开源流量分析系统 Apache Spot 概述
Posted 绿盟科技研究通讯
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源流量分析系统 Apache Spot 概述相关的知识,希望对你有一定的参考价值。
Apache Spot 是一个基于网络流量和数据包分析,通过独特的机器学习方法,发现潜在安全威胁和未知网络攻击能力的开源方案。目前 Apache Spot 已支持对 Netflow、sflow、DNS、Proxy 的网络流量分析,主要依靠 HDFS、Hive 提供存储能力,Spark 提供计算能力,基于 LDA 算法提供无监督式机器学习能力,最终依赖 Jupyter 提供图形化交互能力。
该项目由 Intel 和 Cloudera 向 Apache 基金会贡献,目前尚处于孵化阶段,最新发布版本为 Apache Spot 1.0。
Apache Spot 采集的数据包括网络流量、DNS 和 Proxy 数据包,其中网络流量又划分为外部流量(Perimeter Flows)和内部流量(Internal Flows)。利用这些数据可以做到:
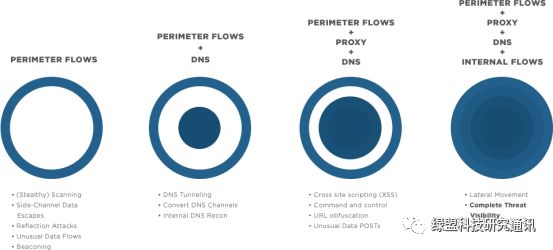
外部流量
隐蔽扫描识别 Stealthy Scanning
旁路攻击检测 Side-Channel Data Escapes
反射攻击检测 Reflection Attacks
异常数据流发现 Unusual Data Flows
信标行为发现 Beaconing
外部流量 + DNS
DNS隧道检测 DNS Tunneling
DNS隐蔽信道识别 Convert DNS Channels
内部DNS探测 Internal DNS Recon
外部流量 + DNS + Proxy
跨站脚本攻击检测 Cross site scripting(XSS)
C&C主机发现 Command and Control
URL混淆检测 URL obfuscation
异常的POST数据发现 Unusual Data POSTs
外部流量 + DNS + Proxy + 内部流量
横向移动检测 Lateral Movement
完整的威胁可见性 Complete Threat Visibility
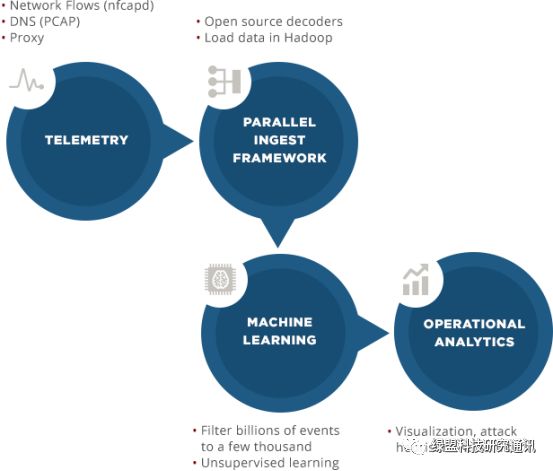
Apache Spot 利用开源且被优化过的解码器接入二进制网络流量数据和数据包,利用机器学习的方法(主要是 LDA 算法)从网络流量中分离出可疑流量,以及特征化独特的网络流量行为。经过上下文增强、噪声过滤、白名单和启发式算法等等一系列手段,最终产生少量且准确的安全威胁事件呈现给用户。
识别可疑DNS数据包 (Suspicious DNS Packets)
利用深度包检测技术(Deep-packet Inspection)对DNS流量进行画像,经过可视化、正则化以及模式匹配处理,向安全分析师呈现出DNS流量数据中最有可能是威胁的部分。
威胁应急响应 (Threat Incident and Response)
可疑网络连接发现 (Suspicious Connects)
通过机器学习的方法对在网络上进行通信的机器及其通信模式建立相应的模型,数十条原始数据在经过一系列处理后,仅剩余几百条,这些剩余的数据就是最有可能是威胁的部分。
故事板(Storyboard)
安全分析师对威胁事件完成调查后,可以通过故事板去表现事件的来龙去脉,也就是说在故事板中,我们可以了解到攻击者是什么时候攻入系统的?都拿下了哪些机器?怎么拿下的?
开放数据模型 (Open Data Models)
为了让威胁检测模型的开发过程更加简单高效,保证个人、企业、社区输出的检测模型的兼容性,Apache Spot 对网络、终端、用户等相关数据进行了标准化定义,规范了这些数据在逻辑层以及物理层的形态。简而言之,开放数据模型保障了不同的开发者在用同一种“语言”在进行威胁检测模型的开发。
协作 (Collaboration)
Apache Spot 平台运行于Hadoop大数据平台之上,通过其定义的开放数据模型,使得个人、企业、社区开发者的产出可以无缝衔接。正如攻击者可以利用其它攻击者制作的攻击工具一样,防护方也能够使用其它防护者制作的防护工具。
1系统架构
Apache Spot项目使用Hadoop大数据生态的各种组件构建其数据分析平台。从数据采集、预处理到存储,从数据分析、结果呈现到交互操作,还集成了大量的开源软件来构建平台的能力。
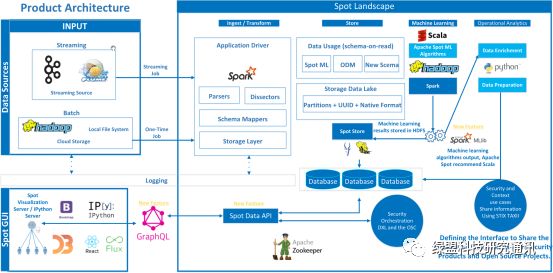
2组件视图
spot-setup 系统配置、初始化
spot-ingest 数据采集
spot-ml 机器学习数据分析
spot-oa 用户交互界面
3数据流视图
下图详细呈现了Apache Spot整个平台的主要数据流,数据从数据源(左上)起始,先经过数据采集器进行解析处理,而后由流式处理组件完成入库,存储到HDFS中。之后,机器学习组件负责对数据进行分析计算,并将计算结果入库存储。分析结果最终通过用户界面呈现出来(右下)。
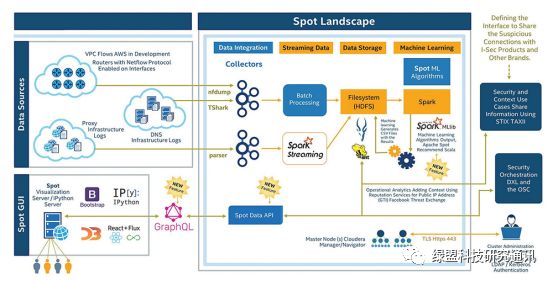
4服务视图
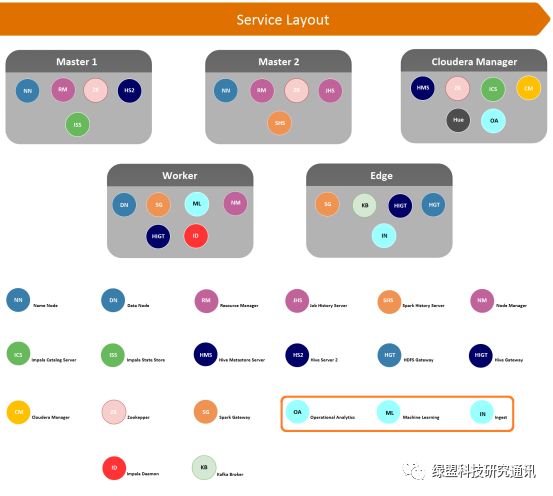
上图是Apache Spot推荐的集群部署下,各个节点上部署的服务。其中:
Master 节点作为大数据平台的主节点,主要负责提供数据存储、检索及资源管理服务;
Cloudera Manager节点作为大数据平台的管理节点,也是Apache Spot平台的管理入口;
Worker 节点作为大数据平台的计算节点,主要负责提供数据分析能力;
Edge 节点作为大数据平台的数据采集节点,主要负责从网络环境中采集数据。
1配置组件 Spot-Setup
Spot-Setup 包含一系列脚本,分别用于初始化系统 HDFS 中的文件路径和 Hive 数据表结构,以及初始化系统配置。
2数据采集组件 Spot-Ingest
>>>>
2.1 架构视图

2.2 内部模块
Spot-Collector
该模块负责在后台监控文件系统指定路径下,由网络工具产生的新文件,或者先前产生的已有数据文件,通过指定解析工具(如nfdump,tshark)转换为可读格式,并以原始格式存储到 HDFS 用于取证,以 avro-parquet 格式存储到 Hive 中以做 SQL 检索。
其中:
文件 > 1MB 的将文件名称和在HDFS中的存储路径交给kafka;
文件 < 1MB 的将其 Data Event 交给 Kafka,之后由 Spark Streaming处理(当前版本中仅 Proxy 数据由 Spark Streaming 处理)。
Kafka
Kafka 负责存储由 Collector 采集到的数据,以供 Spot Workers 解析处理。每个数据采集实例都会创建一个新的 Topic,当前版本包含三个采集实例,分别是 Flow, DNS, Proxy。每个 Topic 的 Partition 数量取决于 Spot Worker 的数量。
Spot Workers
Sport Worker 运行在后台,从指定的 Topic 的 Partitions, 以及 Hive 表中读取、解析数据,并将结果存储到 Hive 中,以供 Spot-ml 组件读取消费。
当前版本中存在两种类型的 Spot Worker:
A:Python 多线程实现,通过预置的解析器处理数据;
B:Spark-Streaming Workers 实现,通过 Spark-Streaming Context 从 kafka 中读取并处理数据。
3机器学习组件 Spot-ML
4交互组件 Spot-OA
Spot-OA 基于 IPython、D3JS、jQuery、Bootstrap、ReactJS技术向用户提供数据处理、转换以及数据可视化的能力。当前版本主要通过 Suspicious、Threat Investigation、Story Board 三个视图页面提供针对 Flow、DNS、Proxy 事件的可视化分析能力。此外,通过 Ingest Summary Notebook 视图页面,提供了解指定时间段内数据采集情况的能力。
4.1 Suspicious 简介
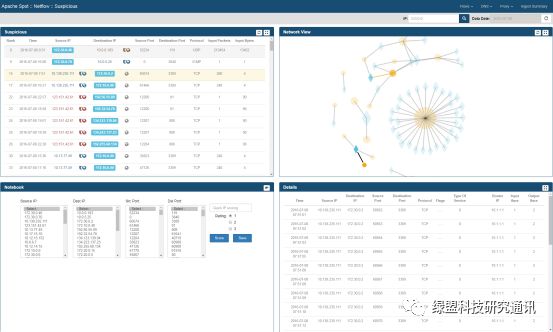
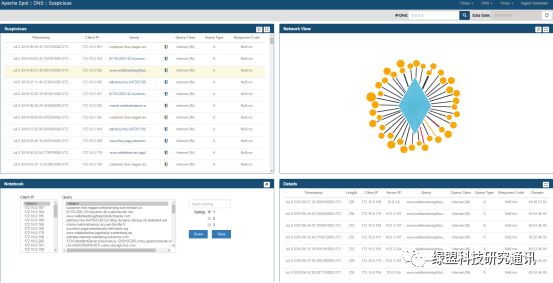
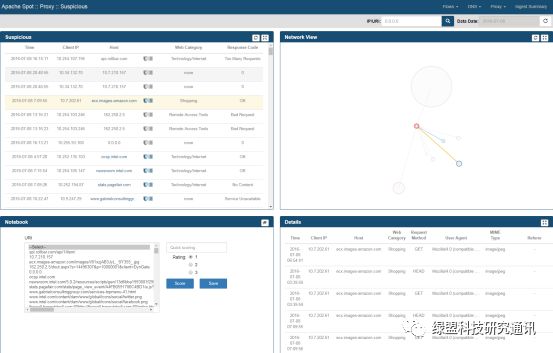
Suspicious 视图页面用于呈现 Spot-ML 发现的可疑活动,主要由四个面板组成。
Suspicious 面板以数据列表的形式展现 Spot-ML 发现的可疑活动;Network View 面板以可视化的形式表现这些可疑活动;Details 面板用于挖掘某个可疑活动更为细节的信息。Notebook 面板提供一种专家能力,通过人为介入的方式修正或改善机器学习模型。
Netflow Suspicious:
DNS Suspicious:
Proxy Suspicious:
4.2 Threat Investigation 简介
Threat Investigation 视图页面是分析结果展示在 Storyboard 之前的最后一步,安全分析师在这个页面对即将展示的分析结果进行最后一步核查。
4.3 Storyboard 简介
Storyboard 视图页面用于呈现系统最终的分析结果,供用户掌握高风险的安全威胁事件以及更进一步的信息。
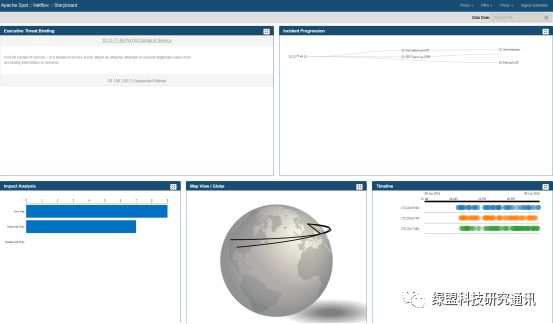
Netflow Story Board:
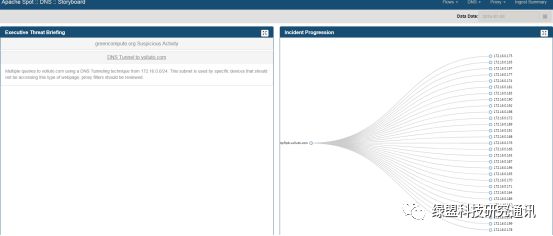
DNS Story Board:
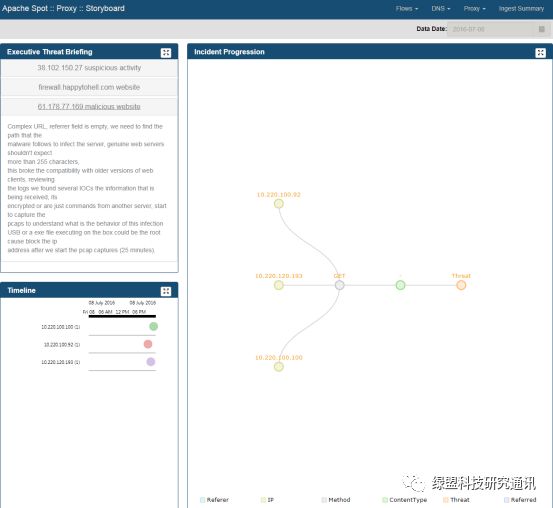
Proxy Story Board:
4.4 Ingest Summary 简介
Ingest Summary 用于了解系统的数据采集情况,可以查看采集的数据类型在指定时间段的数据量分布详情。
1基础环境
CDH 5.7+
Spark 2.1.0
YARN
Hive
IMPALA
KAFKA
SPARK(YARN)
Zookeeper
2Docker 部署
下载镜像:
> docker pull apachespot/spot-demo
启动镜像:
> docker run -it -p 8889:8889 apachespot/spot-demo
http://localhost:8889/files/ui/flow/suspicious.html#date=2016-07-08
3单机部署
Apache Spot 项目 1.0 版本的成熟度还比较低,部署过程中需要人工安装、编译、配置若干基础组件,才能保证 Spot 组件的正常运行。又因为 Spot 当前的说明文档不够完善,对依赖的组件版本缺乏明确的说明,导致在部署过程中会浪费一些时间。
部署安装的大致流程为:
1. Hadoop 大数据环境部署
2. Spot-setup 初始化配置
3. Spot-Ingest 组件配置数据采集
4. Spot-Ml 组件编译、部署
5. Spot-OA 组件构建、部署
4集群部署
Apache Spot 各组件推荐部署位置,结合 5.4 服务视图查看:
Component |
Node |
spot-setup |
Edge Server (Gateway) |
spot-ingest |
Edge Server (Gateway) |
spot-ml |
YARN Node Manager |
spot-oa |
Node with Cloudera Manager |
1Proxy 数据采集
将 Spot-Ingest 组件部署到 Proxy 服务器上,通过编辑数据采集组件配置文件($SPOT_INGEST_HOME/ingest_conf.json)指定待采集 Proxy 服务器的日志路径来完成 Proxy 数据的采集。
2Flow 数据采集
Spot-Ingest 依赖 spot-nfdump 解析流量数据包,可通过 nfdump 工具包中的 nfcapd 将接受 netflow 数据并保存到指定的文件。
nfcapd 接收流量的方式示例:
> nfcapd -b 0.0.0.0 -p 515 -4 -t 60 -w -D -l /data/spot/flow
3DNS 数据采集
Spot-Ingest 依赖 tshark 解析 DNS 数据包。
使用 tshark 抓取 DNS 数据包保存为 pcap 文件示例:
> tshark -i em1 -b filesize:2 -w dns-dump.pcap udp port 53
使用 tcpdump 抓取 DNS 数据包保存为 pcap 文件示例:
> tcpdump -i eth1 -nt udp dst port 53 -s 0 -G 5 -w "dns-dump_%Y%m%d%H%M%S".pcap -Z root
参考链接:
[1] Apache Spot Homepage (https://spot. apache.org/)
[2] Apache Spot Docker Homepage(https://hub. docker. com/r/apachespot/spot-demo/)
[3] Apache Spot Open Data Model 1(https://spot. incubator.apache.org/project-components/open-data-models/)
[4] Apache Spot Open Data model 2(https://github. com/apache/incubator-spot/blob/SPOT-181_ODM/docs/open-data-model.md)
[5] Splunk Common Information Model(http ://docs.splunk.com/ Documentation /CIM/ latest/ User/Overview)
内容编辑:绿盟科技 潘钧康 责任编辑:肖晴
往期回顾
关于我们
绿盟科技研究通讯由绿盟科技创新中心负责运营,绿盟科技创新中心是绿盟科技的前沿技术研究部门。包括云安全实验室、安全大数据分析实验室和物联网安全实验室。团队成员由来自清华、北大、哈工大、中科院、北邮等多所重点院校的博士和硕士组成。
绿盟科技创新中心作为“中关村科技园区海淀园博士后工作站分站”的重要培养单位之一,与清华大学进行博士后联合培养,科研成果已涵盖各类国家课题项目、国家专利、国家标准、高水平学术论文、出版专业书籍等。
我们持续探索信息安全领域的前沿学术方向,从实践出发,结合公司资源和先进技术,实现概念级的原型系统,进而交付产品线孵化产品并创造巨大的经济价值。
以上是关于开源流量分析系统 Apache Spot 概述的主要内容,如果未能解决你的问题,请参考以下文章
大数据综合项目--网站流量日志数据分析系统(详细步骤和代码)