洋码头消息总线架构
Posted 桃哥的后院
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了洋码头消息总线架构相关的知识,希望对你有一定的参考价值。
作者介绍
罗时迁, 洋码头架构师,
负责洋码头消息总线、门神、Falcon等基础设施的设计与研发。
 涂文杰, 洋码头架构师
涂文杰, 洋码头架构师
介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍介绍。
一、设计目标
消息总线(以下简称为总线)是洋码头应用(服务)间异步通信、消息驱动、削峰限流的核心基础设施。对于总线,在必须的大并发、高可用,易扩展之外,我们追求如下目标:
| 易用
消息生产者(Producer)和消费者(Consumer)感知不到底层消息队列(MQ)中间件(如RabbitMQ,Kafka等)。
Producer调用总线的发送API:send(String destinationCode, Message message)即完成消息的发送。
总线根据需要,可将消息在不同MQ间灵活切换。如有必要,总线甚至可以不经由任何MQ,将消息直接发送给Consumer。
| 必达
除非Producer的硬盘和网络同时发生故障,一次send()调用即确保消息一定能送达总线。对于收到的每一笔消息,总线确保其被每一个消费者消费成功。得益于该特性,对于许多一定要执行成功某个操作的场景(譬如取消订单,用户的优惠券一定要返还),本来需要业务服务自身不断轮询补单的处理方式简化为只需往MQ发一条消息即可:)
| 隔离
一条消息往往有多个消费者。一个消费者的快慢不影响其他消费者。
| 溯源
开发人员方便查看每笔消息及其处理过程:什么时间点由什么应用发出,什么时间点到达总线,什么时间点被消费,消费者耗时多少,补单几次才消费成功等。在错综复杂的异构分布式环境中,明了每笔消息的来龙去脉对于分析定位问题至关重要。
| 自警
作为核心基础设施,总线必须有完备的监控和告警机制:消息PV,积压状况,消费者异常/性能等
二、总线总体架构
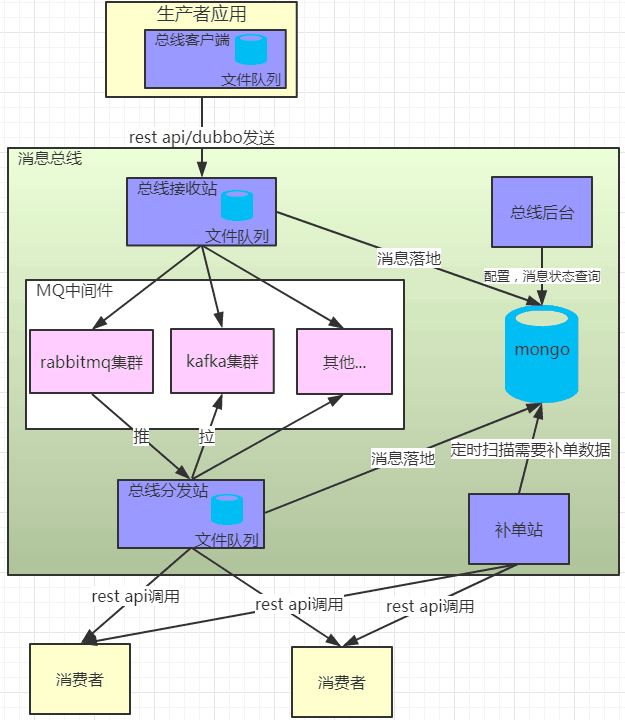
洋码头消息总线总体架构
如上图所示,总线由总线客户端、总线接收站、MQ中间件、总线分发站、补单站和总线后台组成。
1、总线客户端
总线客户端为Producer提供消息发送API:send(String destinationCode,Message message)。其中,
destinationCode:代表消息的目的地。
message:消息报文体,内有两个重要ID。messageId:由总线客户端自动生成,每条消息的uuid;bizId:由Producer传入,代表该消息对应的某个业务实体的ID(譬如订单ID),便于消息查询及消费者消费消息时的幂等控制。
send()执行:消息入本地文件队列,发送消息到接收站;若发送成功,从本地文件队列删除该消息。另外客户端有补单线程,对于长期处于本地文件队列的消息,进行消息补发,若补发成功则从文件队列删除。这样,只要Producer不是硬盘和网络同时发生故障,每笔消息一定能发送到接收站。
2、总线接收站
用于接收消息,将接收到的消息发送给相应的MQ中间件,同时将消息落地到Mongodb中。某类消息的进入TPS可能远高于Mongodb集群中一个节点所能支持的最大安全TPS。因此在Mongodb之上,引入本地文件队列缓冲层,能动态配置消息从文件队列到Mongodb的速率。
3、MQ中间件
当前已引入Rabbitmq和Kafka,不同业务可以灵活选择,也可以通过配置动态切换。
4、总线分发站
从MQ中间件中获取消息,然后通过配置在对应destinationCode的订阅Url,使用异步Httpclient将消息分发给各个消费者应用。通过信号量控制每个订阅Url的最大并发。
根据订阅Url的调用返回结果更新其对应MongodbDocument的消费状态;如果Url调用失败,将<messageId, url>插入补单表,待补单站捞取补单。
和总线接收站类似,在总线分发站引入本地文件队列中间缓冲层,解决MQ中间件push或从MQ中间件pull消息的TPS与Mongodb最大安全写入TPS间的mismatch。
5、补单站
捞取补单表中仍未成功的消息和消息表中长时间处于“未执行”状态的消息,根据补单策略进行补单。确保每笔消息被每个消费者成功消费。
6、总线后台
主要功能有:
消息配置:目的地,订阅Url及其最大并发与补单重试策略等。
消息明细查询:报文体,来源,入总线时间,出总线时间,消费状态,消费耗时等。
手工补发:如需要,消息可补发。如消费者有bug,等到消费者修复上线后,可将一段时间内的消息置为“待重发”。
7、本地文件队列
如前所述,我们的总线大量应用了本地文件队列以提高可靠性。在调研比较各类开源产品后,我们选择基于JetBrains的Xodus做二次开发(https://github.com/JetBrains/xodus)。
三、总线可靠性
1、Producer侧不丢消息
如在“总线总体架构”->“总线客户端”中所述,通过引入本地文件队列,只要不是Producer的硬盘和网络同时发生故障,消息一定能送达总线。
2、消息接收站不丢消息
若经由Rabbitmq, 发送消息时采用PublisherConfirm机制(https://www.rabbitmq.com/confirms.html),发送异常或直接被Rabbitmqnack掉的消息将被直接发送给分发站。
若经由Kafka,发送消时设置ack为1,发送异常或ack失败的消息将被直接发送给分发站。
接收到的每笔消息会最终写入Mongodb。长期处于待执行状态的消息会被补单站直接分发。
3、确保每笔消息被消费
如“总线总体架构”->“补单站”中所述,补单站确保被总线接收的每笔消息被消费。
4、MQ中间件集群高可用
以RabbitMQ为例,描述一下MQ中间件集群的高可用。如下图所示,我们在两个机房部署主/备两套集群,方便硬件维护和集群升级。总线接收站可在两套集群间动态切换。总线分发站同时接收两套集群的消息。集群内的每个节点都配置为Disc Node,每个Queue都有一个镜像(Mirror)。关于总线接收站/分发站与集群的连接,摈弃传统的在集群前加HA的方式,通过自定义的com.rabbitmq.client.AddressResolver实现自动重连与恢复。
RabbitMQ集群高可用架构图
5、Docker/K8S环境应对
如前所述,为可靠性,总线大量使用了本地文件队列(客户端/接收站/分发站)。在K8S环境,K8S按需可随时将服务(POD)在任意节点间自动迁移。这样就存在一个问题:一个POD在Node1节点创建的本地文件队列在POD被迁移到Node2节点后,就成了一个孤岛。我们的解决方案是:开发一个DaemonSet POD,K8S会确保每个Node运行且只运行一个该POD实例,该POD会检测到Node上长期未读写的文件队列,将该队列消费完毕后销毁掉。
6、其他
总线对所有外部依赖(消息中间件/Mongodb等)访问做了降级处理。底线是:只要自身接收站/分发站可用,就能保障消息的收发。
四、不同订阅者间的隔离
同一消息,往往有多个订阅者,每个订阅者可单独设置允许的最大并发,各订阅者之间互不影响。
1、RabbitMQ
采用RabbitMQ Topic Exchange模式(https://www.rabbitmq.com/tutorials/amqp-concepts.html#exchange-topic)。一个目的地(destinationCode)是一个Exchange,不同的Url是不同的Queue,这些Queue与Exchange通过指定的routingpattern绑定,发送到Exchange上的消息带有特定的routing keys,Exchange能将消息自动路由到其绑定的routing pattern与routing keys匹配的所有队列。
2、Kafka
一个目的地(destinationCode)是一个Topic,不同的订阅Url,是一个不同的ConsumerGroup。
五、总线监控
基本思想是采集任何需要关心的数据/指标上报到我们的监控平台Falcon(后续有文专门来介绍这个系统:))并配置报警策略。
1、RabbitMQ
通过RabbitMQ ManagementHttp API获取集群状态/节点状态/内存占用/Connection流控/Queue积压。
2、Kafka
使用Linkedin开源的Burrow(https://github.com/linkedin/Burrow)上报异常。
3、总线自身
监控指标包含每个消息的PV/每个文件队列的积压状况/订阅Url的耗时/订阅Url的调用异常/订阅Url的信号量等。
六、踩过的坑
1、RabbitMQ集群中一个节点内存过高问题
每当有消息大堆积时,集群中一个节点就会内存过高,紧接着很多Connection会被RabbitMQ流控。分析发现内存都是被rabbitmq_management统计数据占用。这是rabbitmq_management Plugin的自身问题(详见,https://github.com/rabbitmq/rabbitmq-management/issues/236),在3.6.5版本才解决。考虑到集群升级验证的代价以及众多统计项(譬如消息的流速等)在接收站已被我们通过监控平台Falcon自行统计,我们通过调节rabbitmq_management的统计项和统计频率来解决。
2、Kafka重发消息问题
线上Kafka偶尔会出现消息会被重复发给消费者的现象。最终原因确认为:由于消费者订阅Url慢,导致一个分发站从Kafka两次poll的间隔超过Kafka的session.timeout。Kafka以为该消息分发站不可用,于是将该消息分发站正在访问的partition分派给其他分发站,导致消息重发。
在Kafka 0.10.1.0及以后版本中,Kafaka客户端有独立心跳,不再依赖poll间的间隔来判定消费客户端是否可用。关于Kafka新旧版本检测客户端可用方式异同,参考:
http://kafka.apache.org/0100/documentation.html#newconsumerconfigs
http://kafka.apache.org/0101/documentation.html#newconsumerconfigs
在不升级Kafka的前提下,我们通过确保两次poll间隔不超过Kafka的session.timout来解决。
七、总结
本文论述了洋码头总线架构设计及实现关键点。该系统上线后在一个月内经过三四次的快速迭代即趋于稳定,日常维护成本基本为0。运行至今,没丢一笔消息,历经两年“黑五”流量洪峰检验。由该系统孵化出的本地文件队列组件被广泛应用于其他基础设施和服务中。
全文完
近期主题预告:
数据挖掘在电商平台上的风控与反作弊应用
洋码头推荐系统的演进
缓存技术在洋码头商品领域的应用
洋码头自动化发布系统介绍
关注【洋码头技术】,第一时间获取我们最新的技术分享推送。
以上是关于洋码头消息总线架构的主要内容,如果未能解决你的问题,请参考以下文章
微服务实战:落地微服务架构到直销系统(构建消息总线框架接口)