技术篇:轻松看懂机器学习分类常用算法
Posted 轨道车辆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术篇:轻松看懂机器学习分类常用算法相关的知识,希望对你有一定的参考价值。

本期带读者简单了解machine learning的常用算法,这里仅以通俗的语言和简单的图片进行讲解,大致原理是什么,它们是干什么的,咱们主要聊一下分类的问题。
介绍算法如下:
1.线性判别分析
2.决策树
3.神经网络
4.支持向量机
5.K值临近
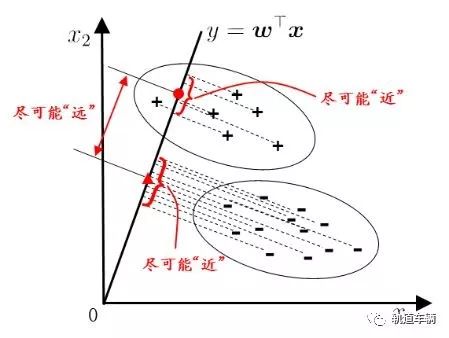
1. 线性判别分析
线性判别分析(Linear Discriminant Analysis)的思想:欲使同类样例的投影点尽可能接近,可以让同类样例投影点的协方差尽可能小;欲使异类样例的投影点尽可能远离,可以让类中心之间的距离尽可能大。
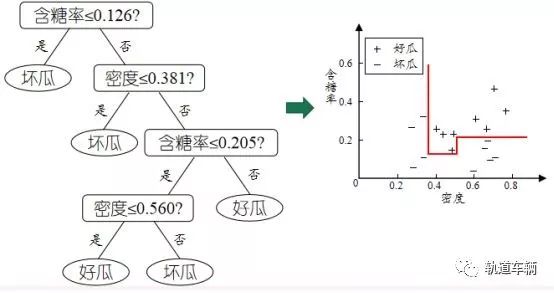
2. 决策树
根据一些 feature 进行分类,每个节点提一个问题;通过判断,将数据分为两类,再继续提问。这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
3. 神经网络
神经网络分为两种,浅层神经网络和深层神经网络(深度学习),就拿BP神经网络和卷积神经网络举例(CNN)。
标准BP神经网络
Neural Networks 适合一个input可能落入至少两个类别里;
NN 由若干层神经元,和它们之间的联系组成第一层是 input 层,最后一层是 output 层;
在 hidden 层 和 output 层都有自己的 classifier;
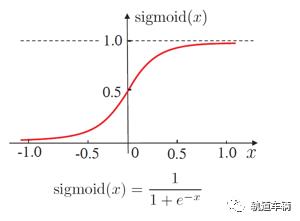
input 输入到网络中,被激活,计算的分数被传递到下一层,激活函数(一般用sigmoid函数)后面的神经层,最后output 层的节点上的分数代表属于各类的分数,同样的 input 被传输到不同的节点上,之所以会得到不同的结果是因为各自节点有不同的weights 和 bias。
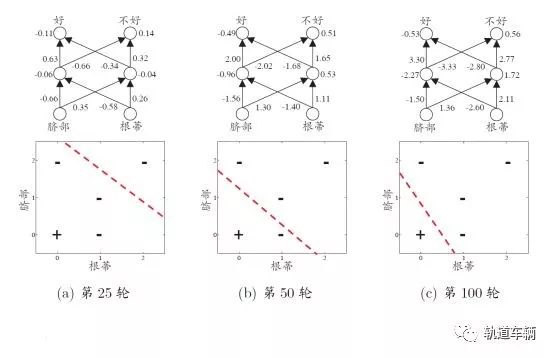
下图每次针对单个训练样例更新权值与阈值,参数更新频繁,不同样例可能抵消,需要多次迭代。
卷积神经网络
结构:CNN复合多个卷积层和采样层对输入信号进行加工, 然后在连接层实现与输出目标之间的映射。
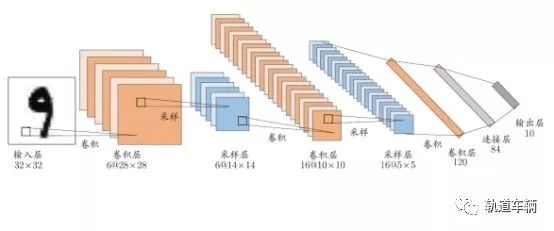
卷基层:每个卷基层包含多个特征映射, 每个特征映射是一个由多个神经元构成的“平面”, 通过一种卷积滤波器提取的一种特征;
采样层:亦称“汇合层”, 其作用是基于局部相关性原理进行亚采样, 从而在减少数据量的同时保留有用信息;
连接层:每个神经元被全连接到上一层每个神经元, 本质就是传统的神经网络, 其目的是通过连接层和输出层的连接完成识别任务 。
4. 支持向量机
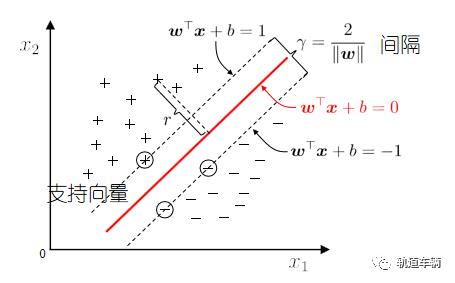
另一个经常使用的机器学习算法是支持向量机(support vector machine, SVM),SVM可以看做是感知机的扩展。在感知机算法中,我们最小化错误分类误差。在SVM中,我们的优化目标是最大化间隔(margin)。间隔定义为两个分隔超平面(决策界)的距离,那些最靠近超平面的训练样本也被称为支持向量(suppor vectors)。
线性模型:在样本空间中寻找一个超平面, 将不同类别的样本分开。
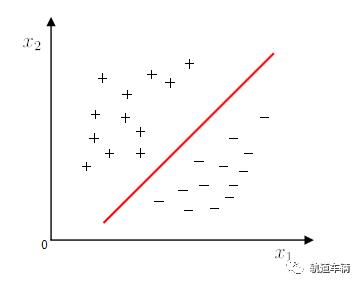
然而将训练样本分开的超平面可能有很多,哪一个好呢?
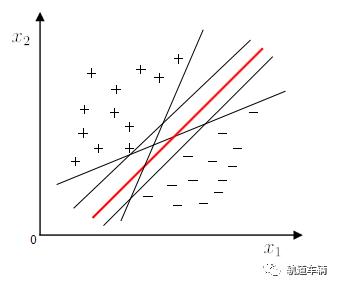
应选择“正中间”, 容忍性好,鲁棒性高,泛化能力最强。
超平面方程:
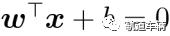
若不存在一个能正确划分两类样本的超平面, 怎么办?
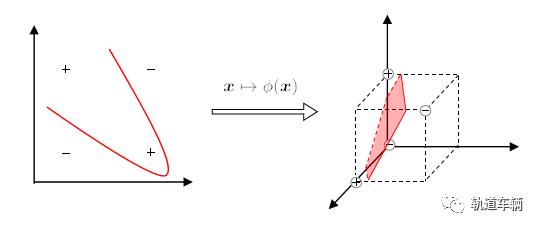
将样本从原始空间映射到一个更高维的特征空间, 使得样本在这个特征空间内线性可分。
5. K值临近
KNN属于变参模型的一个子类:基于实例的学习(instance-based learning)。基于实例的学习的模型在训练过程中要做的是记住整个训练集,而懒惰学习是基于实例的学习的特例,在整个学习过程中不涉及损失函数的概念。
KNN算法本身非常简单,步骤如下:
(1)确定k大小和距离度量。
(2)对于测试集中的一个样本,找到训练集中和它最近的k个样本。
(3)将这k个样本的投票结果作为测试样本的类别。
一图胜千言,请看下图:
“懒惰学习”(lazy learning): 此类学习技术在训练阶段仅仅是把样本保存起来,训练时间开销为零,待收到测试样本后再进行处理。
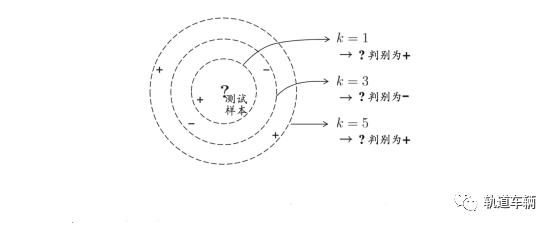
虚线显示初等距线k近邻分类器中的k是一个重要参数,当k取不同值时,分类结果会有显著不同。另一方面,若采用不同的距离计算方式,则找出的“近邻”可能有显著差别,从而也会导致分类结果有显著不同。
以上是关于技术篇:轻松看懂机器学习分类常用算法的主要内容,如果未能解决你的问题,请参考以下文章