实时构建:Apache Kafka的大数据消息传递,Part 2
Posted 猿问
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时构建:Apache Kafka的大数据消息传递,Part 2相关的知识,希望对你有一定的参考价值。
在介绍Apache Kafka的前半部分中,您使用Kafka开发了两个小规模的生产者/消费者应用程序。通过这些练习,您应该熟悉Apache Kafka消息传递系统的基础知识。在本部分中,您将学习如何使用分区来水平分布负载和伸缩应用程序,每天最多处理数百万条消息。您还将了解Kafka如何使用消息偏移量来跟踪和管理复杂的消息处理,以及如何保护您的Apache Kafka消息传递系统在用户宕机时不会发生故障。
Apache Kafka的分区
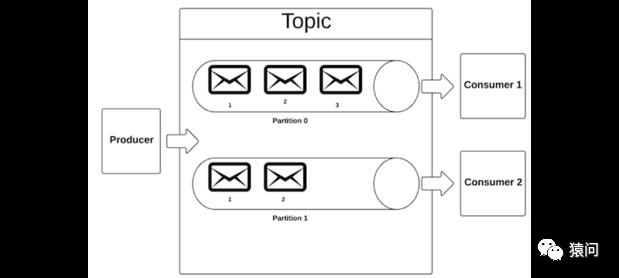
Kafka中的主题可以细分为多个分区。例如,在创建名为Demo的主题时,可以将其配置为三个分区。服务器将创建三个日志文件,每个日志文件对应一个演示分区。当生产者向主题发布消息时,它将为该消息分配分区ID。然后,服务器将仅将消息追加到该分区的日志文件中。
如果随后启动两个使用者,服务器可能将分区1和2分配给第一个使用者,将分区3分配给第二个使用者。每个使用者只能从其分配的分区中读取数据。您可以在图1中看到为三个分区配置的演示主题。
Figure 1.Apache Kafka中的分区的主题
要扩展此场景,请想像一个Kafka集群,其中有两个代理,驻留在两台机器中。在对演示主题进行分区时,需要将其配置为具有两个分区和两个副本。对于这种类型的配置,Kafka服务器将把这两个分区分配给集群中的两个代理。每个代理将是其中一个分区的领导者。
当生产者发布一条消息时,它将发送给分区负责人。leader将接收消息并将其附加到本地机器上的日志文件中。第二个代理将被动地将提交日志复制到它自己的机器上。如果分区领导出现故障,第二个代理将成为新的领导,并开始服务客户机请求。同样,当使用者向分区发送请求时,该请求将首先发送给分区负责人,后者将返回所请求的消息。
分区的好处
考虑基于kafka的消息系统分区的好处:
可伸缩性: 在只有一个分区的系统中,发布到主题的消息存储在单个机器上的日志文件中。主题的消息数量必须适合单个提交日志文件,存储的消息大小不能超过该机器的磁盘空间。对主题进行分区可以通过在集群中的不同机器上存储消息来扩展系统。例如,如果您想为演示主题存储30 GB (GB)的消息,您可以构建一个由三台机器组成的Kafka集群,每台机器有10 GB的磁盘空间。然后将主题配置为三个分区。.
服务器负载均衡: 拥有多个分区允许您跨代理传播消息请求。例如,如果主题每秒处理100万条消息,那么可以将其划分为100个分区,并向集群中添加100个代理。每个代理将是单个分区的领导者,负责每秒仅响应10,000个客户机请求。.
消费者负载均衡: 与服务器负载平衡类似,在不同的机器上托管多个使用者可以分散使用者负载。假设您希望从具有100个分区的主题每秒消费100万条消息。您可以创建100个消费者并并行运行它们。Kafka服务器将为每个使用者分配一个分区,每个使用者将并行处理10,000条消息。由于Kafka只将每个分区分配给一个使用者,所以在分区中,每个消息将按顺序被使用。.
2两种分区的方法
生产者负责决定消息将进入哪个分区。制作人有两个选项来控制这个分配:
自定义分区器: 您可以创建一个实现org.apache.kafka.clients.producer的类。分区程序界面。此自定义分区程序将实现业务逻辑来决定消息发送到何处.
DefaultPartitioner: 如果不创建自定义分区器类,则默认情况下将使用org.apache. kafca .client .producer.internal . defaultpartitionerclass。默认的分区器对于大多数情况已经足够好了,它提供了三个选项:
人工: 创建ProducerRecord时,使用重载的构造函数new ProducerRecord(topicName、partitionId、messageKey、message)指定分区ID.
哈希(局部敏感): 创建ProducerRecord时,通过调用new ProducerRecord(topicName、messageKey、message)指定messageKey。DefaultPartitioner将使用密钥的散列来确保相同密钥的所有消息都将发送到相同的生成器。这是最简单和最常见的方法.
分发(随机负载均衡): 如果您不想控制将消息发送到哪个分区,只需调用new ProducerRecord(topicName, message)来创建您的ProducerRecord。在这种情况下,分区程序将以循环的方式向所有分区发送消息,确保服务器负载平衡。
对Apache Kafka应用程序进行分区
对于第1部分中的简单生产者/消费者示例,我们使用了DefaultPartitioner。现在,我们将尝试创建一个自定义分区程序。对于这个例子,我们假设我们有一个零售站点,消费者可以使用它在世界任何地方订购产品。根据使用情况,我们知道大多数消费者不是在美国就是在印度。我们希望对我们的应用程序进行分割,以便将来自美国或印度的订单发送到它们各自的消费者,而来自其他任何地方的订单将发送到第三个合同。
首先,我们将创建一个CountryPartitioner,它实现org.apache.kafka.clients.producer。分区程序界面。我们必须实现以下方法:
当我们使用配置属性映射初始化Partitioner类时,Kafka将调用configure()。此方法初始化特定于应用程序的业务逻辑的函数,例如连接到数据库。在这种情况下,我们需要一个相当通用的分区器,它将countryName作为一个属性。然后我们可以使用configProperties.put(“partitions.0”,“USA”)将消息流映射到分区。将来我们可以使用这种格式来更改哪些国家拥有自己的分区n.
生产者API对每个消息调用partition()一次。在本例中,我们将使用它来读取消息并从消息中解析国家名称。如果国家的名称在countryToPartitionMap中,它将返回存储在地图中的partitionId。如果不是,它将对国家的值进行哈希,并使用它来计算应该去哪个分区.
我们调用close()关闭分区程序。使用此方法可确保在初始化过程中获取的任何资源在关机过程中得到清理.
注意,当Kafka调用configure()时,Kafka生成器将把我们为生成器配置的所有属性传递给Partitioner类。只读取那些以分区开头的属性是很重要的。,解析它们以获取partitionId,并将ID存储在countryToPartitionMap中.
下面是我们对Partitioner接口的自定义实现。
清单1. CountryPartitioner
public class CountryPartitioner implements Partitioner {
private static Map<String,Integer> countryToPartitionMap;
public void configure(Map<String, ?> configs) {
System.out.println("Inside CountryPartitioner.configure " + configs);
countryToPartitionMap = new HashMap<String, Integer>();
for(Map.Entry<String,?> entry: configs.entrySet()){
if(entry.getKey().startsWith("partitions.")){
String keyName = entry.getKey();
String value = (String)entry.getValue();
System.out.println( keyName.substring(11));
int paritionId = Integer.parseInt(keyName.substring(11));
countryToPartitionMap.put(value,paritionId);
}
}
}
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes,
Cluster cluster) {
List partitions = cluster.availablePartitionsForTopic(topic);
String valueStr = (String)value;
String countryName = ((String) value).split(":")[0];
if(countryToPartitionMap.containsKey(countryName)){
//If the country is mapped to particular partition return it
return countryToPartitionMap.get(countryName);
}else {
//If no country is mapped to particular partition distribute between remaining partitions
int noOfPartitions = cluster.topics().size();
return value.hashCode()%noOfPartitions + countryToPartitionMap.size() ;
}
}
public void close() {}
} 清单2(下面)中的Producer类与第1部分中的simple Producer非常相似,有两个更改用粗体标记:
我们设置一个配置属性,其键值等于ProducerConfig的值。PARTITIONER_CLASS_CONFIG,它匹配CountryPartitioner类的完全限定名。我们还设置countryNameto partitionId,从而映射要传递给CountryPartitioner的属性。我们传递一个实现org.apache.kafka.clients.producer的类的实例。回调接口作为product .send()方法的第二个参数。一旦消息成功发布,Kafka客户机将调用其onCompletion()方法,并附加一个RecordMetadata对象。我们将能够使用这个对象找出消息被发送到哪个分区,以及分配给发布消息的偏移量。
清单2. 1个分区的生产者
public class Producer {
private static Scanner in;
public static void main(String[] argv)throws Exception {
if (argv.length != 1) {
System.err.println("Please specify 1 parameters ");
System.exit(-1);
}
String topicName = argv[0];
in = new Scanner(System.in);
System.out.println("Enter message(type exit to quit)");
//Configure the Producer
Properties configProperties = new Properties();
configProperties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"localhost:9092");
configProperties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.ByteArraySerializer");
configProperties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer"); configProperties.put(ProducerConfig.PARTITIONER_CLASS_CONFIG,CountryPartitioner.class.getCanonicalName()); configProperties.put("partition.1","USA"); configProperties.put("partition.2","India");
org.apache.kafka.clients.producer.Producer producer = new KafkaProducer(configProperties);
String line = in.nextLine();
while(!line.equals("exit")) {
ProducerRecord<String, String> rec = new ProducerRecord<String, String>(topicName, null, line);
producer.send(rec, new Callback() { public void onCompletion(RecordMetadata metadata, Exception exception) { System.out.println("Message sent to topic ->" + metadata.topic()+ " ,parition->" + metadata.partition() +" stored at offset->" + metadata.offset()); ; } });
line = in.nextLine();
}
in.close();
producer.close();
}
}为消费者分配分区
Kafka服务器保证一个分区只分配给一个使用者,从而保证消息使用的顺序。您可以手动分配分区,也可以让它自动分配。
如果业务逻辑需要更多的控制,则需要手动分配分区。在这种情况下,您将使用KafkaConsumer.assign(<ListOfPartitions>)将每个消费者者感兴趣的分区列表传递给Kakfa服务器。
自动分配分区是默认和最常见的选择。在这种情况下,Kafka服务器将为每个消费者分配一个分区,并重新分配分区以适应新的消费者。
假设您正在创建一个包含三个分区的新主题。在启动新主题的第一个使用者时,Kafka将把所有三个分区分配给同一个消费者。如果随后启动第二个消费者,Kafka将重新分配所有分区,将一个分区分配给第一个消费者,其余两个分区分配给第二个消费者。如果添加第三个消费者,Kafka将再次重新分配分区,以便为每个消费者分配一个分区。最后,如果您启动第4和第5个消费者,那么其中3个消费者将拥有一个分配的分区,而其他消费者将不会接收任何消息。如果最初的三个分区中的一个出现故障,Kafka将使用相同的分区逻辑将该消费者的分区重新分配给另一个消费者。
我们将对示例应用程序使用自动分配。我们的大部分消费者代码将与第1部分中看到的简单消费者的代码相同。惟一的区别是,我们将把ConsumerRebalanceListener的实例作为第二个参数传递给KafkaConsumer.subscribe()方法。Kafka将在每次为这个消费者分配或撤销一个分区时调用这个类的方法。我们将覆盖ConsumerRebalanceListener的onpartitionsrevo()和onPartitionsAssigned()方法,并打印从该订阅服务器分配或撤销的分区列表。
清单 3. 1个分区的消费者
private static class ConsumerThread extends Thread {
private String topicName;
private String groupId;
private KafkaConsumer<String, String> kafkaConsumer;
public ConsumerThread(String topicName, String groupId) {
this.topicName = topicName;
this.groupId = groupId;
}
public void run() {
Properties configProperties = new Properties();
configProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
configProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
configProperties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
//Figure out where to start processing messages from
kafkaConsumer = new KafkaConsumer<String, String>(configProperties);
kafkaConsumer.subscribe(Arrays.asList(topicName), new ConsumerRebalanceListener() {
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.printf("%s topic-partitions are revoked from this consumer
", Arrays.toString(partitions.toArray()));
}
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.out.printf("%s topic-partitions are assigned to this consumer
", Arrays.toString(partitions.toArray()));
}
});
//Start processing messages
try {
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> record : records)
System.out.println(record.value());
}
} catch (WakeupException ex) {
System.out.println("Exception caught " + ex.getMessage());
} finally {
kafkaConsumer.close();
System.out.println("After closing KafkaConsumer");
}
}
public KafkaConsumer<String, String> getKafkaConsumer() {
return this.kafkaConsumer;
}
} 测试你的Apache Kafka应用程序
我们已经准备好运行和测试生产者/消费者应用程序的当前迭代。如前所述,您可以使用清单1到清单3中的代码,或者在GitHub上下载完整的源代码(https://github.com/sdpatil/KafkaAPIClient).
通过调用:mvn Compile assembly:single编译并创建fat JAR.
创建一个名为part-demo的主题,其中包含三个分区和一个复制因子:
<KAFKA_HOME>bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 3 --topic part-demo启动生产者:
java -cp target/KafkaAPIClient-1.0-SNAPSHOT-jar-with-dependencies.jar com.spnotes.kafka.partition.Producer part-demo启动三个使用者,然后在每次启动使用者的新实例时,观察控制台如何分配和撤销分区:
java -cp target/KafkaAPIClient-1.0-SNAPSHOT-jar-with-dependencies.jar com.spnotes.kafka.partition.Consumer part-demo group1在您的生产者控制台中键入一些消息,并验证这些消息是否路由到正确的使用者:
USA: First order India: First order USA: Second order France: First order
图2显示了分区主题中的生产者/消费者输出。
Figure 2. 生产者/消费者输出
管理消息偏移
我在第1部分中提到,每当生产者发布消息时,Kafka服务器都会为该消息分配一个偏移量。使用者可以通过设置或重置消息偏移量来控制要使用哪些消息。在开发使用者时,您有两个管理偏移量的选项:自动和手动。
2种偏移方式
当您在Kafka客户端中启动消费者时,它将读取您的ConsumerConfig.AUTO_OFFSET_RESET_CONFIG(auto.off .reset)配置的值。如果将该配置设置为最早,则消费者将从主题可用的最小偏移量开始。在对Kafka的第一个请求中,消费者会说:给我这个分区中的所有消息,其偏移量大于可用的最小值。它还将指定批处理大小。Kafka服务器将以指定大小的批次返回所有匹配的消息。.
消费者者跟踪它处理的最后一条消息的偏移量,因此它总是请求具有高于最后一条偏移量的消息。这种设置在使用者正常工作时有效,但是如果使用者崩溃,或者您想停止它进行维护,会发生什么情况呢?在这种情况下,您希望使用者记住最后处理的消息的偏移量,以便它可以从第一个未处理的消息开始。
为了确保消息持久性,Kafka使用两种类型的偏移量:当前偏移量用于跟踪消费者正常工作时使用的消息。提交的偏移量还跟踪最后一个消息偏移量,但它将该信息发送到Kafka服务器进行持久存储。
如果使用者宕机或由于某种原因宕机,它可以查询Kafka服务器上最近提交的偏移量和恢复消息消费,就像没有时间损失一样。Kafka代理将这些信息存储在一个名为__consumer_offset的主题中。这些数据被复制到多个代理,这样代理就不会丢失偏移量。
提交偏移量数据
您可以选择提交偏移量数据的频率。如果您频繁地提交,您将受到性能损失。另一方面,如果使用者确实下降了,那么需要重新处理和使用的消息就会减少。您的另一个选择是减少提交频率(为了获得更好的性能),但是在失败的情况下重新处理更多的消息。在这两种情况下,使用者都有两个提交偏移量的选项:
自动提交: 您可以将auto.commit设置为true,并将auto.commit.interval.ms属性设置为一个以毫秒为单位的值。启用此功能后,Kafka使用者将提交在响应poll()调用时接收的最后一条消息的偏移量。在设置auto.commit.interval.ms之后在后台会发出poll()调用。
手动提交: 您可以在KafkaConsumer上的任何时候调用commitSync()或commitAsync()方法。发出调用时,使用者将获取poll()期间接收的最后一条消息的偏移量,并将其提交到Kafka服务器.
3个手动偏移的使用案例
让我们考虑三个不希望使用Kafka的缺省偏移管理基础设施的用例。相反,您将手动决定从哪个消息开始。
从最开始: 在这个用例中,您捕获Kafka中的数据库更改。第一个记录是完整的记录;之后,您只得到值发生变化的列(变化量)。在这种情况下,您总是需要从头开始读取主题中的所有消息,以便构造记录的完整状态。要解决这样的场景,可以通过调用kafkaconsumer . seektobegin (topicPartition)方法将使用者配置为从头读取。请记住,默认情况下Kafka将删除超过7天的消息, 因此你需要配置log.retention.hours为1个更高的值。
在最末尾: 现在假设您正在通过实时分析交易来构建股票推荐应用程序。最坏的情况是,您的使用者应用程序宕机。在本例中,您使用kafkaConsumer.seekToEnd(topicPartition)配置偏移量,以忽略停机期间发布的消息。相反,消费者将从重新启动的那一刻开始处理正在发生的交易。
在给定的偏移量开始: 最后,假设您刚刚在生产环境中发布了生产者的新版本。在看到它生成了一些消息之后,您会意识到它正在生成坏消息。修复生成器并重新启动它。您不希望您的使用者使用这些坏消息,因此您可以通过调用kafkaConsumer手动将偏移量设置为生成的第一个好消息。寻求(topicPartition startingOffset)。
手动管理消费者应用的偏移量
到目前为止,我们开发的消费者代码每5秒自动提交记录一次。现在,让我们更新使用者以获取第三个参数,该参数手动设置偏移量消耗。如果使用最后一个参数的值为0,则使用者将假设您希望从头开始,因此它将为每个分区调用kafkaconsumer . seektobegin()方法。如果传递的值为-1,则假定您希望忽略现有的消息,并且只使用在重新启动使用者之后发布的消息。在本例中,它将在每个分区上调用kafkaConsumer.seekToEnd()。最后,如果您指定的值不是0或-1,那么它将假定您已经指定了希望使用者从哪里开始的偏移量;例如,如果您将第三个值传递为5,那么在重新启动时,使用者将使用偏移量大于5的消息。因此,它会调用 kafkaConsumer.seek(<topicname>, <startingoffset>).
清单4. 添加第三个参数给消费者
private static class ConsumerThread extends Thread{
private String topicName;
private String groupId;
private long startingOffset;
private KafkaConsumer<String,String> kafkaConsumer;
public ConsumerThread(String topicName, String groupId, long startingOffset){
this.topicName = topicName;
this.groupId = groupId;
this.startingOffset=startingOffset;
}
public void run() {
Properties configProperties = new Properties();
configProperties.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "localhost:9092");
configProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
configProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
configProperties.put(ConsumerConfig.GROUP_ID_CONFIG, groupId);
configProperties.put(ConsumerConfig.CLIENT_ID_CONFIG, "offset123");
configProperties.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,false);
//Figure out where to start processing messages from
kafkaConsumer = new KafkaConsumer<String, String>(configProperties);
kafkaConsumer.subscribe(Arrays.asList(topicName), new ConsumerRebalanceListener() {
public void onPartitionsRevoked(Collection<TopicPartition> partitions) {
System.out.printf("%s topic-partitions are revoked from this consumer
", Arrays.toString(partitions.toArray()));
}
public void onPartitionsAssigned(Collection<TopicPartition> partitions) {
System.out.printf("%s topic-partitions are assigned to this consumer
", Arrays.toString(partitions.toArray()));
Iterator<TopicPartition> topicPartitionIterator = partitions.iterator();
while(topicPartitionIterator.hasNext()){
TopicPartition topicPartition = topicPartitionIterator.next();
System.out.println("Current offset is " + kafkaConsumer.position(topicPartition) + " committed offset is ->" + kafkaConsumer.committed(topicPartition) );
if(startingOffset ==0){
System.out.println("Setting offset to beginning");
kafkaConsumer.seekToBeginning(topicPartition);
}else if(startingOffset == -1){
System.out.println("Setting it to the end ");
kafkaConsumer.seekToEnd(topicPartition);
}else {
System.out.println("Resetting offset to " + startingOffset);
kafkaConsumer.seek(topicPartition, startingOffset);
}
}
}
});
//Start processing messages
try {
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);
for (ConsumerRecord<String, String> record : records) {
System.out.println(record.value());
}
}
}catch(WakeupException ex){
System.out.println("Exception caught " + ex.getMessage());
}finally{
kafkaConsumer.close();
System.out.println("After closing KafkaConsumer");
}
}
public KafkaConsumer<String,String> getKafkaConsumer(){
return this.kafkaConsumer;
}
}一旦你的代码准备好了,你可以通过执行以下命令来测试它:
java -cp target/KafkaAPIClient-1.0-SNAPSHOT-jar-with-dependencies.jar com.spnotes.kafka.offset.Consumer part-demo group1 0 Kafka客户机应该打印偏移量为0的所有消息,或者您可以更改最后一个参数的值,以便在消息队列中跳转。
Apache Kafka消费组
传统的消息用例可以分为两种主要类型:点到点和发布-订阅。在点到点场景中,一个使用者使用一条消息。当消息中继银行事务时,只有一个消费者应该通过更新银行帐户进行响应。在发布-订阅cenario中,多个使用者将使用单个消息,但对其作出不同的响应。当web服务器宕机时,您希望将警报发送给编程以不同方式响应的使用者。
Queue指的是点到点场景,其中消息仅由一个消费者使用。Topic指的是发布-订阅场景,其中消息由每个使用者使用。Kafka没有为队列和主题用例定义单独的API;相反,在启动使用者时,需要指定ConsumerConfig.GROUP_ID_CONFIG属性。
如果您对多个使用者使用相同的GROUP_ID_CONFIG, Kafka将假定它们都是单个组的一部分,并且它将只向其中一个使用者传递消息。如果在单独的组中启动两个消group.id、Kafka将假设它们不相关,因此每个消费者将获得自己的消息副本。
回想一下,清单3中的分区使用者将groupId作为其第二个参数。现在我们将使用groupId参数为使用者实现队列和主题用例。
创建一个名为group-test的主题,包含两个分区:
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 2 --topic group-test启动一个生产者,该生成器可用于将消息发布到刚刚创建的group-test主题:
java -cp target/KafkaDemo-1.0-SNAPSHOT-jar-with-dependencies.jar com.spnotes.kafka.partition.Producer group-test启动三个消费者监听发布到group-test主题的消息。使用group1作为组id的值。这将在group1中为您提供三个消费者:
java -cp target/KafkaDemo-1.0-SNAPSHOT-jar-with-dependencies.jar com.spnotes.kafka.simple.Consumer group-test group1启动第四个消费者,但这次将组id的值更改为group2。这将在group1中提供三个消费者,在group2中提供一个消费者:
java -cp target/KafkaDemo-1.0-SNAPSHOT-jar-with-dependencies.jar com.spnotes.kafka.simple.Consumer group-test group2返回生产者控制台并开始键入消息。您发布的每个新消息应该在group2使用者窗口中出现一次,在三个group1使用者窗口中出现一次,如图3所示.
Figure 3. 消费组输出
Part 2总结
大数据消息系统的早期用例需要批处理,例如运行夜间ETL进程或定期将数据从RDBMS移动到NoSQL数据存储。在过去几年中,对实时处理的需求增加了,特别是对欺诈检测和应急响应系统的需求。Apache Kafka就是为这些类型的实时场景而构建的。
Apache Kafka是一个伟大的开源产品,但它也有一些局限性;例如,您不能在主题到达目的地之前从主题内部查询数据,也不能跨多个地理分布的集群复制数据。您可以将MapR流(一种商业产品)与Kafka API结合使用,用于这些和其他更复杂的发布-订阅场景。
以上是关于实时构建:Apache Kafka的大数据消息传递,Part 2的主要内容,如果未能解决你的问题,请参考以下文章