跨城实践中,腾讯如何应用 Apache Pulsar
Posted StreamNative
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了跨城实践中,腾讯如何应用 Apache Pulsar相关的知识,希望对你有一定的参考价值。
本文作者:刘德志
腾讯后台开发高级工程师、 TEG 技术工程事业群和计费系统开发者
腾 讯 计 费 介 绍
腾讯计费(米大师)是孵化于支撑腾讯内部业务千亿级营收的互联网计费平台,汇集国内外主流支付渠道,提供账户管理、精准营销、安全风控、稽核分账、计费分析等多维度服务。
平台承载了公司每天数亿收入大盘,为 180+ 个国家(地区)、万级业务代码、100W+ 结算商户提供服务,托管账户总量 300 多亿,是一个全方位、一站式计费平台。
作为一个千亿级在线支付平台,腾讯计费(米大师)需要在以下方面进行重点优化和升级。
计费场景要求不能丢掉任何数据,这是最基本的诉求。毕竟属于金融资产类,虽然有的是虚拟账户,但还是用真金白银进行交易的。通过提取 SQL 来保证数据层面高可靠性、高一致性。
平台的操作流程跟一些电商平台的支付流程有些相似,即加入购物车、下单、发货。不同的是,大多数电商平台需要用户自己手动参与这些流程,而腾讯计费则是用户在后台点击便可自动完成。
尤其是对于一些免付费的项目,对整体可用性会有更高的要求。需具备容灾能力,在异常情况下能够自动修复。
在逻辑层面,因为整个系统覆盖 300 多个不同的业务产品,在面临海量增长的数据时,对性能的稳定性就有着极高的需求。
对于腾讯业务的量级情况,在容灾的效果期望上至少是城市级别的。在腾讯内部有上万个业务,这些业务部署在各地,计费平台的服务基本是部署在深圳和上海两个地方。在这里就需要提供「异地多活」的服务。
当然在多数情况下,我们会保持在同城部署服务。在进行业务请求时,选择就近的网关,可以减少不必要的情况。当然异地情况下,也要保证快速切换的状态。
腾讯计费场景下的跨城挑战
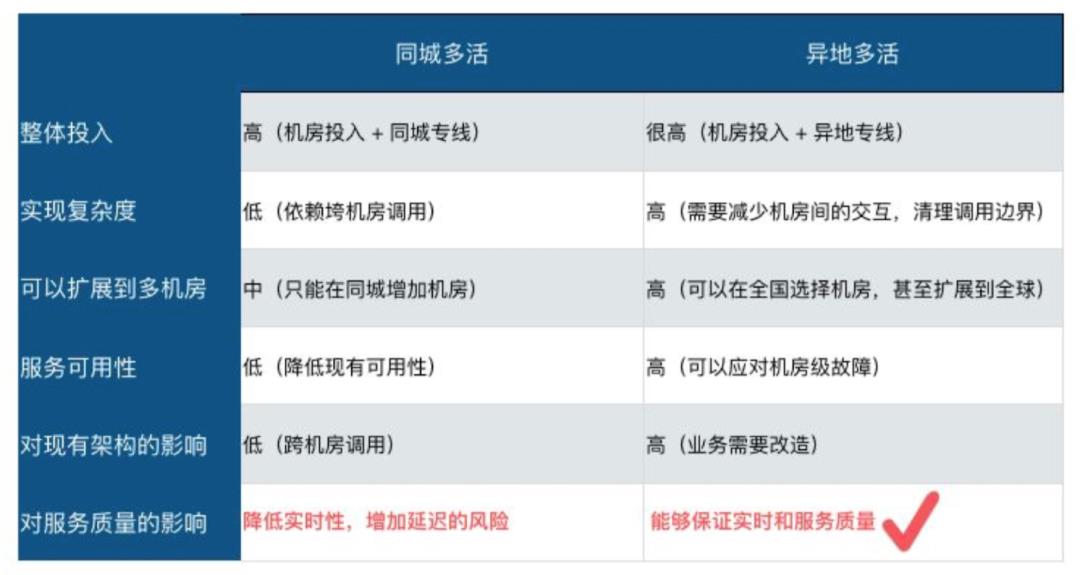
在容灾层面,按照地域可以分为「同城多活」和「异地多活」。在逻辑层面,两种状态下都比较容易操作,比较困难地是在数据层面。
同城多活状态下,在数据层会有多个副本构成,采用跨机房或 IDC 部署。如果出现问题,可以立即切换到其他机房/IDC 进行部署,达到无损切换。虽然这种方式操作比较简单,但是它避免不了跨城市之间、一些极端情况的出现。
异地多活情况下,在部署方面就需要跨城多地进行。当一个城市的服务器宕机时,另一个城市可以继续支撑产品,来减少损失。
但是想要做到完全无损是非常困难的,除非是每一步操作后都同步到异地并操作成功,才能保证任何时刻数据都是一致的。但是这样性能方面,效率就大大下降了。
在整体性的表现上,异地多活更适用于腾讯计费的产品模式。
>> 异地单活与异地多活
在之前,腾讯计费采用的是异地单活的模式。当时的业务没有现在这么多元复杂,大部分请求都在主城市/主数据库完成。对于数据库的读取,可以根据不同产品的不同需求,在主城或备城读取。
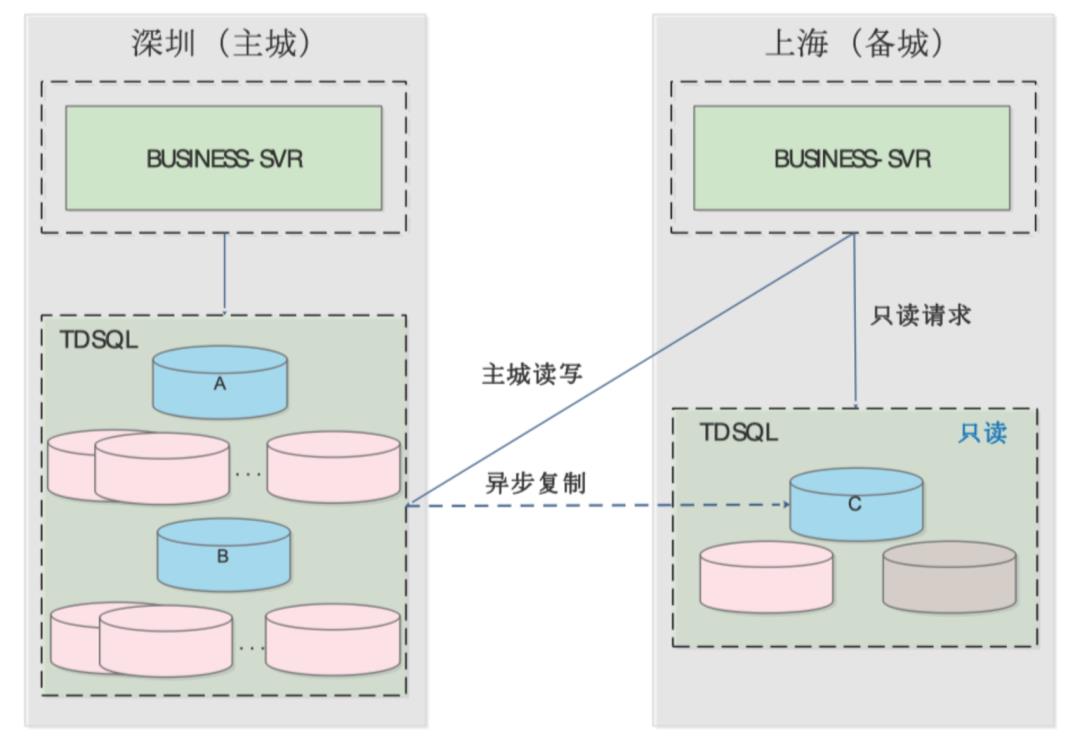
这种架构的好处是,数据是强一致性的,不会出错,因为所有的数据都是集成在同一地方去写入。缺点就是一旦出现城市级网络灾难,就没有设备进行写入操作。
随着腾讯业务的扩展和丰富,异地多活成为必然的选择,用来提供高质量、高稳定的服务。这就涉及到两个数据中心的同步问题。
目前业界主流的是 CDC 异步模式,可以通过消息队列来应用到消息层面。不仅可以利用 MQ 的海量堆积能力来存放操作流水,还可以利用多消费处理能力来支撑数据复制的效率。
对于 MQ 的部署,同样也可以采用同城或者跨城的部署。
同城:在 DB 中心单独部署一个 MQ 集群。生产时,在同城的 MQ 进行,消费时,则交叉地进行数据读取。这样做的好处是生产效率高,缺点是消费时需要进行跨省访问,本身不具备「跨省」的能力。
跨城:MQ 采用同城部署,具备跨省能力,能够进一步减少数据丢失。缺点是生产配置时,需要进行跨城市的数据调用,以及消费副本需要绑定在多地。
日常使用中多采用第二种方式,因为需要尽可能减少数据丢失的风险。
所以腾讯计费系统对分布式消息队列的要求如下:
一致性要求:计费场景要求数据一条不能丢,这是最基本的诉求。
高可用要求:需具备容灾能力,在异常情况下能够自动修复。
海量存储需求:在移动互联网时代,产生大量的交易数据,需要具备海量堆积能力。
快速响应要求:在亿级支付场景下,要求 MQ 能提供平滑的响应时间,尽可能控制在 10ms 内。
相比业界使用比较多的 Kafka 而言,它的主要场景是大数据日志处理,较少用于金融场景。RocketMQ 对 Topic 运营不太友好,特别是不支持按 Topic 删除失效消息,以及不具备宕机 Failover 能力。
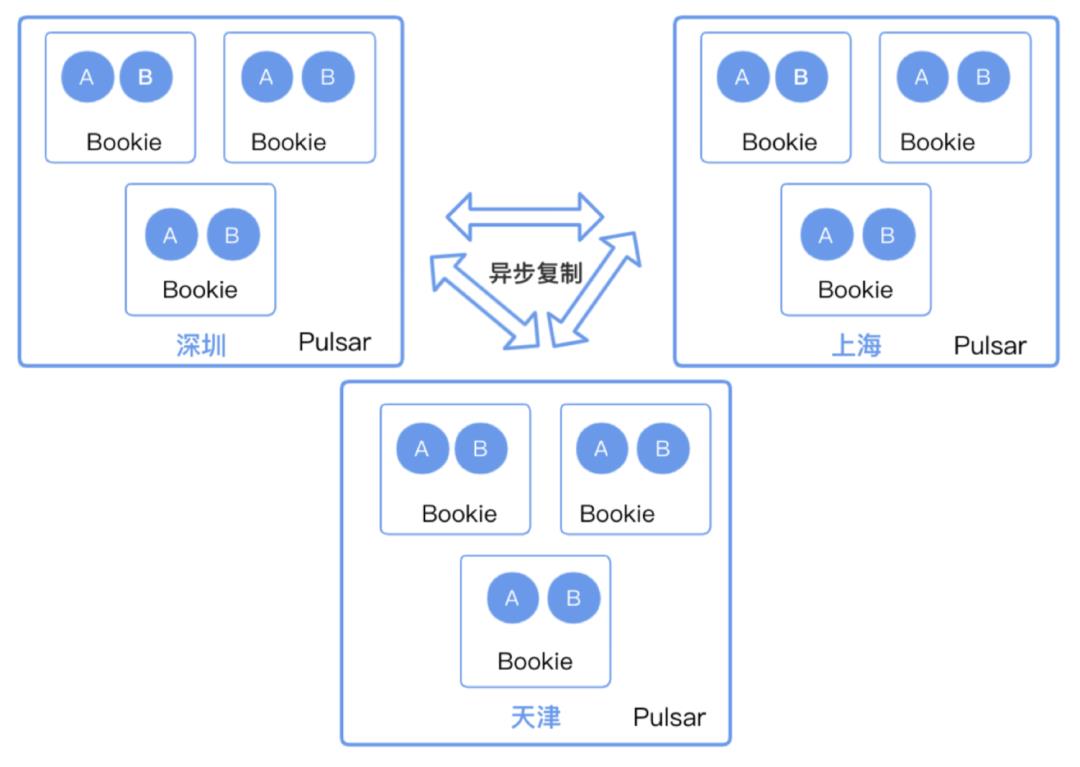
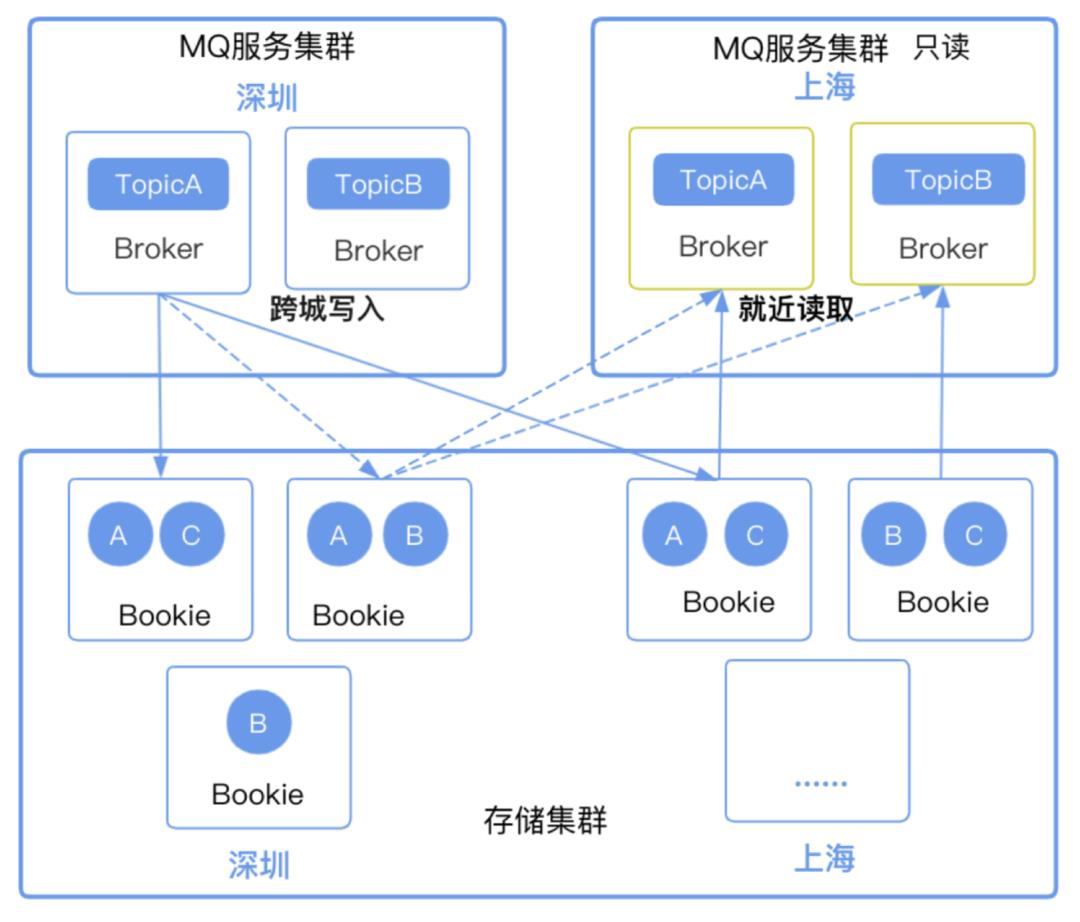
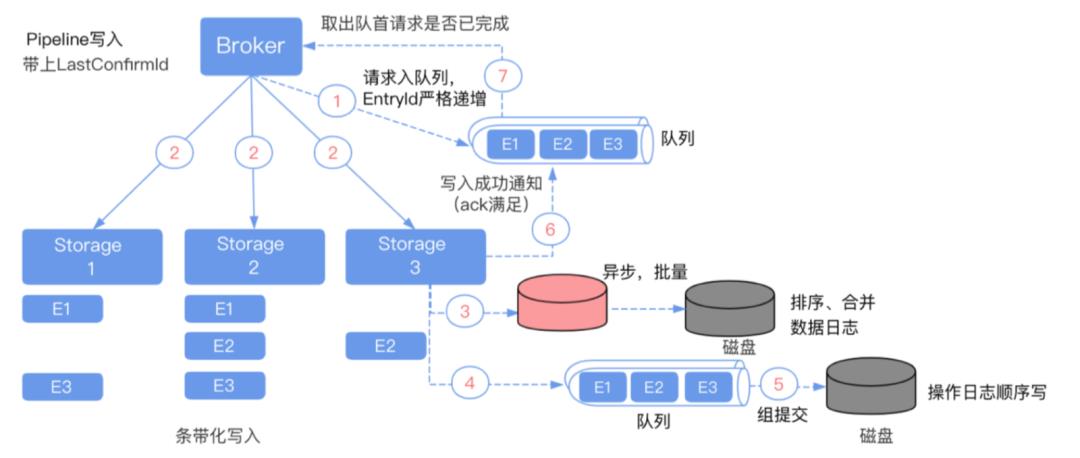
因为只读 broker 和 broker 是采用隔离部署的,需要去把 topic 元数据从写入的 broker 上同步过来,这样就知道 topic 对应的 ledger 集合有哪些,就可以分辨数据读取了。
2. 如何读取最近的数据?
以上是关于跨城实践中,腾讯如何应用 Apache Pulsar的主要内容,如果未能解决你的问题,请参考以下文章