LF DL的Horovod项目增加了对PySpark和Apache MXNet的支持以及其他功能,以加快培训速度
Posted LFAPAC
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LF DL的Horovod项目增加了对PySpark和Apache MXNet的支持以及其他功能,以加快培训速度相关的知识,希望对你有一定的参考价值。
摘录:Horovod在最新版本中支持更多框架,并引入了新功能以提高通用性和生产力。
Horovod是由Uber创建的分布式深度学习框架,它使分布式深度学习变得快速,且易于使用。Horovod使用TensorFlow、Keras、PyTorch和Apache MXNet改进训练机器学习(ML)模型的速度、规模和资源分配。LF Deep Learning是支持和维持人工智能和机器学习开源创新的Linux基金会项目,于2018年12月接受了Horovod作为其托管项目之一。该项目被托管以后,Uber以外的额外贡献和协作由于LF DL的中立环境、开放式治理和基金会为项目提供的一系列推动因素而出现。
最新版本中的更新以三个关键方式改进了Horovod:为更多框架添加支持和集成,改进现有功能,以及为TensorFlow 2.0带来的变化准备。综合起来,这些新功能和能力使Horovod更容易、更快速、更灵活、适用于不断增长的用户群,包括NVIDIA和Oak Ridge National Laboratory。Horovod还与各种深度学习生态系统集成,包括AWS、Google、Azure和IBM Watson。
在此版本中,添加了许多用于Horovod的新用例,目的是使框架成为培训深度学习模型的更通用工具。随着集成和支持框架的增加,用户可以利用Horovod加速大量开源模型,并在多个框架中使用相同的技术。
PySpark和Petastorm的支持
Apache Spark能够处理大量数据,可用于许多机器学习环境。易用性、内存处理功能、近实时分析以及丰富的集成选项,如Spark MLlib和Spark SQL,使Spark成为一种受欢迎的选择。
鉴于其可扩展性和易用性,Horovod得到了更广泛的基于Python的机器学习社区的兴趣,包括Apache Spark。随着PySpark支持和集成的发布,Horovod对更广泛的用户变得有用。
在Horovod之前,PySpark的典型工作流程,是在PySpark中进行数据准备,将结果保存在中间存储中,使用不同的群集解决方案运行不同的深度学习培训工作,导出训练的模型,并在PySpark中运行评估。Horovod与PySpark的集成允许在同一环境中执行所有这些步骤。
为了平滑Spark集群中PySpark和Horovod之间的数据传输,Horovod依赖于Petastorm,这是一个由Uber Advanced Technologies Group(ATG)开发的深度学习开源数据访问库。Petastorm于2018年9月开源,可直接从多TB数据集,进行单机或分布式培训,以及深度学习模型的评估。
典型的Petastorm用例需要在PySpark中预处理数据,将其写入Apache Parquet中的存储,这是一种高效的列式存储格式,并使用Petastorm读取TensorFlow或PyTorch中的数据。
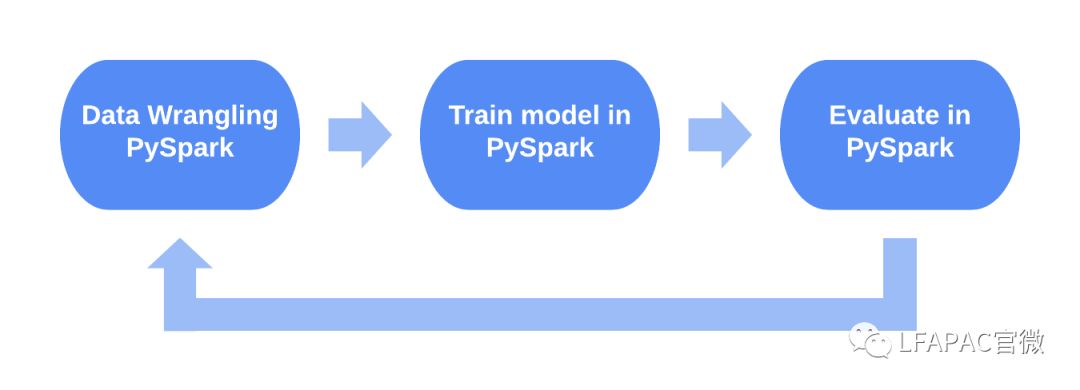
Apache Spark和Petastorm也在Uber内部的某些应用程序中使用,因此扩展Horovod对PySpark和Petastorm的支持一直是使Horovod成为更多通用工具的过程中的自然步骤。
Apache MXNet的支持
Apache MXNet(孵化)是一个开源深度学习框架,可以促进更灵活、更有效的神经网络培训。亚马逊是Horovod和MXNet的重要贡献者,并且在Amazon EC2 P3实例和Amazon SageMaker上原生支持这两个框架。
就像最近对PySpark的支持一样,Horovod与MXNet的整合是将Horovod提供给更广泛社区的更大努力的一部分,进一步扩大了对更快更轻松的模型培训。
自动调节
最新版本的第三次更新是Horovod推出自动调节的alpha版本。在此版本中,自动调整是可选的,但在将来的版本中它将默认打开。
Horovod支持许多内部参数,可以调整这些参数以提高硬件和模型架构变化的性能。这些参数包括融合缓冲门槛
(fusion buffer threshold),用于确定可以将多个张量(tensor)一起批量合并为单个allreduce、用于控制allreduce批次的频率的循环时间、以及当主机数量变得非常大时,作为单环allreduce的替代方案的分层allreduce 。
找到这些参数的正确值,可以使性能提高多达30%。但是,手动尝试不同的参数是一种耗时的反复试验。
Horovod的自动调节系统,通过使用贝叶斯(Bayesian),优化动态探索和选择最佳内部参数值来消除猜测。
自动调节会自动化手动过程,执行尝试不同选项和参数值,以确定最佳配置,如果硬件、比例或模型发生变化,必须重复这些配置。由于自动化,自动调节使参数优化更有效,可以加快模型培训速度。
嵌入的改进
嵌入通常用于涉及自然语言处理(NLP)和从表格(tabular)数据学习的机器学习用例。在Uber的数据存储区,Uber旅程数据存储为表格数据,这些数据具有一些分类界限。在像Uber这样的用例中,嵌入的数量和嵌入的大小将会扩展。在最新版本中,Horovod增强了其扩展深度学习模型的能力,这些模型大量使用嵌入式设备,例如Transformer和BERT。
此外,这些嵌入改进更快地促进了大嵌入梯度(gradient),以及小嵌入梯度的融合,允许更多数量的嵌入更快地处理操作。
TensorFlow的热切执行支持
热切执行(Eager execution)将是TensorFlow 2.0中的默认模式。热切执行允许开发者在命令式编程环境中创建模型,其中立即评估操作,并将结果作为实际值返回。热切执行消除了创建会话(session)和使用图形的需要。
凭借对动态模型的热切执行支持,模型评估和调试变得更加容易和快捷。对于缺乏经验的开发者而言,热切执行也使得TensorFlow更直观。
在过去,运行Horovod的热切执行,意味着按顺序计算所有工人(worker)的每个张量梯度(tensor gradient),没有任何张量批处理或并行性。在最新版本中,完全支持热切执行。在我们的实验中,使用热切执行的Tensor批处理,可将性能提高6倍以上。此外,用户现在可以使用TensorFlow的GradientTape的分布式实现来记录自动区分(differentiation)操作。
混合精确训练
混合精度是在计算方法中组合使用不同的数值精度。使用低于FP32的精度,可以通过使用更小的张量来减少内存需求,从而允许部署更大的网络。此外,数据传输花费的时间更少,计算性能也大幅提升。具有Tensor Core的GPU支持混合精度,使用户能够充分利用更低内存使用率和更快数据传输的优势。
深度神经网络的混合精确训练实现了两个主要目标:
减少所需的内存量,支持更大型号的培训或使用更大的小批量培训
通过使用低精度算法减少所需资源,缩短训练或推理时间
在过去,混合精确训练通常打断Horovod的融合逻辑,因为FP16张量的序列将经常被FP32张量打断,并且不同精度的张量不能参与单个融合事务。
在最新版本中,NVIDIA对张量融合逻辑做出了改进,允许FP16和FP32张量序列通过前瞻机制独立处理。通过这种变化,我们已经看到高达26%的性能提升。
想知道Horovod如何让你的模型训练更快,更具可扩展性?查看这些更新,并亲自试用该框架,并确保加入Deep Learning Foundation的Horovod公告和技术讨论邮件列表。
点击文末<<阅读原文>>进入网页了解更多。

大会日期:
会议日程通告日期:2019 年 4 月 10 日
会议活动举办日期:2019 年 6 月 24 至 26 日
官方注册现已开通,早鸟票(1月28日 - 5月2日)票价如下:
标准注册:1500人民币(晚注册2400,即时可省900!)
贵宾注册:3750人民币(晚注册6000,即时可省2250!)
个人或学术注册:375人民币(需要发送电子邮件至events@cncf.io申请批准。晚注册600,即时可省225!)
扫描二维码到购票窗口,立即购票!
Linux基金会是非营利性组织,是技术生态系统的重要组成部分。
Linux基金会通过提供财务和智力资源、基础设施、服务、活动以及培训来支持创建永续开源生态系统。在共享技术的创建中,Linux基金会及其项目通过共同努力形成了非凡成功的投资。请长按以下二维码进行关注。
以上是关于LF DL的Horovod项目增加了对PySpark和Apache MXNet的支持以及其他功能,以加快培训速度的主要内容,如果未能解决你的问题,请参考以下文章