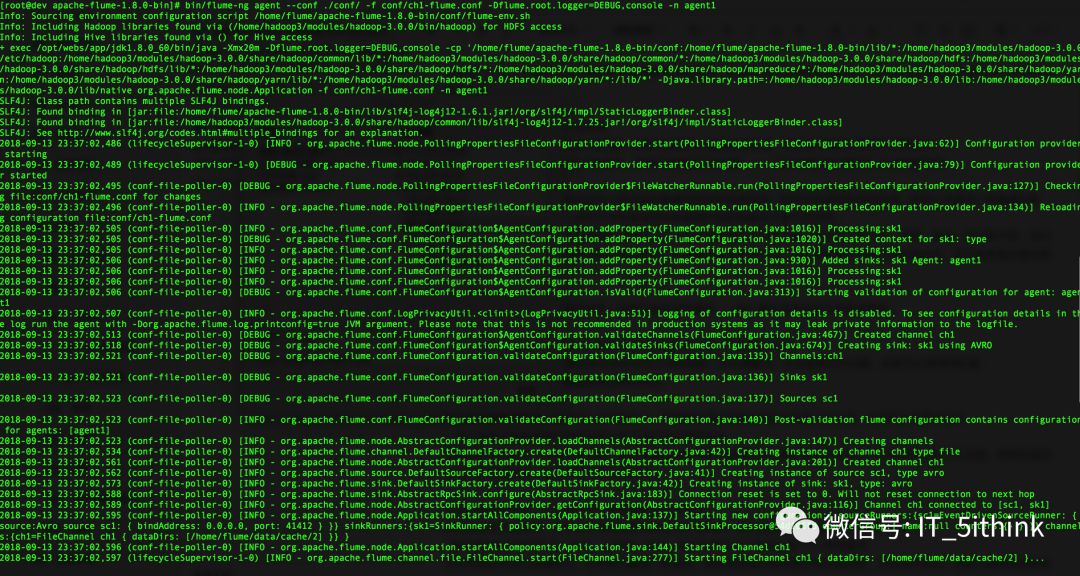
6.启动Channel Agent
bin/flume-ng agent --conf ./conf/ -f conf/ch1-flume.conf -Dflume.root.logger=DEBUG,console -n agent1
7.启动Source Agent
bin/flume-ng agent --conf ./conf/ -f conf/sk1-flume.conf -Dflume.root.logger=DEBUG,console -n agent1
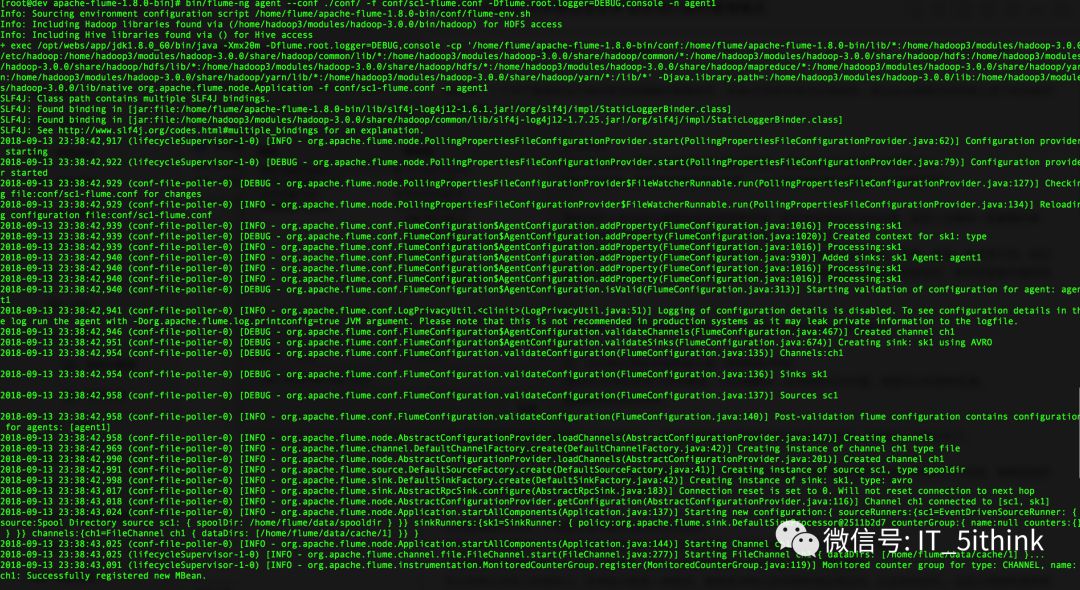
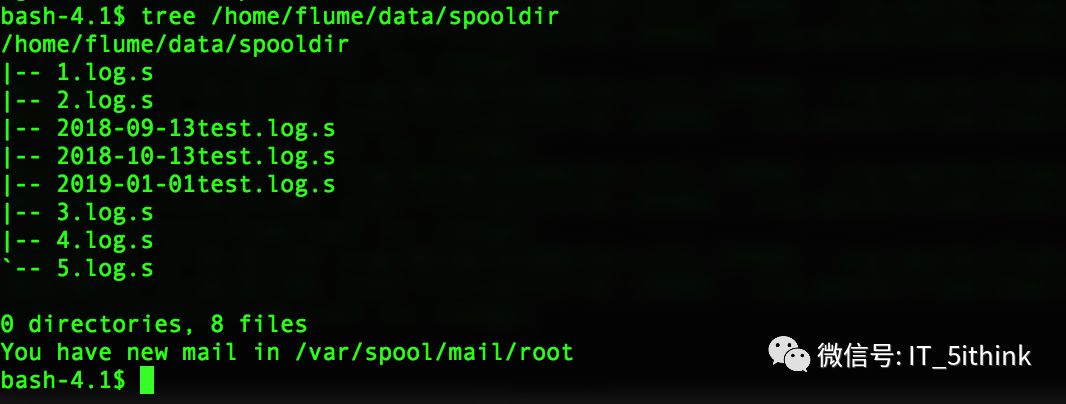
8.写文件
cd /home/flume/data/spooldir
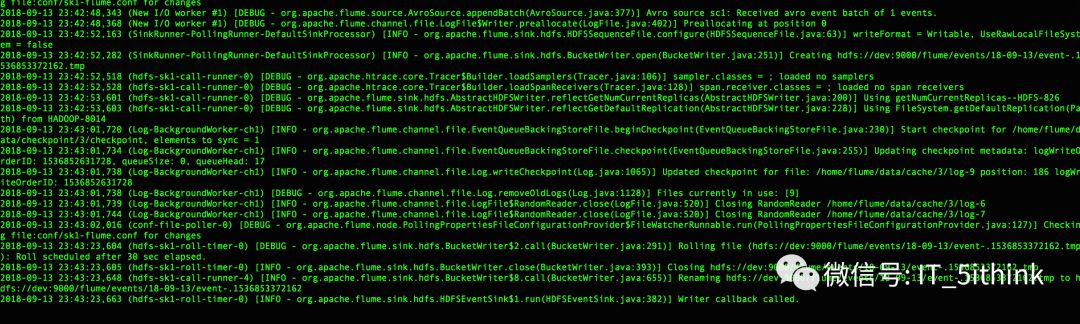
9.观察Sink Agent日志
10.验证数据写入hdfs
参考连接:
http://flume.apache.org/FlumeUserGuide.html#
http://flume.apache.org/download.html
https://cwiki.apache.org//confluence/display/FLUME/Getting+Started
以上是关于实践篇 |Apache Flume的主要内容,如果未能解决你的问题,请参考以下文章