扩展Apache Kylin流数据源以对接阿里云LogHub的实践
Posted apachekylin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了扩展Apache Kylin流数据源以对接阿里云LogHub的实践相关的知识,希望对你有一定的参考价值。

前言
Apache Kylin 从1.6开始支持流式数据作为数据源,可以直接消费 Apache Kafka 的数据进行 Cube 构建,从而实现了在流数据上的近实时亚秒级 SQL 分析。
Apache Kafka 是一种高吞吐量的分布式发布订阅消息系统,被广泛用于构建流式数据平台。然而使用 Kafka 的话,用户需要自己搭建和运维 Kafka 集群。为了便于用户使用,各大公有云平台都针对流式数据推出了免运维的流数据服务,例如AWS_Kinesis,Azure_EventHub 以及阿里云 LogHub。
阿里云 LogHub 是阿里云日志服务下的一个实时采集和消费功能。通过 ECS、容器、移动端,开源软件,JS 等接入实时日志数据(例如 Metric、Event、BinLog、TextLog、Click 等),以及提供实时消费接口,与实时计算及服务对接。此外还提供包括数据清洗(ETL),流计算(Stream Compute),监控与报警,机器学习与迭代计算的功能。LogHub 对比 Apache Kafka 对比具有使用成本低,稳定性高,安全性强等优势,已经广泛应用于阿里巴巴集团的大数据场景。
Apache Kylin 的数据源接口是可以扩展的,这为对接其它数据源提供了可能。本文将介绍如何基于 Apache Kylin 对接阿里云的 LogHub 数据源,从而达到大数据的近实时分析。
Apache Kylin 流式构建简介
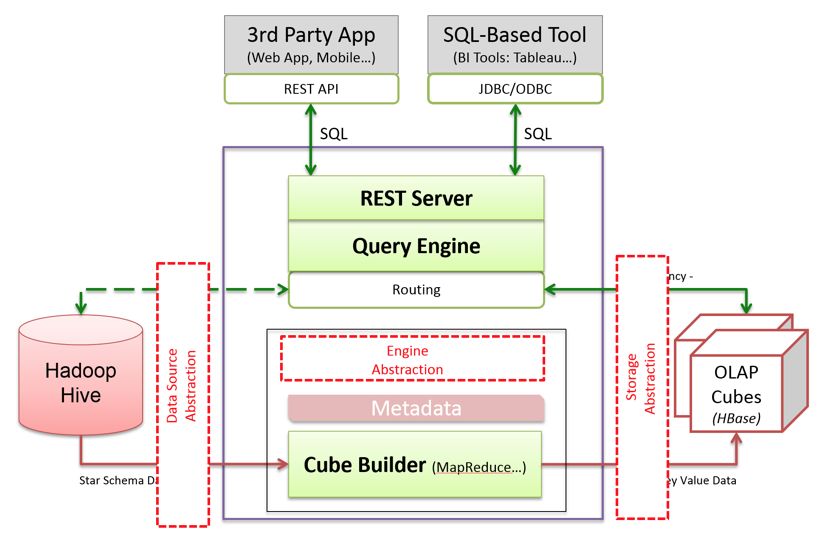
受益于 Apache Kylin 1.5 引入的可插拔架构,Kylin 对接新的数据源的难度大大降低。以下是 Apache Kylin 的可插架构图。
下面是 Apache Kylin 对接 Apache Kafka 的伪代码逻辑图。
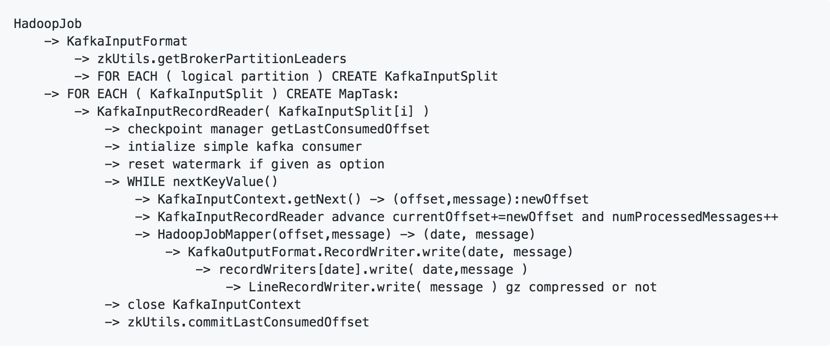
可点击放大查看
Apache Kylin 对应于 Kafka 的每个 partition 分配一个 mapper,每个 mapper 通过 Kafka 的客户端读取对应的 partition 上的 offset 范围的消息进行读取,将信息通过解析器解析成行,并以 sequence file 格式写入 HDFS,用于后续的构建。
可以看到,整个流程是无状态、可反复执行的。当切换另一个数据源的时候,可以依照这个框架简单重写。
如何对接 LogHub
LogHub 服务与 Kafka 类似,但是无需用户运维底层平台。用户只需要使用 API 写入和消费数据即可。在对接过程中,我们主要解决了以下几个问题。
如何并行化消费LogHub消息
InputFormat是Hadoop 类库的一个接口,主要是确定分片的策略(getSplits)和得到读取数据的 RecordReader (getRecordReader),以便于 Hadoop 平台并行处理。在 Kafka 中有 partition 的概念,对应于 LogHub 为 shard,于是我们可以使用 shardId 来对 LogHub 的数据进行并行式处理。对于分片,需要传入以下几个参数。
 可点击放大查看
可点击放大查看
这里输入的不仅仅有用于定位的 brokers,logstore 和 shard,还有用于读信息所用的 timeInSec,它对应于 Kafka 的 offset。
RecordReader:根据LogHub提供的API以及相应的分片中的信息读取日志。
如何增量消费LogHub消息
ISource 是 Kylin 中每个数据源必须实现的接口。对于流式数据源,如何做到记录数据的位置以及保持数据的一致性,是通过实现 ISource 的 enrichSourcePartitionBeforeBuild 方法决定的。对于 Kafka,构建完成的Cube需要记录每个partition的offset,下一次构建的依据来自所记录的offset。对于LogHub,没有 offset 的概念,但是有时间戳 timeInSec 的概念与之相对应,可以起到相同的作用。
以下是 enrichSourcePartitionBeforeBuild 方法的部分代码。
可点击放大查看
如何解析LogHub消息
Kafka 里通常使用 JSON 文件格式进行传输,而 LogHub 日志服务大部分都是以 CSV 格式进行记录。于是需要继承抽象类 StreamingParser 新建一个针对 CSV 格式进行解析的 CSVStreamingParser,解析后的结果作为 MapReduce 的 doMap 后的 value。需要注意的是,CSV 格式的流式数据没有所对应的列名,需要用户手动传入,成为以下代码中的 headers。
可点击放大查看
总结
Apache Kylin 的可插拔架构,使得我们可以很方便地扩展新的数据源,比如对接阿里云 LogHub,我们可以实现实时流式数据的接入,通过 Cube 构建加速大数据查询,与历史数据完整结合,实现大数据的近实时分析,助力数据分析师更快获得数据洞察。
"Apache and Apache Kylin are either registered trademarks or trademarks of The Apache Software Foundation in the US and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks."
作者简介
金荣钏,2018年本科毕业于上海大学计算机学院,现就职于 Kyligence 云团队担任软件工程师。
反馈
如果您遇到问题或疑问,请发送邮件至 Apache Kylin dev 或 user 邮件列表:dev@kylin.apache.org;user @kylin.apache.org
在发送之前,请确保您已通过发送电子邮件至:
dev-subscribe@kylin.apache.org
user-subscribe@kylin.apache.org 订阅了邮件列表。
以上是关于扩展Apache Kylin流数据源以对接阿里云LogHub的实践的主要内容,如果未能解决你的问题,请参考以下文章