博弈游戏中的常用算法
Posted 紫冬科协
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了博弈游戏中的常用算法相关的知识,希望对你有一定的参考价值。
自动化系学生科协举办的新生C语言大赛、软件设计大赛前不久刚刚结束,相信不论是碧水保卫战中的争夺与追逐还是Link游戏中棋盘占领的对弈,都让给大家带来了乐趣。
本文从相对简单的Link游戏出发,介绍一些在同类问题中常用的传统算法。
0
Link游戏规则回顾
这是一个支持多人对战的同时决策游戏,每名玩家每回合可以选择在某一列的最顶端放下属于自己阵营的一枚棋子(类似俄罗斯方块的堆叠方式),若多人选择在同一位置落子则该位置变成中立的障碍格。玩家的目标则是尽可能让己方的棋子连成线,线越长分数越高,最终分数总和高者获胜。
1
简单贪心法
贪心法可以说是最容易想到,最容易实现的方法。事实上我们提供的样例程序便是使用贪心法,它的逻辑是,在当前所有可能的落子决策中,寻找一个能让自己本回合得分最高的一步,这个逻辑就是所谓的贪心策略。贪心策略就是贪心法的一切,如果拿象棋来举例,我们的贪心策略可能是能将军就将军,不能就看看能否吃掉对方棋子,再不然就随机决策,这也是一种贪心策略。显而易见,策略不同,AI的强度将会天差地别,然而贪心策略的寻找几乎没有方法可循,只能是根据具体的游戏目标、游戏规则进行设计,最终往往需要设置大量参数,然后在实战中慢慢调整出一套合适的贪心策略。

(落子先行后列与先列后行
两个简单贪心的对弈结果)
在设计过程中发现,由于Link游戏的特殊性,有一个简单的贪心策略达到的效果比很多复杂策略来得好,用文字来描述就是——计算出当前一步给自己带来收益最大的一个决策,和妨碍对方落子给对方带来损失最大的一个决策,再对这个收益、损失加以比较得到最终决策。最终观察选手对局时发现有至少3位选手使用了这一策略的贪心法,这也提示我们一个好的贪心策略不一定是非常复杂的,有时简单而巧妙的决策能带来意想不到的的效果。
需要提到的一点是,为了让精心设计出来贪心策略在之后的搜索算法中也有用武之地,我们往往会从“局面估价”的角度设计贪心,也就是做出这个决策之后的局面对我来说赢面有多大,而非做出这个决策给我带来的收益有多少,在后面的搜索算法中我们会进一步分析。

2
搜索法
搜索法是本文的重点,它依赖于对双方后续决策的模拟来寻找较优决策。
1. 极大极小搜索
极大极小是搜索中的一个核心思想,即假设我方必定会选取最可能让自己胜利的决策,敌方必定会选择最可能让我失败的决策,在此基础上对所有决策均进行模拟。如果确实地模拟到游戏结束,是能够得到一个最优决策的。然而这样做的计算量非常大,Link游戏中已经极大地缩减了决策数量,每回合每人只有10个可能的决策,即使如此也只能模拟到3回合后的局面,即使配合α-β剪枝(剪去那些继续扩展也不可能成为最终结果的分支)也至多模拟到4、5回合。这个时候游戏还没有结束,我们便需要用到前面提到的“局面估计”,估计一下来到这一局面时自己的获胜概率,这样才能反推出当前获胜概率最大的决策。
这里的局面估计实际上也就是贪心,于是可以认为这是对于贪心算法的一种改进,将多余的计算量用搜索的方式加以利用。多数游戏中,这部分利用已经对AI强度有极大的提升,即使局面估计没有经过仔细推敲,也是可以吊打大部分贪心算法了。
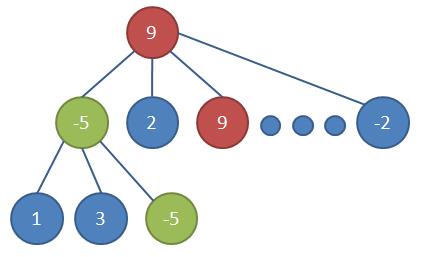
极大极小搜索(图片来自网络)
2. 启发式搜索
所谓启发式,就是让你的搜索更加聪明一些。想想看我们的极大极小搜索,它对所有的决策都进行了搜索,然而大部分决策都是可以很容易看出收益不高,不需要进一步搜索的。于是每次搜索时我们可以先做“预估计”,使用之前的贪心法找出收益最大的数个决策(我一般取3~5),然后只针对这些最有可能的决策进行扩展。当然这一个“预估计”的部分也可以使用较少步数的搜索进行,这里面组合方式千千万,需要我们根据实际问题逐个尝试,找出效果最好的一种方式。
3. 蒙特卡洛搜索
听起来非常高大上的一个名字,但你只需要知道这也是对于我们前文提到搜索的一种优化罢了。在蒙特卡洛搜索中,我们将启发式搜索“预估计”一步保留的决策个数减少至1个,此时搜索不再是搜索,变成了一条路走到底的模拟,这样一来如果对方做出的决策跟我们贪心法算出来的结果不一致就不行了,于是我们做出一点让步,假设对方(也可以是双方)有一定的概率不按套路出牌,此时可以是随机决策,也可以是按照其他决策的价值赋予不同的选中概率。另外既然决策树变成了决策链,计算量大幅下降,同时我们又引入了随机性,那么便可以重复这一过程数百数千遍,比较决策的平均收益。这样一来,大多数时候我们的算法都是在使用最优的决策进行模拟,同时模拟的步数能够一下子增大,这意味着我们的AI能够看到更加长远的局势,这对于AI的强度而言是很大的提升。
蒙特卡洛搜索法只搜索大量分支中的一支
顺便一提,现在Link的AI排行榜上排在第一名的AI就是使用了蒙特卡洛搜索法。
Link排行榜
3
遗传算法
这里介绍遗传算法并不打算将其作为一个单独的AI算法来使用,而是使用遗传算法来帮助我们完成调参的工作。不论是贪心法的贪心策略还是搜索法的局面估价,都会有大量参数存在,于是有一天我就想抖个机灵,随机地调整一下自己的某一个参数,让它跟旧参数的AI对战,如果胜率超过60%,我就将这一参数进行更新,让这程序一直更新下去,我们的AI是不是就越来越强了?结果,我们的AI在天梯排行榜上分数越来越低,究其原因,我只跟自己的AI对战参考性不足,达成了某种过拟合,于是我们需要更加合理的调参方式。
遗传算法参考了自然界种群繁殖的遗传过程,首先随机生成参数的方式获取一批AI,让他们进行对战,并进行排序,表现较差的AI直接淘汰,以表现较好的AI的参数作为参考(可以模拟自然界的交配和染色体的变异等),在此生成一批新的AI,如此循环往复。这样一来每一只被认可的AI,都是打败了大量其他AI产生出来的,参考性较强,当然也可以准备一些其他算法的AI参与对战作为参考,进一步提高稳定性。
遗传算法中的繁殖过程(图片来自网络)
以上便是本次想介绍给大家的写出强力AI的传统算法,当然我们也可以使用非传统的方式,使用神经网络来训练AI,该部分内容可以参考科协另外两篇关于强化学习的推送:
本次推送相关代码可以参考:
https://github.com/Suikasxt/LinkAI
文案 科协技术部
排版 科协宣策部
以上是关于博弈游戏中的常用算法的主要内容,如果未能解决你的问题,请参考以下文章