马铁大神的 Apache Spark 十年回顾
Posted 过往记忆大数据
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了马铁大神的 Apache Spark 十年回顾相关的知识,希望对你有一定的参考价值。
首先祝大家端午节快乐,幸福安康。
就在上周
五,
Apache Spark 3.0
全新发布,此版本给我们带来了许多重要的特性,感兴趣的同学可以看下这篇文章: 。
Spark 是从 2010 年正式开源,到今年正好整整十年了!
一年一度的 Spark+AI SUMMIT 在本周正在如火
如荼的进行。Apache Spark 的发明者马铁大神给我们带来了 Apache Spark 3.0 介绍:回顾 Spark 过去十年,以及未来展望。

大神首先激情回顾了自己过去十年的情况,介绍了发明 Spark 的目的,以及后面几年 Spark 的发展。



Apache Spark 大概是从 2009年8月开始开发的
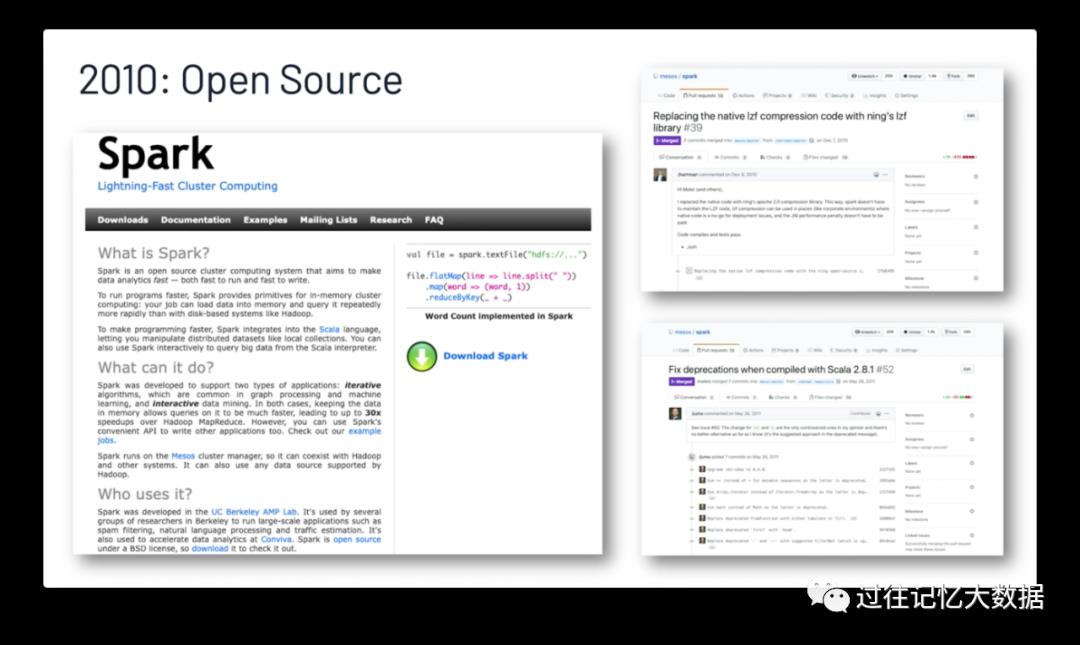
2010年 Spark 正式开源

2010-2011年期间开始有大量的用户使用,产生了许多预料之外的案例。

2012-2015年期间社区对 Spark 加了很多扩充,在语言支持上增加了 Python、R 以及 SQL 等;在类库上增加了 ML、图以及实时流处理功能;添加了许多高层次的 API。
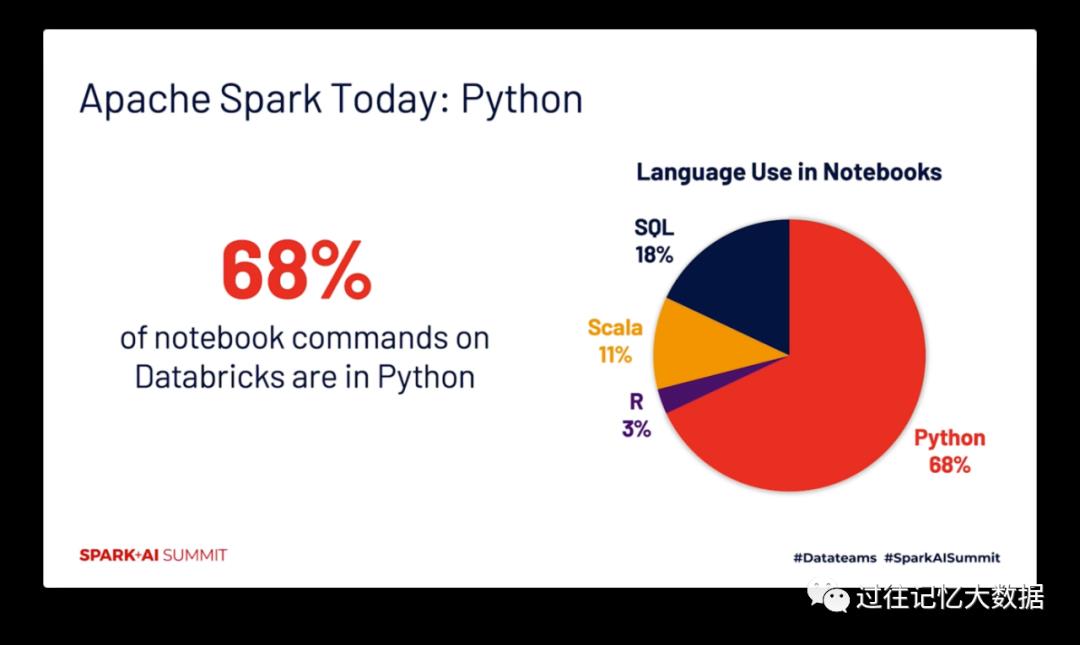
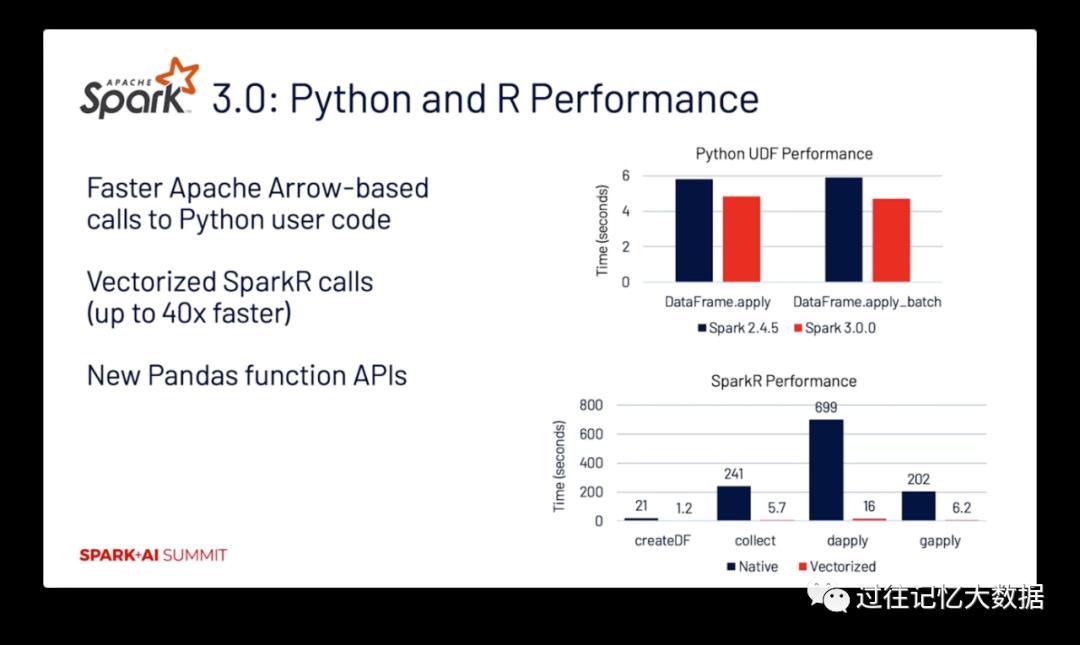
今天,数砖公司的产品中 68% 的 notebook 命令都是使用 Python 写的。
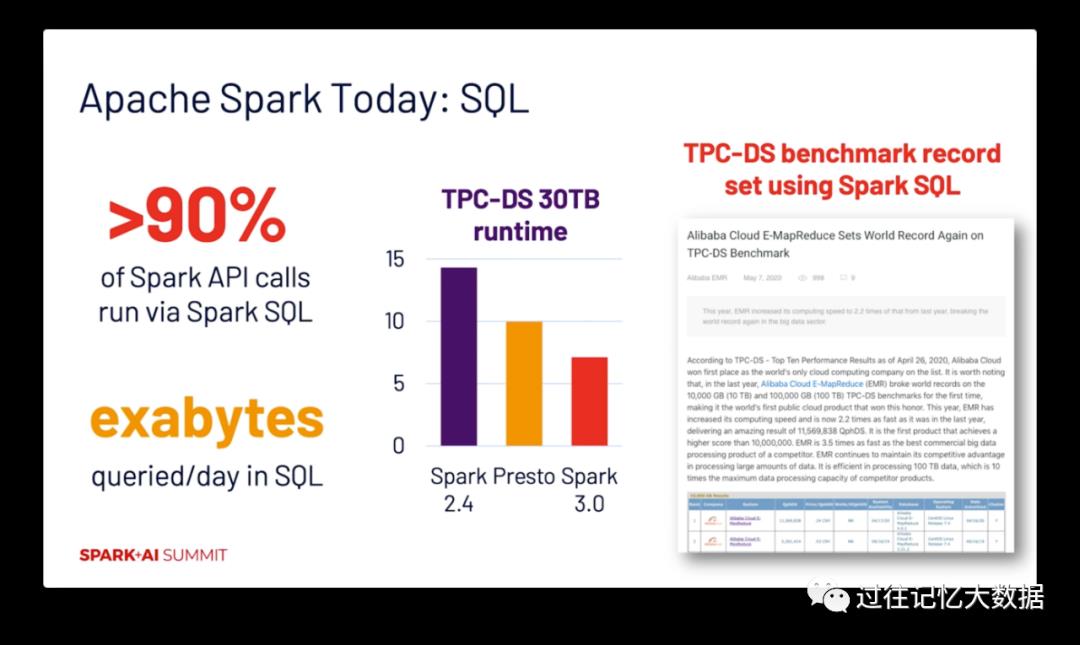
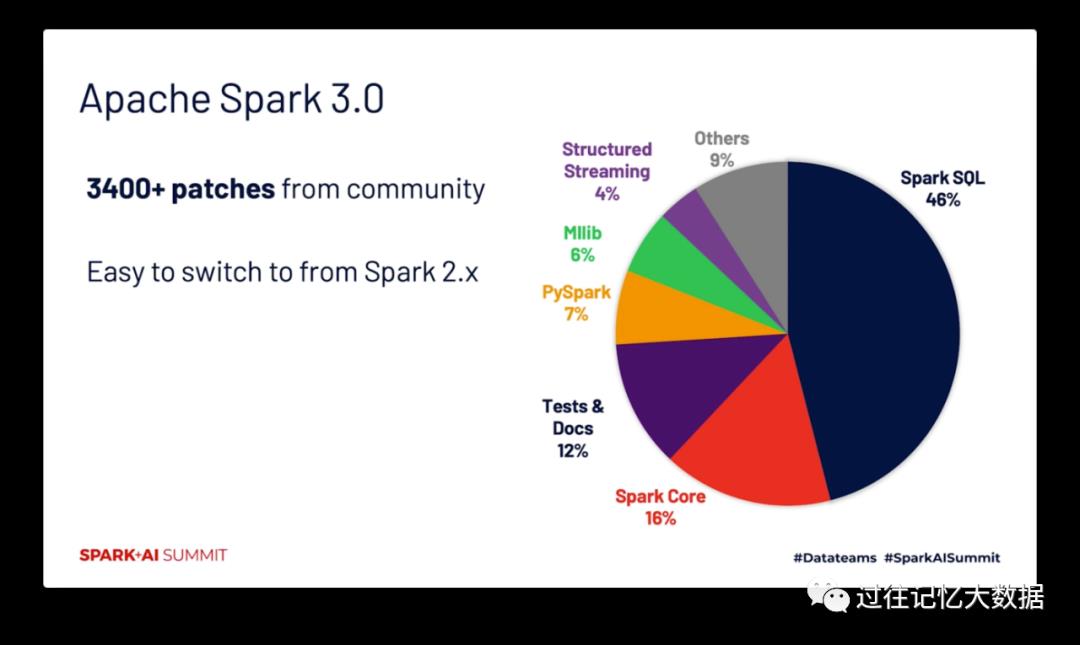
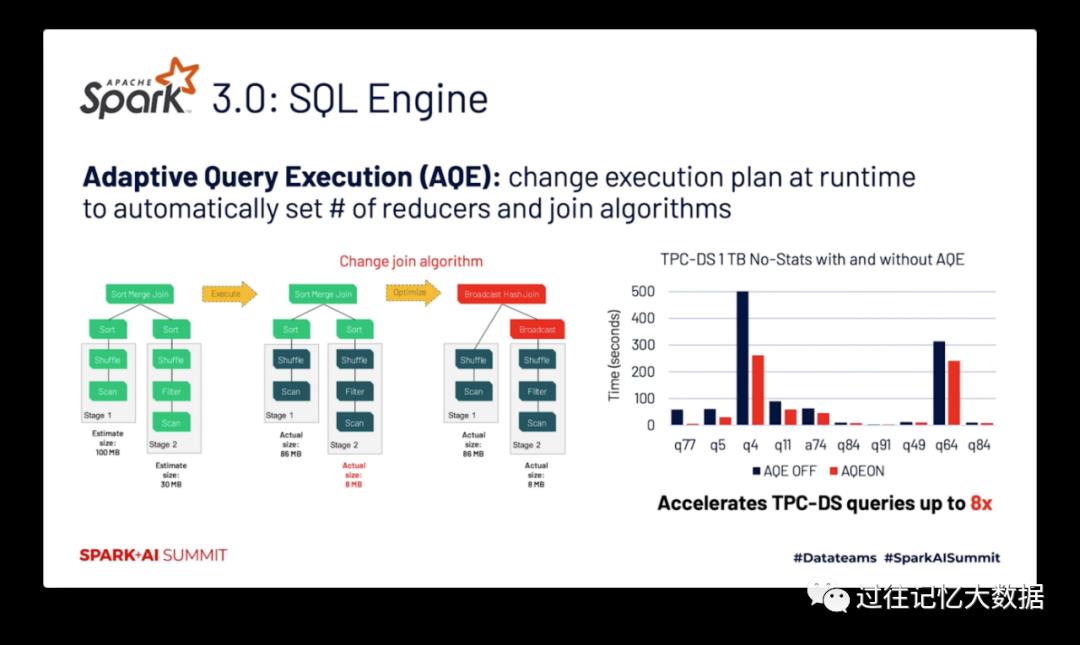
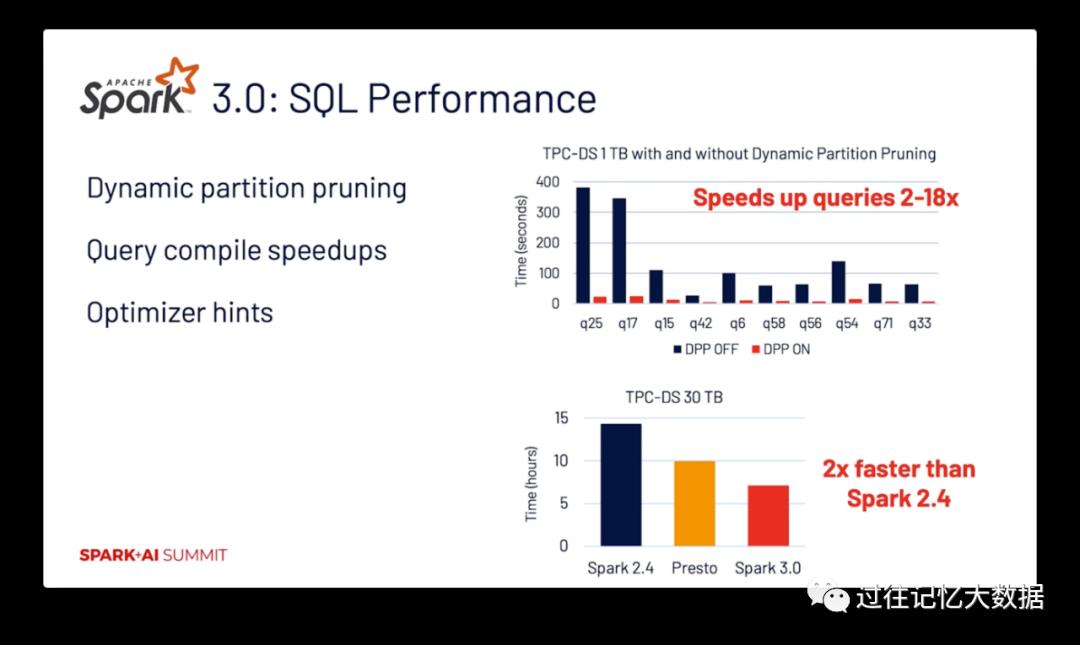
超过 90% 的 Spark API 都是通过调用 Spark SQL 进行的,所以搞到最后 Spark SQL 才是最重要的东西,其底层的优化器为大多数作业进行优化。最近发布的 Spark 3.0 的 TPC-DS 测试性能比 Spark 2.4 提升近2倍,甚至比 Presto 还快!
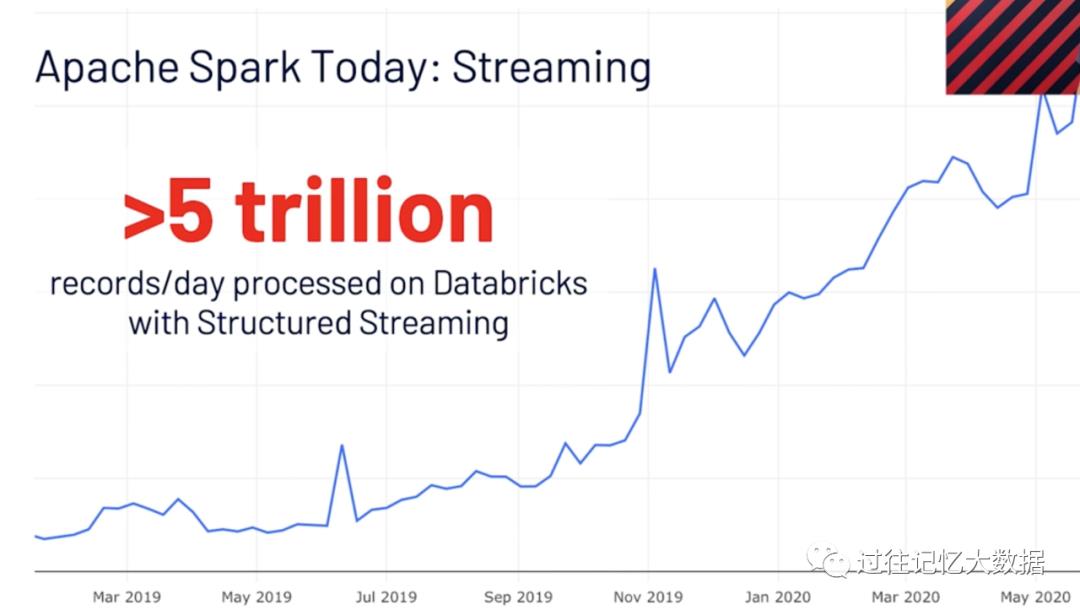

产品的易用性很重要
支持最佳实践的 API
接下来马铁大神简单介绍了 Apache Spark 3.0 的新功能:感兴趣的同学也可以到过往记忆大数据的
去看看。






以上是关于马铁大神的 Apache Spark 十年回顾的主要内容,如果未能解决你的问题,请参考以下文章
“深度学习”这十年:52篇大神级论文再现AI荣与光
Spark诞生头十年:Hadoop由盛转衰,统一数据分析大行其道
2019年Apache Spark技术交流社区原创文章回顾
如何在云端更好地使用 Apache Spark,1029 SA Immersion Day 线上培训回顾
Spark Transformation 算子
类型不匹配;找到:org.apache.spark.sql.DataFrame 需要:org.apache.spark.rdd.RDD